概述
为了实现redis集群的高可用,redis经历了好几次迭代,从最开始的主从模式,到哨兵模式,再到现在的集群模式,可以说架构的优化越来越好,那本篇文章就介绍一下redis的哨兵模式,不过我司其实使用的是cluster模式,这里就当学习一下。
redis哨兵模式架构
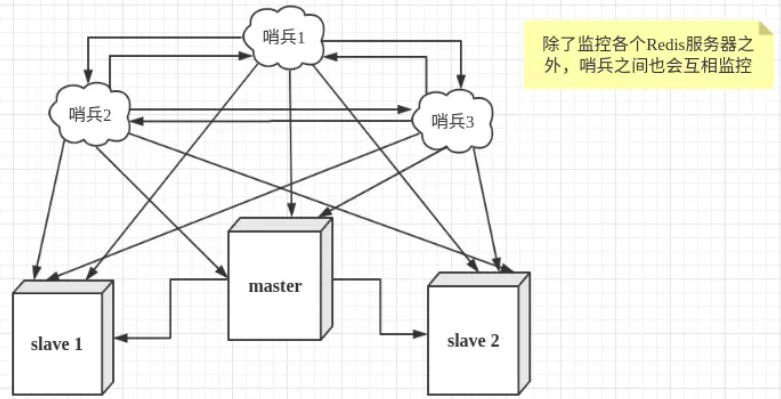
声明:本图来源Redis ==> 集群的三种模式
要解释什么是哨兵模式,要从redis的主从模式说起,redis的主从模式就是把上图的所有的哨兵去掉,就变成了主从模式,主从模式是主节点负责写请求,然后异步的同步给从节点,然后从节点负责读请求,所以在主从架构中redis每个节点保存的数据是相同的,只是数据的同步可能会有一点延迟,那考虑到高可用性,如果主节点挂了,是没有一个自动选主的机制的,需要人工来指定一个节点为主节点,然后再恢复成主从结构,所以其实也是不能做到高可用。
为了解决主从模式不能高可用的问题,就发明了哨兵模式,所谓的哨兵模式,就是在原来的主从架构的基础上,又搞了一个集群,哨兵集群,这个集群会监控redis集群的主节点和从节点的状态,如果发现主节点挂了,就会重新在从节点中选出来一个作为主节点,从而做到高可用。
那哨兵本身是一个集群,那这个集群之间是怎么通信的呢?哨兵模式既然可以监控redis集群,做到故障转移,哨兵集群又是怎么监控redis集群的呢?下面就分析这两个问题
哨兵模式工作原理
哨兵集群中的每个节点都会启动三个定时任务
- 第一个定时任务: 每个sentinel节点每隔1s向所有的master、slaver、别的sentinel节点发送一个PING命令,作用:心跳检测
- 第二个定时任务: 每个sentinel每隔2s都会向master的__sentinel__:hello这个channel中发送自己掌握的集群信息和自己的一些信息(比如host,ip,run id),这个是利用redis的pub/sub功能,每个sentinel节点都会订阅这个channel,也就是说,每个sentinel节点都可以知道别的sentinel节点掌握的集群信息,作用:信息交换,了解别的sentinel的信息和他们对于主节点的判断
- 第三个定时任务: 每个sentinel节点每隔10s都会向master和slaver发送INFO命令,作用:发现最新的集群拓扑结构
哨兵如何判断master宕机
主观下线
这个就是上面介绍的第一个定时任务做的事情,当sentinel节点向master发送一个PING命令,如果超过own-after-milliseconds(默认是30s,这个在sentinel的配置文件中可以自己配置)时间都没有收到有效回复,不好意思,我就认为你挂了,就是说为的主观下线(SDOWN),修改其flags状态为SRI_S_DOWN
客观下线
要了解什么是客观下线要先了解几个重要参数:
- quorum:如果要认为master客观下线,最少需要主观下线的sentinel节点个数,举例:如果5个sentinel节点,quorum = 2,那只要2个sentinel主观下线,就可以判断master客观下线
- majority:如果确定了master客观下线了,就要把其中一个slaver切换成master,做这个事情的并不是整个sentinel集群,而是sentinel集群会选出来一个sentinel节点来做,那怎么选出来的呢,下面会讲,但是有一个原则就是需要大多数节点都同意这个sentinel来做故障转移才可以,这个大多数节点就是这个参数。注意:如果sentinel节点个数5,quorum=2,majority=3,那就是3个节点同意就可以,如果quorum=5,majority=3,这时候majority=3就不管用了,需要5个节点都同意才可以。
- configuration epoch:这个其实就是version,类似于中国每个皇帝都要有一个年号一样,每个新的master都要生成一个自己的configuration epoch,就是一个编号
客观下线处理过程
- 每个主观下线的sentinel节点都会向其他sentinel节点发送 SENTINEL is-master-down-by-addr ip port current_epoch runid,(ip:主观下线的服务id,port:主观下线的服务端口,current_epoch:sentinel的纪元,runid:*表示检测服务下线状态,如果是sentinel 运行id,表示用来选举领头sentinel(下面会讲选举领头sentinel))来询问其它sentinel是否同意服务下线。
- 每个sentinel收到命令之后,会根据发送过来的ip和端口检查自己判断的结果,如果自己也认为下线了,就会回复,回复包含三个参数:down_state(1表示已下线,0表示未下线),leader_runid(领头sentinal id),leader_epoch(领头sentinel纪元)。由于上面发送的runid参数是*,这里后两个参数先忽略。
- sentinel收到回复之后,根据quorum的值,判断达到这个值,如果大于或等于,就认为这个master客观下线
选择领头sentinel的过程
到现在为止,已经知道了master客观下线,那就需要一个sentinel来负责故障转移,那到底是哪个sentinel节点来做这件事呢?需要通过选举实现,具体的选举过程如下:
- 判断客观下线的sentinel节点向其他节点发送SENTINEL is-master-down-by-addr ip port current_epoch runid(注意:这时的runid是自己的run id,每个sentinel节点都有一个自己运行时id)
- 目标sentinel回复,由于这个选择领头sentinel的过程符合先到先得的原则,举例:sentinel1判断了客观下线,向sentinel2发送了第一步中的命令,sentinel2回复了sentinel1,说选你为领头,这时候sentinel3也向sentinel2发送第一步的命令,sentinel2会直接拒绝回复
- 当sentinel发现选自己的节点个数超过majority(注意上面写的一种特殊情况quorum>majority)的个数的时候,自己就是领头节点
- 如果没有一个sentinel达到了majority的数量,等一段时间,重新选举
故障转移过程
通过上面的介绍,已经有了领头sentinel,下面就是要做故障转移了,故障转移的一个主要问题和选择领头sentinel问题差不多,到底要选择哪一个slaver节点来作为master呢?按照我们一般的常识,我们会认为哪个slaver中的数据和master中的数据相识度高哪个slaver就是master了,其实哨兵模式也差不多是这样判断的,不过还有别的判断条件,详细介绍如下:
在进行选择之前需要先剔除掉一些不满足条件的slaver,这些slaver不会作为变成master的备选
- 剔除列表中已经下线的从服务
- 剔除有5s没有回复sentinel的info命令的slaver
- 剔除与已经下线的主服务连接断开时间超过 down-after-milliseconds*10+master宕机时长的slaver
选主过程
- 选择优先级最高的节点,通过sentinel配置文件中的replica-priority配置项,这个参数越小,表示优先级越高
- 如果第一步中的优先级相同,选择offset最大的,offset表示主节点向从节点同步数据的偏移量,越大表示同步的数据越多
- 如果第二步offset也相同,选择run id较小的
后续事项
新的主节点已经选择出来了,并不是到这里就完事了,后续还需要做一些事情,如下
- 领头sentinel向别的slaver发送slaveof命令,告诉他们新的master是谁谁谁,你们向这个master复制数据
- 如果之前的master重新上线时,领头sentinel同样会给起发送slaveof命令,将其变成从节点
哨兵模式存在的问题
任何一种模式都不是完美的,哨兵模式也不例外,下面就介绍一下这种模式存在的一些问题
主节点写压力过大
由于只有主节点负责写数据,如果有大量的写请求的时候,主节点负载太高,有挂掉的风险
解决办法:使用cluster模式^_^
集群脑裂
所谓的集群脑裂,就是一个集群中出现了两个master,这种情况是如何产生的呢?当集群中的master的网络出现了问题,和集群中的slaver和sentinel通信出现问题,但是本身并没有挂,见下图
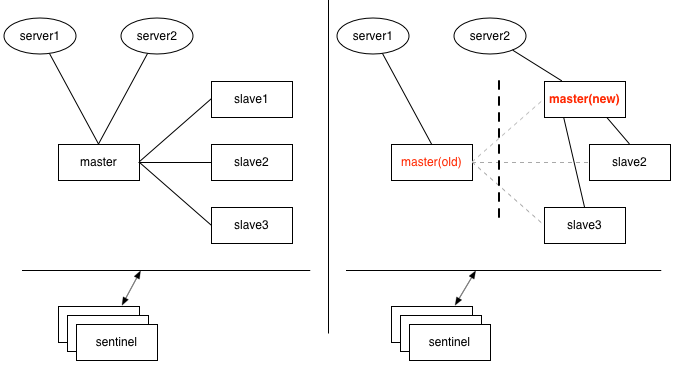
声明:本图来源:redis 脑裂等极端情况分析
这时,由于sentinel连接不上master,就会重新选择一个新的slaver变成master,这时候如果client还么有来得及切换,就会把数据写入到原来的那个master中,一旦网络恢复,原来的master就会被变成slaver,从新的master上复制数据,那client向原来的master上写的数据就丢失了。
解决办法:在redis的配置文件中有如下两个配置项
- min-slavers-to-write 1
- min-slavers-max-lag 10
这两个配置项组合在一起配置的意思就是至少有一个slaver和master数据同步延迟不超过10s,如果所有的slaver都超过10s,那master就会拒绝接收请求,为什么加了这两个参数就可以解决问题呢?如果发生脑裂,如果client向旧的master写数据,旧的master不能向别的slaver同步数据,所以client最多只能写10s的数据。这里有些萌新可能就会有问题了,如果发生脑裂的时候,之前集群中的master和一个slaver都与别的slaver和sentinel无法通信了,但是这两个哥们还可以通信,那这个slaver不就可以正常从master同步数据吗,不就满足了上面的两个条件了吗,对,确实会这样^_^,所以你可以把min-slavers-to-write配置大一点
主从数据不一致
这个没办法,异步复制确实会有这个问题,如果系统可以接受这一点延迟,那就没问题,如果一定要没有一点延迟,那就指定读主库吧。
总结
本文介绍了什么是哨兵模式,以及哨兵模式中如何选择领头sentinel来做故障转移和故障转移的过程,之后又介绍了哨兵模式的一些问题,一般来说吧,如果redis中的数据量不是很大都可以使用这种模式,比如就几个G的数据,使用哨兵模式没什么问题。
番外话:最近觉得变成一个厉害的码农,要精通的东西太多,但人的精力有限,觉得就像一个蜗牛要去攀登珠穆朗玛峰一样,爬呀爬,爬呀爬,回头一看,发现自己还没有到山脚下。
参考: