1)集合定义
set是一个无序且不重复的元素集合。
set其实内部是key:value的形式保存的key是根据值算出来的一个哈希值,只是我们在使用时不需要关注key,只需要关心value。
和其他语言中的哈希表(数据结构)相似。
2)set集合的创建方式(只有一种):因为不常用,所以python语法堂没提供其他方式
s1 = set()
s1 = set(('2','3','4'))
ps:set()函数的参数可以是列表、元组(字符串,可以但字符串没有意义)因为set集合天然去重,所以当传入列表或元组时,可以得到去重后的结果
3)set的常用方法:
有的函数帮你处理完后生成新的集合。有的是对原来的集合进行修改
s1.add() 添加元素
s1.clear() 清空里面的元素
s1.copy() 浅拷贝
s1.difference(s2) 比对两个集合s1 -s2,return 一个新集合(新集合里的元素是两个集合的差集 )且不改变老集合
s1.difference_update(s2) 比对两个集合 s1 -s2,改变老集合s1为两个集合的差集
s1.intersection(s2) 取交集,创建一个新set
s1.intersection(s2) 取交集,修改原来的set
s1.isdisjoint(s2) 如果没有交集返回false
s1.issubset(s2) 判断s1是不是s2的子集
s1.issuperset(s2) 判断s1是不是s2的父集
s1.pop() 删除元素,并return这个值
s1.remove(arg) 移除,不返回,必须有参数
s1.symmetric_difference 取差集,
s1.symmetric_difference_update() 差集,改变原来
s1.union(s2) 并集合,return新集合
s1.update 更新
set的应用实例:
4)应用场景:爬虫程序
比如爬京东主页,你去拿首页中的所有<a></a>标签,一个商品可能有多个入口,所以可以找到一个url 放到set里(set.add),这样就不会爬重复的链接。
使用set集合保存url有两个好处:
1.访问速度快(内部是key:v的保存形式,比列表的元素快很多)
2.天生解决了重复问题
>>> set(['alex','eric','tony','alex'])
set(['tony', 'alex', 'eric’])
06 python s12 day3 Python集合Set(二)
5) 讲解s1.difference(s2) 和s1.issuperset(s2) 的不同之处
07 python s12 day3 Python计数器Counter
7.collection系列之计数器
计数器collections.Counter类实例化
需要记住的用法,和5个方法
方法一:
obj.most_common(4)获得前面4个(元素,数量)对,并保存在列表中
方法二:
obj.elements():获得一个迭代器,for循环得到实例化Counter()类时的参数,但是顺序是排列过的。应用场景:在需要处理Counter对象原生值时使用。
方法三:
直接对Counter进行循环得到(元素,数量)键值对
具体使用举例:
>>> import collections
>>> obj = collections.Counter('sdfsfdcxsdfsfgcvsfafasd')
>>> print(obj)
Counter({'f': 6, 's': 6, 'd': 4, 'a': 2, 'c': 2, 'g': 1, 'v': 1, 'x': 1})
>>> ret = obj.most_common(4)
>>> print(ret)
[('f', 6), ('s', 6), ('d', 4), ('a', 2)]
>>> for k,v in obj.items():
... print(k,v)
...
('a', 2)
('c', 2)
('d', 4)
('g', 1)
('f', 6)
('s', 6)
('v', 1)
('x', 1)
>>> for k in obj.elements():
... print k
...
a
a
c
c
d
d
d
d
g
f
f
f
f
>>>
08 python s12 day3 Python有序字典OrderedDict
方法四:
obj.update()方法
>>> import collections
>>> obj = collections.Counter([11,22,22,33])
>>> print(obj)
Counter({22: 2, 33: 1, 11: 1})
>>> obj.update(['eric','11',11])
>>> print(obj)
Counter({11: 2, 22: 2, 33: 1, '11': 1, 'eric': 1})
方法五:
obj.subtract()方法
>>> obj.subtract(['eric','11','11'])
>>> print(obj)
Counter({11: 2, 22: 2, 33: 1, 'eric': 0, '11': -1})
8.有序字典orderedDict (是对字典的补充)
1)有序字典的内部实现本质
将字典.keys()取出,放到一个列表中
列表是有序的,那么你在循环的时候,去循环这个列表中的key,然后拿着这个key值,去字典里字典['key’]获得这个value值
2)有序字典的创建方法
>>> dic = collections.OrderedDict()
>>> dic['k1'] = ‘v1'
>>> dic['k2'] = 'v2’
>>> dic['k3'] = 'v3’
>>> print(dic)
OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
3)有序字典的常用方法
有一般字典的方法,还有扩展的方法
dic.pop() 按顺序拿,不带参数拿最后一个。弹夹的方式(后进先出,内存里的栈就是这种弹夹方式),带参数,指定要拿指定key,拿到值返回value
dic.popitems()
dic.setdefault()
dic.update(dic2) 把后面一个字典加进去,
dic.values()
dic.move_to_end() 这个新加的,把一个k,v对拿到最后
>>> print(dic)
OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
>>> dic.move_to_end('k1’)
>>> print(dic)
OrderedDict([('k2', 'v2'), ('k3', 'v3'), ('k1', 'v1')])
09 python s12 day3 Python默认字典defaultdict
9.默认字典defaultdict (是对字典的补充)
1)默认字典的本质
默认字典实质是设置字典里的 value的类型为列表活着字符串
2)默认字典的创建方法
>>> import collections
>>> dic = collections.defaultdict(list) #这里就显示将value的默认类型为list
>>> dic['k1'].append('alex’) 这样相当于普通字典的dic = {‘k’:[]} 然后dic[‘k’].append(‘alex')
>>> print(dic)
defaultdict(<class 'list'>, {'k1': ['alex']})
3)默认字典的常用方法
和正常字典一样的方法
10 python s12 day3 Python可命名元祖namedtuple
10.可命名元组(namedtuple) (对元组的一个扩展)
1)可命名元组的定义
可命名元组和普通元组的不同之处,普通元组使用下标访问元素,可命名元组可以使用名字访问。
2)可命名元组的创建方法:
1.创建一个可命名元组的类 (比其他的扩展多了这步)
2.使用这个类的构建方法创建可命名元组的对象
举例:
>>> mytuple = collections.namedtuple('mytuple',['x','y','z'])
>>> t = mytuple(1,2,3)
>>> t.x
1
>>> t.y
2
>>> t.z
3
3)可命名元组的常用方法:
类似元组的方法,依然不能更改里面的元素
11 python s12 day3 Python双向队列deque
11.双向队列(deque)
1)基本介绍:
python内置的提供了内存级别的消息队列类
python里面提供了2种队列:1.单向队列。 2.双向队列
2)单向队列:先进先出,一头光进,一头光出
3)双向队列:两头 每一头都可以进都可以取。想从哪边取放都行。
双向队列的创建方法 collections里有双向队列的类
>>> import collections
>>>d = collections.deque()
d.append(‘') 默认从右边添加
>>> d.append('1’)
d.appendleft('’) 从左边添加
>>> d.appendleft('10’)
>>> d.appendleft('2’)
>>> d.appendleft('1’)
>>> print(d)
deque(['1', '2', '10', '1'])
d.count('1’) 查看某个元素在对象中个数
d.extend(['yy','uu','ii’]) 默认右边扩展
>>> d.extend(['yy','uu','ii’]) 默认右边扩展
>>> print(d)
deque(['1', '2', '10', '1', 'yy', 'uu', 'ii'])
d.extendleft(['y1','u1','i1']) 从左边扩展
>>> d.extendleft(['y1','u1','i1'])
>>> print(d)
deque(['i1', 'u1', 'y1', '1', '2', '10', '1', 'yy', 'uu', 'ii'])
>>>
d.index('yy’) 取值的索引位置默认从左
d.pop()默认从右边取
d.popleft() 从左边
d.remove()
d.reverse 反转
d.rotate()参数数字,意思是从左边循环拿数据往右边放。暂时没用
总结:双向队列的优势就是两面都可以取
12 python s12 day3 Python单项队列queue.Queue
12.单向队列
单向队列不在collections ,而是放在模块queue
import queue
单向队列的创建方法
>>> import queue
>>> q = queue.Queue()
>>>
单向队列的常用方法:
q.qsize()查看队列的个数
q.full()单向队列可以预先定义最多的个数。q.full判断是否满了
q.put()往队列插入一条数据
q.get() 不用加参数,只能是先进先出。
其他方法,之后多线程。
13 python s12 day3 Python深浅拷贝原理
其他语言中两种数据类型:值类型 和 引用类型
python中分成两类 :字符串和数字一类,其他一类
1)对于 字符串和数字一类,赋值 、浅拷贝、深拷贝得到的内存都是一样的。也就是说对于字符串和数字一类 浅拷贝、深拷贝是没有什么意义的。
举例:(为了不是每次创建字符串或者数字类的同一个值时都要在内存中创建内存块。python内部数字和字符串都有一个缓冲池机制,专门放这些经常用到字符串和数字类型。这样当需要创建多个相等的值时,就不在创建了,直接从缓冲池里去,从而提高了内存使用率。)
赋值
>>> a1 = 247
>>> a2 = 247
>>> id(a1)
4297545824
>>> id(a2)
4297545824
通过赋值两个变量远指向同一个内存块
>>> a1 = 24823423424234234
>>> a2 = 24823423424234234
>>> id(a1)
4300230480
>>> id(a2)
4301816784
>>> a3 = a1
>>> id(a3)
4300230480
浅拷贝
>>>import copy
>>>a3 = copy.copy(a1)
>>> a3
24823423424234234
>>> id(a3)
4300230480
深拷贝:
>>> a3 = copy.deepcopy(a1)
>>> id(a3)
4300230480
>>> id(a1)
4300230480
2)对于其他类,如列表、字典、集合 类 浅拷贝、深拷贝才有意义
列表、字典等数据类型有.copy()实际上调用的copy模块中的浅拷贝。
举例:
赋值:对于赋值 对内id是一样的
>>> n1 = {'k1':'v1','k2':123,'k3':['alex',456]}
>>> n2 = n1
>>> id(n1)
4302200328
>>> id(n2)
4302200328
浅拷贝
>>> n3 = copy.copy(n1)
>>> n3 {'k2': 123, 'k1': 'v1', 'k3': ['alex', 456]}
>>> id(n3)
4302223624
拷贝完了就不一样了。
原因:一样的字典有出现了一个,所以id不一样了,但是浅拷贝只拷贝了第一层,也就是说只是拷贝了字典这一层,里面的元素值都没有拷贝。也就是说n1[‘k3’]的id和n3[‘k3’]的id是一样的。为什么没拿n1[‘k1’]和n3[‘k1’]做比较,因为,n1[‘k1’]的值是字符串,字符串和数字深浅拷贝都一样,都是原来的内存id.而n1[‘k3’]的值是 列表。
>>> id(n3['k3'])
4321236552
>>> id(n1['k3'])
4321236552
深拷贝
深拷贝 较浅拷贝,拷贝多层,也就是除了字符串和数字类,其他元素都创建了一个新的(内存id不一样。)
举例:
>>> n4 = copy.deepcopy(n1)
>>> id(n4['k3'])
4322108872
>>> id(n1['k3'])
4321236552
14 python s12 day3 Python深浅拷贝应用
应用场景举例
1)浅拷贝举例:
import copy
'''比如下面是500台服务器的监控参数,现在想在添加500台的监控参数,将cpu改成50,这时就必须用深拷贝'''
dic = {
'cpu':[80,],
'mem':[80,],
'disk':[80,]
}
print dic
new_dic = copy.copy(dic)
new_dic['cpu'][0] = 50
print(dic)
print(new_dic)
执行结果如下,所以浅拷贝不行,
{'mem': [80], 'disk': [80], 'cpu': [80]}
{'mem': [80], 'disk': [80], 'cpu': [50]}
{'mem': [80], 'disk': [80], 'cpu': [50]}
2)深拷贝举例:
import copy
'''比如下面是500台服务器的监控参数,现在想在添加500台的监控参数,将cpu改成50,这时就必须用深拷贝'''
dic = {
'cpu':[80,],
'mem':[80,],
'disk':[80,]
}
print(‘before:’,dic)
new_dic = copy.deepcopy(dic)
new_dic['cpu'][0] = 50
print(dic)
print(new_dic)
执行结果如下:
('before:', {'mem': [80], 'disk': [80], 'cpu': [80]})
{'mem': [80], 'disk': [80], 'cpu': [80]}
{'mem': [80], 'disk': [80], 'cpu': [50]}
15 python s12 day3 Python函数的基本定义
函数的好处
1.可以将100行代码 按功能拆分出多个函数,那么主程序的逻辑看起来就很清晰了了
2.如果一段代码需要多个业务逻辑都需要使用到,用函数就可以方便代码块的重用
函数在python中如何执行的:
函数定义后,不主动执行,python解释器是不会执行函数代码块中的内容的。
python中用关键字 def 定义函数,python解释器当遇到def关键字后,就知道这是个函数,先不解释。
函数名() ,是调用这个函数。
定义函数的方法:
def mail():
n = 123
n += 1
print(n)
mail() #调用这个函数
f = mail 将函数赋值给f ,f()调用
16 python s12 day3 Python函数的返回值(一)
函数的返回值(一):
函数中是功能代码块,那么这个功能代码块执行完了,要得到执行的结果,用return关键字将结果返回。可以把返回值赋值给变量。
发送邮件,发送成功返回123,失败返回456
#!/usr/bin/env python3.5
import smtplib from email.mime.text
import MIMEText from email.utils
import formataddr
def mail():
ret = 123
try:
msg = MIMEText('message1','plain','utf-8’)
msg['From'] =formataddr(['zhming26','114648340@qq.com'])
msg['To'] = formataddr(["ceshi01",'114648340@qq.com'])
msg['Subject'] = "zhutipythonceshi1”
#server = smtplib.SMTP("smtp.qq.com",465)
server = smtplib.SMTP_SSL("smtp.qq.com”)
server.login("114648340@qq.com","jarhfvmbjwwwah”)
server.sendmail('114648340@qq.com',['114648340@qq.com',],msg.as_string())
server.quit()
except Exception:
ret = 456
return ret
ret = mail()
print(ret)
if ret == 123:
print(“发送成功”)
else:
print(“发送失败”)
17 python s12 day3 Python函数的返回值(二)
函数的返回值(二):
如果一个函数里面没有出现return,那么这个函数的返回值是None
当函数中有return时,直接返回,return后面的代码不在继续执行
举例:
def show():
print(‘a’)
return [11,22]
print(‘b’)
调用此函数不会打印b
18 python s12 day3 Python函数的普通参数
参数详解:形参、实参
1.普通参数:
定义函数时,如果有多个参数时,调用函数时要一一对应,不能多不能少,否则报错
19 python s12 day3 Python函数的默认参数
2.默认参数:
定义默认参数时,要放在参数的最后,否则语法就报错了。
def show(a1,a2,a3=99,a4=88):
print(a1,a2,a3,a4)
调用函数时:
show(11,22)
就会把默认参数也打印出
3.指定参数:
def show(a1,a2):
print(a1,a2)
在执行参数可以:
show(11,22)
也可以:
show(a2=22,a1=11)
20 python s12 day3 Python函数的动态参数(一)
4.动态参数
def show(arg): 普通参数
print(arg)
n=[11,22,33,44]
show(n)
执行结果:
[11, 22, 33, 44]
def show1(*arg): 一个*的,可传入多个参数,传入的参数会被弄成元组,也可以不传参数。
print(arg,type(arg))
show1(11,22,33,44,55)
show1()
执行结果
((11, 22, 33, 44, 55), <type 'tuple'>)
((), <type 'tuple'>)
def show2(**arg): 两个 *的,可传入多个参数,传入的参数会被弄成字典,但传入的格式必须是 n1 = v1。也可以不传参数
print(arg,type(arg))
show2(n1=78,uu=123)
show2()
执行结果
({'uu': 123, 'n1': 78}, <type 'dict'>)
({}, <type 'dict’>)
def show3(*args,**kwargs): 一个*、两个*同时写入,python会自动识别,但是顺序不能乱
print(args,type(args))
print(kwargs,type(kwargs))
show3(11,22,33,44,n1=88,n2=99,n3=77)
执行结果
((11, 22, 33, 44), <type 'tuple'>)
({'n1': 88, 'n2': 99, 'n3': 77}, <type 'dict’>)
21 python s12 day3 Python函数的动态参数(二)
def show4(*args,**kwargs):一个、两个同时写入,python会自动识别,但是顺序不能乱
print(args,type(args))
print(kwargs,type(kwargs))
l1 = [11,22,33,44]
d1 = {'n1':88,'alex':'sb'}
show4(l1,d1)
执行结果:
(([11, 22, 33, 44], {'n1': 88, 'alex': 'sb'}), <type 'tuple'>)
({}, <type 'dict’>)
所以如果你想给*args直接传入一个列表,就要在传入列表参数时加*
所以如果你想给**kwargs直接传入一个字典,就要在传入列表参数时加**
调用如下:
show4(*l1,**d1)
执行结果
((11, 22, 33, 44), <type 'tuple'>)
({'n1': 88, 'alex': 'sb'}, <type 'dict'>)
22 python s12 day3 使用动态参数实现字符串格式化
普通的字符串格式化方式
s1 = "{0} is {1}"
ret = s1.format('alex', '1b')
print(ret)
传入列表的方式
s2 = "{0} is {1}"
li = ['alex','2b']
ret2 = s2.format(*li)
print(ret2)
普通定义名称化的格式化方法
s3 = "{name} is {acter}"
ret3 = s3.format(name='alex',acter = '3b')
print ret3
传入字典的格式化方法
s4 = "{name} is {acter}"
dic4 = {'name':'alex','acter':'4b'}
re4 = s4.format(**dic4)
print re4
23 python s12 day3 Python lambda表达式
lambda表达式的说明:
def func1(a):
a = a+1
return a
func2 = lambda a: a+1
#上面func1这个简单函数,可以用func2方式书写。
ret1 = func1(99)
ret2 = func2(99)
print ret1
print ret2
ps:lambda表达式只能用于简单的函数。因为只能写一行代码
三元运算的说明:
temp = None
if 1>3:
temp = 'gt'
else:
temp = 'lt'
用三元运算可以写成下面这样:
result = 'gt' if 1>3 else 'lt’
24 python s12 day3 Python 内置函数(一)
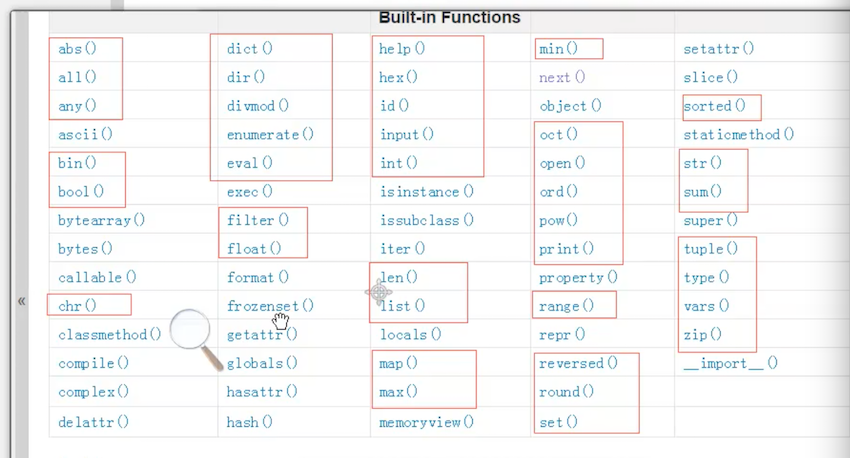
python为我门提供了一些,不需要导入某一个模块就可以使用的函数,称之为python内置函数。图片中即是所有内置函数:红框中即需要掌握的函数。
一一解说:
abs() 相当于*.__abs__()
all() 所有为真,则返回真
any() 任何为真,则返回真
ascii() 转为ascii码,实际调用 *.__repr__()方法
bin() 将数字转为2进制模式,
callable() 是否可执行,判断是否是执行方法
chr() 把数字转换成字符,和ord()相反把字符转换成数字,动态生成验证码。
动态生成验证码的实现还得用random
import random
random.randint(1,99) 返回一个随机数
>>> x = random.randint(1,99)
>>> chr(x)
'G'
>>> x = random.randint(1,99)
>>> chr(x)
'E'
classmethod() 过,类里面的类方法
compile() 编译时用的,暂时用不到,python有web框架中用到compile(),compile就可以把字符串编译成python代码。
complex() 复数,过没用
delattr() 反射的时候用。第4天课程用
dict() 字典的创建方法
dir() 查看类的方法
divmod() 得到商和余数(网页页数的时候用到!)
enumerate() 得到序列号 +元素
>>> li = ['alex','eric','bob']
>>> enumerate(
>>> enumerate(li,1)
<enumerate object at 0x101af3828>
>>> for i,item in enumerate(li,1):
... print(i,item)
...
1 alex
2 eric
3 bob
25 python s12 day3 Python 内置函数(二)
eval() 执行字符串,返回结果
>>> a = '8*6'
>>> print(a)
8*6
>>> eval(a)
48
exec() 同上,等学到编译时和eval()比较
filter() 过滤
>>> li = [11,22,33]
>>> def fun1(x):
... if x > 22:
... return True
... else:
... return False
>>> filter(fun1,li)
<filter object at 0x101af2390>
>>> li2 = filter(fun1,li)
>>> print(li2)
<filter object at 0x101af2b38>
>>> list(li2)
[33]
>>>
map() 这个函数必须掌握,具体说明如下:
假设有个需求:一个列表,每个元素都加10
我们普通方法是,遍历每一个元素,加10
这里就可以使用map()方法实现:
li = [33,44,55]
def func1(arg):
return arg+10
new_list = map(func1,li) #map就把后面li列表中的每一个值作为func1的实参。得到结果赋添加到新列表里。
print new_list
func1就可以用lambda表达式
func1 = lambda arg:arg+1
#上面new_list可以写成
new_list = map(lambda arg : arg+10,li)
map()函数的多参数的应用场景: 传三个参数的实例
l1 = [11,22,33]
l2 = [44,55,66]
l3 = [77,88,99]
需求:每一个列表的同一个下标位置相加得到结果。map()也支持.
def func2(a1,a2,a3):
return a1+a2+a3
new_list = map(fun2,l1,l2,l3)
#那我们考虑当3个列表中的值个数不一样呢。
#map遍历每一个列表取值,如果没取到返回None,所以参数不一致将报错。
#接下来想我们给func2里设置成默认参数是不是就可以了,如下
def func2(a1,a2,a3=999):
return a1+a2+a3
l1 = [11,22,33]
l2 = [44,55,66]
l3 = [77,88]
new_list = map(fun2,l1,l2,l3)
#也是会报错,因为l3遍历第三次时返回的None,None也是值。只是这种类型比较特殊。所以定义成默认参数也不行。那应该怎么解决呢。
#在函数中定义:如下
def func2(a1,a2,a3):
if not a3:
a3 = 999
return a1+a2+a3
l1 = [11,22,33]
l2 = [44,55,66]
l3 = [77,88]
new_list = map(fun2(),l1,l2,l3)
#上面的例子,用lambda表示简写如下:
l1 = [11,22,33]
l2 = [44,55,66]
l3 = [77,88,99]
def func2(a1,a2,a3):
new_list = map(fun2,l1,l2,l3)
#简写如下:
new_list = map(lambda a1,a2,a3: a1+a2+a3,l1,l2,l3)
float() 浮点数创建方法
format() 格式化,同字符串.__format__()
forzenset() 我们学过set集合,这个是不能更改的集合
ge tattr()过,反射用得到
globals() 当前可用的所有变量
hash() 做字典的key时用的。
help()
hex() 十进制转十六进制 ox表示16进制
id()
input()
int()
max() 拿到最大值
min() 拿到最小值
oct() 十进制转八进制
open()打开文件用的
ord()
pow()幂
print()
range() 拿到一个区间的生成器
repr() 同ascii ,调用str.__repr__()
round() 四舍五入
str()
sum()
super() 通过子类执行父类的构造方法
dir() 返回类的方法,返回的是key
vars() 返回类的方法,返回的是key:values ,返回的是字典
zip()
>>> x = [1,2,3]
>>> y = [4,5,6]
>>> zipped = zip(x,y)
>>> zipped
<zip object at 0x101af5508>
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)]
python内置方法暂时到这。
26 python s12 day3 Python 文件操作
1.打开文件
2.操作文件
1.打开文件
文件句柄 = open('文件路径’,’')
obj = file('文件路径’,’模式')
obj = open('文件路径’,’模式')
open其实调用的是file 推荐 open方式,因为到python3.0 以后 file的模块变位置了,那么open内部会调用。
#打开的方式有
#r,w,a
obj.seek() 按照字节操作的
obj.tell() 按照字节操作的,而下面的read()是按字符来读的,这将是个坑
obj.read(2) 这个是按照字符来读的。以后做上传一个文件,通过socked发给你,socked计算的时候按字节计算的。我们读的时候按字符来读,那么就会出错,所以python3.0这点read()按字符来读的更改是挖了一个坑。
#对于打开模式中还有r+、w+、a+
老师说:只用r+有意义,w+,a+都没有使用的意义
obj = open(‘log’,’r+’)
obj.write(‘000’)
obj.truncate() #截断数据,根据当前指针截断,保留指针之前的,抛弃指针之后,并且直接写入当前文件。
obj.close()
还有
obj = open(‘log’,’rb’)
rbwbab以二进制模式打开文件,Linux平台下默认以二进制模式存储文件。windows下才有意义。
最后一个U
这个只能和 r一起用 rU
作用:很多工具的换行符是不一样。
rU 就把
、
、
换成
27 python s12 day3 Python 本节作业(一)
28 python s12 day3 Python 本节作业(二)