NSDI2012 的一篇经典文章 《Jellyfish: Networking Data Centers Randomly》提出使用新的拓扑结构 Jellyfish 来设计网络。
Jellyfish 模型是在 《Jellyfish: A conceptual model for the as internet topology》 这篇文章提出的,是在现有 Internet 拓扑结构研究基础之上提出的一个概念模型。其实这个模型算是大规模随机图的一个共同特点,不只是 Internet 图有这个特点。
NSDI2012 这篇文章提出,使用Jellyfish 设计的网络拓扑结构,与传统的 fat
-tree 结构相比,吞吐量一点都不差,而且灵活性还更多,更好扩展。这篇工作还挺重要的,网上可以找到不少 review、reproducing 的工作。
fat-tree 结构是这样的:
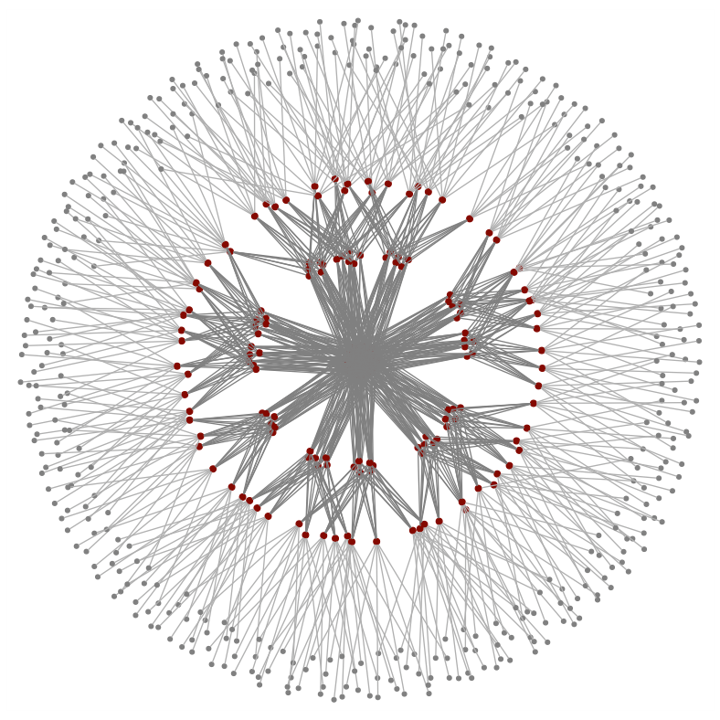
jellyfish 结构是这样的:
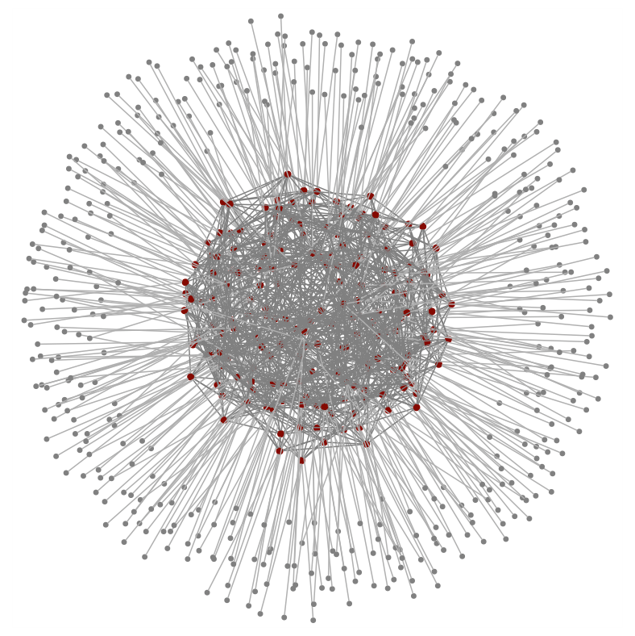
放大来看,fat-tree 结构这样组织交换机:
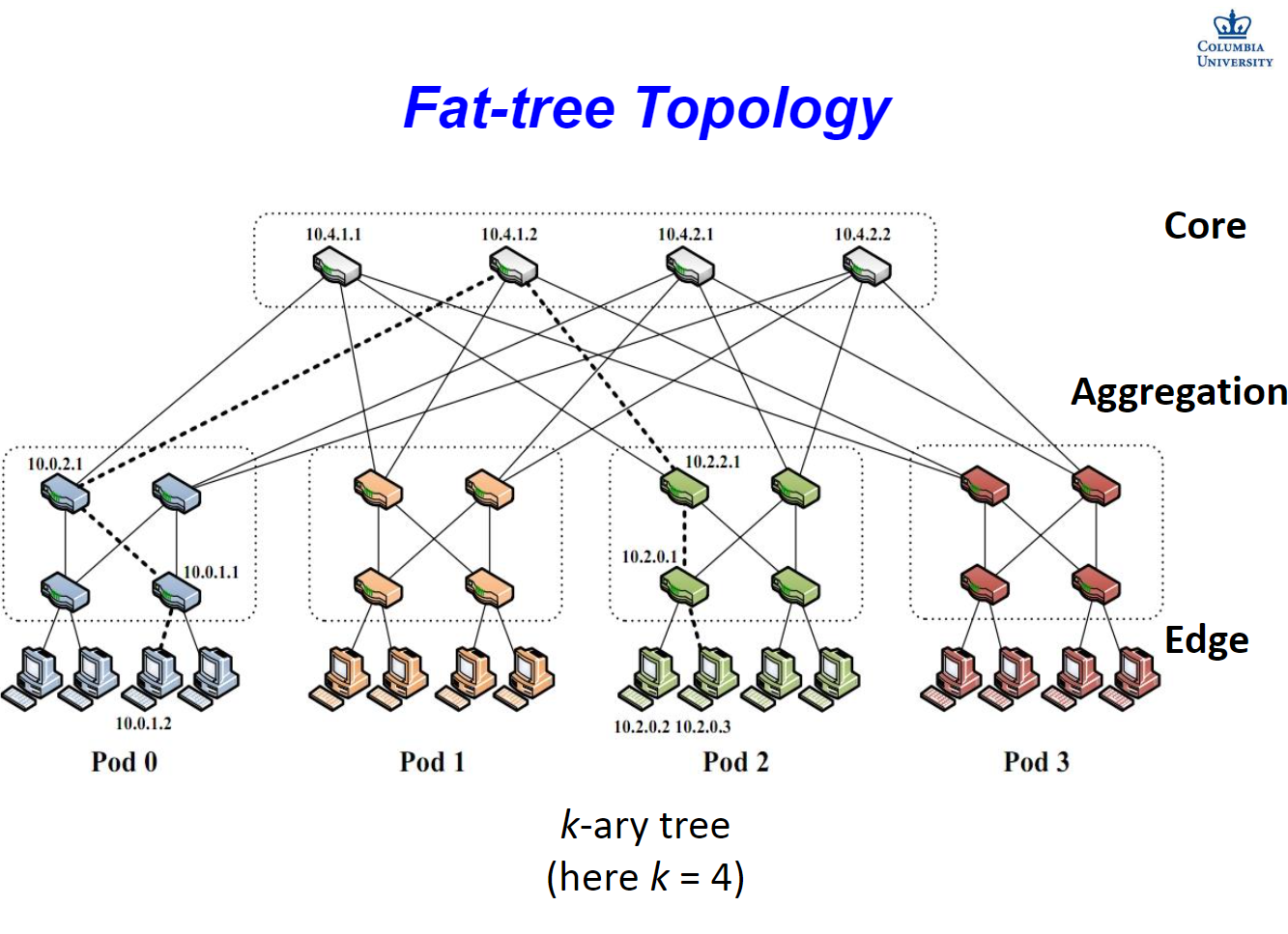
注意,这里为什么叫 fat-tree 而不是直接的 tree 呢?因为它相比于普通的 tree 要更 fat 一点(废话!)
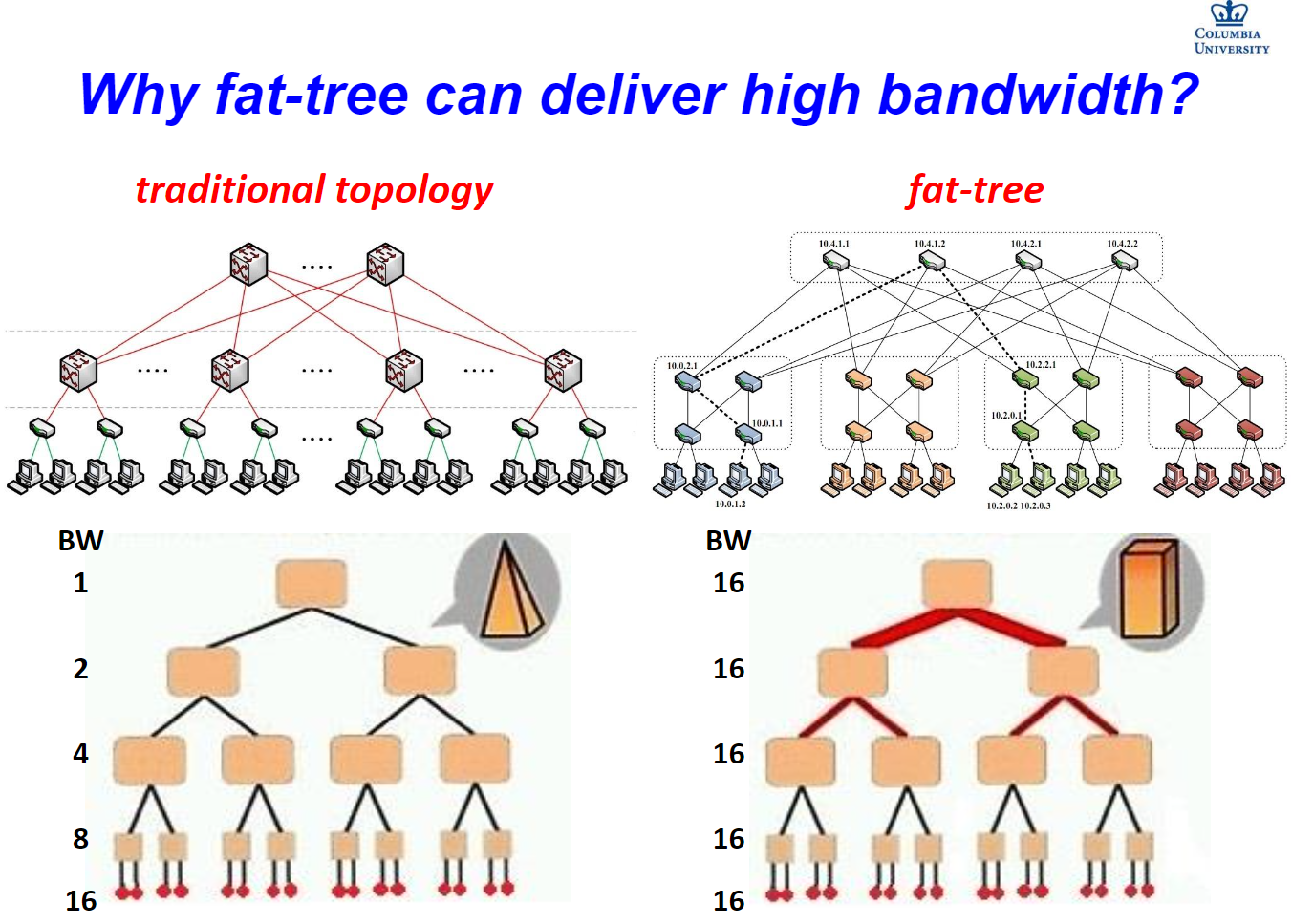
看下图,普通 n叉树结构做网络拓扑是不合适,原因之一是不够健壮,一个交换机坏了下面的主机就不可达了,这可不行;另一个原因在于带宽,层层减少的交换机,带来的结构必然是带宽紧张,越靠近骨干网络带宽越小怎么行!
所以fat-tree 就出现了,通过在 n 叉树的基础上设立多份“冗余”副本,来提高网络健壮性和带宽。
看评测结果,主机数量上来之后,n叉树的表现还是很符合理论分析的:
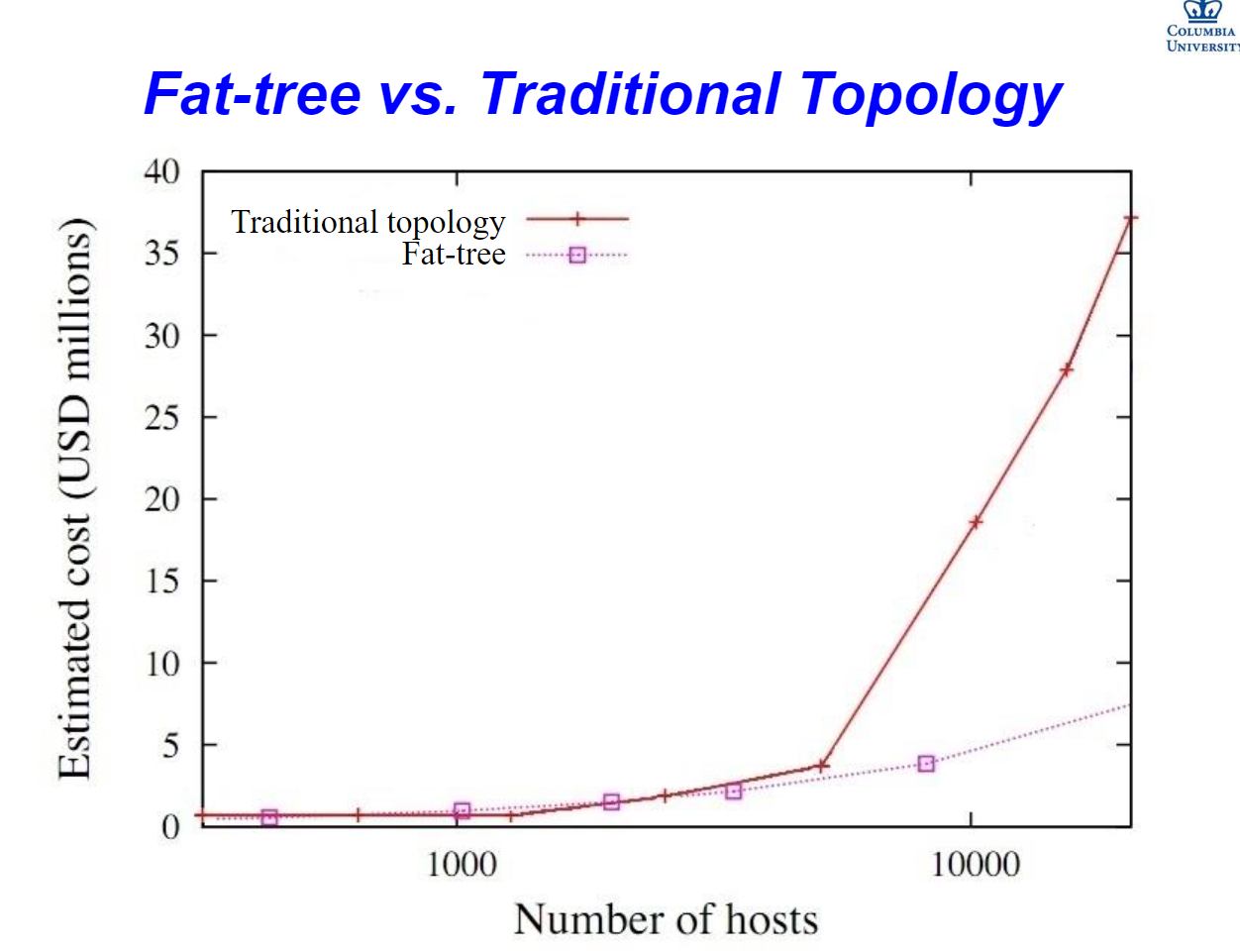
但是 fat-tree 有两个问题:一个是网络规模受限,不可能支持无限多主机;另一个是网络结构要在设计时定下来,不好动态更改。
于是 Jellyfish 就出来了,这个从网络结构中来、到网络结构中去的随机图模型解决了这两个问题。
相比于fat-tree,jellyfish有两大优点:一是可以支持的主机数量不受限制,不必像fat-tree那样受交换机端口个数的限制;另一个是可以动态扩展主机数量,不必像fat-tree那样一开始就固定死网络的形态。
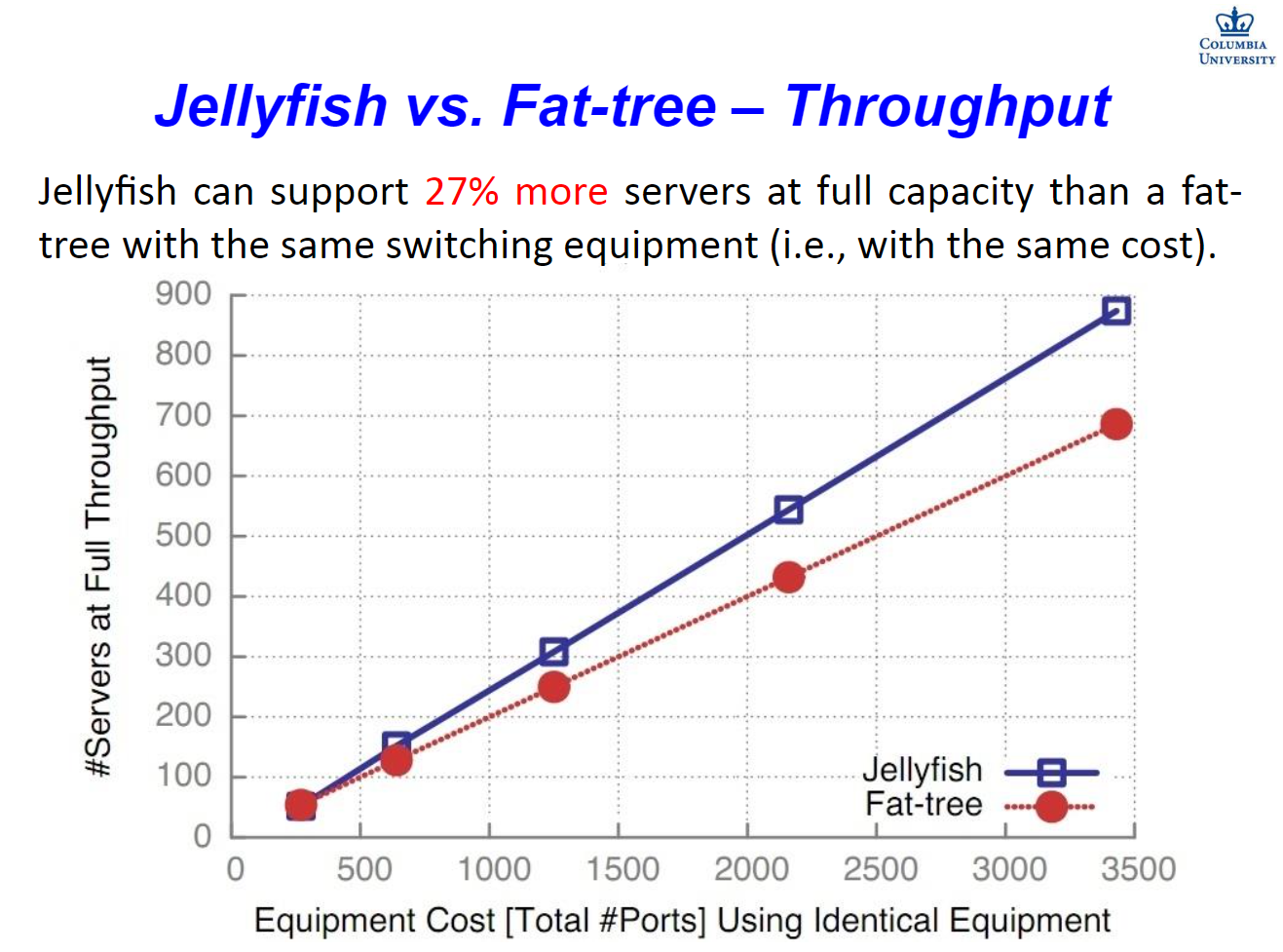
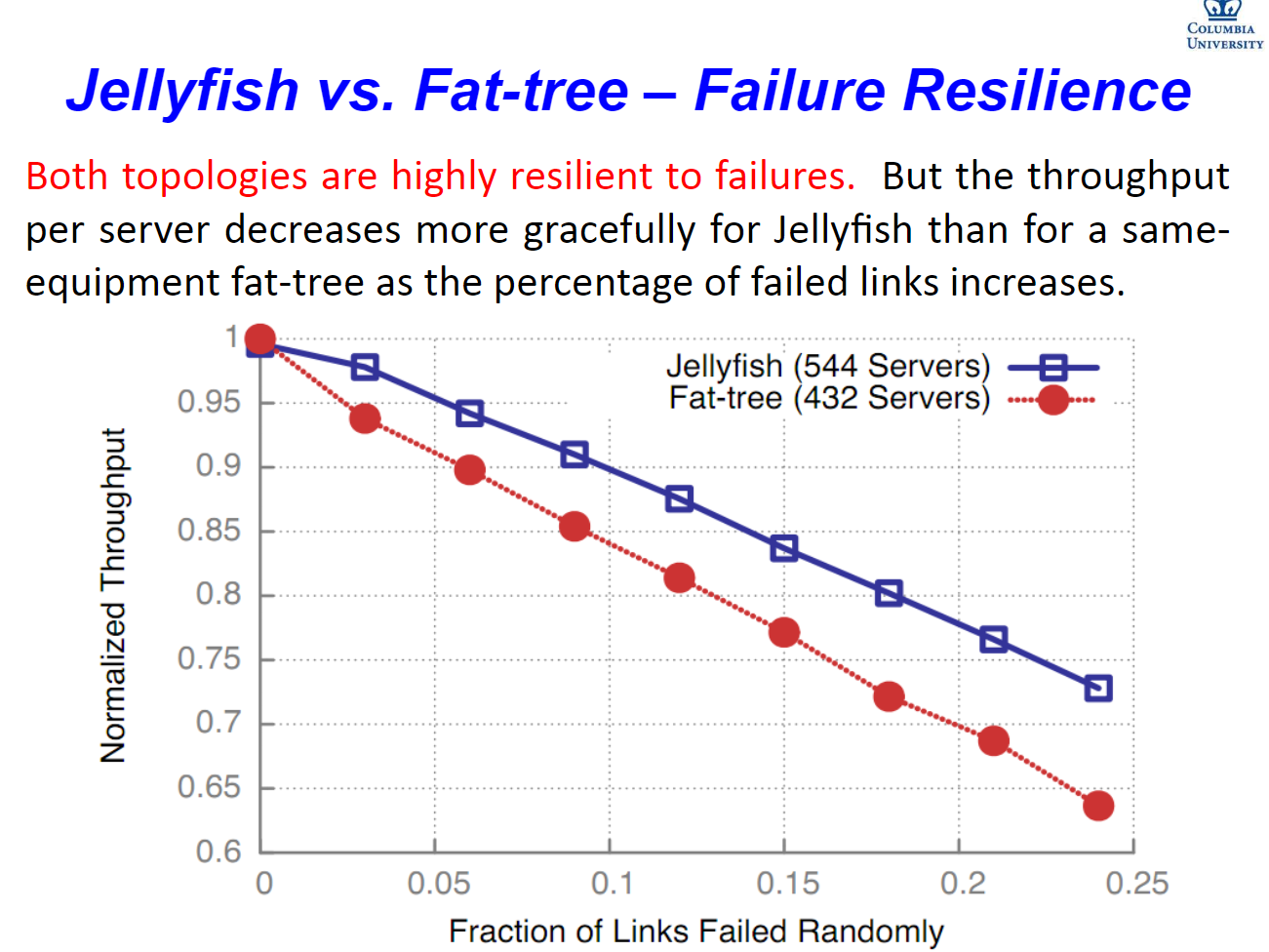
but,实际用的时候机器怎么接……?总得有点道道吧,不可能每次都找印度工程师来接吧?(误
