第10章 Python Spark RDD
RDD概念:
Spark的核心是RDD,即是弹性分布式数据集,是一种分布式的内存系统数据集的应用;Spark的主要优势来自RDD本身的特性,RDD能与其他系统兼容,可以导入外部存储系统的数据集,例如HDFS、HBase、Hadoop数据源。
10.1 RDD的3种基本运算
在RDD上可以增加3种类型的运算:
- “转换”类型:(Transformation)
- RDD执行转换会产生另一个RDD,但不会立即执行
- “动作”类型:(Action)
- RDD执行动作类型后,会产生数值、数组或者写入文件系统
- RDD的执行会立即执行,并连同之前的“转换”一起执行
- “持久化” Persistence
- 对于那些会重复使用的RDD,可以将RDD“持久化”在内存中作为后续使用,以提高执行性能
RDD的血缘机制具备容错的特性 (Lineage)
RDD具备血缘机制,它会记录每个RDD与其父代RDD之间的关联,还会记录通过什么操作才由父代转化得到当前的RDD。
RDD本身的不可变性,某个结点遇到故障后,那么存储于这个结点上的RDD损毁后就会重新执行一连串的"转换"命令,产生新的输出数据,以避免因为特定结点导致整个系统无法运行的问题.
10.3 基本RDD"转换运算"
创建一个RDD
# 创建一个数字类型的RDD
intRDD = sc.parallelize([12,3,4,5])
# 执行collect 转为列表(动作类型,立即执行)
intRDD.collect()
[12, 3, 4, 5]
# 创建一个String类型的RDD
stringRDD = sc.parallelize(["11", "22", "333"])
# 执行collect (动作类型,立即执行)
stringRDD.collect()
['11', '22', '333']
map运算介绍
map运算操作可以通过传入的函数对每一个元素进行运算产生另一个rdd,在Spark的map运算中,可以使用两种语句:具名函数和匿名函数。
具名函数和匿名函数,基本同Pandas的apply操作:
def addOne(x):
return (x+1)
intRDD.map(addOne).collect()
intRDD.map(lambda x : x+1).collect()
[13, 4, 5, 6]
[13, 4, 5, 6]
filer 操作运算
intRDD.filter(lambda x : x%2==0).collect()
[22]
distinct操作 去重
intRDD.distinct().collect()
[11,22,333]
randomSplit运算
- 使用randomsplit将整个集合按照4:6的比例分为两个RDD
sRDD = intRDD.randomSplit([0.4,0.6])
sRDD[0].collect()
[11, 22]
groupBy运算操作
可以按照传入的匿名函数规则将数据分为多个list
grdd = intRDD.groupBy(lambda x : x%2==0).collect()
print(grdd)
[(False, <pyspark.resultiterable.ResultIterable object at 0x7f8de0558390>), (True, <pyspark.resultiterable.ResultIterable object at 0x7f8de0558350>)]
10.4 多个RDD"转换运算"
支持多个RDD
- 并集 (union)
- 交集(intersection)
- 差集(subtract)
- 笛卡尔乘积运算(cartesian)
示例:
intRDD1 = sc.parallelize([1,2,3,4])
intRDD2 = sc.parallelize([5,6])
intRDD3 = sc.parallelize([2,7])
# uninon 并集运算
intRDD1.union(intRDD2).union(intRDD3).collect()
[1, 2, 3, 4, 5, 6, 2, 7]
10.5 基本"动作"运算 (Action运算, 立即执行)
- first()
- take(num_th)
- takeOrdered(3)
- takeOrdered(3, key=lambda x:-x)
统计运算 - stats() 统计, 基本同pd下的info
- min()
- max()
- stdev() 标准差
- count() 计数
- sum() 总和
- mean() 平均
key-value RDD基本的转换运算
SparkRDD支持键值运算,kv运算也算是MR的基础.
(同元组的列表)
kv1 = sc.parallelize([(1,'odd'), (2,'even')])
kv1.collect()
[(1, 'odd'), (2, 'even')]
类元组列表的结构的key-value RDD的其他:
- keys()
- values()
- filters()
- mapValues() 批量映射apply值
- sortByKey() 按照key排序,支持ascending
- reduceBykey(): 将key相同的元素进行reduce操作
- join():将两个RDD按照相同的key把value值join起来
kv2 = sc.parallelize([(1,'odd'), (4,'even')])
kv2.collect()
kv1.join(kv2).collect()
# 输出 [(1, ('odd', 'odd'))]
- leftOuterJoin() : 同leftJoin
10.8 key-value "动作" 运算
- first()
- take()
- collectAsMap() 创建kv字典, 之后使用对照表转换数据
- lookup(x) 输入key的值来查找value
kv1.lookup(1)
输出:
['odd']
10.9 Broadcast 广播变量
Shared variable(共享变量)
- 广播变量——Broadcast
- 累加器——accumulator
示例01 不使用广播变量的范例
# 创建frultMap
kv = sc.parallelize([(1,"apple"), (2, "orange"), (3, "banana"), (4, "grape")])
fruitMap = kv.collectAsMap()
print(fruitMap)
# 创建fruitids
fruitids = sc.parallelize([k for k,v in fruitMap.items()])
fruitNames = fruitids.map(lambda x : fruitMap[x]).collect()
print(fruitids.collect(), fruitNames)
输出:
{1: 'apple', 2: 'orange', 3: 'banana', 4: 'grape'}
[1, 2, 3, 4] ['apple', 'orange', 'banana', 'grape']
分析
上面的示例执行起来虽然没有问题,但是在并行处理中每执行一次转换都必须将fruitIds和fruitMap传送到WorkerNode,才能够执行转换,如果字典fruitMap(映射表)很大,那么就会耗费大量的内存与时间。
示例 (使用广播变量)
Broadcast广播变量使用规则如下:
- 可以使用SparkContent(sc).broadcast([初始值]) 进行初始化.
- 使用.value来进行读取数据.
- Broadcast广播变量被创建后,不支持再被修改.
# 创建frultMap
kv = sc.parallelize([(1,"apple"), (2, "orange"), (3, "banana"), (4, "grape")])
fruitMap = kv.collectAsMap()
print(fruitMap)
print(dict(fruitMap_sc.value))
# 创建fruitids
# fruitMap_sc = sc.broadcast(fruitMap)
fruitids = sc.parallelize([k for k,v in fruitMap_sc.value.items()])
fruitNames = fruitids.map(lambda x : fruitMap_sc.value[x]).collect()
print(fruitids.collect(), fruitNames)
输出:
{1: 'apple', 2: 'orange', 3: 'banana', 4: 'grape'}
{1: 'apple', 2: 'orange', 3: 'banana', 4: 'grape'}
[1, 2, 3, 4] ['apple', 'orange', 'banana', 'grape']
10.10 accumulator 累加器
累加器介绍
方便共享变量,可以不用重复再在工作结点中进行计算,直接在驱动程序中计算;同时,计算总和是MR的常用运算。使用规则如下:
- 累加器可以使用sc.accumulator([初始值])来创建
- 使用.add()来进行累加
- 在task中,例如在for循环中不能使用累加器
- 只有驱动程序,也就是循环外,才可以使用.value()进行读取累加器的值.
累加器示例
# 创建frultMap
intrdd = sc.parallelize([1,2,3,4])
total = sc.accumulator(0)
num = sc.accumulator(0)
intrdd.foreach(lambda x : [total.add(x), num.add(x)])
avg = total.value / num.value
avg
输出:
1.0
10.11 RDD的持久化机制(Persistence)
Spark持久化机制可以用于将重复计算的RDD存储在内存中,以便于大幅提升运算效率。
Spark RDD持久化使用方法如下:
- RDD.persist(存储等级)——可以指定存储等级,默认是MEMORY_ONLY,也就是存储在内存中。
- RDD.unpersist()——取消持久化
持久化等级说明如下:
- 仅内存型 (非串行化存储Java对象)
- 内存+磁盘型 (非串行化存储Java对象)
- 仅内存串行化 (存储RDD以Java对象的形式进行串行化存储,比较存储内存,但是在进行串行化的时候需要CPU计算资源)
- 内存串行化+磁盘串行化
- memory_only_2 和 memory_and_disk_2 等
- 同上,但是每一个RDD的分区都复制到两个节点上
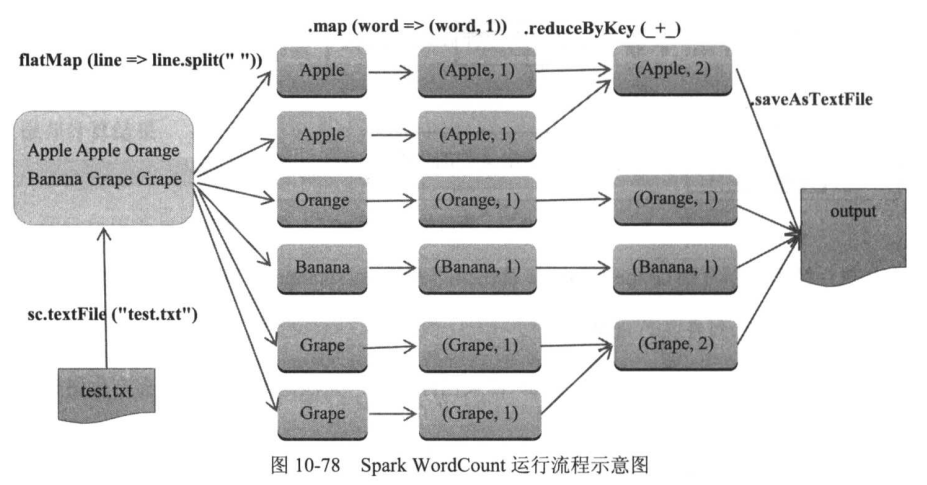
10.12 使用Spark创建wordCount
略
流程示意图如下: