首先对一些spark的基本知识进行了学习
spark的基本工作原理是:将spark的程序提交到spark集群上,在Hadoop的HDFS或者Hive上读取数据,读取的数据存放在各个spark的节点上,分布式的存放在多个节点上,主要在每个节点的内存上,这样可以加快速度。
对节点的数据进行处理,处理后的数据存放在其他的节点的内存上。对数据的 计算操作针对多个节点上的数据进行并行操作。处理之后的数据可以到hadoop或者mysql或hbase中,或者结果直接返回客户端。每一批处理的数据就是一个RDD
Hadoop 是基于磁盘的大数据计算框架 ,Spark是基于内存计算的大数据并行计算框架
spark架构: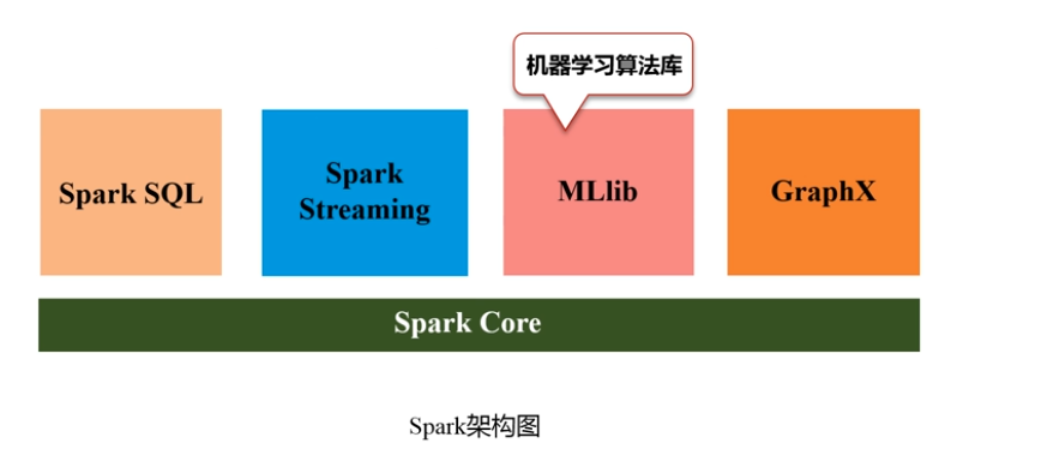
通过写实验一把Linux 系统常用命令又熟悉了一遍
(1)切换到目录 /usr/bin : $ cd /usr/bin
(2) 查看目录/usr/local 下所有的文件:$cd /usr/local $ls -al
(3)进入/usr 目录,创建一个名为 test 的目录,并查看有多少目录存在:$ cd /usr $ mkdir test $ ls -al
(4)在/usr 下新建目录 test1,再复制这个目录内容到/tmp:$ cd /usr $ mkdir test1 $ sudo cp -r /usr/test1 /tmp
(5)将上面的/tmp/test1 目录重命名为 test2:$ sudo mv /tmp/test1 /tmp/test2
(6)在/tmp/test2 目录下新建 word.txt 文件并输入一些字符串保存退出:$ cd /tmp/test2 $ vim word.txt
(7)查看 word.txt 文件内容:$ cat /tmp/test2/word.txt
(8)将 word.txt 文件所有者改为 root 帐号,并查看属性:$ sudo chown root /tmp/test2/word.txt $ ls -l /tmp/test2/word.txt
(9)找出/tmp 目录下文件名为 test2 的文件:$ sudo find /tmp -name test2
(10)在/目录下新建文件夹 test,然后在/目录下打包成 test.tar.gz:$ sudo mkdir /test $ sudo tar -zcv -f /test.tar.gz test
(11)将 test.tar.gz 解压缩到/tmp 目录:$ sudo tar -zxv -f /test.tar.gz -C /tmp