设计分析:
遇到这样一个程序设计,首先解决的是文件读入的问题(我选择读入txt),用C中的文件指针很容易解决;
第二,英文文章中由英文字母,标点符号,其他字符组成,要将他们分离,这就用到了词法分析,将每个单词分离出来并且分析;
第三,统计单词个数(不一样的单词各有几个),排序,输出频率最高的10个。
要解决的是文件读取后储存问题,就是放在结构体中,单词的种类和数量统计起来。可以用结构体数组,可以用链表。
统计后排序的问题,如果将整个结构体或链表排序,那将是一件好大的工程,但是题目只是将频率最高的10个词打印出来,就像每天人们听歌,排行榜上的第一页是用户听得最多的歌曲。于是,我只是初始化了一个结构体数组,长度为10,将10个排序,然后用最后一个,也就是这10个中频率最小的与其他的比较,如果有频率比他高的,则插入到这个长度为10 的结构体数组中。插入之后还是顺序的。这样就节省了很多的工作量。
数据结构:
储存单词的数据结构:
①结构体
typedef struct
{
char danci[19];//储存单词
int count;//记录单词个数,后面出现几次
}sq;
②链表
struct Word
{
char danci[19];
int count;
struct Word *next;
};
找出频率最高的十个单词
for(i=10;i<n;i++)
{
if(frequency_max[9].count<word[i].count)
{
int a=8;
while(frequency_max[a].count<word[i].count&&a>=0)
{
a--;
}
for(j=9;j>a+1;j--)
{
frequency_max[j]=frequency_max[j-1];
}
if(a<0)
frequency_max[0]=word[i];
else
frequency_max[j]=word[i];
}
}
代码:
#include<iostream> #include<iomanip> #include<time.h> using namespace std; #define M 20000 //文章单词个数 typedef struct { char danci[19];//储存单词 int count;//记录单词个数,后面出现几次 }sq; void main() { double start,finish; start=(double)clock(); sq word[M]; sq t_word; double s,f; int K,n=0,i,j; char infile[10]; s=(double)clock(); cout<<"***********请输入文件路径:***********"<<endl; cin>>infile;//文件路径输入 f=(double)clock();// cout<<"输入文件路径的时间:"<<(f-s)/1000<<"s"<<endl; FILE *fp; char ch; //fp=fopen("d://pro.txt","r"); if((fp=fopen(infile,"r"))==NULL) { cout<<"无法打开文件!"<<endl; exit(0); } s=(double)clock(); while(!feof(fp)) { ch=getc(fp); if(ch==' '||ch==10) {//虑空 continue; } if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) //发现一个单词 { K=0; t_word.count=1; while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch=='\'')) { if(ch>='A'&&ch<='Z') ch+=32;//转换成小写 t_word.danci[K++]=ch; ch=getc(fp); } t_word.danci[K++]='\0'; //一个单词结束 j=n; for(i=0;i<j;i++) //与前面的单词比较 { if(strcmp(t_word.danci,word[i].danci)==0) { word[i].count++; break; } } if(n==0||i==j) { word[n]=t_word; n++; } } } f=(double)clock(); cout<<"读文件,分出单词并统计的时间:"<<(f-s)/1000<<"s"<<endl; s=(double)clock(); //输出频率最高的十个单词 sq frequency_max[10]; sq temp; for(i=0;i<10;i++) { frequency_max[i]=word[i];//初始化频率最高的十个单词为前十个单词 } //前十个排序 for(j=0;j<10;j++) for (i=0;i<10-j;i++) if(frequency_max[i].count<frequency_max[i+1].count) { temp=frequency_max[i]; frequency_max[i]=frequency_max[i+1]; frequency_max[i+1]=temp; } for(i=10;i<n;i++) { if(frequency_max[9].count<word[i].count) { int a=8; while(frequency_max[a].count<word[i].count&&a>=0) { a--; } for(j=9;j>a+1;j--) { frequency_max[j]=frequency_max[j-1]; } if(a<0) frequency_max[0]=word[i]; else frequency_max[j]=word[i]; } } f=(double)clock(); cout<<"冒泡排序,搜索频率最高的10个单词的时间:"<<(f-s)<<"ms"<<endl; for(i=0;i<10;i++) { cout<<setiosflags(ios::left)<<setw(10)<<frequency_max[i].danci<<frequency_max[i].count<<endl; } finish=(double)clock(); cout<<"总运行时间:"<<(finish-start)/1000<<"s"<<endl; }
运行截图:
运用结构体数组存储:

运用链表存储:
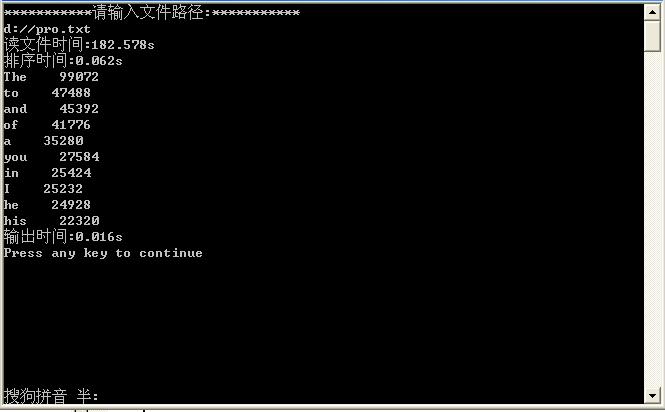
总结:
我用9M的文本文件测试,发现时间主要花费在文件的io上,由上面截图可以看出链表的效率更低,排序的时间非常少,几乎可以忽略不计。IO由于是与硬件之间的操作,所以花费时间比较多,链表由于需要地址操作,效率也没有数组高。