为什么要学习GO语言
- 语法简洁,相比其他语言更容易上手,开发效率更高;
- 自带垃圾回收(GC),不用再手动申请释放内存,能够有效避免 Bug,提高性能;
- 语言层面的并发支持,让你很容易开发出高性能的程序;
- 提供的标准库强大,第三方库也足够丰富,可以拿来即用,提高开发效率;
- 可通过静态编译直接生成一个可执行文件,运行时不依赖其他库,部署方便,可伸缩能力强;
- 提供跨平台支持,很容易编译出跨各个系统平台直接运行的程序。
对比其他语言,Go 的优势也显著。比如 Java 虽然具备垃圾回收功能,但它是解释型语言,需要安装 JVM 虚拟机才能运行;C 语言虽然不用解释,可以直接编译运行,但是它不具备垃圾回收功能,需要开发者自己管理内存的申请和释放,容易出问题。而 Go 语言具备了两者的优势。
如今微服务和云原生已经成为一种趋势,而Go 作为一款高性能的编译型语言,最适合承载落地微服务的实现 ,又容易生成跨平台的可执行文件,相比其他编程语言更容易部署在 Docker 容器中,实现灵活的自动伸缩服务。
总体来看,Go 语言的整体设计理念就是以软件工程为目的的,也就是说它不是为了编程语言本身多么强大而设计,而是为了开发者更好地研发、管理软件工程,一切都是为了开发者着想。
Go开发环境搭建
Go语言SDK下载
SDK安装
SDK目录说明
api:api存放
bin:go的一些可执行文件,类似javac.exe

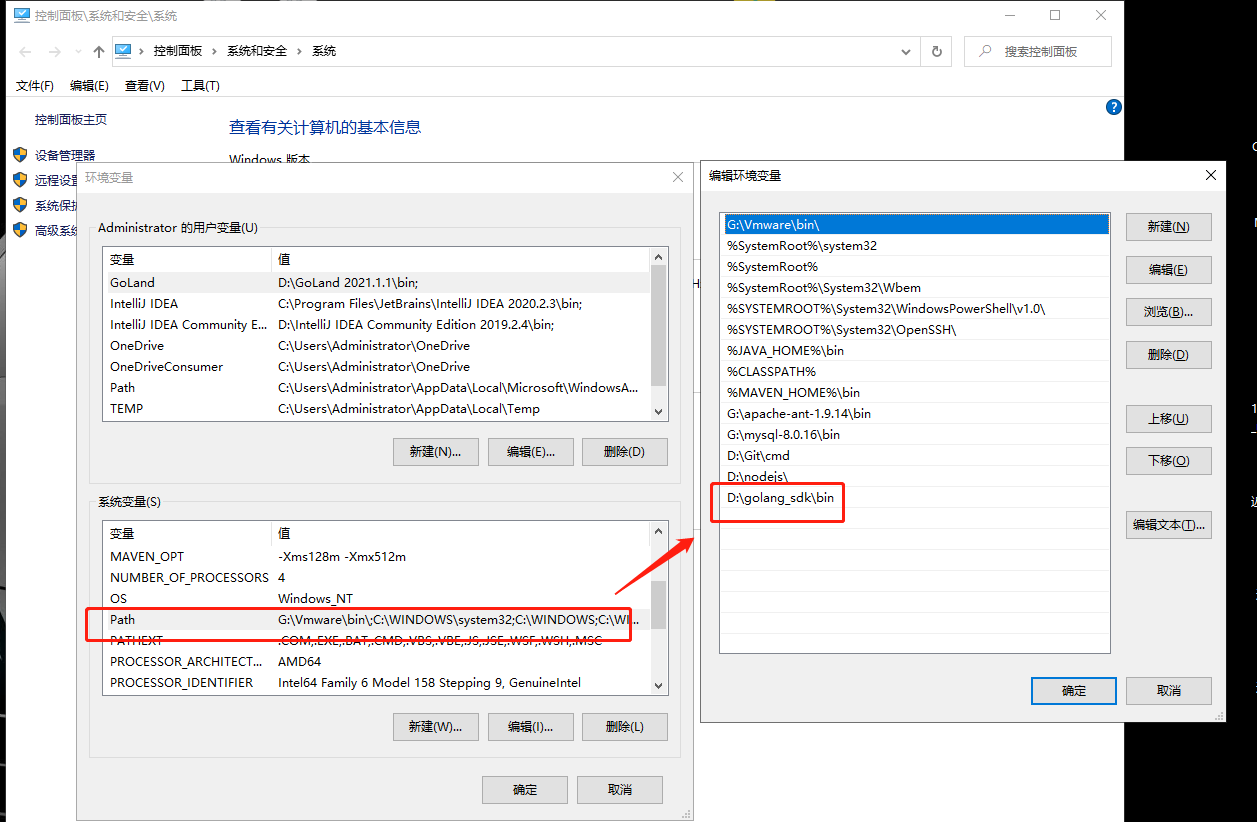
配置环境变量
Go代码编译
go build xxx :仅仅编译 ,会直接生成一个xx.exe可执行文件,直接可以在没有go开发环境的机器行直接运行,相当于把go的环境也一起打包了,牛逼!!!
go run xxx : 编译并执行
进制转换
几进制:就是逢几进1的问题
平时生活中用的最多的是10进制
计算机用的最多的是2进制
二进制转换为10进制
1101 = 1 * 2^3 + 1 * 2^2 + 0 * 2^1 + 1 * 2^0
= 8 + 4 + 1
= 13
变量的声明
//1.变量的声明
var age int
//2.变量赋值
age = 18
//3.变量使用
fmt.Println(age)
//变量的声明和赋值可以在一行
var age2 = 20
fmt.Println(age2)
//数据类型自动推导
var name = "zhangyb02"
fmt.Println(name)
//同时声明多个变量
var (
i = 12
j = 34
)
fmt.Println(i, j)
基础数据类型
- 整数 int int8 int16 int32 int64
- 浮点数 float32 float64
//在Go中,浮点数两种精度,一种是float32,一种是float64,后者的精度更高,计算误差会更小 var f64 = 12.2345667889 - 布尔类型 bool
var isOk = false - 字符串 String
var str = "this code is string type"
零值
零值:即一个变量的默认值
var (
num int
strs string
flo float64
boolean bool
)
这些变量都是默认值
简洁的变量声明方式
nums := 10
boolean2 := false
fl := 123.456
s := "我是字符串"
指针
//指针,&可以获取到一个变量的内存地址,也就是指针,使用*pi的形式可以取到pi的值
pi := &i
fmt.Println(*pi) //打印的是内存地址
fmt.Println(pi) //打印的是内存地址上的值
常量
//常量 const,类似于Java中的final,防止在程序运行期间被恶意篡改
const name3 = "zhangyb02"
fmt.Println(name3)
//iota:常量生成器
const (
one = 1
two = 2
three = 3
)
fmt.Println(one, two, three)
const (
one2 = iota + 1
two2
three2
)
fmt.Println(one2, two2, three2)
highNum := strconv.Itoa(170)
fmt.Println(highNum)
strings工具包
//strings工具包,提供了一系列的字符串操作的方法,比如查找字符串,拆分字符串,判断字符串是否有某个前缀或者后缀等等...
array := strings.Split("1,2,3", "s")
fmt.Println(array)
流程控制语句
//if语句
numi := 10
if numi > 10 {
fmt.Print(">10")
} else {
fmt.Println("<=10")
}
//switch语句,fallthrough可以强制执行下一个case代码。
switch j := 1; j {
case 1:
fmt.Println("1")
fallthrough
case 2:
fmt.Println("2")
fallthrough
case 3:
fmt.Println("没有匹配到...")
fallthrough
default:
fmt.Println("default...")
}
//for循环
sum := 0
for i := 1; i <= 100; i++ {
if i%2 != 0 {
continue //结束本次循环,继续下一轮循环
}
sum += i
}
fmt.Println("the sum is ", sum)
容器
//声明数组 array
arrays := [5]string{"1", "2", "3", "4", "5"}
for index := range arrays {
fmt.Println(arrays[index])
}
//index是对应的下标,val是下标对应的数据
for index, val := range arrays {
fmt.Printf("数组索引:%d,对应的值:%s
", index, val)
}
//如果使用不到下标,则可以使用_下划线丢弃
for _, val := range arrays {
fmt.Println(val)
}
//切片 slice,是一个动态数组,可以动态扩容
//从数组得到切片
slices := [5]string{"0", "1", "2", "3", "4"}
slice := slices[2:5] //新生成的切片,仍然可以认为是一个数组,只不过是一个新的数组
fmt.Println(slice)
//声明切片
//slice1 := make([]string,4) //声明一个元素类型是string,长度为4的切片
//Map 映射,无序,结构为map[key]val,map中所有的key必须具有相同的类型,value也同样,但key和value的类型可以不同
//key的类型必须支持==运算符,这样才可以判断它是否存在,并保证key的唯一
//创建Map的方式一:
//mmp1 := make(map[string]int)
//创建Map的方式二:有初始数据
mmp2 := map[string]int{"zany": 28}
//创建Map的方式三:没有初始数据
mmp3 := map[string]int{}
//map取值
newAge := mmp2["zany"]
fmt.Println(newAge)
newAge2, ok := mmp2["zany2"] //map取值,应该先判断这个值是存在,占位符:OK
if ok {
fmt.Print(newAge2)
} else {
fmt.Println("is not ok")
}
//删除map中的元素
delete(mmp2, "zany")
afterDeleteMapVal, ok := mmp2["zany"]
if ok {
fmt.Println(afterDeleteMapVal)
} else {
fmt.Println("the val is deleted")
}
//遍历map中的元素,注意遍历是无序的
for key, val := range mmp2 {
fmt.Println(key,val)
}