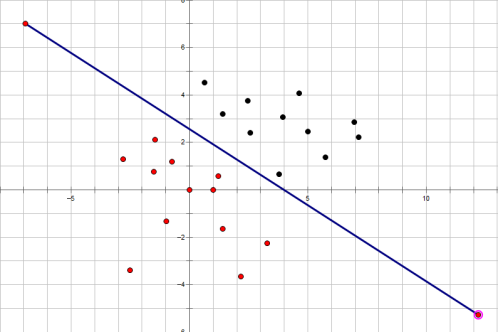
给定一张图片,如何让计算机帮助我们识别它是不是一张猫的图片,这个问题可以看成一个简单的分类问题。如下图所示,平面上有两种不同颜色(黑色,红色)的点,我们要做到就是要找到类似与那条直线那样的界限。当某个点位于直线上方时,那么就可以判定该点是黑色的,当某个点位于直线的下方时,那么就可以判定该点是红色的。
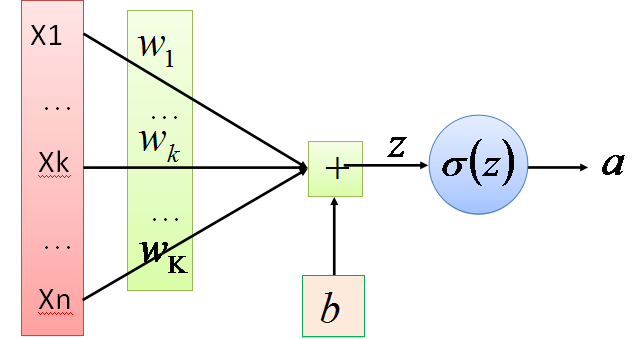
- 正向传播
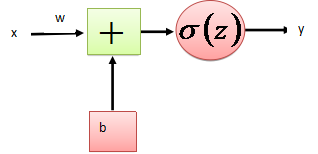
正向传播考虑的是如何得到这条直线的方程,可以先来假定这条直线的函数为,这里的W和b先任意取一个数(可能会很不准确),当我们把x带入里面后会有一个输出y,从图中我们发现当y值越大,那么它就越可能属于黑色点一类,当y值越小,那么它就越有可能属于红色点一类。这种接近程度通常可以用概率来表示,由此引入sigmoid函数:
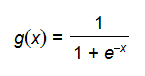
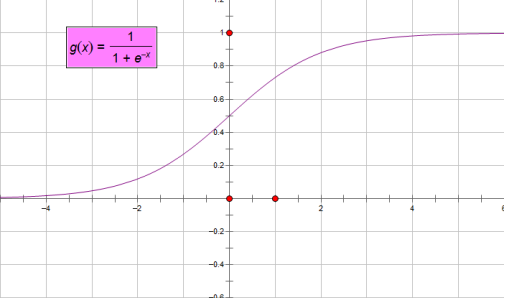
正如图像所示,sigmoid函数的值域为(0,1),定义域为(-∞,+∞)。下面求两个极限
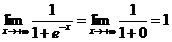
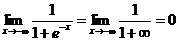
这就意味着无论我们在实数的定义域内取何值,经过sigmoid函数运算后结果都可以收敛于(0,1)之间,而一件事发生的概率取值正好满足此区间。
对于sigmoid函数的理解
令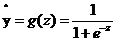 ,
,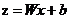 ,当我们输入x后用事先任取的w,b参与运算后会得到一个z值,这个z值越大,就认为这点越接近黑色的点,将z带入sigmoid函数z值越大g(z)的值就越接近1,可以认为该点是黑色的点的概率越接近1。Z值越小,认为这点越接近红色的点(越远离黑色的点),将z带入sigmoid函数z值越小g(z)的值就越接近0,可以认为该点是黑色的点的概率越接近0。
,当我们输入x后用事先任取的w,b参与运算后会得到一个z值,这个z值越大,就认为这点越接近黑色的点,将z带入sigmoid函数z值越大g(z)的值就越接近1,可以认为该点是黑色的点的概率越接近1。Z值越小,认为这点越接近红色的点(越远离黑色的点),将z带入sigmoid函数z值越小g(z)的值就越接近0,可以认为该点是黑色的点的概率越接近0。
- 反向传播
反向传播考虑的是直线的方程准不准,即参数w,b的取值是否合理。利用数据训练的过程实质上就是不断迭代寻找最合适的参数的过程。判断参数准不准,就要用一个偏差来衡量实际输出与真实结果y(真实y取1或0,1表示这点是黑色,0表示这点不是黑色)之间的距离。由此需要来定义损失函数。
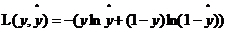
这样定义是为了避免在进行梯度下降法中得到局部最优解(不太理解)。
当y=0时,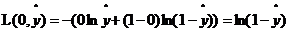 ,如果想让损失函数取值较小即距离越小,那么
,如果想让损失函数取值较小即距离越小,那么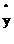 就应该接近0。
就应该接近0。
当y=1时,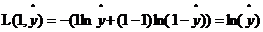 ,如果想让损失函数取值较小即距离越小,那么
,如果想让损失函数取值较小即距离越小,那么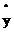 就应该接近1。
就应该接近1。
梯度下降法
梯度的方向是函数变化速度最快的方向,为了使损失函数取到最小值,所以需要使用按照梯度下降的方向来逐步迭代求出函数的最小值。
令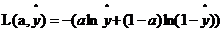
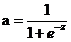
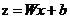
那么由链式求导法有一下关系

得到
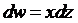
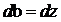
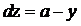
那么更新后的w,b变为
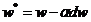
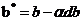
其中α为学习率,需要人为设置。对于更新后的w,b为了达到较好的训练效果,需要再次正向传播得到输出,再进行反向传播缩小差距更新w,b多次迭代。
以上所谈如下图所示仅为一个样本输入一层传播的情况。
对于如下图所示的多个样本输入的一层传播情况,需要将样本数据写成矩阵形式,相应的运算变为矩阵运算。