课程十 应用机器学习的建议
本课时主要讲了在应用机器学习时的一些建议,比如选择什么样的模型,如何解决训练时出现的方差,偏差问题等等。
1、评估假设
评估假设的目的是利用一些算法来评估假设函数,来避免过拟合和欠拟合的问题。前面的课程中我们了解过拟合和欠拟合,所以,当我们训练时,并不是训练误差越小越好,训练误差过小,可能是过拟合,导致训练出的模型无法适应新数据,因此,也就无法仅仅通过判断训练误差来选择假设函数了。因此,我们设计了一种新方法:把数据集分成训练集和测试集,在划分时要注意每一类数据包括各种类型的数据。
通过训练集训练出模型之后,再让其作用于测试集上,然后计算出误差,通过此误差来判断参数选择的是否合适。一般我们计算误差有两种方式:
1.对于线性回归模型,我们利用测试集计算出代价函数J
2.对于逻辑回归模型,我们可以利用测试集来计算代价函数:
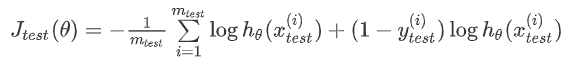
另外还可以对每个测试集样本计算误分类的比率,方法如下:

2、模型选择和交叉验证集
假设我们要在10个不同的次数的二项式模型之间选择:
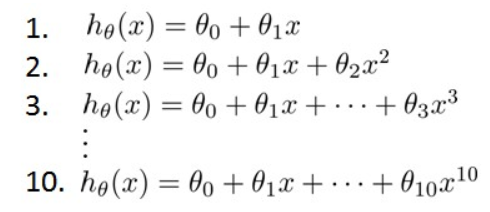
次数越高的多项式越能适应我们的训练集,但是可能会导致过拟合现象,所以要选择一个合适的模型。我们需要使用交叉验证集来帮助选择模型。 即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集。模型选择的方法:
1.使用训练集训练出10个模型
2.用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
3.选取代价函数值最小的模型
4.用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
3.方差和偏差
方差和偏差的问题基本上来说是欠拟合和过拟合的问题。确定是方差还是偏差,对于改进学习算法非常重要。
下图是训练集和交叉验证集的代价函数误差和多项式次数之间的关系图:
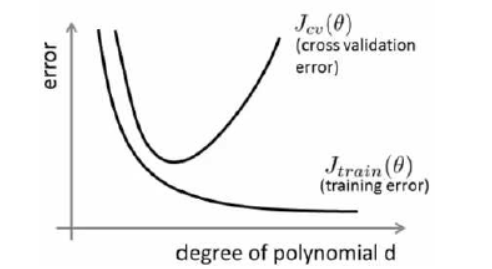
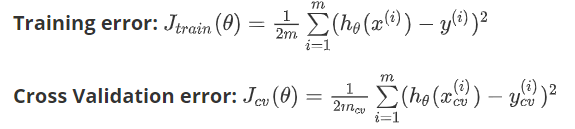
对于训练集,当d较小时,模型拟合度较小,训练误差较大,随着d提高,拟合度升高,误差减小。对于交叉验证集,d偏小时,模型拟合度低,误差较大,当d增大时,模型拟合度提高,误差减小,当d继续增大时,出现过拟合现象,误差又继续增大。
通过上图我们可以发现,当训练集误差和交叉验证集误差接近,并且都比较大时,说明此时是高偏差,属于欠拟合。当训练集误差远远小于交叉验证集误差时,说明此时是高方差,属于过拟合。
4、正则化和方差偏差
正则化可以帮助我们防止过拟合,但是正则化程度太高或者太小,也会出现高方差和高偏差问题。我们选择一系列的想要测试的 值,通常是 0-10之间的呈现2倍关系的值。 我们同样把数据分为训练集、交叉验证集和测试集。

选择的λ方法为:
1.使用训练集训练出12个不同程度正则化的模型
2.用12个模型分别对交叉验证集计算的出交叉验证误差
3.选择得出交叉验证误差最小的模型
4.运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
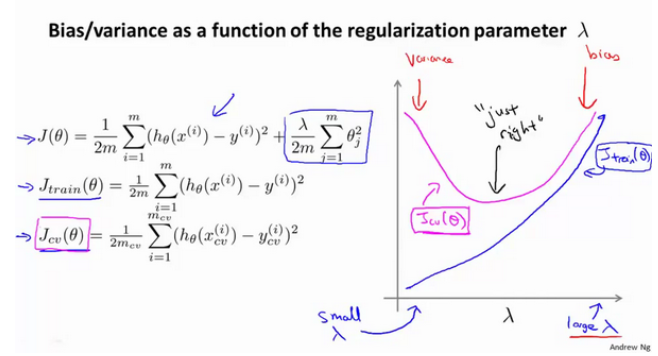
当λ较小时,训练误差小,交叉验证集误差大,过拟合。随着λ的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
5、学习曲线
学习曲线就是一种很好的工具,我们经常使用学习曲线来判断某一个学习算法是否处于偏差、方差问题。学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量(m)的函数绘制的图表。
下面举例如何利用学习曲线判断高偏差(欠拟合)
比如我们尝试用直线来拟合下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观:
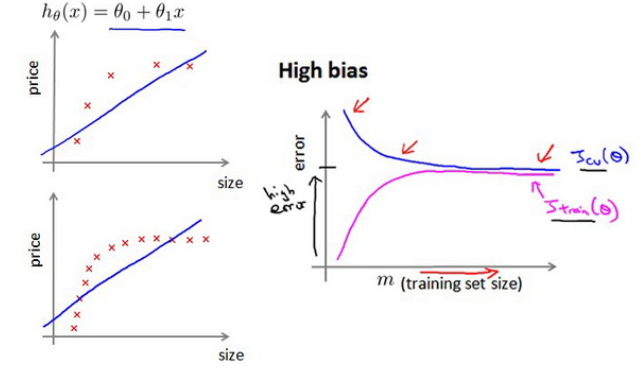
也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。
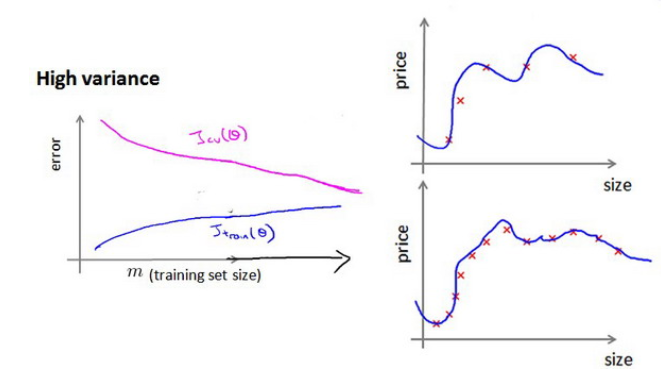
如何利用学习曲线识别高方差/过拟合:假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。
6、决定下一步做什么
利用诊断法来确定如何改进学习算法:
1.获得更多的训练样本——解决高方差
2.尝试减少特征的数量——解决高方差
3.尝试获得更多的特征——解决高偏差
4.尝试增加多项式特征——解决高偏差
5.尝试减少正则化程度λ——解决高偏差
6.尝试增加正则化程度λ——解决高方差
神经网络的方差和偏差:
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小。使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。 通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。 对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络, 然后选择交叉验证集代价最小的神经网络。
以上就是本节课时的内容,这节课我认为主要是帮助我们改善学习算法,如何确定学习算法出现的问题在哪以及解决方法是什么,掌握好这些我认为可以提高我应用机器学习算法的效率。
笔记内容来自“机器学习初学者”网站提供的吴恩达老师的2014机器学习课程笔记http://www.ai-start.com/