原文转自:https://www.cnblogs.com/davidwang456/articles/8693050.html
HtmlUnit使用场景
- httpClient的局限性
对于使用java实现的网页爬虫程序,我们一般可以使用apache的HttpClient组件进行HTML页面信息的获取,HttpClient实现的http请求返回的响应一般是纯文本的document页面,即最原始的html页面。
对于一个静态的html页面来说,使用httpClient足够将我们所需要的信息爬取出来了。但是对于现在越来越多的动态网页来说,更多的数据是通过异步JS代码获取并渲染到的,最开始的html页面是不包含这部分数据的。
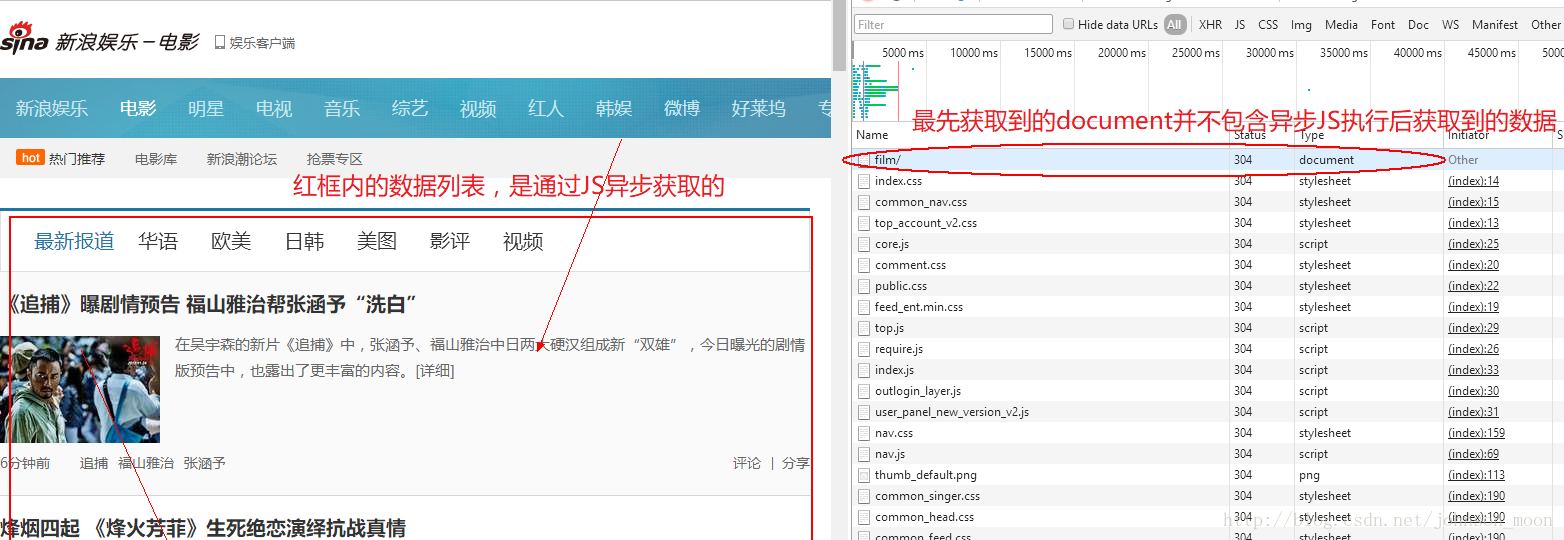
上图我们所见到的网页,在最初的document加载完成之后,并不会看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据,渲染到最初的document页面中,才最终变成了我们看到的网页。而对于这部分需要执行JS代码获取的数据,httpClient就显得无能为力了。虽然我们可以通过研究拿到JS执行的请求路径再用java代码获取我们需要的这部分数据,且不说我们能不能够从JS脚本中分析到这个请求路径和请求参数,光是分析这部分源码的代价就已经很高了。
- HtmlUnit来解决
通过上面的介绍,我们了解了现在很大一部分动态网页,展现的数据都是通过异步JS请求获取,然后再通过JS对页面进行渲染得到的。那我们是不是可以进行这么一个假设,假设我们的爬虫程序模拟了一个浏览器,在获取html页面之后,像浏览器一样执行异步JS代码,等到JS将html页面渲染完成之后,就可以愉快的获取页面上的节点信息了。那么有没有这样的java程序呢?
答案是有的。
HtmlUnit就是这么一个程序库,用来做出了界面展示意外所有的异步工作。由于没有了展示这一块耗时的工作,HtmlUnit加载完成一个完整的网页要比实际的浏览器块多了。并且根据不同配置,HtmlUnit可以模拟市面上常用的浏览器如Chrome、Firefox、IE浏览器等。
通过HtmlUnit库,加载一个完整的Html页面(图片视频除外),然后就可以将其转换成我们常用的字串格式,用其他工具如Jsoup来获取其中的元素了。当然也可以直接在HtmlUnit提供的对象中获取网页元素,甚至是操作如按钮、表单等控件。除了不能像可见浏览器一样用鼠标键盘浏览网页之外,我们可以用HtmlUnit来模拟操作其他的一切操作,像登录网站,撰写博客等等都是可以完成的。当然网页内容爬取是最简单的一个应用了。
HtmlUnit使用方法
1.新建maven工程,添加HtmlUnit依赖:
<dependencies>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.27</version>
</dependency>
</dependencies>- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.新建一个Junit TestCase来尝试一下程序库的使用
程序代码注释如下:
package xuyihao.util.depend;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.junit.Test;
import java.util.List;
/**
* Created by xuyh at 2017/11/6 14:03.
*/
public class HtmlUtilTest {
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
HtmlPage page = null;
try {
page = webClient.getPage("http://ent.sina.com.cn/film/");//尝试加载上面图片例子给出的网页
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);//异步JS执行需要耗时,所以这里线程要阻塞30秒,等待异步JS执行结束
String pageXml = page.asXml();//直接将加载完成的页面转换成xml格式的字符串
//TODO 下面的代码就是对字符串的操作了,常规的爬虫操作,用到了比较好用的Jsoup库
Document document = Jsoup.parse(pageXml);//获取html文档
List<Element> infoListEle = document.getElementById("feedCardContent").getElementsByAttributeValue("class", "feed-card-item");//获取元素节点等
infoListEle.forEach(element -> {
System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").text());
System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").attr("href"));
});
}
}上面的例子将获取到的页面中消息列表的标题和超链接URL打印到控制台,操作HTML文档的库是Jsoup,需要添加依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>- 1
- 2
- 3
- 4
- 5
经过三十秒的等待,控制台输出的结果是这样的:
十一月 06, 2017 2:17:05 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
十一月 06, 2017 2:17:06 下午 com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter runtimeError
严重: runtimeError: message=[An invalid or illegal selector was specified (selector: '*,:x' error: Invalid selector: :x).] sourceName=[http://n.sinaimg.cn/lib/core/core.js] line=[1] lineSource=[null] lineOffset=[0]
十一月 06, 2017 2:17:06 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
2017-11-06 14:17:11.003:INFO::JS executor for com.gargoylesoftware.htmlunit.WebClient@618c5d94: Logging initialized @7179ms to org.eclipse.jetty.util.log.StdErrLog
十一月 06, 2017 2:17:11 下午 com.gargoylesoftware.htmlunit.javascript.host.WebSocket run
严重: WS connect error
java.util.concurrent.ExecutionException: org.eclipse.jetty.websocket.api.UpgradeException: 0 null
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
at com.gargoylesoftware.htmlunit.javascript.host.WebSocket$1.run(WebSocket.java:151)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:672)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:590)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.eclipse.jetty.websocket.api.UpgradeException: 0 null
at org.eclipse.jetty.websocket.client.WebSocketUpgradeRequest.onComplete(WebSocketUpgradeRequest.java:513)
at org.eclipse.jetty.client.ResponseNotifier.notifyComplete(ResponseNotifier.java:193)
at org.eclipse.jetty.client.ResponseNotifier.notifyComplete(ResponseNotifier.java:185)
at org.eclipse.jetty.client.HttpExchange.notifyFailureComplete(HttpExchange.java:269)
at org.eclipse.jetty.client.HttpExchange.abort(HttpExchange.java:240)
at org.eclipse.jetty.client.HttpConversation.abort(HttpConversation.java:141)
at org.eclipse.jetty.client.HttpRequest.abort(HttpRequest.java:748)
at org.eclipse.jetty.client.HttpDestination.abort(HttpDestination.java:444)
at org.eclipse.jetty.client.HttpDestination.failed(HttpDestination.java:224)
at org.eclipse.jetty.client.AbstractConnectionPool$1.failed(AbstractConnectionPool.java:122)
at org.eclipse.jetty.util.Promise$Wrapper.failed(Promise.java:136)
at org.eclipse.jetty.client.HttpClient$1$1.failed(HttpClient.java:588)
at org.eclipse.jetty.client.AbstractHttpClientTransport.connectFailed(AbstractHttpClientTransport.java:154)
at org.eclipse.jetty.client.AbstractHttpClientTransport$ClientSelectorManager.connectionFailed(AbstractHttpClientTransport.java:199)
at org.eclipse.jetty.io.ManagedSelector$Connect.failed(ManagedSelector.java:655)
at org.eclipse.jetty.io.ManagedSelector$Connect.access$1300(ManagedSelector.java:622)
at org.eclipse.jetty.io.ManagedSelector$1.failed(ManagedSelector.java:364)
at org.eclipse.jetty.io.ManagedSelector$CreateEndPoint.run(ManagedSelector.java:604)
... 3 more
Caused by: java.lang.NullPointerException
at org.eclipse.jetty.io.ssl.SslClientConnectionFactory.newConnection(SslClientConnectionFactory.java:59)
at org.eclipse.jetty.client.AbstractHttpClientTransport$ClientSelectorManager.newConnection(AbstractHttpClientTransport.java:191)
at org.eclipse.jetty.io.ManagedSelector.createEndPoint(ManagedSelector.java:420)
at org.eclipse.jetty.io.ManagedSelector.access$1600(ManagedSelector.java:61)
at org.eclipse.jetty.io.ManagedSelector$CreateEndPoint.run(ManagedSelector.java:599)
... 3 more
十一月 06,