前文中已经提到,SVG从诞生之初起就可以非常方便地使用javascript脚本语言来进行其DOM对象的控制。当然,控制的方法有很多,有直接控制SVG对象的方法,例如使用原生js;有帮你封装一下图形接口再进行直接控制的js类库,如 Raphaël。但是正如我在第一篇文章中所说,d3作为一个中间型类库还能脱颖而出的重要原因,在于它突破了其他类库的那种直接控制表现层的机制,而采用了对于web图形处理领域较为新颖的数据驱动机制(2011),并获得了极大的成功。
数据驱动的历史
数据驱动编程并不是一个新鲜玩意,在老书《Unix编程艺术》中,作者在介绍Unix设计原则时,其中有一条为“表示原则:把知识叠入数据以求逻辑质朴而健壮”。其核心出发点是相对于程序逻辑,人类更擅长于处理数据。数据比程序逻辑更容易驾驭,所以我们应该尽可能的将设计的复杂度从程序代码转移至数据。这条原则早在70年代的软件危机中就得到了印证:凡是执着于逻辑实现的代码最终都难以维护,而将逻辑变化沉淀到数据集中的程序,则撑过了时间的检验。在web开发领域流行20多年的MVC架构,核心也是将数据、表现、操作分离从而降低程序复杂度。JAVA社区多年来就程序设计领域的讨论,翻来覆去也离不开数据驱动这个原则。
然而,web前端,尤其是图形图像处理领域,长期以来人们的关注点集中在图形渲染API,设计诸如var circle = paper.circle(50, 40 ,10)这样的图形呈现接口。对图形元素的使用,也长期停留在使用程序直接控制的状态。当然,如果交互逻辑少,即使图形略微复杂,这么做并非不可以。但是在创造交互逻辑复杂的数据可视化项目时,这种做法的代码复杂度会随着交互逻辑的规模指数上升,并带来许多意料之外的程序冲突——这一切与MVC之前的web开发领域或者70年代的软件危机原因如出一辙。有识之士很早就意料到这种问题,于是在web端图形处理的基础渲染技术已经渐渐完善的2011年,D3js诞生,并迅速在数据可视化领域和web图形渲染领域掀起了旋风。
对D3数据转换的理解
用官网上的原文说,它注重的是是转化而不是表现(Transformation, not Representation)。d3不是一个新的图形呈现类库。不像 Processing, Raphaël, 或者 Protovis这类类库,D3不注重对图形呈现接口的封装,而是使用web标准的HTML, SVG和CSS来处理表现层。这意味着如果哪一天浏览器支持了新的图形渲染特性,那么你就可以立即用上,而不需要在代码层有什么特殊的修改。D3将重点放在了数据与图形之间的绑定上。数据一般是json格式的对象,也可以是xml;而图形不仅包括SVG对象,也可以是html对象,或者其他浏览器所支持的图形对象。总之,同一组数据,你可以使用D3来创建一个HTML table,也可以创建一个SVG柱状图。
那么,D3是如何将数据与DOM节点之间绑定的呢?
第一步,是要选中DOM对象以构建选择区(selection)。 选中DOM对象的方式跟Jquery如出一辙,都是使用类似CSS选择器的语法,例如选中一组css类名为my-node的div节点并使之文字为白色:
|
1
|
d3.selectAll("div.my-node").style("color", "white");
|
第二步,就是将数据集绑定到选择区(selection)的DOM对象上。D3的提供一个十分有用的data函数,用以进行数据对象序列化和可能的预处理工作(详见API),并且它会把集合元素一个一个返回用以进行下一步处理。例如下面这个例子:
|
1
2
3
|
d3.selectAll("p")
.data([4, 8, 15, 16, 23, 42])
.style("font-size", function(d) { return d + "px"; });
|
在这个例子中,选择区(selection)中的每个P标签都与数据中的一个数字按顺序一一对应地绑定起来(我们假设P标签的个数与数组长度相等)。这样最后回调函数中,就可以取回被绑定的数据,从而动态地计算每个P标签中文字大小。熟悉jquery或者prototype类库的程序员都能很容易地发现他们之间的共相似之处,尤其是通过回调函数的方式来实现对一个集合中每个元素进行操作。
上面这个例子看起来很简单很容易理解。但是其中影藏一个重大的问题,就是数据集是经常变化的,一旦变化,那么数据集中的每个数据对象和选择区(selection)中的DOM对象不再一一对应了,那么多余的数据或者多余的dom对象该怎么处理呢?
为此,D3专门提供了一个enter, update, exit三个行为的数据集合(data)与选择区(selection)绑定的机制。要理解这个机制,最好还是得看图看例子,要不然不容易理解。这有一个d3的简单教程可以下载。下面这个图就是从该教程中摘出的D3数据绑定机制示意图,其解释如下:
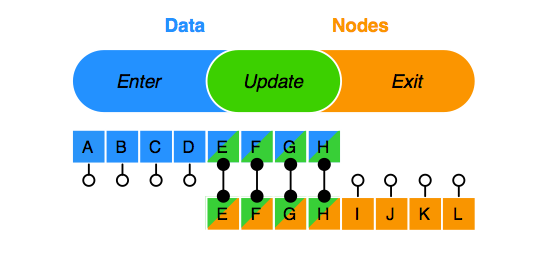
- 数据集(data)和选择区(selection)中的对象应该是一一对应地绑定的。绑定的数据,一旦发生变化都会反映给对应的dom对象,这叫做update过程。
- 如果数据数量大于节点的数量,那么有一部分数据放不下了,将产生enter过程。
- 反之,如果数据从节点中取出来,导致节点空闲,这就发生exit的过程。
以上update, enter, exit三个过程,你都可以进行一系列自己特别定制。例如,通过ajax获取数据,初始化图形时,你可以通过定制enter过程来实现渐变地显示图形;在用户点击一个图形对象时,通过改变该图形对象所对应的数据数值,然后通过update过程来同时修改图形对象;当要删除某个图形对象时,触发exit过程,来实现渐隐的效果。于是,我们看到github上大量d3例子的代码,都类似如下分成三大块:update, enter, exit…
|
1
2
3
4
5
6
7
8
9
10
11
|
// Update…
var p = d3.select("body").selectAll("p")
.data([4, 8, 15, 16, 23, 42])
.text(String);
// Enter…
p.enter().append("p")
.text(String);
// Exit…
p.exit().remove();
|
多说无用,我们还是来看具体的代码吧。我根据上文提到的教程中的案例创建了一个在线的例子:http://runjs.cn/detail/8enw0npq,在这里大家可以直接看到代码,我这里就不赘述了。大家可以看看d3的数据绑定机制究竟如何,enter, update, exit过程都是怎么工作的。
<iframe style=” 100%; height: 300px” src=”http://sandbox.runjs.cn/show/8enw0npq” allowfullscreen=”allowfullscreen” frameborder=”0″></iframe>

反思学习历程
就我的面试经验,国内的前端程序员大多数都是从jquery开始学javascript的。那么想必看完上面的代码,大家都会觉得跟jquery非常像,链式编程的风格,回调函数,很容易理解。
但为什么还说D3的学习曲线比较高呢?这是因为一般只看完一两个github上的D3 demo,没有专门的讲解,普通程序员还是难以彻底理解D3的那种以数据(以及容纳数据的容器)为核心的思路。至少我当初就没一下子搞明白为什么要搞update, enter, exit这么三个过程。这是因为常规的思维,对于图形操作,首先都把注意力集中在图形本身上。例如,一个通常的jquery程序员,遇到一个需求:在点击一个图形后将图形变大一倍同时把数据更新为原来的2倍。他通常都是这么构思整个流程的:先选中图形对象,改变图形,然后更新数据(或者先更新数据再改变图形)。虽然这样想逻辑很简单,但这样做无疑将数据和图形孤立了起来。如果这个图形还绑定了很多别的交互,数据集又很复杂,那么就会经常遇到顾头不顾腚的维护难题。D3处理交互逻辑时,通常是先通过图形对象找到数据,之后改变数据,最后再update更新图形对象。似乎转了一个圈才最后返回到图形本身,比起直接操作图形要麻烦。但是这里才是D3的精华所在。只有把复杂逻辑沉淀到数据上,才能在复杂交互的情况下保持代码的清晰性。
当然,如果你只是为了画几个图,并没有太多复杂交互,我认为D3就没多少优势了。有很多用jquery的chart插件实现的简单图表,并不比D3实现类似的案例多多少代码量,也能收到很好的效果。所以我以为D3的主要用武之地还是在进行较为复杂的交互式可视化项目开发时。而且,一旦理解了D3的数据驱动模式,思路就会广阔许多。将它与backbone,angularjs,ember.js等框架一做比较,确实地感到,所谓前端开发革命的浪潮,就是从数据驱动开始。