前言:
都知道,小编前面已经简单介绍过在windows下hadoop和hive环境搭建和基本使用。这次的Spark有点突兀,但是也可以先忽略,重要的是先在IDEA中安装bigData插件连接hadoop已经HDFS,而后再简单介绍使用Spark操作Hive。
Big Data Tools安装:
1. 点击File, 选择Settings,再选择Plugins搜索Big Data Tools,最后下载安装。
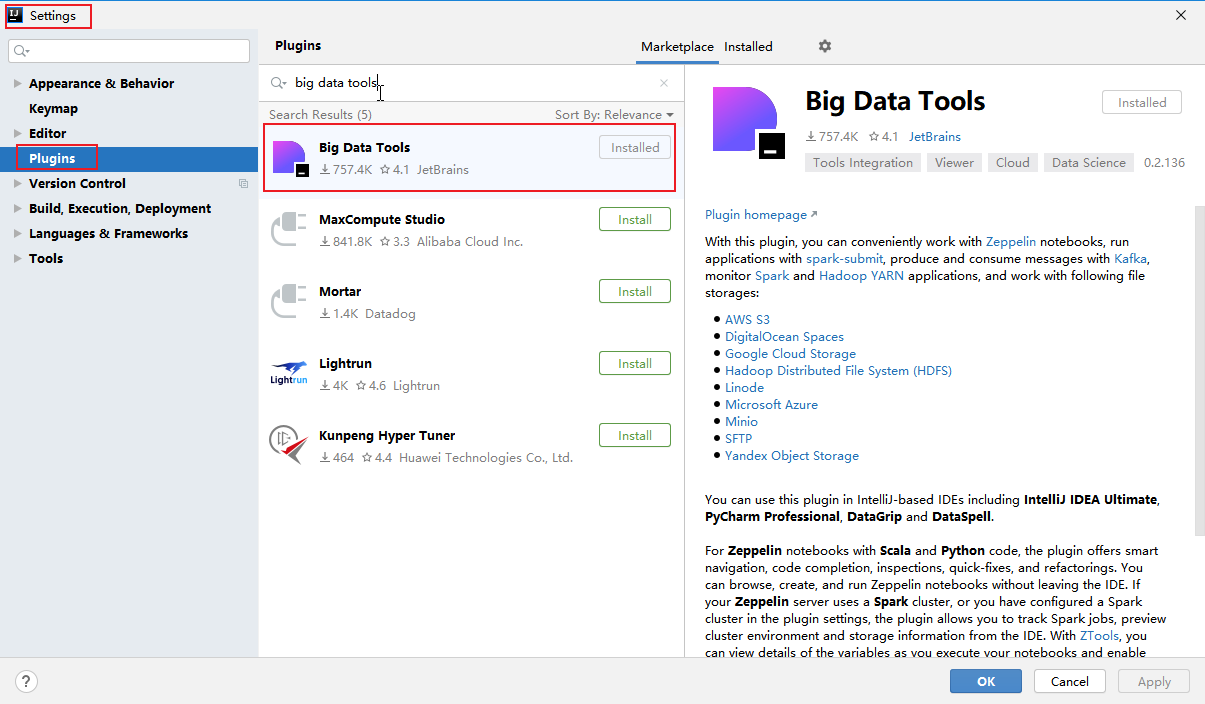
2. 下载完毕后,底部和右侧栏会多出Hadoop或Big Data Tools的选项。
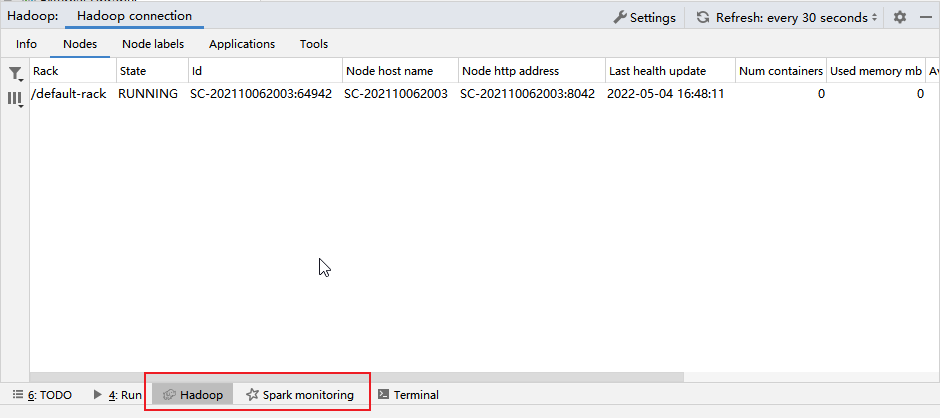
连接方法:
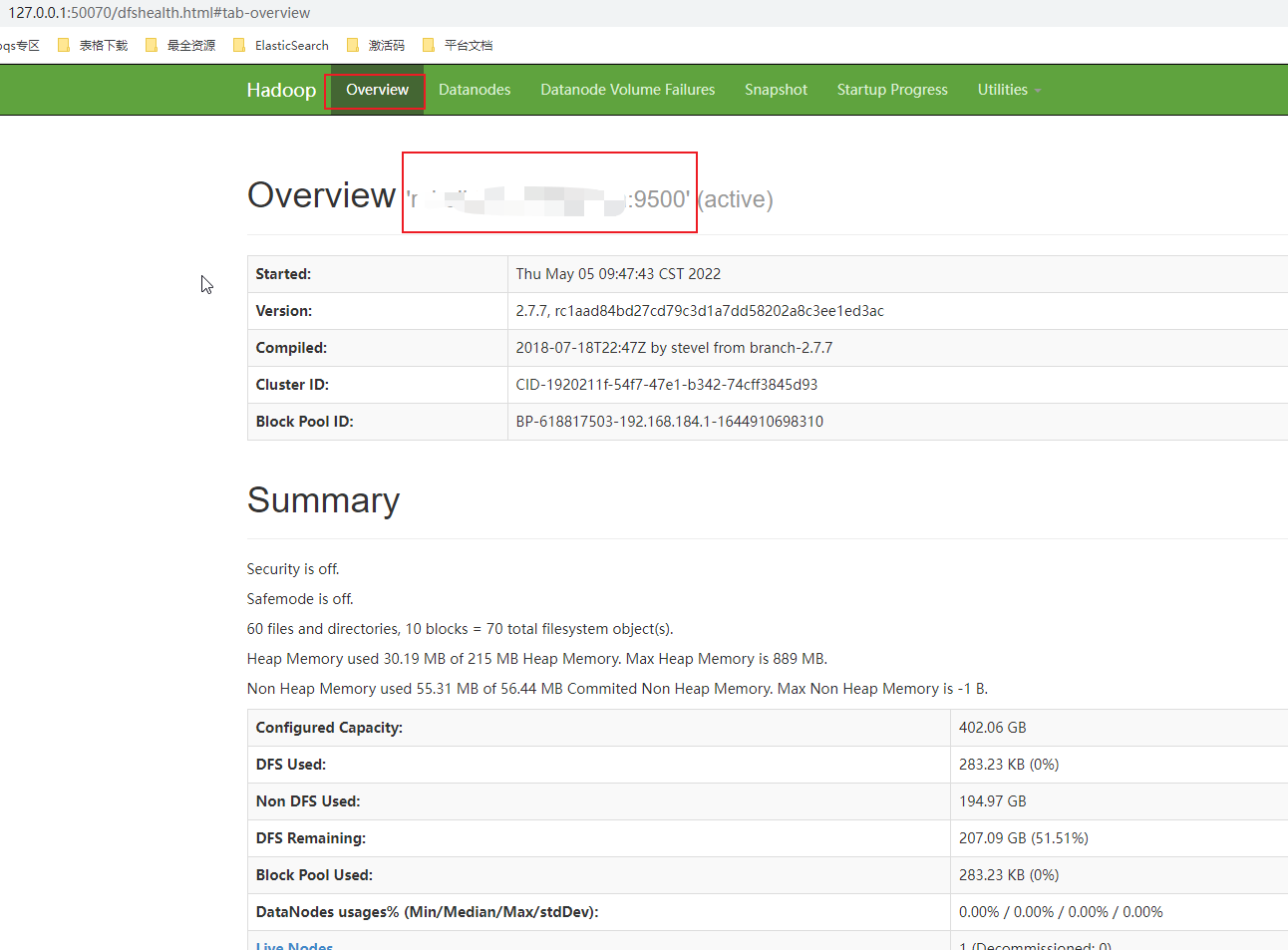
1. 进入hadoop的sbin目录,start-all启动成功,打开web控制台127.0.0.1:50070(默认),记住如下标志的节点地址,后面hdfs连接的就是这个。
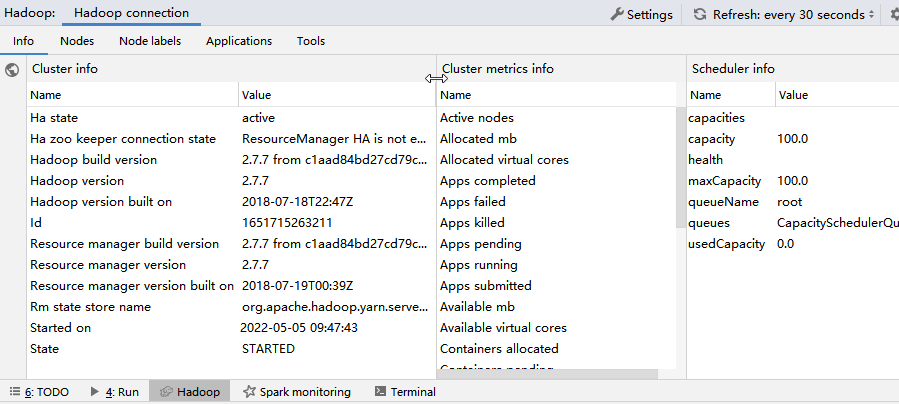
2. 只要hadoop启动成功后,打开IDEA的hadoop其实就可以正常自动连接了。
3. 或者打开右侧栏的Big Data Tools,添加一个连接,Hadoop。
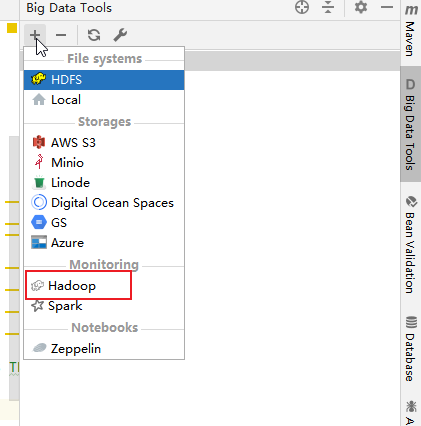
4. 连接Hdfs。
(1). 点击右侧栏Big Data Tools新增Hdfs。
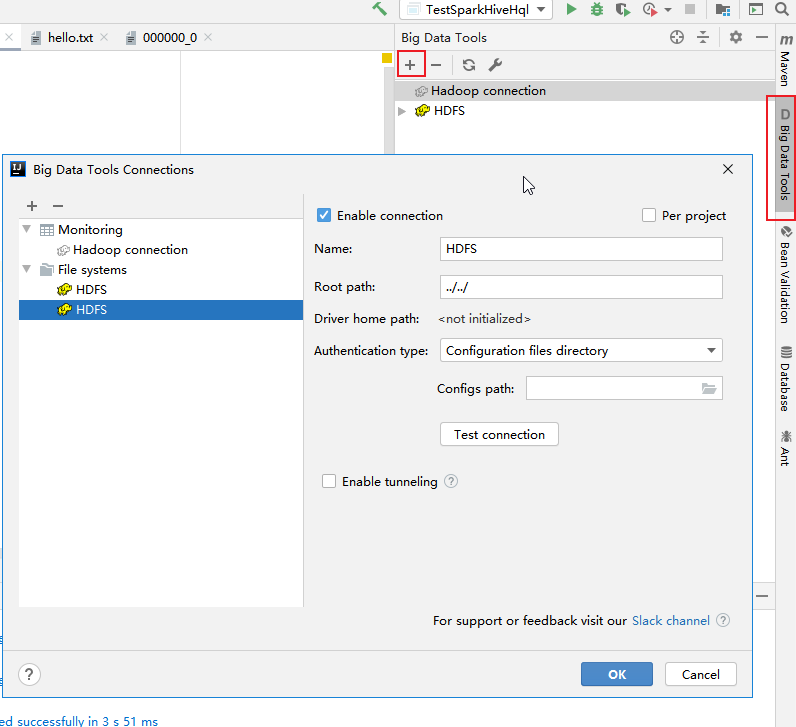
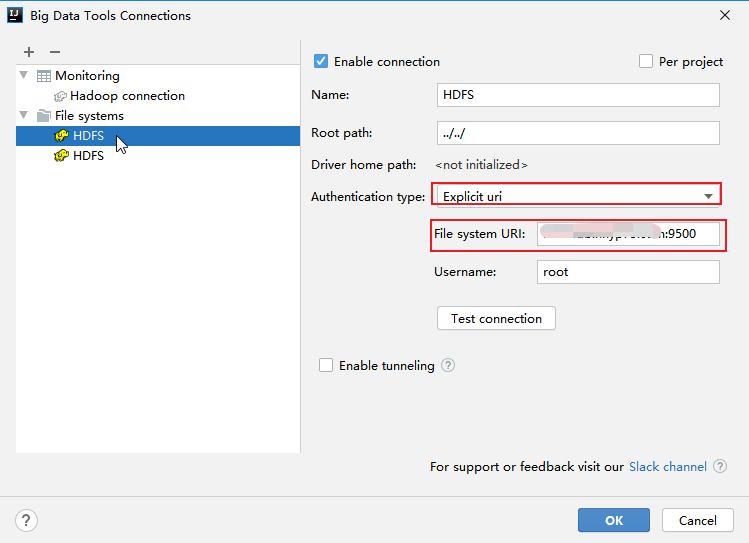
(2). 重要的就是Authentication type,选择Explicit uri。File system URI填写的就是上面控制台的节点地址。
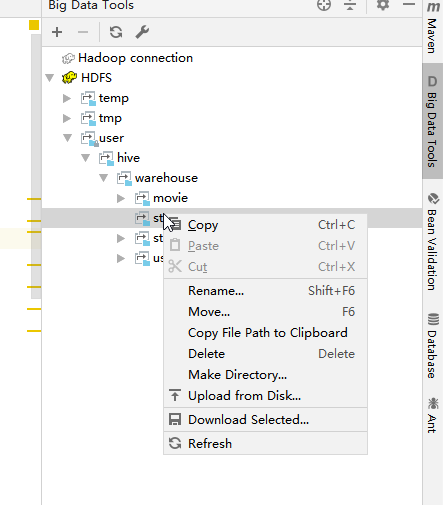
(3). 连接成功后就可以清晰的看到HDFS的目录,并且可以创建,删除和上传。不过需要对指定路径授权。
Hive操作:
关于操作Hive, 以下基于Maven构建Scala项目。项目创建和Hive就略过了,好像在Kafka一文中介绍过如何新建Maven的Scala,而Hive的产品还是原理介绍网上比较多,以下主要是小编的日志式记录,所以以过程居多,那么就开始了。
1. pom.xml添加如下依赖并安装(其实是我整个文件,不需要的可以根据注释删除)。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>maven_scala_test</artifactId>
<version>1.0-SNAPSHOT</version>
<name>${project.artifactId}</name>
<description>My wonderfull scala app</description>
<inceptionYear>2015</inceptionYear>
<licenses>
<license>
<name>My License</name>
<url>http://....</url>
<distribution>repo</distribution>
</license>
</licenses>
<properties>
<maven.compiler.source>1.6</maven.compiler.source>
<maven.compiler.target>1.6</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.5</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<spark.version>2.2.0</spark.version>
<hadoop.version>2.6.0</hadoop.version>
<hbase.version>1.2.0</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<!-- <scope>test</scope>-->
</dependency>
<dependency>
<groupId>org.specs2</groupId>
<artifactId>specs2-core_${scala.compat.version}</artifactId>
<version>2.4.16</version>
<!-- <scope>test</scope>-->
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.compat.version}</artifactId>
<version>2.2.4</version>
<!-- <scope>test</scope>-->
</dependency>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</