作者
Conor Walsh is a software engineering intern with the Architecture Team of Intel’s Network Platform Group (NPG), based in Intel Shannon (Ireland).
引言
高速包处理是一种资源密集型应用。一种解决方案是将包处理流水线(pipeline)分离到多线程以提高程序性能。
然而,这样做可能增加缓存(Cache)和内存(Memory)访问的压力。
因此,构建高性能应用程序的关键在于尽可能减少数据面流量(data plane traffic)相关的内存占用(memory footprint)。
本文介绍了一种多线程包处理应用程序的内存优化技术,提高访存密集型应用的性能。
即使应用程序没有内存受限的情况,也应该减少内存需求。
参考程序
本文基于对源自Intel的vCMT系统的研究。
vCMTS是基于DOCSIS3.1标准和DPDK包处理框架实现的MAC层数据面流水线程序。
该程序是为了测试Intel至强平台vCMTS数据平面包处理性能及功耗开发的工具。
可以从0.1org的the Access Network Dataplanes下载vCMTS。
虽然本文测试的vCTMS基于DPDK 18.08版本,但是背后的原理可以应用到早期版本的DPDK或者其他包处理库,比如Cisco的VPP。
本文用到的一些功能在DPDK 16.07.2首次引入。
vCMTS的下行(downstream)部分采用了多线程流水线设计。
流水线分为上/下MAC两部分,分别运行于两个不同的线程。而且这两个线程必须运行于同一个物理核心的2个超线程上,否则会浪费L2 Cache的效率。
参见图1 vCMTS下行包处理流水线

图1 vCMTS下行上/下MAC流水线
目前vCMTS的上行部分没有使用多线程模型。本文主要关注下行部分作为参考。
Ring VS Stack
DPDK用mbuf存储包数据。mbuf存在名为mempool的内存池结构中。
默认情况下,mempool创建内存池时使用的是类似于先进先出(FIFO)系统的环形(ring)配置。
该模型适合运行于多核心多线程的应用。
但是对于多个线程运行在同一个核心的情况,这种模型会浪费内存带宽,部分超线程性能也会无法发挥。
对于多个线程在同一个核心的应用,环形内存池结束循环的时候会遍历全部的mbuf。
当mbuf的数量比较多的时候(比如vCMTS),几乎每次访问分配好的mbuf的时候都会发生Cache Miss.
除了环形内存池,DPDK也提供后入先出(LIFO)的栈结构的内存池配置。
mempool包含mempool的Cache,允许回收“热"缓存(warm buffer, 理解为最近使用过的buffer),当buffer在同一个线程分配/释放时,可以提供更好的缓存性能。
一般都是通过配置mempool采用LIFO配置提升mempool cache的性能。
每个DPDK线程的每个mempool都拥有自己的mempool cache.
在一个线程收包,另一个线程发包的情况下,mbuf不会在同一个线程分配/释放,也就是上述导致内存池cache冗余(两个线程,两个mempool,两个mempool的cache)的例子。
采用环形内存池模型时buffer的移动方式(见图2):
- 应用程序从线程0的mempool cache中取出mbuf给网卡接收队列
- mbuf不会在线程0上释放,所以mempool cache会直接从mempool中取mbuf。
- 程序从mempool的cache中分配mbuf
- 当mbuf从网卡发送部分释放时,缓存于线程1上的mempool cache中
- 当线程1的mempool满了,程序会开始把mbuf返还到线程0的mempool中
对这个程序来说,这是一个糟糕的模型,因为线程0的mempool cache一直包含的是'冷'的mbuf,而线程1的mempool cache一直是满的
如果mempool很大,CPU将无法把整个mempool的内容保持在Cache里,需要刷到内存中。
在这个模型里,程序会高速循环整个mempool,并由于mbuf频繁进出Cache导致大量占用内存带宽。
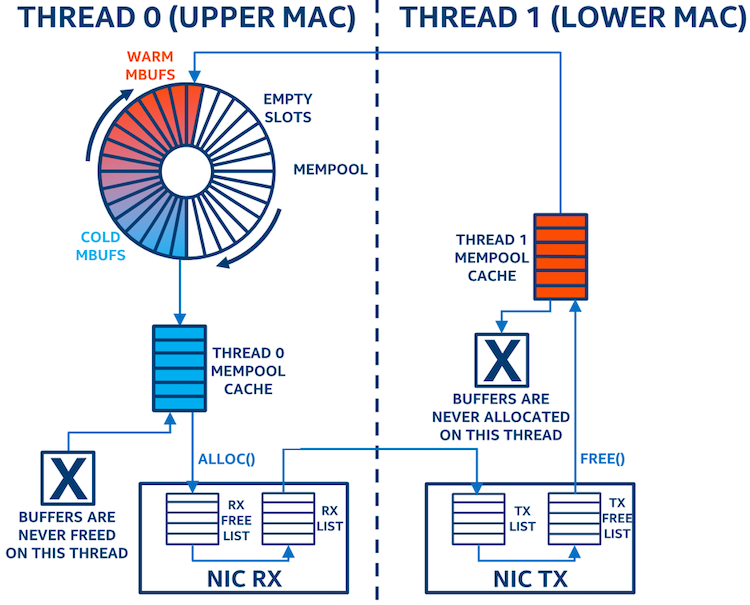
图2: 采用环形内存池时buffer的移动路径
采用栈形内存池模型时buffer移动方式(见图3):
- 程序从mempool中分配mbuf给网卡接收队列
- 当mbuf从发送网卡释放时返还给mempool
这个模型的效率更高。mempool改为使用stack实现,禁用了冗余的mempool cache。mbuf直接从mempool分配,释放后直接回到mempool,不再由线程1缓存。
注意,从stack mempool分配/释放mbuf代价可能略微更高,因为多线程访问时需要锁住mempool。
锁保护的负面影响很小,因为这些锁是绑定在同一个核心上的。(如果这些线程运行在不同的物理核心上,锁的代价会很大)
总体来说,把'热'mbuf利用起来的好处要大过比额外的锁开销。
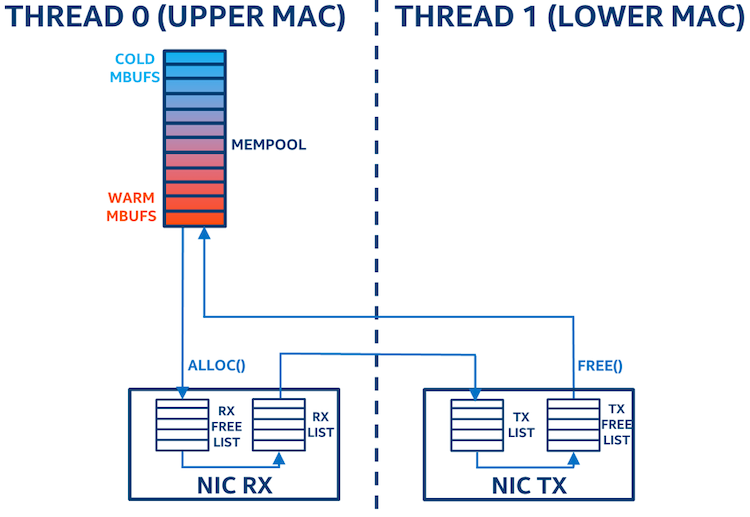
图3: 采用stack内存池时buffer移动方式
另一种减少环形mempool内存占用的方法是减少mempool中mbuf的数量。
分析显示对于vCMTS来说,大部分时候会用到750个mbuf,但是偶尔会升至20000个mbuf.
这意味着减少mempool的大小的方式不适合,因为极端情况下mbuf的需求量和一般情况下多出几个数量级。
如果那些mbuf分配不到,程序的性能无法预测。
采用stack模型的mempool时,CPU会尽可能把程序请求的大多数mbuf保持在Cache中,只有其中少部分会被刷到内存里。
因为在大部分情况下,重复使用的是相同的mbuf,因此极大减少了内存带宽占用。
程序采用stack模型的mempool后,CPU可以把大部分mbuf保持在Cache中,少部分需要刷到内存上。由于只有很少的mbuf在常见操作时反复使用,极大的减少了内存带宽占用
结论
It is clear that across all four tests, the drop in memory bandwidth due to the change from ring to stack was significant. The average drop across the four tests was 76%. A key benefit of this is, when high traffic rates are run, the data-plane cores are less likely to approach memory bandwidth saturation, which could degrade performance. In this case, a direct performance benefit can be achieved using stack mempool configuration for dual-threaded packet processing applications, as it reduces memory bandwidth utilization and improves the traffic rate at which memory bandwidth gets saturated. Another benefit of this change is the availability of more memory bandwidth for other applications running on the same socket. This modification should require minimal code changes to the application, so the effort would be worth the reward for this change2.
Resources
Maximizing the Performance of DOCSIS 3 0/3 1 Processing on Intel® Xeon® Processors
Endnotes
1 This model is more streamlined for the dual sibling hyper-threaded case; it was not tested in a scenario where the threads spanned multiple cores.
2 When vCMTS is changed to stack the system should not have to be populated with as many DIMMs of memory due to the reduced memory bandwidth and this would result in a power saving of roughly seven watts per DIMM. This claim was not verified as part of this paper but it could be a possible way to gain power savings from switching to a stack configuration.