CNN到底什么呢,看了很多,还是有点恍恍惚惚,所以决定还是概念和公式走起,慢慢学习!
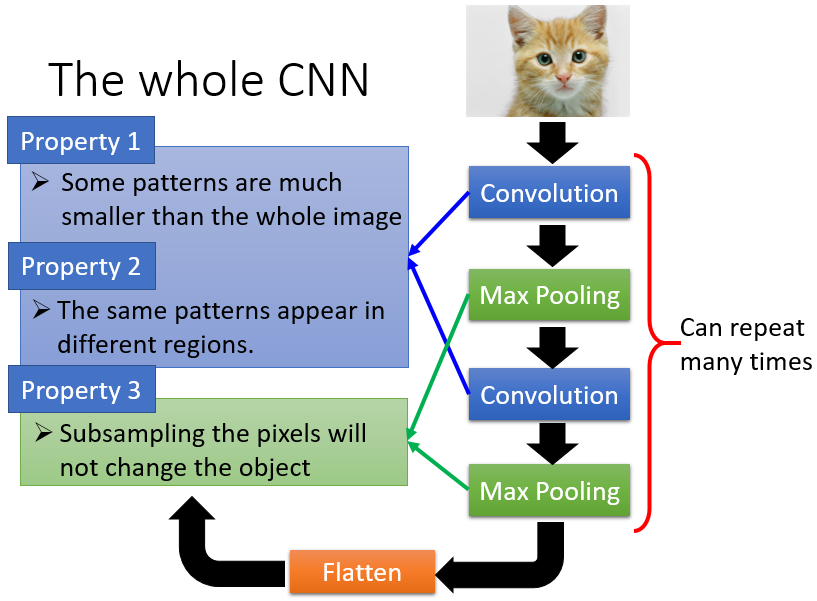
The whole CNN
卷积的整个流程可以从下图可以瞧见出: (下图是个彩色图片)
Why CNN for Image
Property:(1)Some patterns are much smaller than the whole image.
Property:(2)The same patterns appear in different regions.
Property:(3)Subsampling the pixels will not change the object.
其中,(1)和(2)用Convolution实现,后面(3)用Max Pooling实现
1、卷积----Convolution
每一个卷积核(kernel)相当于fully connected layer里面的一个neuron,这个Matrix中每一个值和neuron的weight、bias一样是network的parameters是要learn出来的
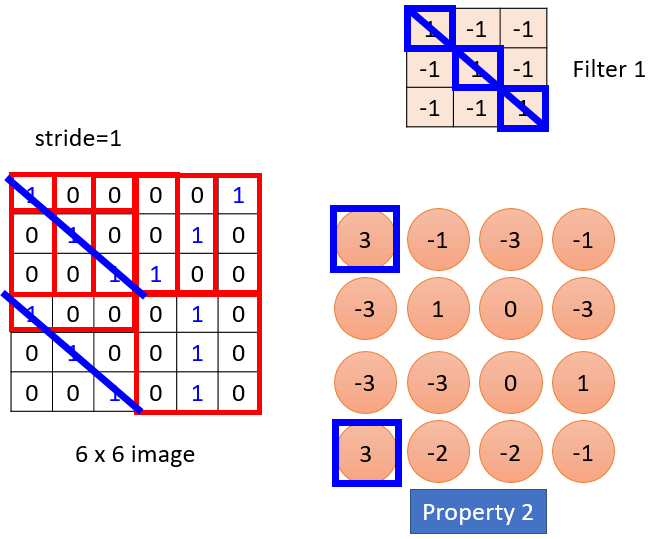
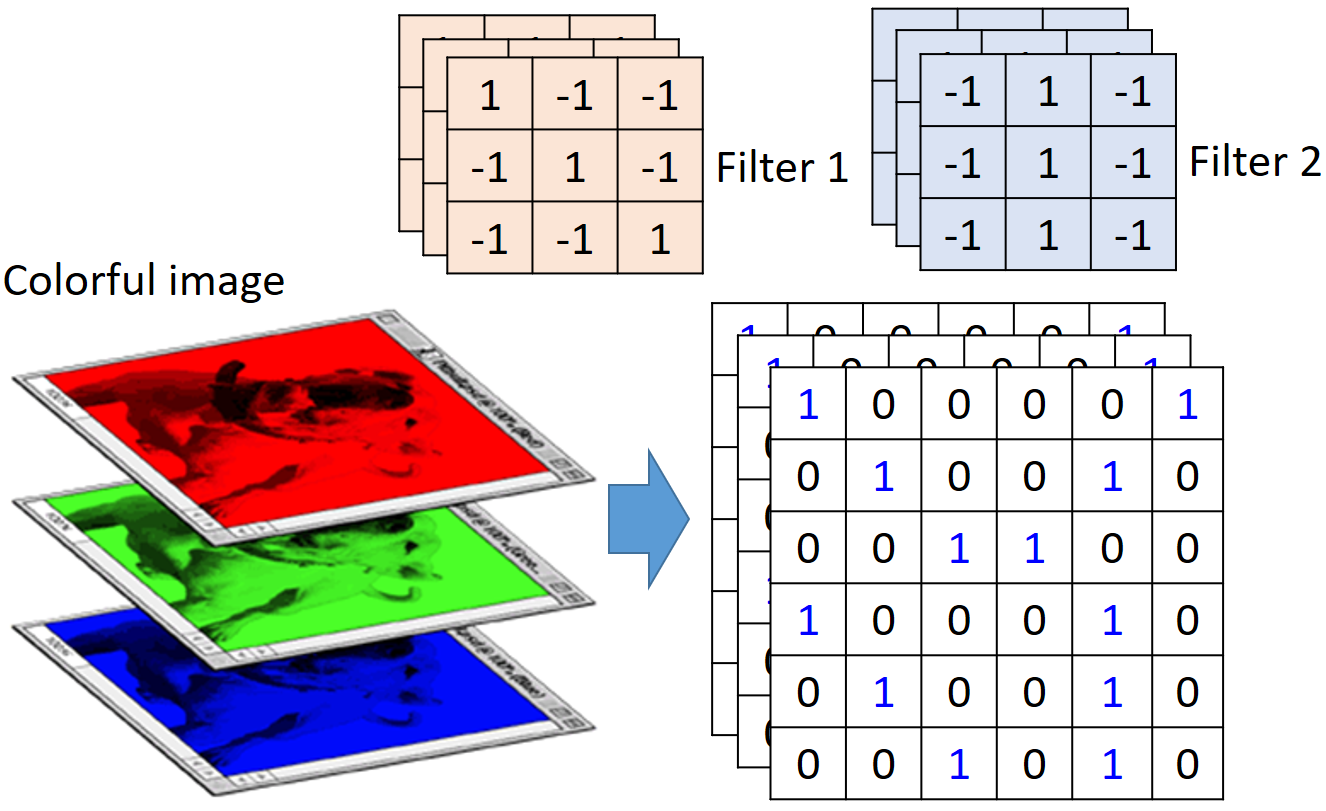
如下是一个3*3的filter,等同于说它是在侦测图片中出现斜对角线全为“1”的特征有没有出现在这个image里,不看整张图片的前提下。
这个就验证了Property(2):The same patterns appear in different regions. 即一个filter可以检测same patterns ,whatever 它出现在image的哪个region里(下图是黑白图片,单通道)
卷积层是一组平行的特征图即是feature map。它通过输入图像上滑动不同的卷积核并运行一定的运算所组成。直白地说,卷积核就是线性滤波器。
1.1 operation
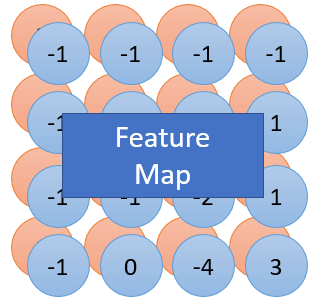
在每一个滑动的位置上,卷积核与输入图像之间会运行一个元对应乘积并求和的运算已将感受内的信息投影到特征图中的一个元素中,通俗而言就是计算它的邻域像素和滤波器矩阵的对应元素的乘积,然后加起来,作为该像素位置的值,这样就完成了滤波的过程。(inner product)
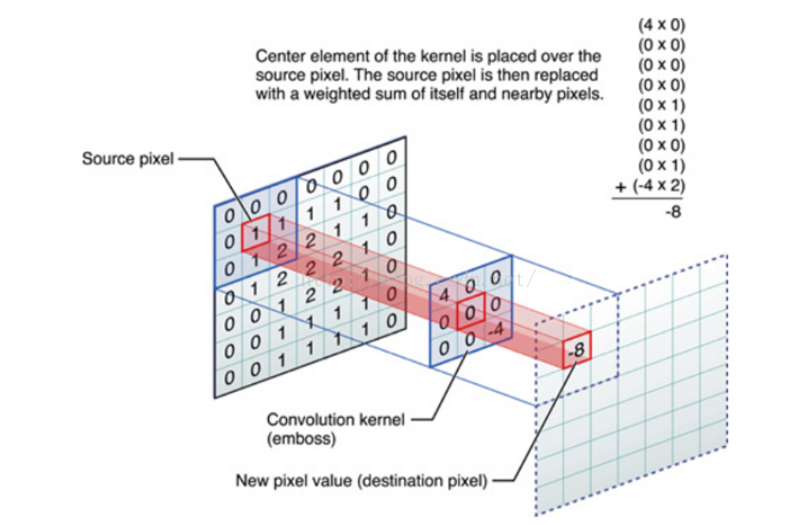
这一滑动的过程可称之stride,设为步幅Z_s,步幅Z_s是控制输入特征图尺寸的一个因素,卷积核的尺寸要比输入图像小得多,且重复和平行地作用于输入图像中,一张特征图中的所有元素都是通过一个卷积核计算得出的即一张特征图共享了相同的权重和偏置项。
1.2 RGB图片
一个彩色的image就是好几个图层叠在一起即为一个立方体,那么卷积核(filter)也是一个立方体,如下图,此时input是3*6*6,filter是3*3*3
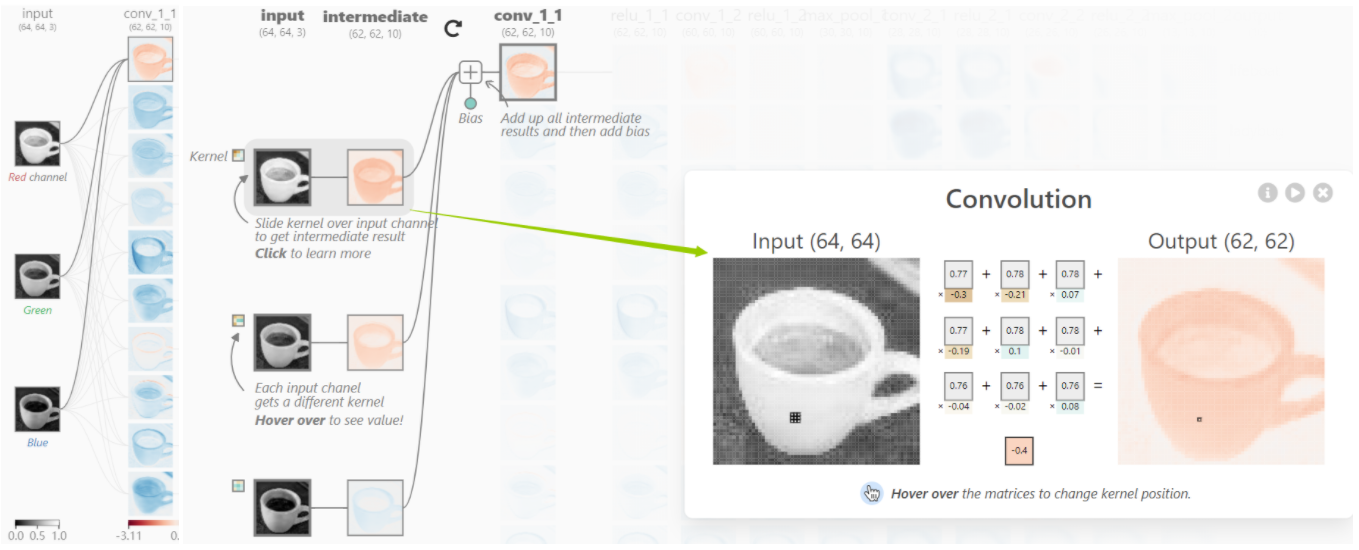
上图中,输入图像的在卷积核的作用下结果为-0.42,最终输入图像在这个卷积核的作用下,把图片转换成了右边橘色茶杯的效果。
图片一般RGB三个颜色通道
注意点:如果同一个pattern的size不一样 ,那么filter是不好识别的,因为你不好设置卷积核的size
2、线性整流层
线性整流层(Rectified Linear Units layer, ReLu layer)使用线性整流(Rectified Linear Units, ReLU)$f(x)=max(0,x)$作为这一层神经的激励函数(Activation function)。它可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层。
事实上,其他的一些函数也可以用于增强网络的非线性特性,如双曲正切函数$f(x)=tanh(x),f(x)=|tanh(x)|$,或者Sigmoid函数$f(x)=(1+e^{-x})^{-1}$,相比与其他函数来说,ReLU函数更受青睐,这是在于它可以将神经网络的训练速度提升数倍,而不会对模型的繁华准确度造成显著影响。
3、池化层
池化(Pooling)采用一种非线性形式的降采样,有多种不同形式的非线性池化函数,
这种机制能够有效地原因在于,一个特征的精确位置远不及它相对于其他特征的粗略位重要,池化层会不断减小数据的空间大小,因此参数的数量和计算量也会下降,这一定程度上也控制了过拟合。通常来说,CNN的网络结构中的卷积层之间都会周期性地插入池化层。
池化操作提供了另一种形式的平移不变性,因为卷积核是一种特征发现器,我们通过卷积层可以很容易地发现图像中的各种边缘,但是卷积层发现的特征往往都过于精确,我们即时高速连拍拍摄一个物体,照片中的物体边缘像素位置也不太可能完全一致,通过池化层,我们可以降低卷积层对边缘的敏感性。
池化层每次在一个池化窗口(depth slice)上计算输出,然后根据步幅移动池化窗口,下面是当前最常用的池化器,步幅为2,池化窗口为2×2的二维最大池化层,每隔2个元素从图像划分出2×2的区块,然后地每个区域中的4个数取最大值。这样将会减少75%的数据量。
$$f_{X, Y}(S)=max _{a, b=0}^1 S_{2 X+a, 2 Y+b}$$
3.1 Max-Pooling
“最大池化(Max pooling)”是最为常见的,它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值,如下图所示。
Max Pooling实际就是做了Property:(3)Subsampling the pixels will not change the object.
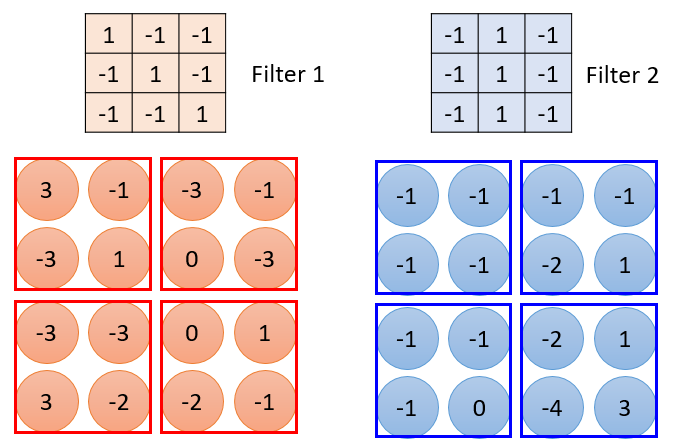
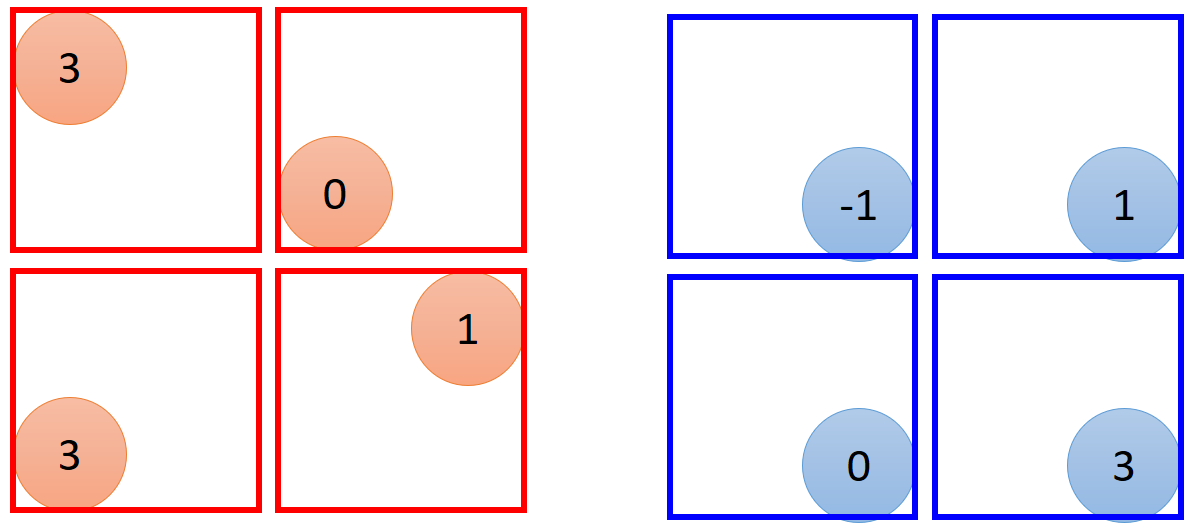
在经过一层卷积核和Max Pooling后,6*6的image变成了2*2image,对于2*2image,其每一个pixel的深度取决于filter的数量(如果有50个filter,那么就是50维表示一个pixel)
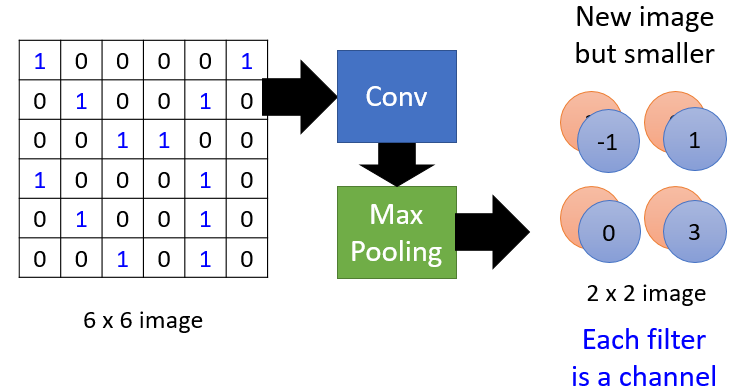
把上述得到的`A new image`再次进行处理,(再次通过Convolution 和 Max Pooling 得到一个更小的image)
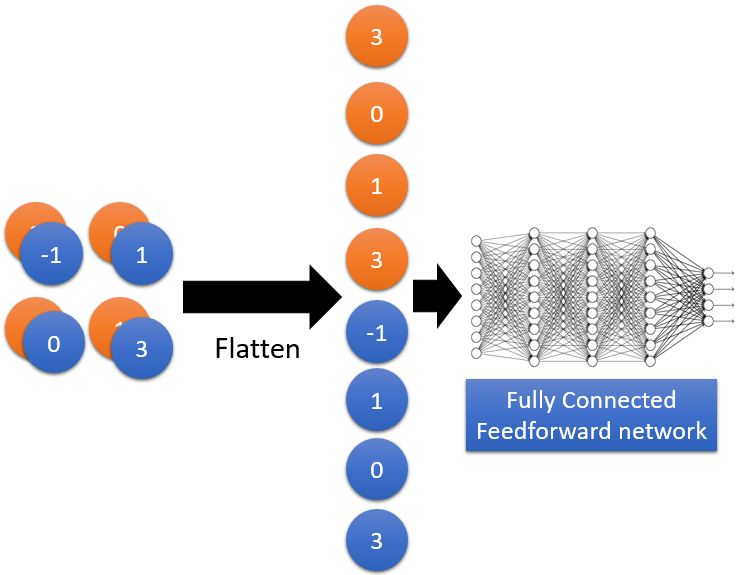
4、 Flatten
flattern就是把feature map 拉直排列好,方便后面放入Fully Connected Feedforward network计算。
参考文献
1. https://blog.csdn.net/weixin_42026802/article/details/80181627
2. 李宏毅老师CNN讲解视屏