问题:
查询user_low_carbon表中每日流水记录,条件为:
用户在2017年,连续三天(或以上)的天数里,每天减少碳排放(low_carbon)都超过100g的用户低碳流水。
需要查询返回满足以上条件的user_low_carbon表中的记录流水。
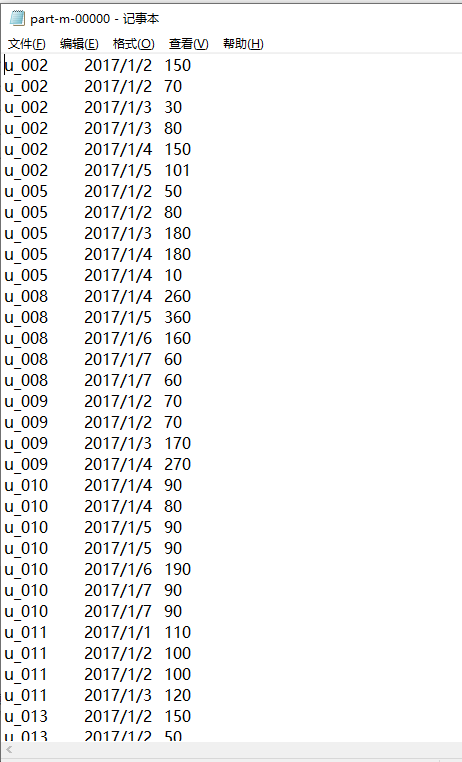
例如用户u_002符合条件的记录如下,因为2017/1/2~2017/1/5连续四天的碳排放量之和都大于等于100g:
seq(key) user_id data_dt low_carbon xxxxx10 u_002 2017/1/2 150 xxxxx11 u_002 2017/1/2 70 xxxxx12 u_002 2017/1/3 30 xxxxx13 u_002 2017/1/3 80 xxxxx14 u_002 2017/1/4 150 xxxxx14 u_002 2017/1/5 101 备注:统计方法不限于sql、procedure、python,java等
统计方法除了使用hive sql之外,还可以使用Java编写MapReduce程序来解决,这次我就来尝试了一下。
首先,使用Hive SQL过滤出在2017年,每个用户在一天内减少碳排放量大于100g的日期。
select user_id,date_format(regexp_replace(data_dt,'/','-'),'yyyy-MM-dd') data_dt from user_low_carbon where substring(data_dt,1,4)="2017" group by user_id,data_dt having sum(low_carbon)>100; a1
得到的完整数据为:
user_id data_dt u_001 2017-01-02 u_001 2017-01-06 u_002 2017-01-02 u_002 2017-01-03 u_002 2017-01-04 u_002 2017-01-05 u_003 2017-01-02 u_003 2017-01-03 u_003 2017-01-05 u_003 2017-01-07 u_004 2017-01-01 u_004 2017-01-03 u_004 2017-01-06 u_004 2017-01-07 u_005 2017-01-02 u_005 2017-01-03 u_005 2017-01-04 u_005 2017-01-06 u_005 2017-01-07 u_006 2017-01-02 u_006 2017-01-03 u_006 2017-01-07 u_007 2017-01-01 u_007 2017-01-02 u_007 2017-01-04 u_007 2017-01-06 u_007 2017-01-07 u_008 2017-01-01 u_008 2017-01-02 u_008 2017-01-04 u_008 2017-01-05 u_008 2017-01-06 u_008 2017-01-07 u_009 2017-01-02 u_009 2017-01-03 u_009 2017-01-04 u_009 2017-01-07 u_010 2017-01-02 u_010 2017-01-04 u_010 2017-01-05 u_010 2017-01-06 u_010 2017-01-07 u_011 2017-01-01 u_011 2017-01-02 u_011 2017-01-03 u_011 2017-01-07 u_012 2017-01-02 u_013 2017-01-02 u_013 2017-01-03 u_013 2017-01-04 u_013 2017-01-05 u_014 2017-01-01 u_014 2017-01-02 u_014 2017-01-05 u_014 2017-01-06 u_014 2017-01-07 u_015 2017-01-07
将这些数据放入txt文件中,命名为t1.txt,作为我们MR程序的输入文件。
因为我们现在已经得到的数据是每天减碳量超过100g的数据,所以对于我们的MR程序来说,核心的业务是将读取的数据以用户id作为分组的条件,然后相同用户id的记录输出到一个reduce中,在reduce中判断是否是连续三天或以上减碳量超过100g的情况,如果是那么就写出到输出文件中,作为输出的结果。
为了后续的处理方便,在Map阶段,我们要对数据进行排序,所以我们需要构造一个bean对象,实现WritableComparable接口,排序的规则是,先按照用户id进行正序排序,如果用户id相同,那么就按照日期排序,也是正序的。这样给reduce的数据就是一个有序的数据集了。此外,为了使得相同用户id的数据能够进入一个reduce中,我们需要进行一个分组的辅助排序,自定义一个分组排序的类,继承自WritableComparator这个抽象类,排序的逻辑就是根据用户id进行排序。
1、定义bean对象,作为MR程序中的数据载体。
package com.fym.ant; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** */ public class UserCarbonBean implements WritableComparable<UserCarbonBean> { private String user_id; private String datee; public UserCarbonBean() { super(); } public UserCarbonBean(String user_id, String date) { this.user_id = user_id; this.datee = date; } public int compareTo(UserCarbonBean o) { int result; if (user_id.compareTo(o.getUser_id()) > 0){ result = 1; }else if (user_id.compareTo(o.getUser_id()) < 0){ result = -1; }else { if(datee.compareTo(o.getDate()) > 0){ result = 1; }else if (datee.compareTo(o.getDate())<0){ result = -1; }else { result = 0; } } return result; } public void write(DataOutput out) throws IOException { out.writeUTF(user_id); out.writeUTF(datee); } public void readFields(DataInput in) throws IOException { user_id = in.readUTF(); datee = in.readUTF(); } @Override public String toString() { return user_id + ' ' +datee; } public String getUser_id() { return user_id; } public void setUser_id(String user_id) { this.user_id = user_id; } public String getDate() { return datee; } public void setDate(String date) { this.datee = date; } }
2、编写Mapper程序,读取t1.txt中的内容,进行分解
package com.fym.ant; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class AntsMapper extends Mapper<LongWritable, Text,UserCarbonBean, NullWritable> { UserCarbonBean k = new UserCarbonBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split(" "); String uid = fields[0]; String datee = fields[1]; k.setUser_id(uid); k.setDate(datee); context.write(k,NullWritable.get()); } }
3、编写reducer程序,统计每个用户,是否有连续三天减碳量超过100g的情况,如果有要写出
package com.fym.ant; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; public class AntsReducer extends Reducer<UserCarbonBean, NullWritable,UserCarbonBean,NullWritable> { @Override protected void reduce(UserCarbonBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { String dates = "1970-01-01"; ArrayList<UserCarbonBean> list = new ArrayList<UserCarbonBean>(); for (NullWritable value : values) { if (dates.equals("1970-01-01")){ list.add(new UserCarbonBean(key.getUser_id(),key.getDate())); dates = key.getDate(); }else { if (key.getDate().compareTo(dates) == 1){ list.add(new UserCarbonBean(key.getUser_id(),key.getDate())); dates = key.getDate(); }else { if (list.size() >= 3){ for (UserCarbonBean userCarbonBean : list) { context.write(userCarbonBean,NullWritable.get()); } list.clear(); list.add(new UserCarbonBean(key.getUser_id(),key.getDate())); dates = key.getDate(); }else { list.clear(); list.add(new UserCarbonBean(key.getUser_id(),key.getDate())); dates = key.getDate(); } } } } if (list.size()>=3){ for (UserCarbonBean userCarbonBean : list) { context.write(userCarbonBean,NullWritable.get()); } } } }
记住在循环结束以后,要判断一下列表中的数据是否超过3个,如果有要写出。
4、驱动程序


package com.fym.ant; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class AntsDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"F:/ProgramTest/testfile/ant/input/t1.txt" , "F:/ProgramTest/testfile/ant/output/6"}; // 1 获取配置信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 设置jar包加载路径 job.setJarByClass(AntsDriver.class); // 3 加载map/reduce类 job.setMapperClass(AntsMapper.class); job.setReducerClass(AntsReducer.class); // 4 设置map输出数据key和value类型 job.setMapOutputKeyClass(UserCarbonBean.class); job.setMapOutputValueClass(NullWritable.class); // 5 设置最终输出数据的key和value类型 job.setOutputKeyClass(UserCarbonBean.class); job.setOutputValueClass(NullWritable.class); // 6 设置输入数据和输出数据路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 设置reduce端的分组 job.setGroupingComparatorClass(UserCarbonGroupingSort.class); // 7 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
5、输出的结果
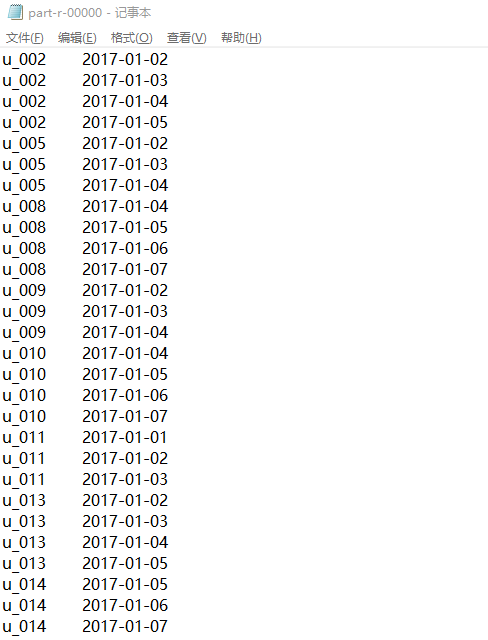
此时得到仅仅是,连续三天或者三天以上减碳量超过100g的用户,及其连续减碳的日期。为了能够得到详细的流水记录,那么就需要和原表进行join操作,因为详细的流水记录只有在原表中采用。我们现在得到的是连续的日期,而详细的流水情况可能是:对于同一天其减碳量是多次的,一天的总和超过了100g,而对应的详细的流水记录就是多条的。所以我们要获得详细的流水记录,就需要和原表join,join的条件是上面那个结果表的用户id要相同,同时日期也要相同。
这里我们采用map join的方式,因为我们要进行join操作,需要的就是两个表的数据,所以对于mapper程序,需要重写setup函数和map函数:
setup函数用于读取原始表的数据,由于原始表中的日期和上面的结果中的日期格式是不一样的,所以我们需要进行日期格式转换的处理。为了实现join操作,我们将这些数据存放到一个哈希表中,将用户id和格式转换之后的日期进行字符串连接作为哈希表的key,由于用户id和日期作为key,那么对应的数据会有很多条,所以哈希表的value的数据类型也是list类型,这个list内部存储的元素就是String类型,也就是与key对应的原始表中的一行行数据。每读取一行数据,就根据key将当前读取的行添加到对应的value列表中(因为题目要的和原始表中一样的数据流水,所以直接将从原始表读取的行数据存入value列表中),这样原始表的数据就加载完成了。
map函数,用于一条一条读取上面那个结果表中的数据,每次读取一条数据就分割出用户id和日期,将它们进行字符串连接,然后作为key去获取哈希表中的value,这个value是List<String>类型,其内部可能包含了多条数据,我们将其循环写出。通俗的解释一下,map读取的数据是上面那个结果表的数据,因此一条数据就是某个用户连续三天或者三天以上减碳量超过100g的某一天,这个某一天,对应于原始表,可能就是多条记录,因为之前说了,原始表中,一天之内可能有多次流水,而我们在求这个题目的最开始,已经将同一天的所有流水记录进行了求和计算。
代码:
package com.fym.ant; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Date; import java.util.HashMap; import java.util.List; public class MapJoinMapper extends Mapper<LongWritable, Text,Text, NullWritable> { private HashMap<String, List<String>> ucMap; @Override protected void setup(Context context) throws IOException, InterruptedException { ucMap = new HashMap<String, List<String>>(); URI[] cacheFiles = context.getCacheFiles(); String path = cacheFiles[0].getPath().toString(); BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8")); String line; List<String> templist; while (StringUtils.isNotEmpty(line = reader.readLine())){ String[] fields = line.split(" "); String uid = fields[0]; String dt = fields[1].replace('/','-'); Date date = null; String now; try { date = new SimpleDateFormat("yyyy-MM-dd").parse(dt); now = new SimpleDateFormat("yyyy-MM-dd").format(date); if (ucMap.get(uid+" "+now)==null){ templist = new ArrayList<String>(); templist.add(line); ucMap.put(uid+" "+now,templist); }else { templist = ucMap.get(uid+" "+now); templist.add(line); ucMap.put(uid+" "+now,templist); } } catch (ParseException e) { e.printStackTrace(); } } reader.close(); } Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split(" "); String uid = fields[0]; String dt = fields[1]; List<String> res = ucMap.get(uid + " " + dt); for (String re : res) { k.set(re); context.write(k,NullWritable.get()); } } }
map join的驱动程序:
package com.fym.ant; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class MapJoinDriver { public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException { // 0 根据自己电脑路径重新配置 args = new String[]{"F:/ProgramTest/testfile/ant/output/6", "F:/ProgramTest/testfile/ant/output/2"}; // 1 获取job信息 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 设置加载jar包路径 job.setJarByClass(MapJoinDriver.class); // 3 关联map job.setMapperClass(MapJoinMapper.class); // 4 设置最终输出数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 加载缓存数据 job.addCacheFile(new URI("file:///F:/ProgramTest/testfile/ant/input/user_Carbon.txt")); // 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0 job.setNumReduceTasks(0); // 8 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
需要注意的是,这里需要把原始表数据手动加载到缓存中,以便mapper初始化的时候获取。写文件路径的时候,固定就是:
file:///你自己的在本地的具体文件存放路径
输出的结果: