章节十六:编码和文件读写
在你的网络冲浪生涯里,我想你或多或少有这样的疑问:为什么传说中只能读懂0和1的计算机能显示如此五花八门的内容?为什么明明办的100兆的宽带,撑死就只有10几兆的下载速度?为什么有时打开文件会出现这样像中毒一般的“火星文”?

今天主要有两大块内容,分别是编码和文件读写。
1. 编码
我们先来看编码。编码的本质就是让只认识0和1的计算机,能够理解我们人类使用的语言符号,并且将数据转换为二进制进行存储和传输。
这种从人类语言到计算机语言转换的形式,就叫做编码表,它让人类语言和计算机语言能够一一对应起来。
要了解编码,我们还得先来聊聊二进制。由于有二进制,0和1这两个数字才能像“太极生两仪,两仪生四象,四象生八卦”一样,涵盖容纳世间所有的信息。
1.1 二进制
说起二进制,我就想起了西游记里的二进陈家庄……噢不对,是更久远的周幽王烽火戏诸侯。所以接下里我会用烽火这种古老的信息传递形式,来比喻说明计算机是怎么传输和存储数据的。
假设我们都是看守城墙的小兵,你在烽火台A上,我在烽火台B上,只要你那边来了敌人,你就点着烽火台通知我。
如果只有一个烽火台,那么只有“点着火”和“没点火”两种状态,这就像电子元件里“通电”和“没通电”的状态,所以只有0和1.
但是你光告诉我来敌人还不够啊,还得告诉我敌人的数量有多少,让我好call齐兄弟做好准备。现在问题是你要怎么通知我敌人的数量呢?
所以,我们之间就约定了特别的“暗号”,来通知彼此敌情。
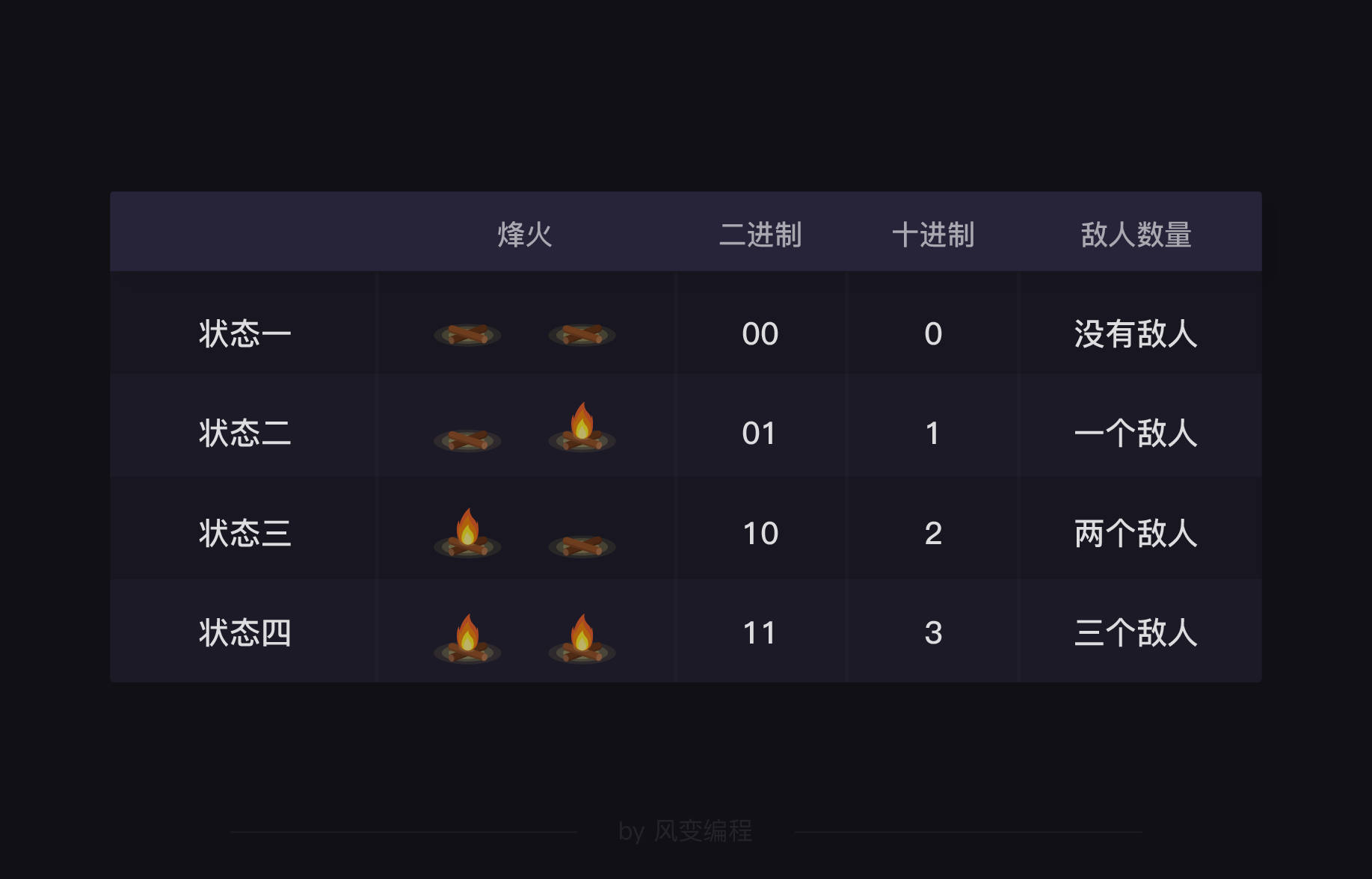
现在有两座烽火台,右边为第1座,左边为第2座。我们约定,当没有烽火台被点着的时候,表示没有敌人(00);只点着第一座烽火台的时候,表示来了一个敌人(01);只点着第二座烽火台的时候,表示来了2个敌人。(10,逢二进一)
当两座烽火台都被点着的时候(11),就表示来了3个人。
也就是这样的对应关系:
二进制 - 十进制
00 - 0
01 - 1
10 - 2
11 - 3
所以两个二进制位可以表示十进制的0,1,2,3四种状态。
现在你应该可以听得懂这个笑话:世界上有10种人,懂二进制和不懂二进制的。
我们继续往下推,当有三座烽火台的时候,我们可以表示0~7八种状态(也就是2的3次方)。

以此类推,当有八座烽火台的时候,我们就能表示2的8次方,也就是256种状态,它由8个0或1组成。
00000000 表示状态0: 烽火全暗,一个敌人没有,平安无事,放心睡觉。
11111111 表示状态255:烽火全亮,来了255个敌人。起来打啊!
用来存放一位0或1,就是计算机里最小的存储单位,叫做【位】,也叫【比特】(bit)。我们规定8个比特构成一个【字节】(byte),这是计算机里最常用的单位。

bit和byte长得有点像,可别混淆!1 byte = 8 bit,也就是1字节等于8比特。
这些计算机单位,可与我们息息相关,你的手机“流量”,就是这么计算的:

而百兆宽带,下载速度最多能达到十多兆,是因为运营商的带宽是以比特每秒为单位的,比如100M就是100Mbit/s。
而我们常看到的下载速度KB却是以字节每秒为单位显示的,1byte = 8bit,所以运营商说的带宽得先除以8,你的百兆宽带下载速度,也就是十几兆了。
二进制居然能牵扯出这么多生活中的问题,你是否也很意外?哈哈,其实生活处处是知识呀。
好,咱们言归正传,来看让人类语言和计算机语言能够一一对应起来的【编码表】。
1.2 编码表
计算机一开始发明的时候,只是用来解决数字计算的问题。后来人们发现,计算机还可以做更多的事,正所谓能力越大,责任越大。但由于计算机只识“数”,因此人们必须告诉计算机哪个数字来代表哪个特定字符。
于是除了0、1这些阿拉伯数字,像a、b、c这样的52个字母(包括大小写),还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,理论上每个人都可以有自己的一套规则(这就叫编码)。
但大家如果想要互相沟通而不造成混乱,就必须使用相同的编码规则。如果使用了不同的编码规则,那就会彼此读不懂,这就是“乱码”的由来。

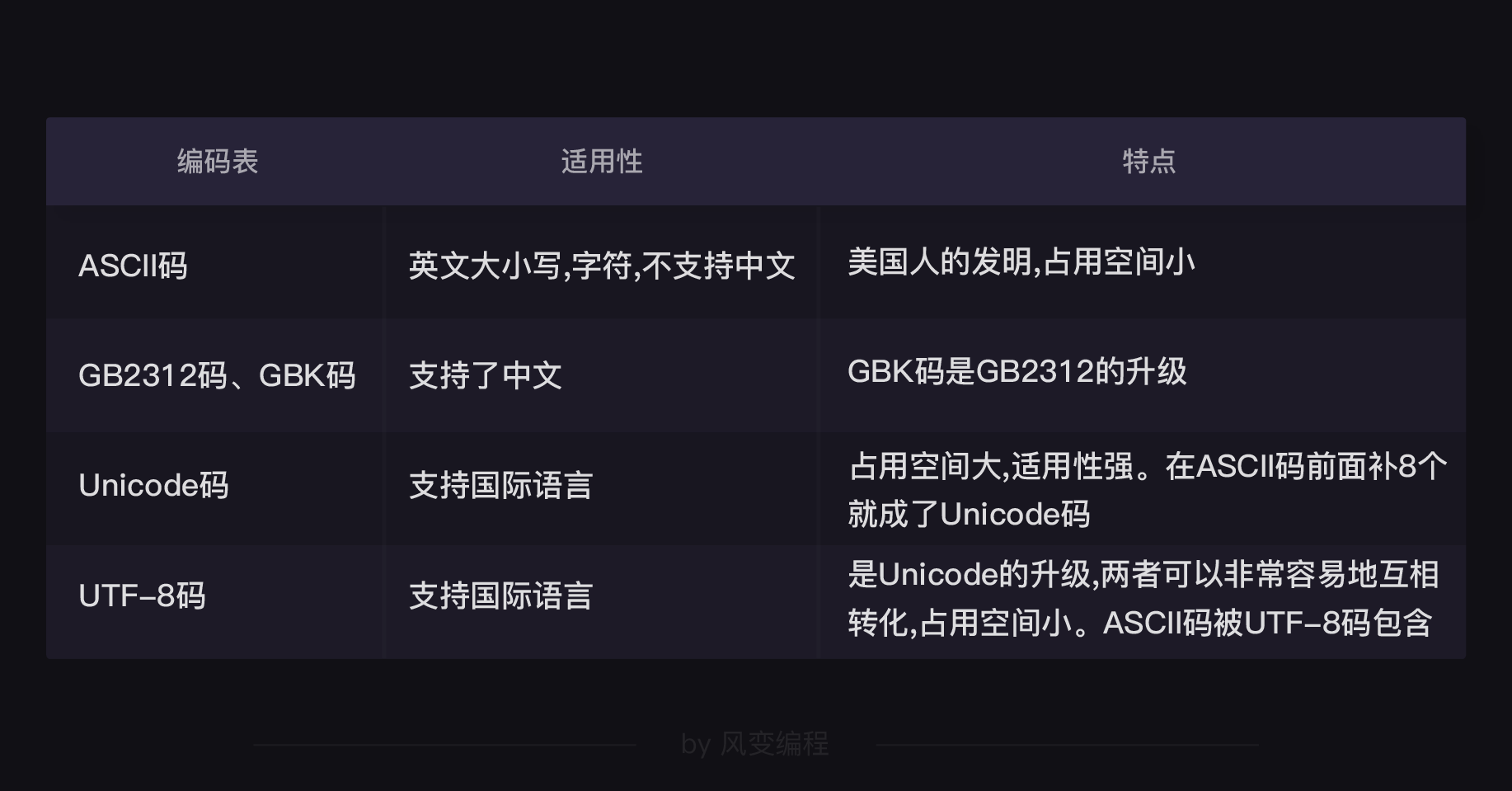
为了避免乱码,一段世界历史就此启动。一开始,是美国首先出台了ASCII编码(读音:/ˈæski/),统一规定了常用符号用哪些二进制数来表示。
因为英文字母、数字再加上其他常用符号,也就100来个,因此使用7个比特位(最多表示128位)就够用了,所以一个字节中被剩下的那个比特位就被默认为0。
再后来呢,这套编码表传入欧洲,才发现这128位不够用啊。比如说法语字母上面还有注音符,这个怎么区分?得!把最后一个比特位也编进来吧。因此欧洲普遍使用一个全字节(8个比特位)进行编码,最多可表示256位,至此,一个字节就用满了!
但是前面的状态0-127位可以共用,但从状态128到255这一段的解释就完全乱套了,比如135在法语,希伯来语,俄语编码中完全是不同的符号。
当计算机漂洋过海来到中国后,问题又来了,计算机完全不认识博大精深的中文,当然也没法显示中文;而且一个字节的256位都被占满了,但中国有10万多个汉字,256位连塞牙缝都不够啊。

于是中国科学家自力更生,重写了一张编码表,也就是GB2312,它用2个字节,也就是16个比特位,来表示绝大部分(65535个)常用汉字。后来,为了能显示更多的中文,又出台了GBK标准。
不仅中国,其他国家也都搞出自己的一套编码标准,这样的话地球村村民咋沟通?日本人发封email给中国人,两边编码表不同,显示的都是乱码。
为了沟通的便利,Unicode(万国码)应运而生,这套编码表将世界上所有的符号都纳入其中。每个符号都有一个独一无二的编码,现在Unicode可以容纳100多万个符号,所有语言都可以互通,一个网页上也可以显示多国语言。
看起来皆大欢喜。但是!问题又来了,自从英文世界吃上了Unicode这口大锅饭,为迁就一些占用字节比较多的语言,英文也要跟着占两个字节。比如要存储A,原本00010001就可以了,现在偏得用两个字节:00000000 00010001才行,这样对计算机空间存储是种极大的浪费!
基于这个痛点,科学家们又提出了天才的想法:UTF-8(8-bit Unicode Transformation Format)。它是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,而当字符在ASCII码的范围时,就用一个字节表示,所以UTF-8还可以兼容ASCII编码。
Unicode与UTF-8这种暧昧的关系一言以蔽之:Unicode是内存编码的规范,而UTF-8是如何保存和传输Unicode的手段。
将上述这段波澜壮阔、分久必合的编码史浓缩成一个表格表示,就是:
人类语言千变万化,我们有《新华字典》《牛津英语字典》这样的辞书来记录和收纳。可以说,这些编码表就是计算机世界的字典辞书,它们同样也是人类智慧的结晶。

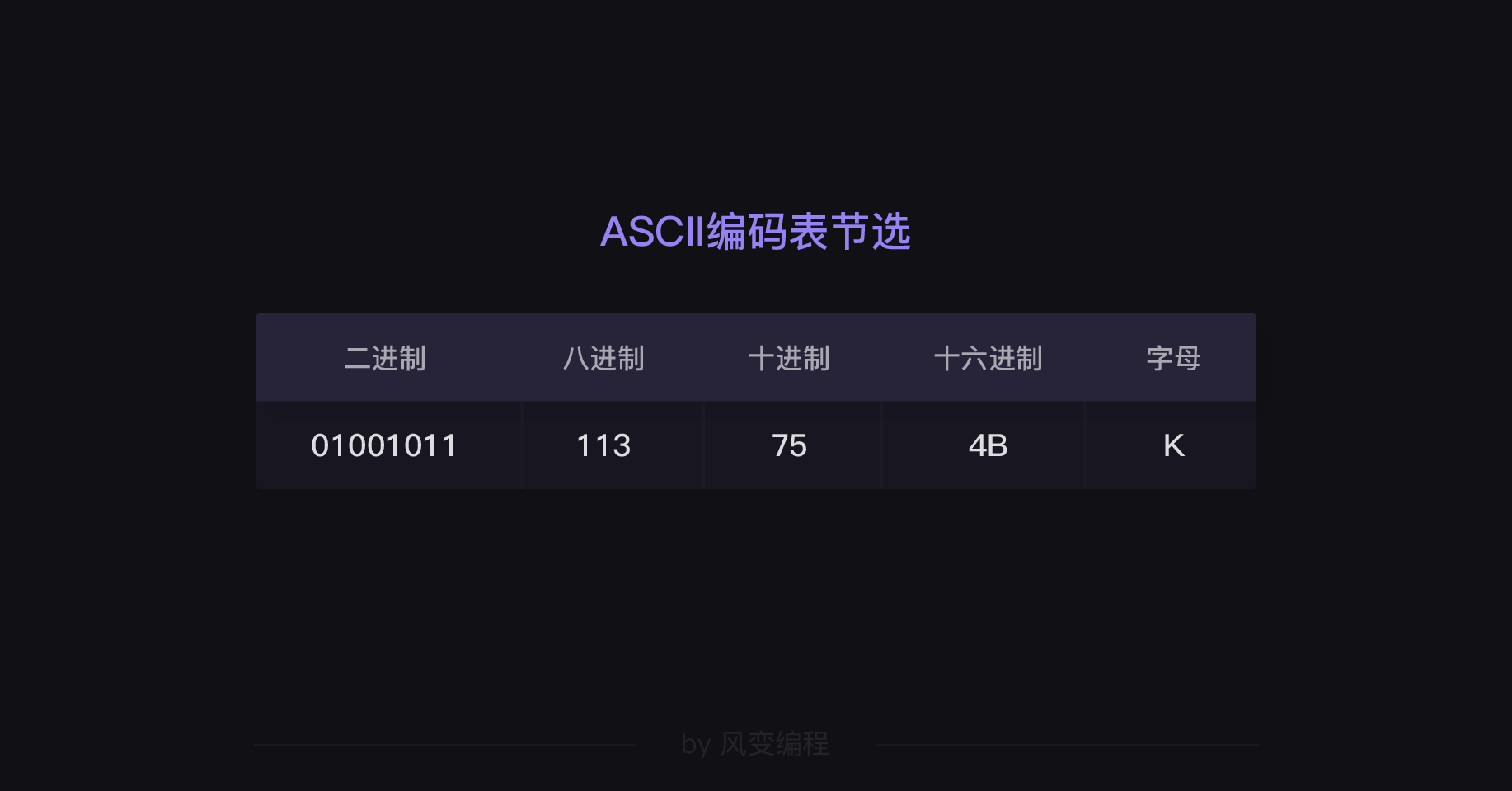
这里,我再顺便介绍下八进制和十六进制,别嫌我啰嗦啊。
因为二进制是由一堆0和1构成的,过长的数字对于人的阅读有很大障碍,为了解决这一问题,也减少书写的复杂性,我们又引入了八进制和十六进制。
为什么偏偏是16或8进制?2、8、16,分别是2的1次方、3次方、4次方。这一点使得三种进制之间可以非常直接地互相转换。
8进制是用0,1,2,3,4,5,6,7;16进制是用0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f来表示。比如说,字母K在ASCII编码表用不同进制表示的话是这样的:(你并不需要知道具体的转换规则)
接下来,我为你介绍几种编码方案在当前的使用情况。
第0,计算机是有自己的工作区的,这个工作区被称为“内存”。数据在内存当中处理时,使用的格式是Unicode,统一标准。
在Python3当中,程序处理我们输入的字符串,是默认使用Unicode编码的,所以你什么语言都可以输入。
第1,数据在硬盘上存储,或者是在网络上传输时,用的是UTF-8,因为节省空间。但你不必操心如何转换UTF-8和Unicode,当我们点击保存的时候,程序已经“默默地”帮我们做好了编码工作。
第2,一些中文的文件和中文网站,还在使用GBK,和GB2312。
基于此,有时候面对不同编码的数据,我们要进行一些操作来实现转换。这里就涉及接下来要讲的【encode】(编码)和【decode】(解码)的用法。
1.3 encode()和decode()
编码,即将人类语言转换为计算机语言,就是【编码】encode();反之,就是【解码】decode()。它们的用法如下图所表示:

可以尝试运行下面的代码。1~2行是encode()的用法,3-4行是decode()的用法
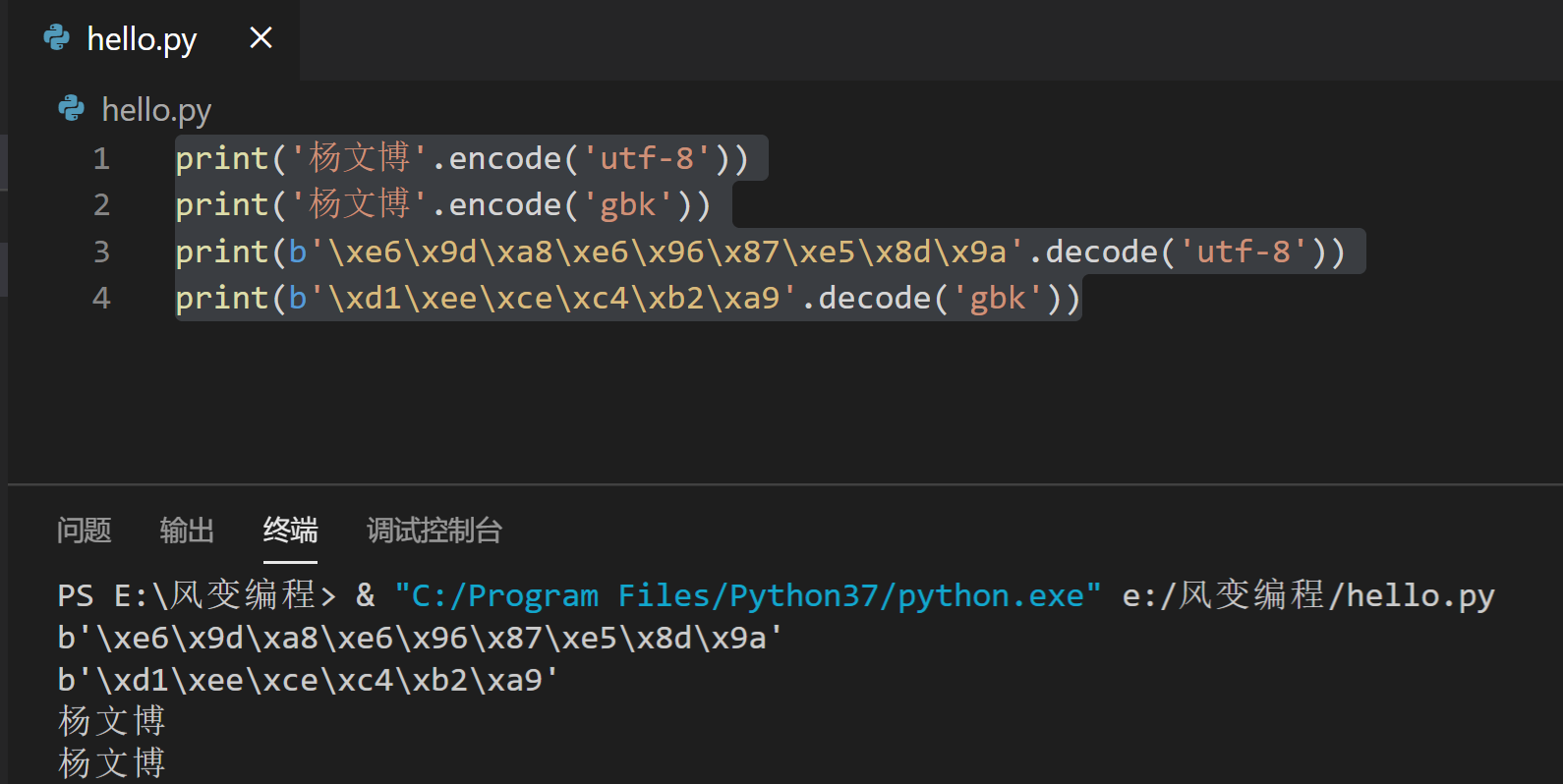
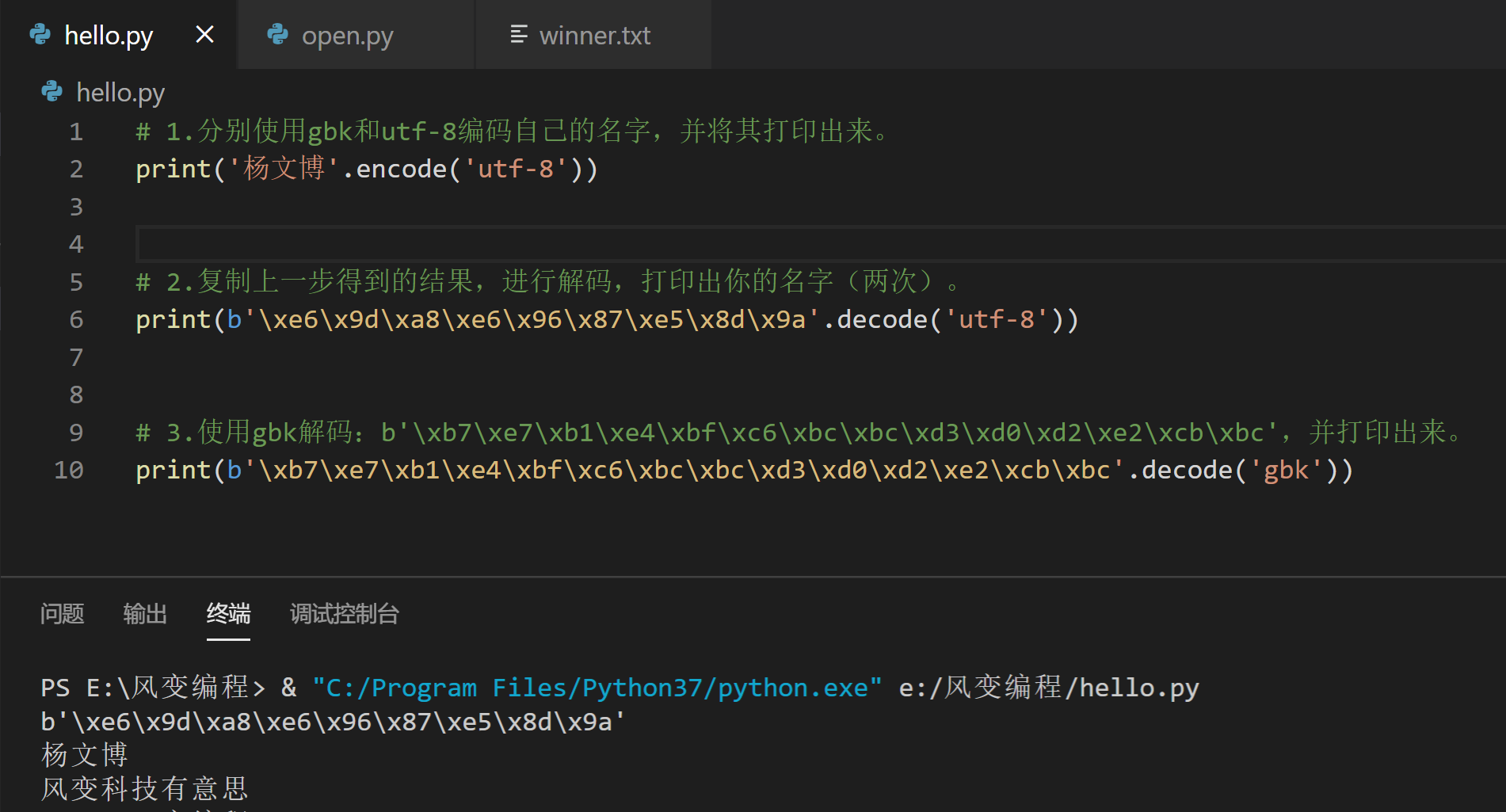
print('杨文博'.encode('utf-8'))
print('杨文博'.encode('gbk'))
print(b'\xe6\x9d\xa8\xe6\x96\x87\xe5\x8d\x9a'.decode('utf-8'))
print(b'\xd1\xee\xce\xc4\xb2\xa9'.decode('gbk'))
将人类语言编码后得到的结果,有一个相同之处,就是最前面都有一个字母b,比如b'\xce\xe2\xb7\xe3',这代表它是bytes(字节)类型的数据。我们可以用type()函数验证一下。
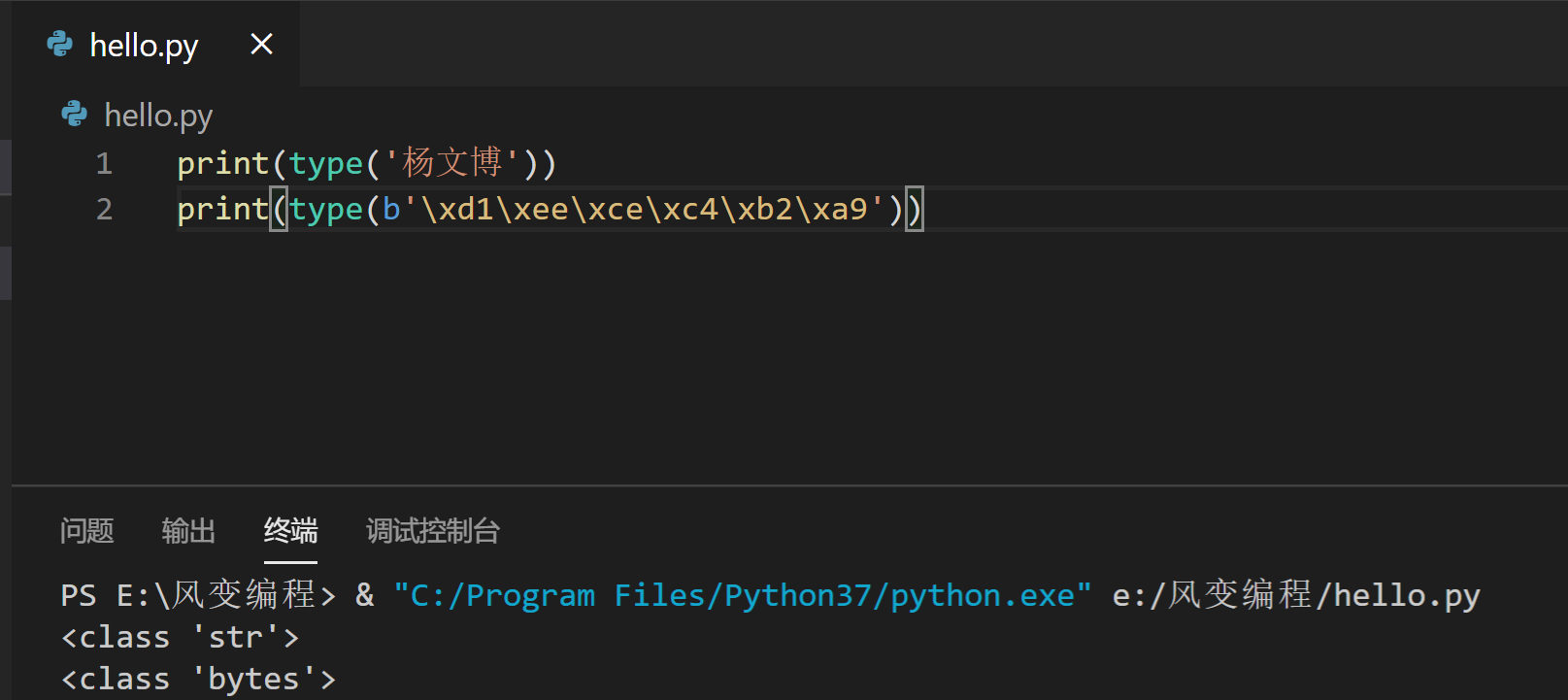
所谓的编码,其实本质就是把str(字符串)类型的数据,利用不同的编码表,转换成bytes(字节)类型的数据。
我们再来区分下字符和字节两个概念。字符是人们使用的记号,一个抽象的符号,这些都是字符:'1', '中', 'a', '$', '¥' 。
而字节则是计算机中存储数据的单元,一个8位的二进制数。
编码结果中除了标志性的字母b,你还会在编码结果中看到许多\x,你再观察一下这个例子:b'\xce\xe2\xb7\xe3'。
\x是分隔符,用来分隔一个字节和另一个字节。
分隔符还挺常见的,我们在上网的时候,不是会有网址嘛?你经常会看到网址里面有好多的%,它们也是分隔符,替换了Python中的\x。比如像下面这个:
它的意思就是在百度里面,搜索“杨文博”,使用的是UTF-8编码。你眯着眼睛看一看上面的UTF-8编码结果和这一串网址的差异,其实它们除了分隔符以外,是一模一样的。
\xe6\x9d\xa8\xe6\x96\x87\xe5\x8d\x9a # Python编码“杨文博”的结果
%e6%9d%a8%e6%96%87%e5%8d%9a # 网址里的“杨文博”
此外,用decode()解码的时候则要注意,UTF-8编码的字节就一定要用UTF-8的规则解码,其他编码同理,否则就会出现乱码或者报错的情况,现在请你将下列字节解码成UTF-8的形式,打印出来。
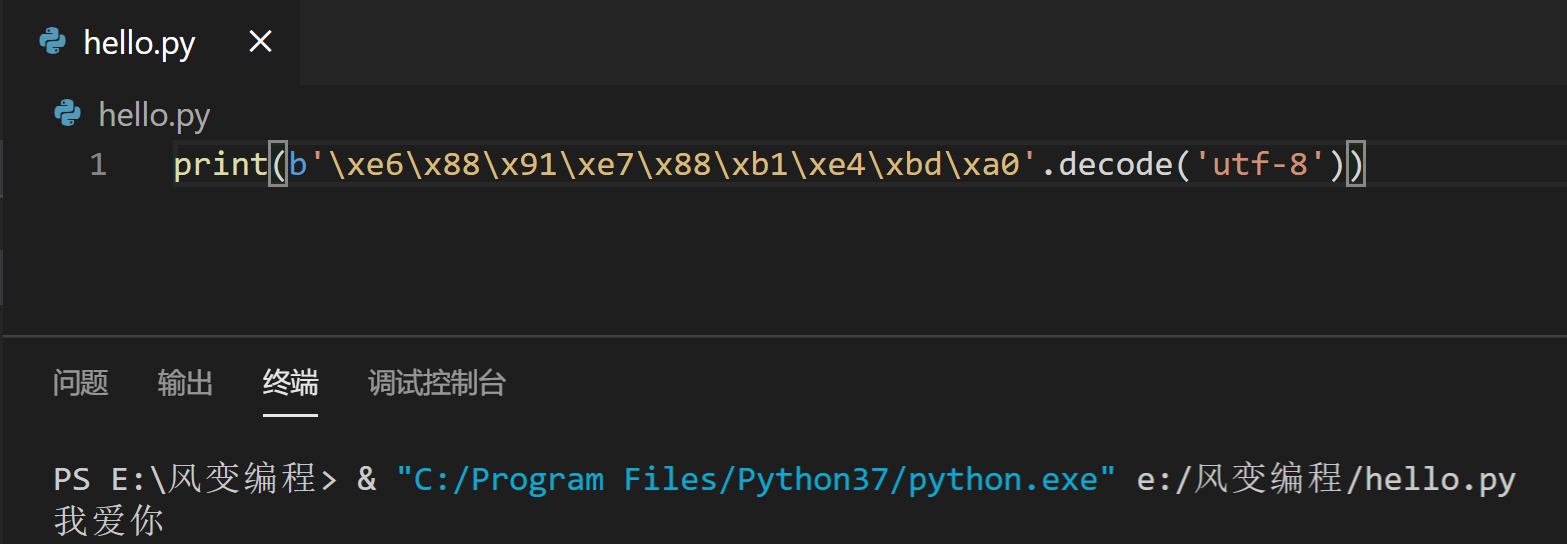
print(b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'.decode('utf-8'))
所以以后当闷骚的程序猿丢给你这样一串代码时,不要一脸懵,或者你想向不解风情的程序员委婉地表白时,或许可以采用这种清奇的示爱方式噢。
最后我们再来看下ASCII编码,它不支持中文,所以我们来转换一个大写英文字母K。
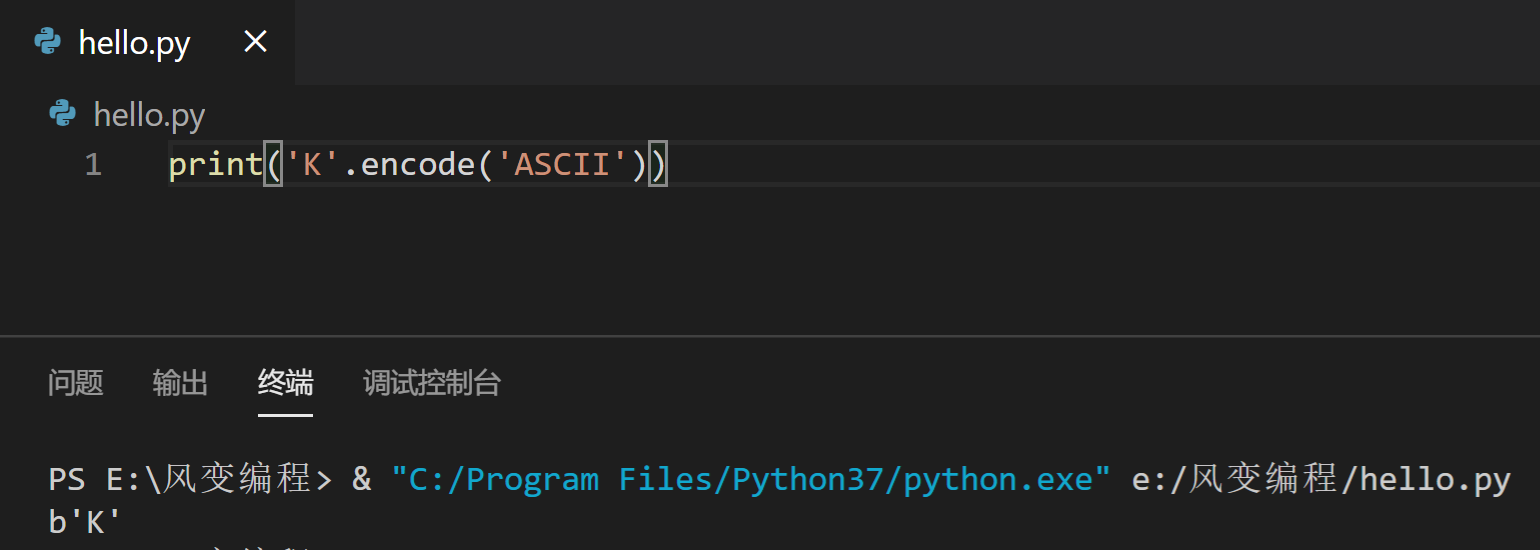
你看到大写字母K被编码后还是K,但这两个K对计算机来说意义是不同的。前者是字符串,采用系统默认的Unicode编码,占两个字节。后者则是bytes类型的数据,只占一个字节。这也验证我们前面所说的编码就是将str类型转换成bytes类型。
编码知识虽然看起来很琐碎,但它又是非常重要的,如果不能理解这些背景知识,指不定你哪天就会遇到坑,就像隐藏在丛林中的蛇,时不时地咬你一口。而它和我们接下来要教的文件读写也有点关系。
接下来我们就来看看文件读写。
2. 文件读写
文件读写,是Python代码调用电脑文件的主要功能,能被用于读取和写入文本记录、音频片段、Excel文档、保存邮件以及任何保存在电脑上的东西。
你可能会疑惑:为什么要在Python打开文件?我直接打开那个文件,在那个文件上操作不就好了吗?
一般来说直接打开操作当然是没问题的。但假如你有一项工作,需要把100个Word文档里的资料合并到1个文件上,一个个地复制粘贴多麻烦啊,这时你就能用上Python了。或者,当你要从网上下载几千条数据时,直接用Python帮你把数据一次性存入文件也是相当方便。
要不然怎么说,Python把我们从重复性工作中解放出来呢~
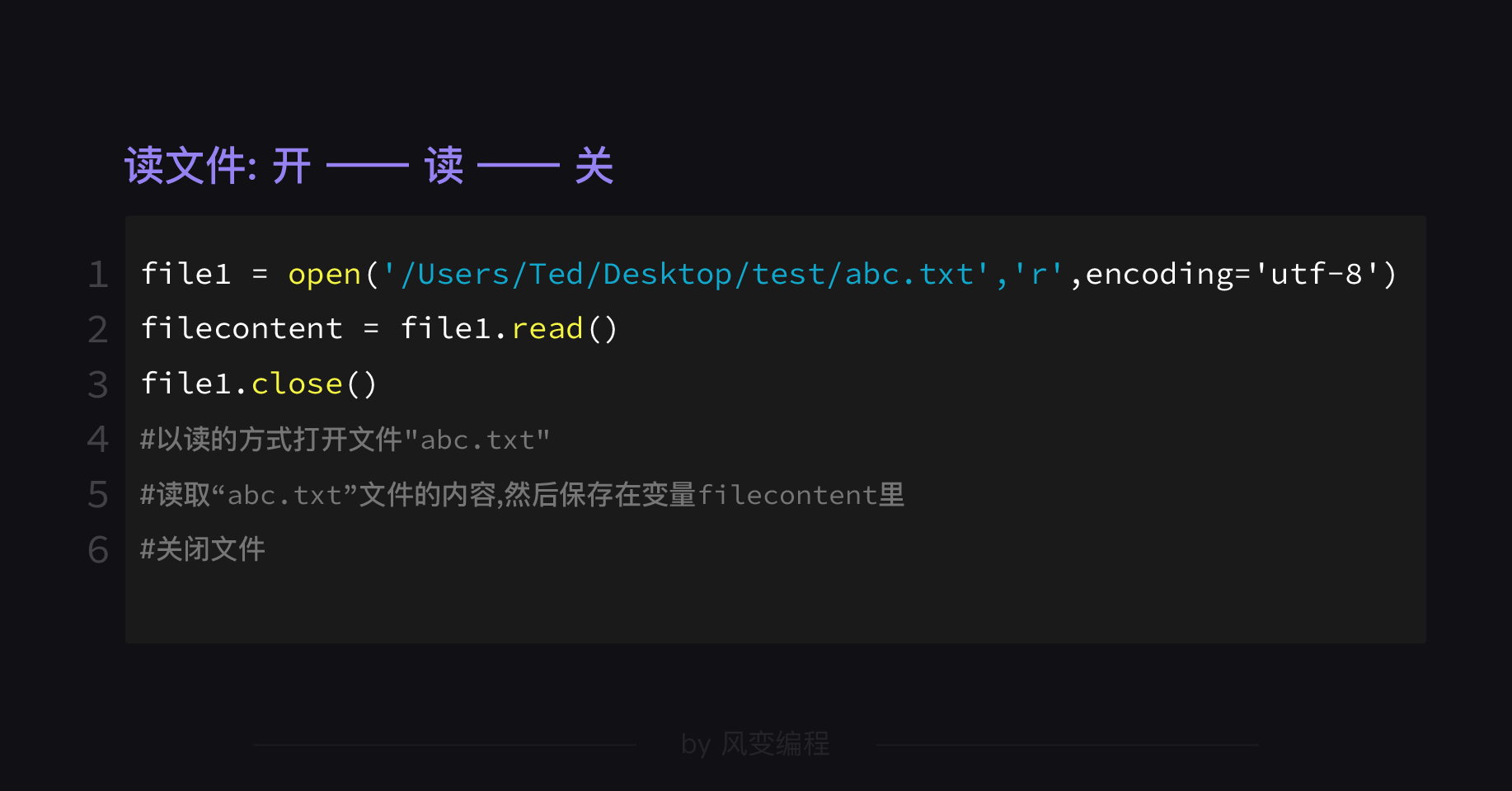
【文件读写】,是分为【读】和【写】两部分的,我们就先来瞧瞧【读文件】是怎么实现的?
2.1 读取文件
其实,真的就三步:
是不是像很久之前的那个冷笑话?“请问把大象放进冰箱需要几步?”三步:打开冰箱,放入大象,关闭冰箱。同样地,读文件也是三步:开——读——关。
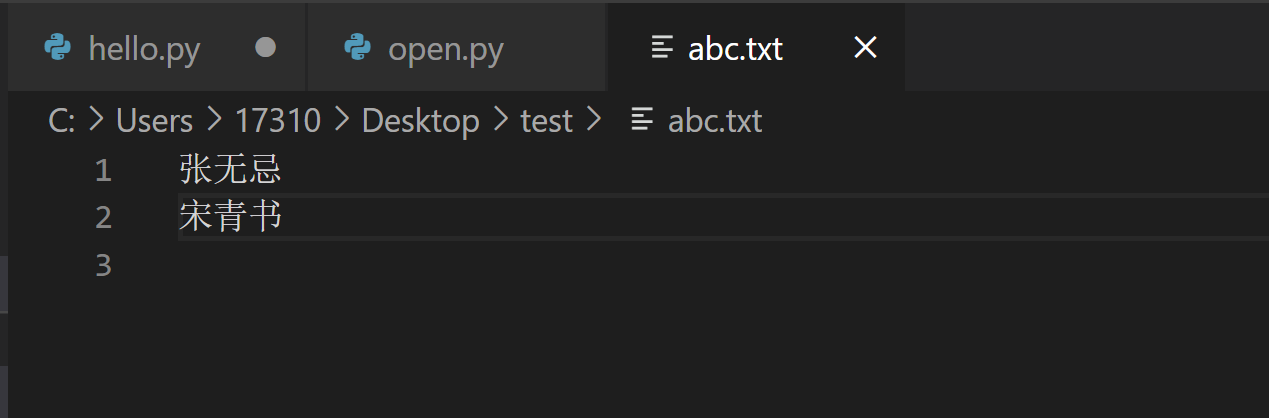
首先,我们先在桌面新建一个test文件夹,然后在文件夹里新建一个名为abc的txt文件,在里面随便写点儿什么,我写的是周芷若、赵敏。
我用编辑器Visual Studio Code打开这个文件,是这样的:
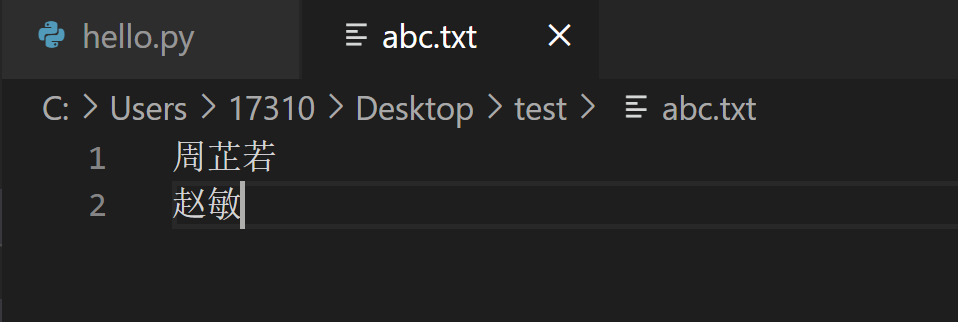
然后,你可以用VS Code新建一个open.py的Python文件,也放在test文件夹里,我们就在这里写代码。
代码怎么写呢?
【第1步-开】使用open()函数打开文件。语法是这样的:
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','r',encoding='utf-8')
file1这个变量是存放读取的文件数据的,以便对文件进行下一步的操作。
open()函数里面有三个参数,对吧:
'C:\\Users\\17310\\Desktop\\test\\abc.txt'
'r'
encoding='utf-8'
我们一个个来看。第一个参数是文件的保存地址,一定要写清楚,否则计算机找不到。
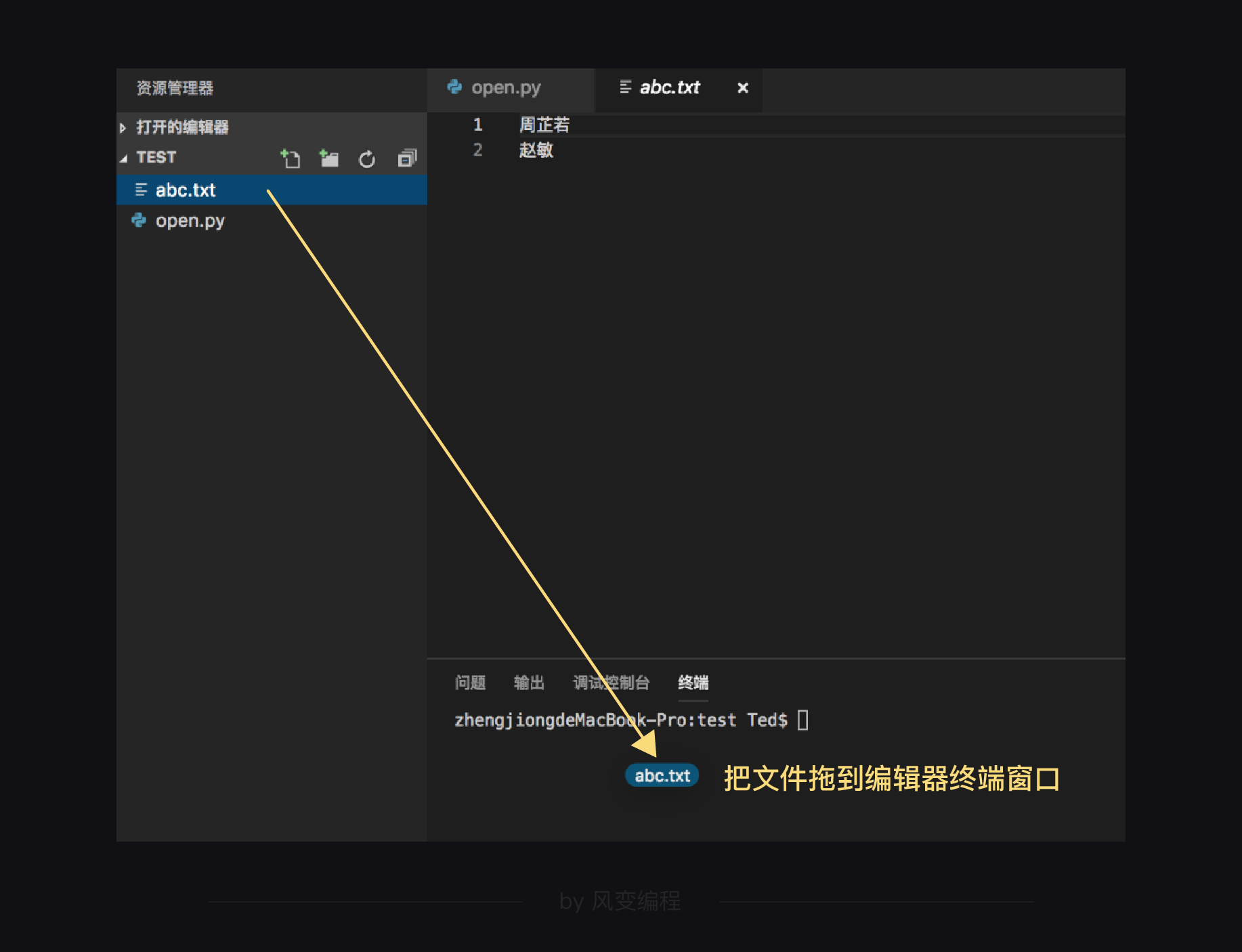
要找到你的文件地址,只需要把你要打开的文件直接拖到编辑器终端的窗口里,就会显示出文件地址,然后复制一下就好。
不过文件的地址有两种:相对路径和绝对路径,拖到终端获取的地址是绝对路径。这两种地址,Mac和Windows电脑还有点傲娇地不太一样,下面我就帮大家捋一捋。
绝对路径就是最完整的路径,相对路径指的就是【相对于当前文件夹】的路径,也就是你编写的这个py文件所放的文件夹路径!
如果你要打开的文件和open.py在同一个文件夹里,这时只要使用相对路径就行了,而要使用其他文件夹的文件则需使用绝对路径。
我们先来看Mac电脑,现在我的txt文件和py文件都放在桌面的test文件夹里。
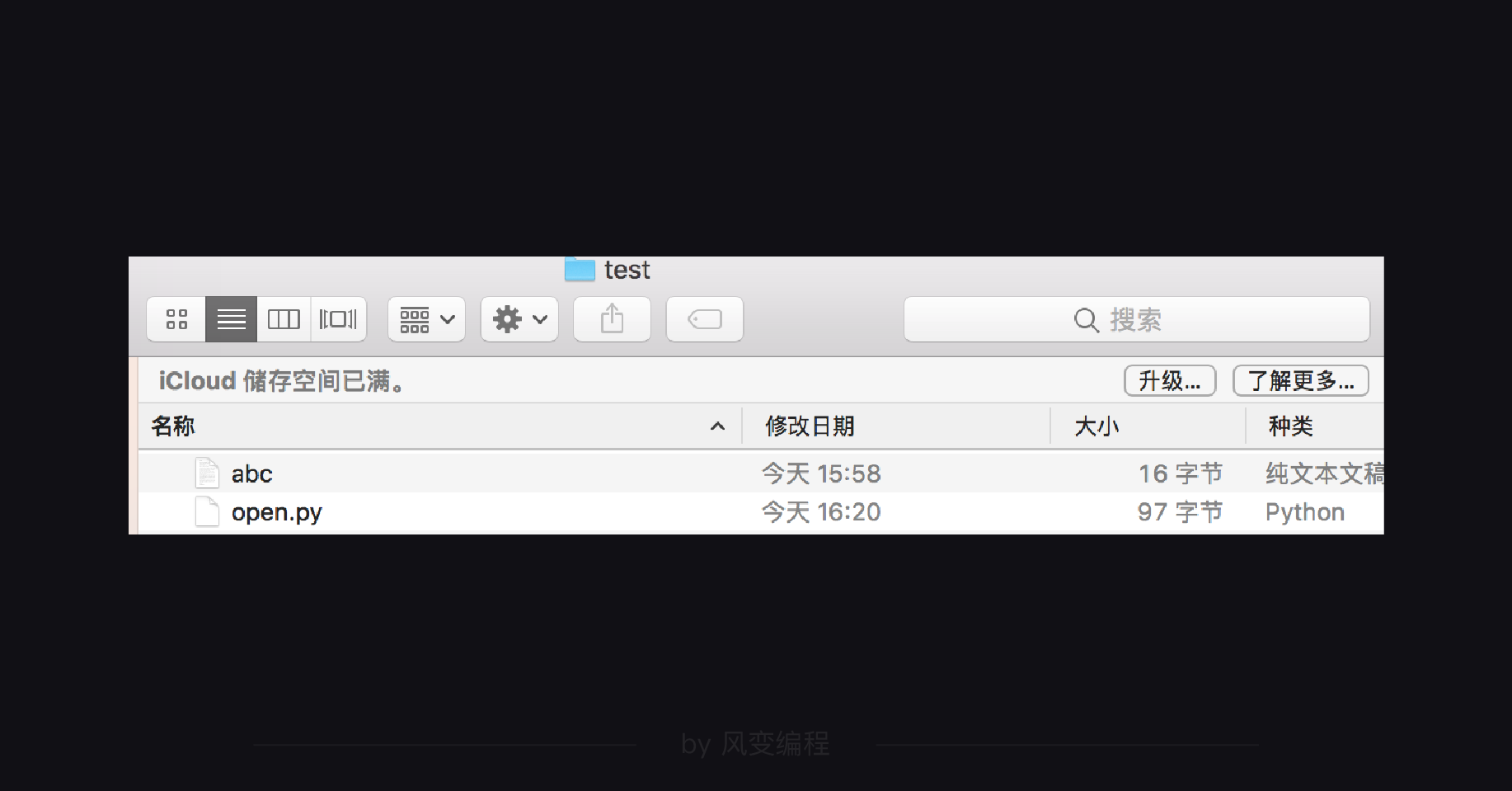
我将txt文件拖入终端窗口,获得文件的绝对路径:
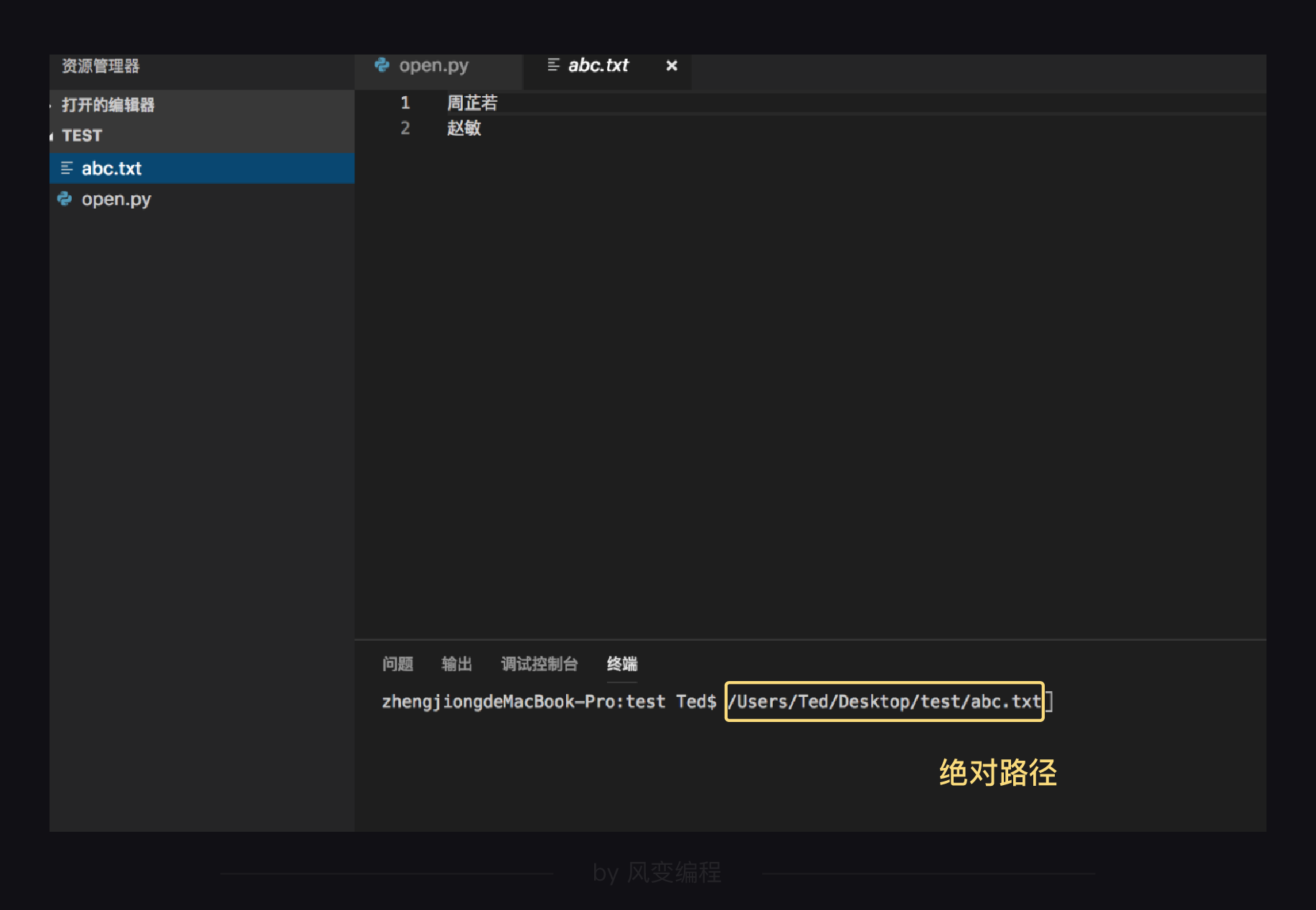
那么当我用open()函数打开的时候,就可以写成:
open('/Users/Ted/Desktop/test/abc.txt') #绝对路径
open('abc.txt') #相对路径
#相对路径也可以写成open('./abc.txt')
在这种情况下,你写绝对和相对路径都是可以的。
假如现在这个txt文件,是放在test文件夹下面一个叫做word的文件夹里,绝对路径和相对路径就变成:
open('/Users/Ted/Desktop/test/word/abc.txt'')
open('word/abc.txt')
我们再来看看Windows。Windows系统里,常用\来表示绝对路径,/来表示相对路径,所以当你把文件拖入终端的时候,绝对路径就变成:
C:\Users\17310\Desktop\test\abc.txt
但是呢,别忘了\在Python中是转义字符,所以时常会有冲突。为了避坑,Windows的绝对路径通常要稍作处理,写成以下两种格式;
open('C:\\Users\\17310\\Desktop\\test\\abc.txt')
#将'\'替换成'\\'
open(r'C:\Users\17310\Desktop\test\abc.txt')
#在路径前加上字母r
获取文件的相对路径还有个小窍门,用VS Code打开文件夹,在文件点击右键,选择:
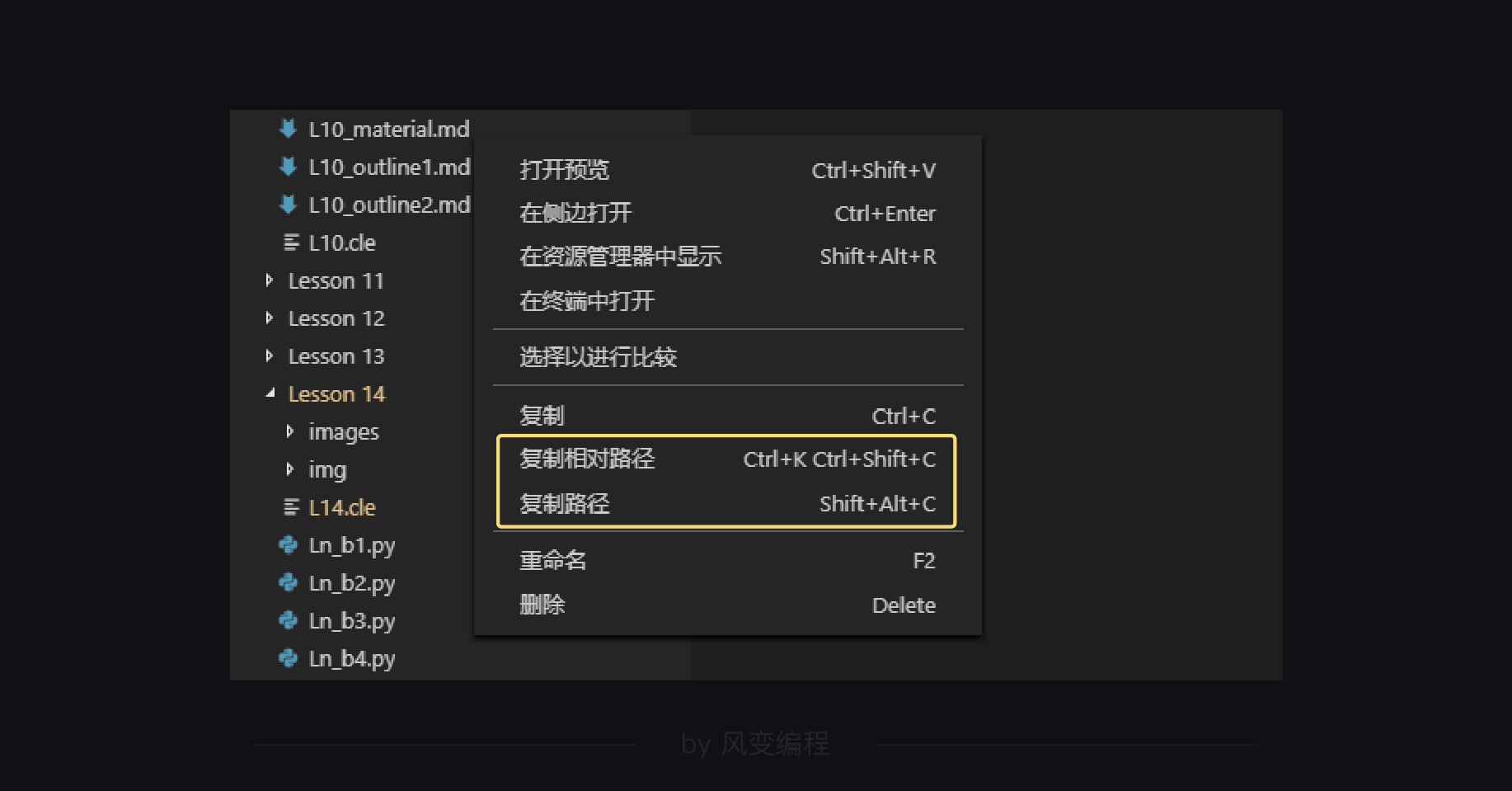
现在,把这行代码复制到你的open.py文件中,然后把文件地址替换成你自己的地址。
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','r',encoding='utf-8')
好了。终于讲完了第一个参数文件地址,我们来回头看看open()的其他参数:
第二个参数表示打开文件时的模式。这里是字符串 'r',表示 read,表示我们以读的模式打开了这个文件。
你可能会疑惑,为什么打开的时候就要决定是读还是写,之后决定不行吗?这是因为,计算机非常注意数据的保密性,在打开时就要决定以什么模式打开文件。
除了'r',其他还有'w'(写入),'a'(追加)等模式,我们稍后会涉及到。
第三个参数encoding='utf-8',表示的是返回的数据采用何种编码,一般采用utf-8或者gbk。注意这里是写encoding而不是encode噢。
读文件的三步:开——读——关,【第1步-开】我们就讲完了,现在看【第2步-读】。
打开文件file1之后,就可以用read()函数进行读取的操作了。请看代码:
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','r',encoding='utf-8')
filecontent = file1.read()
第1行代码是我们之前写的。是以读取的方式打开了文件“abc.txt”。
第2行代码就是在读取file1的内容,写法是变量file1后面加个.句点,再加个read(),并且把读到的内容放在变量filecontent里面,这样我们才能拿到文件的内容。
那么,现在我们想要看看读到了什么数据,可以用print()函数看看。请你在自己的电脑里,把剩下的代码补全,可参考下面的代码
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','r',encoding='utf-8')
filecontent = file1.read()
print(filecontent)
然后,在编辑器窗口【右键】,选择【在终端中运行Python文件】,这时终端显示的是:
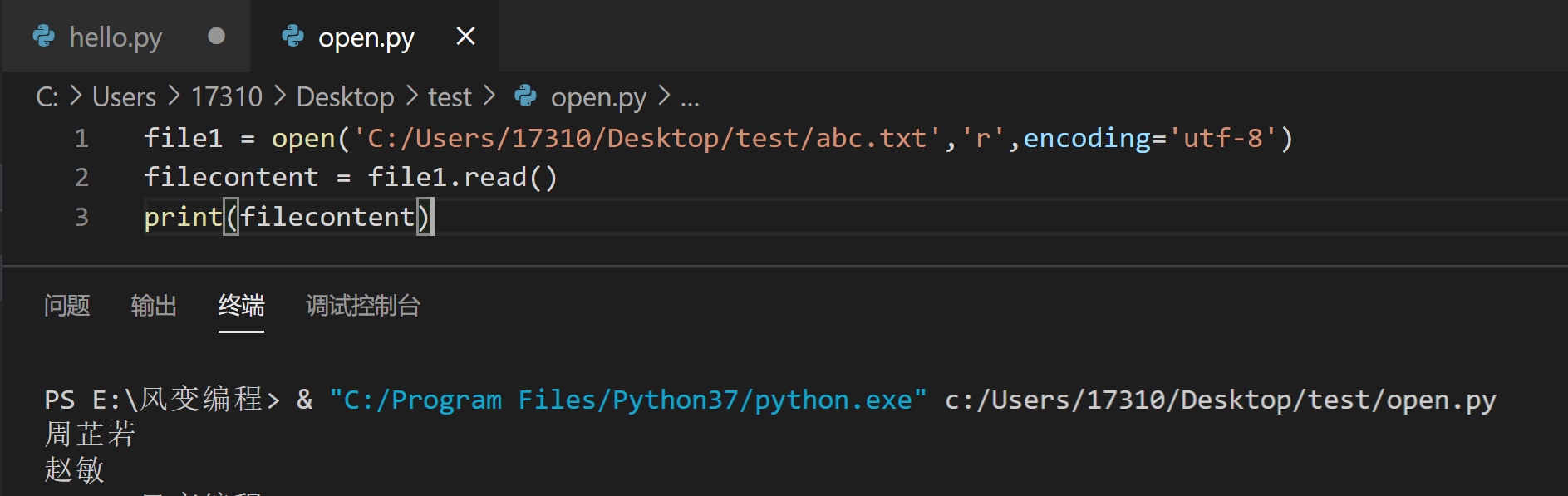
你会发现,打印出了abc.txt文件里面的内容,它会读成字符串的数据形式。
【第3步-关】关闭文件,使用的是close()函数。
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','r',encoding='utf-8')
filecontent = file1.read()
print(filecontent)
file1.close()
前3行代码你都学了,第4行:变量file1后面加个点,然后再加个close(),就代表着关闭文件。千万要记得后面的括号可不能丢。
为啥要关闭文件呢?原因有两个:1.计算机能够打开的文件数量是有限制的,open()过多而不close()的话,就不能再打开文件了。2.能保证写入的内容已经在文件里被保存好了。
文件关闭之后就不能再对这个文件进行读写了。如果还需要读写这个文件的话,就要再次 open() 打开这个文件。
我们总结一下读文件的三步:开——读——关,并奉上一张总结图。
尤其需要留意的是第二、三步,即读和关的写法。
学完了【读文件】,然后是【写文件】。
2.2 写入文件
嘻嘻,写文件也是三步:打开文件——写入文件——关闭文件。
【第1步-开】以写入的模式打开文件。
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','w',encoding='utf-8')
第1行代码:以写入的模式打开了文件"abc.txt"。
open() 中还是三个参数,其他都一样,除了要把第二个参数改成'w',表示write,即以写入的模式打开文件。
【第2步-写】往文件中写入内容,使用write()函数。
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','w',encoding='utf-8')
file1.write('张无忌\n')
file1.write('宋青书\n')
第2-3行代码:往“abc.txt”文件中写入了“张无忌”和“宋青书”这两个字符串。\n表示另起一行。
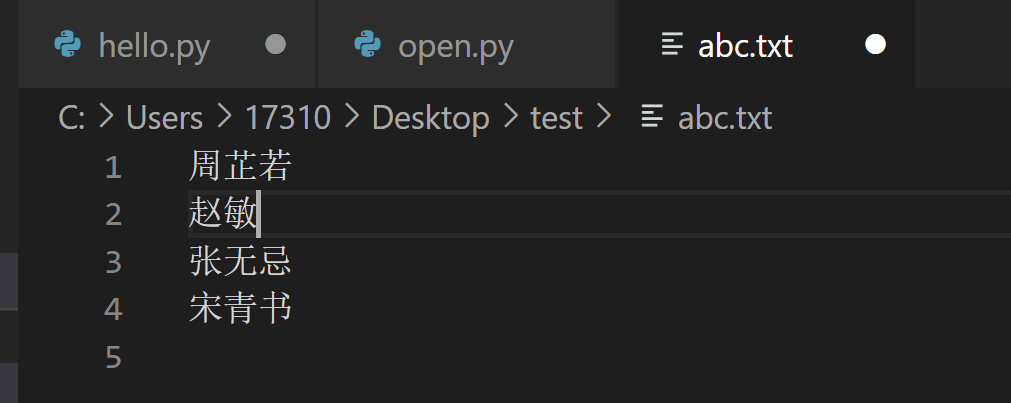
请你原样照做,然后记得运行程序。然后当你打开txt文件查看数据:
诶?原来文件里的周芷若和赵敏去哪里了?
是这样子的,'w'写入模式会给你暴力清空掉文件,然后再给你写入。如果你只想增加东西,而不想完全覆盖掉原文件的话,就要使用'a'模式,表示append,你学过,它是追加的意思。
如果重新再来一遍的话,就要这样写:
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','a',encoding='utf-8')
#以追加的方式打开文件abc.txt
file1.write('张无忌\n')
#把字符串'张无忌'写入文件file1
file1.write('宋青书\n')
#把字符串'宋青书'写入文件file1
这样的话,就会追加成功,而不会覆盖了。你可以随便试试加点什么,运行看看。
【第3步-关】还是要记得关闭文件,使用close()函数,看代码:
file1 = open('C:\\Users\\17310\\Desktop\\test\\abc.txt','a',encoding='utf-8')
file1.write('张无忌\n')
file1.write('宋青书\n')
file1.close()
第4行代码,还是熟悉的配方,还是熟悉的味道。这样就搞定【写文件】了。
不过呢,有两个小提示:1.write()函数写入文本文件的也是字符串类型。2.在'w'和'a'模式下,如果你打开的文件不存在,那么open()函数会自动帮你创建一个
【练习时间来咯】1.请你在一个叫1.txt文件里写入字符串'难念的经' 2.然后请你读取这个1.txt文件的内容,并打印出来。
提示:先写再读。写文件分为3步,读文件也同样分为3步。
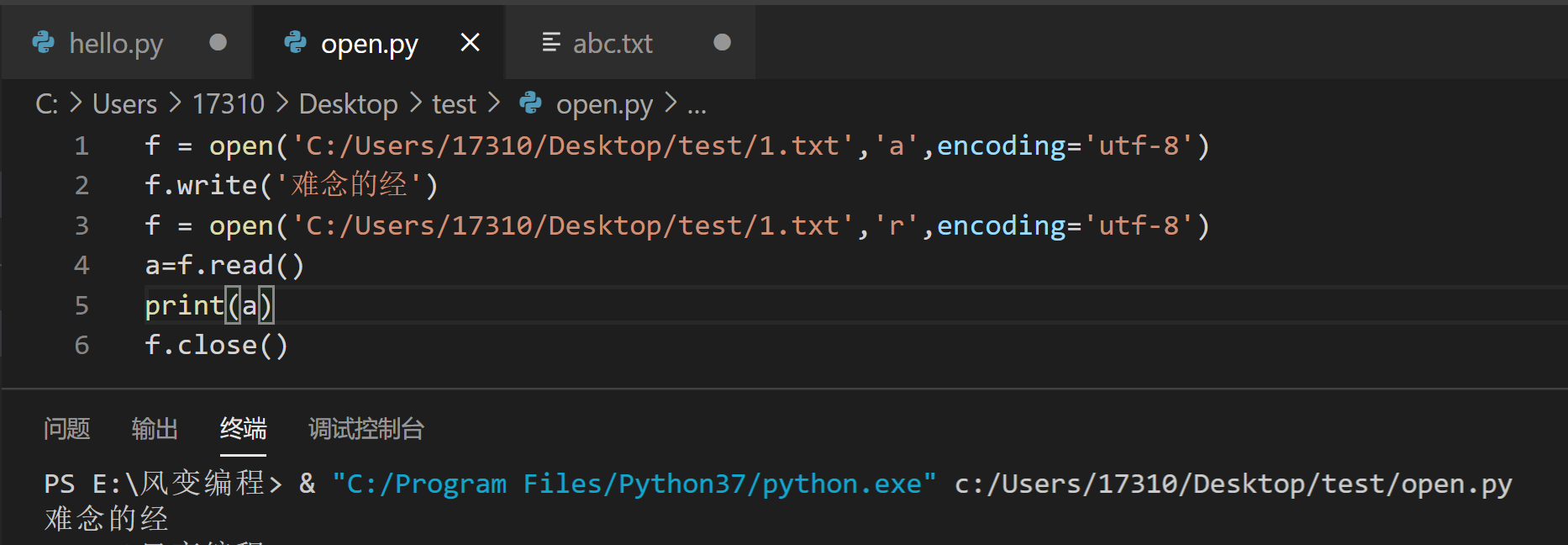
f = open('C:\\Users\\17310\\Desktop\\test\\1.txt','a',encoding='utf-8')
#以追加的方式打开一个文件,尽管并不存在这个文件,但这行代码已经创建了一个txt文件了
f.write('难念的经')
#写入'难念的经'的字符串
f = open('C:\\Users\\17310\\Desktop\\test\\1.txt','r',encoding='utf-8')
#以读的方式打开这个文件
a=f.read()
#把读取到的内容放在变量a里面
print(a)
#打印变量a
f.close()
#关闭文件
我们再来总结下写文件的三步法。
现在问题来了,如果我们想写入的数据不是文本内容,而是音频和图片的话,该怎么做呢?

我们可以看到里面有'wb'的模式,它的意思是以二进制的方式打开一个文件用于写入。因为图片和音频是以二进制的形式保存的,所以使用wb模式就好了,这在今天的课后作业我们会用到。
这里再顺便补充一个用法,为了避免打开文件后忘记关闭,占用资源或当不能确定关闭文件的恰当时机的时候,我们可以用到关键字with,之前的例子可以写成这样:
# 普通写法
file1 = open('abc.txt','a')
file1.write('张无忌')
file1.close()
# 使用with关键字的写法
with open('abc.txt','a') as file1:
#with open('文件地址','读写模式') as 变量名:
#格式:冒号不能丢
file1.write('张无忌')
#格式:对文件的操作要缩进
#格式:无需用close()关闭
所以之后当你看到with open...as这种打开文件的语法格式也要淡定,这种还挺常见的。
2.3 小练习
我们一路到这里,你应该也看出来了,本人非常喜欢《哈利波特》哈哈。
现在假设你来到了魔法世界,最近期末快到了,霍格沃兹魔法学校准备统计一下大家的成绩。
评选的依据是什么呢?就是同学们平时的作业成绩。
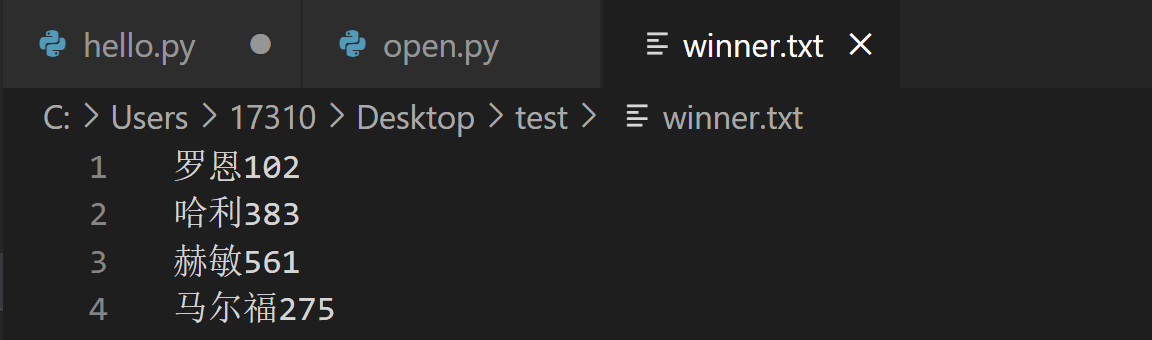
现在有这样一个叫scores.txt的文件,里面有赫敏、哈利、罗恩、马尔福四个人的几次魔法作业的成绩。

但是呢,因为有些魔法作业有一定难度,教授不强制同学们必须上交,所以大家上交作业的次数并不一致。
这里是文件内容,你可以在自己的电脑里新建一个scores.txt来操作。
罗恩 23 35 44
哈利 60 77 68 88 90
赫敏 97 99 89 91 95 90
马尔福 100 85 90
希望你来统计这四个学生的魔法作业的总得分,然后再写入一个txt文件。注意,这个练习的全程只能用Python。
面对这个功能,请你思考30s,粗略地想想该怎么实现?然后点击enter继续。
好,一个非常粗糙的思路应该是:拿到txt文件里的数据,然后对数据进行统计,然后再写入txt文件。好,马上开始。
首先,毫无疑问,肯定是打开文件,还记得用什么函数吗?
file1 = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
接着呢,就是读取文件了。一般来说,我们是用read()函数,但是在这里,我们是需要把四个人的数据分开处理的,我们想要按行处理,而不是一整个处理,所以读的时候也希望逐行读取。
因此,我们需要使用一个新函数readlines(),也就是“按行读取”。
file1 = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
print(file_lines)
用print()函数打印一下,看看这种方法读出来的内容是咋显示的:
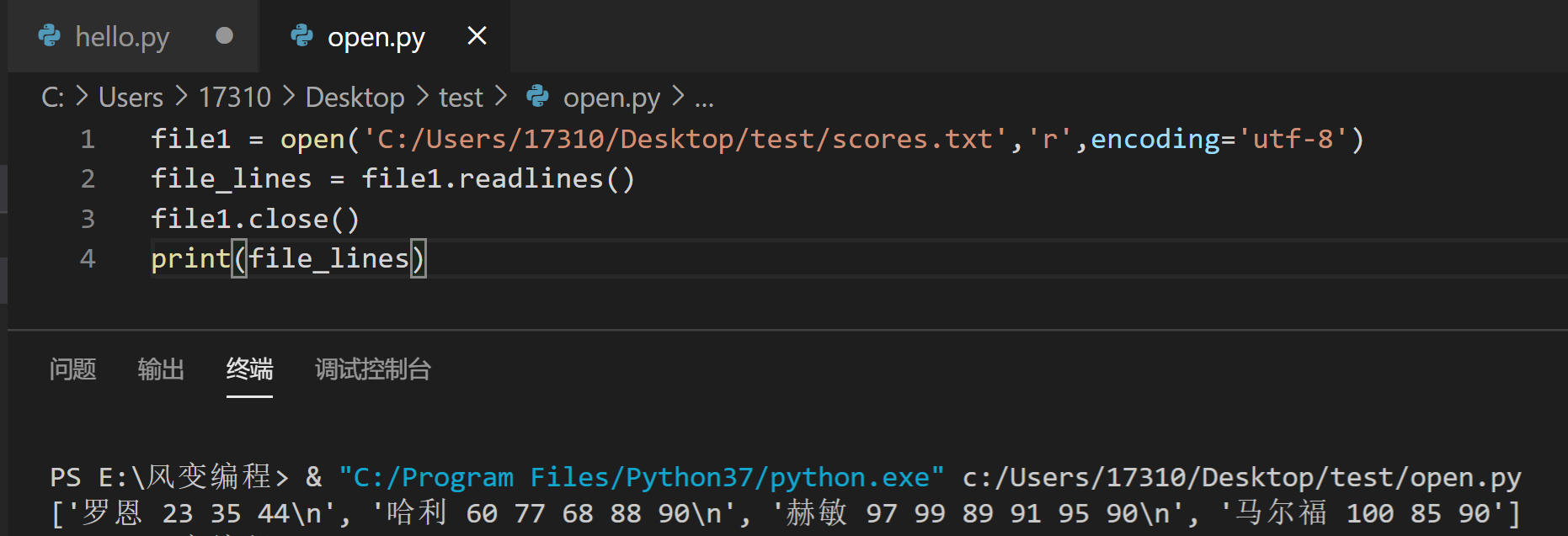
你看到了,readlines() 会从txt文件取得一个列表,列表中的每个字符串就是scores.txt中的每一行。而且每个字符串后面还有换行的\n符号。
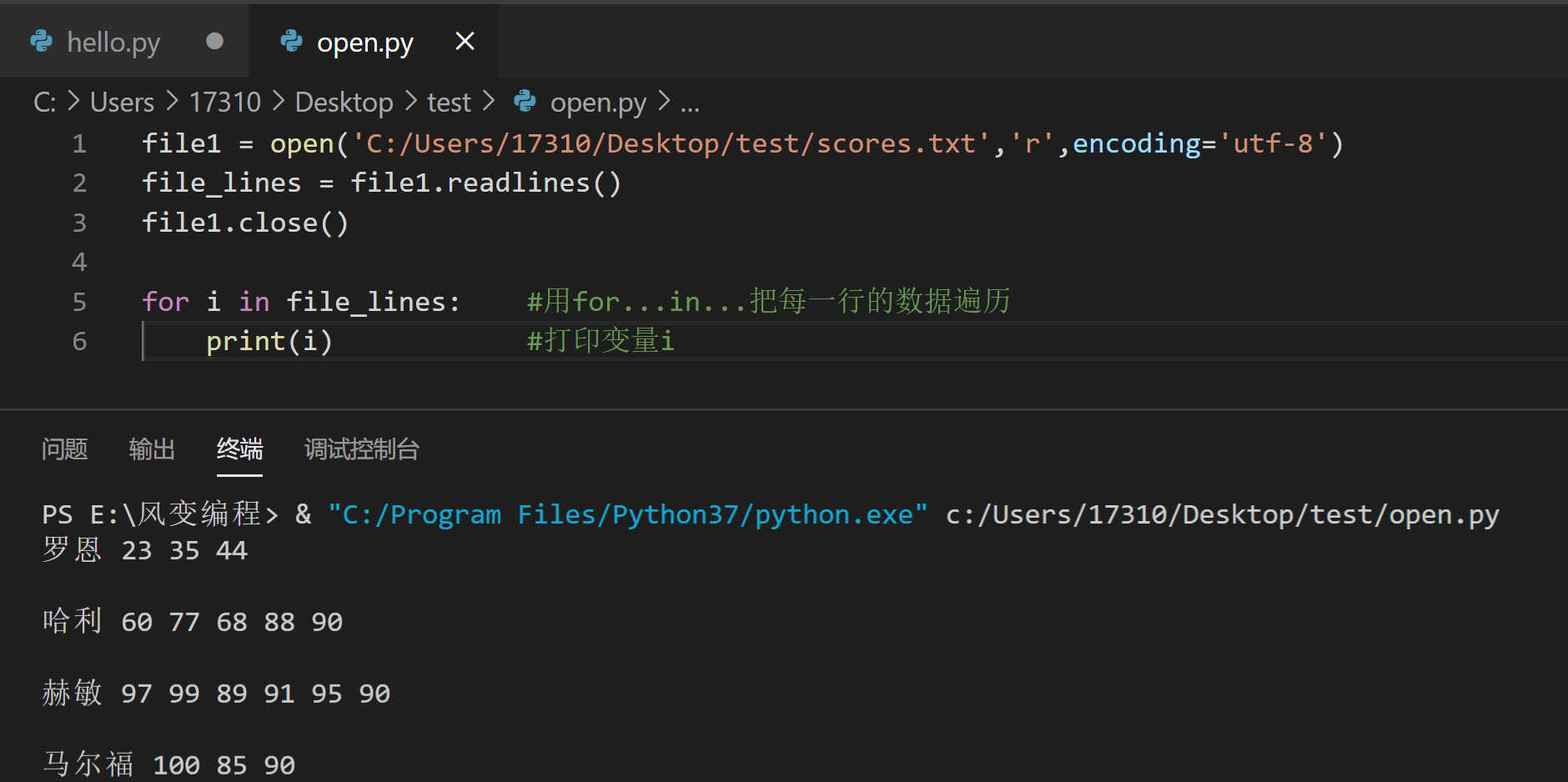
这样一来,我们就可以使用for循环来遍历这个列表,然后处理列表中的数据,请看第五行代码:
file1 = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
for i in file_lines: #用for...in...把每一行的数据遍历
print(i) #打印变量i
我们一样来打印看看。
好,现在我们要把这里每一行的名字、分数也分开,这时需要我们使用split()来把字符串分开,它会按空格把字符串里面的内容分开。
看上图第一行的罗恩 23 35 44,它将被分为['罗恩', '23', '35', '44']。
file1 = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
for i in file_lines: #用for...in...把每一行的数据遍历
data =i.split() #把字符串切分成更细的一个个的字符串
print(data) #打印出来看看
终端是这样的:
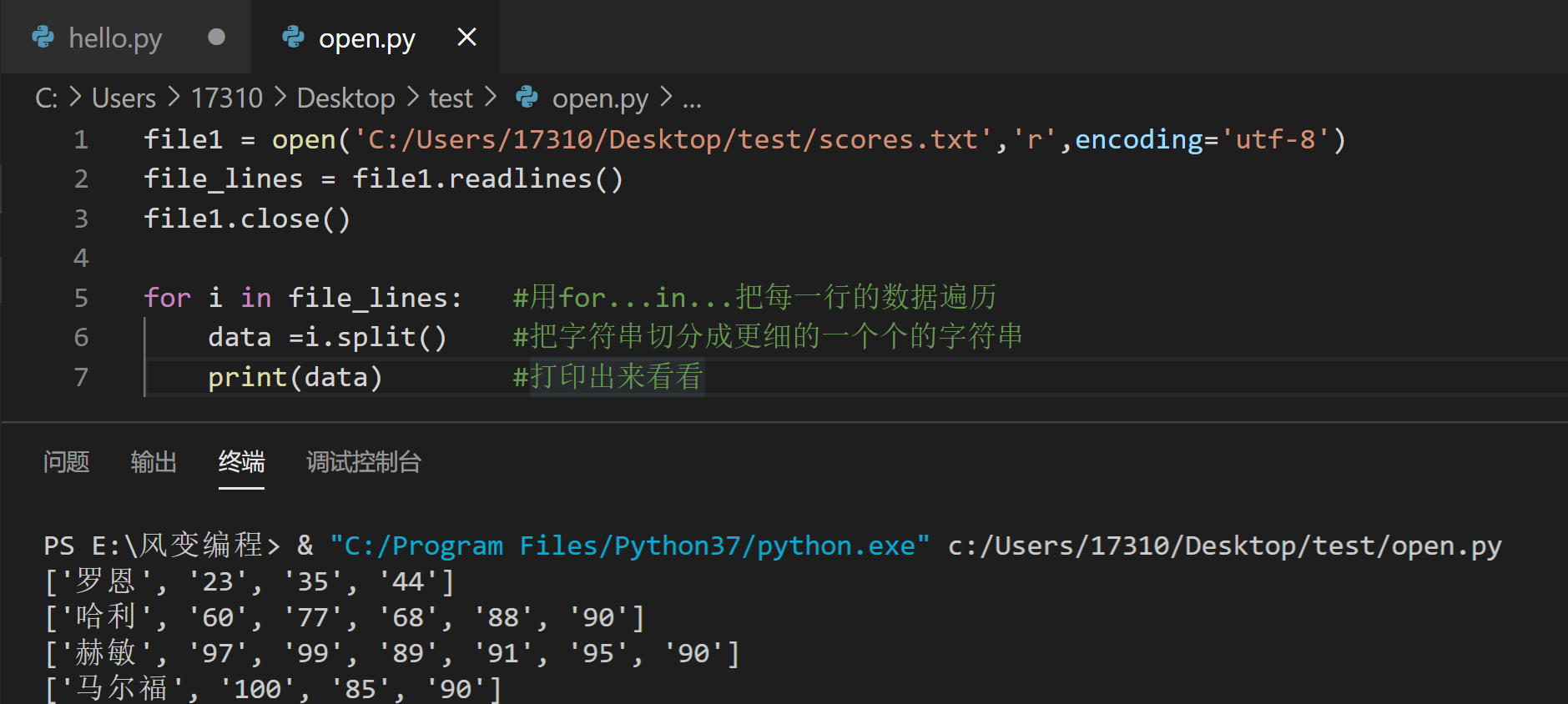
显然,对比上面两个终端的图,split()又把每一行的内容分成了一个个的字符串,于是变成了一个个列表。
split()是我们没有学过的对字符串的处理方法,在这里,老师想插一句,对数据类型的处理是有很多种方法的,但我们不可能一次学完,而应该学习最基础必要的知识,然后在需要用到新知识时,再继续学。
split()是把字符串分割的,而还有一个join()函数,是把字符串合并的。
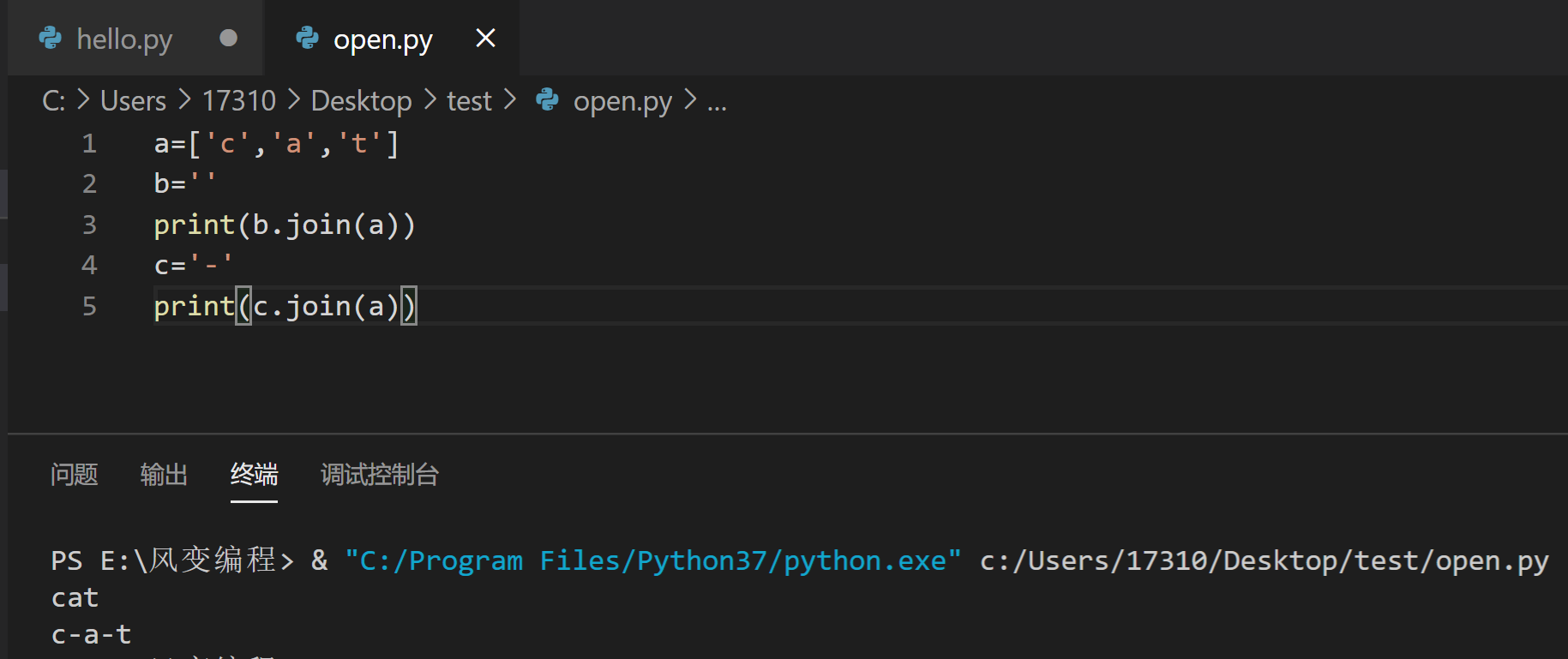
join()的用法是str.join(sequence),str代表在这些字符串之中,你要用什么字符串连接,在这里两个例子,一个是空字符串,一个是横杠,sequence代表数据序列,在这里是列表a。
在这里只是为了让大家理解join(),不需要记忆,之后再用再看就好。
回到哈利波特的那一步:
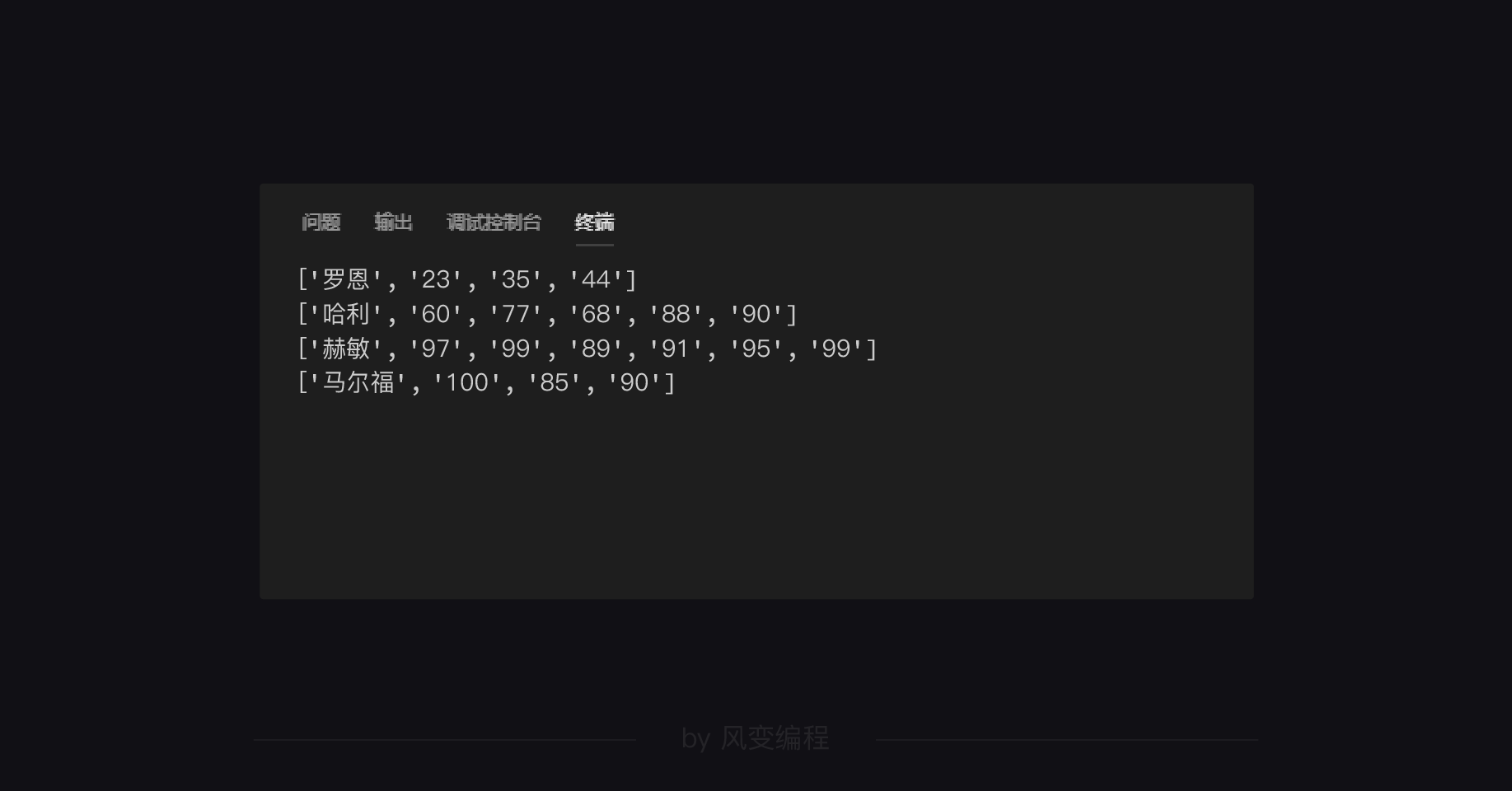
这4个列表的第0个数据是姓名,之后的就是成绩。我们需要先统计各人的总成绩,然后把姓名和成绩放在一起。
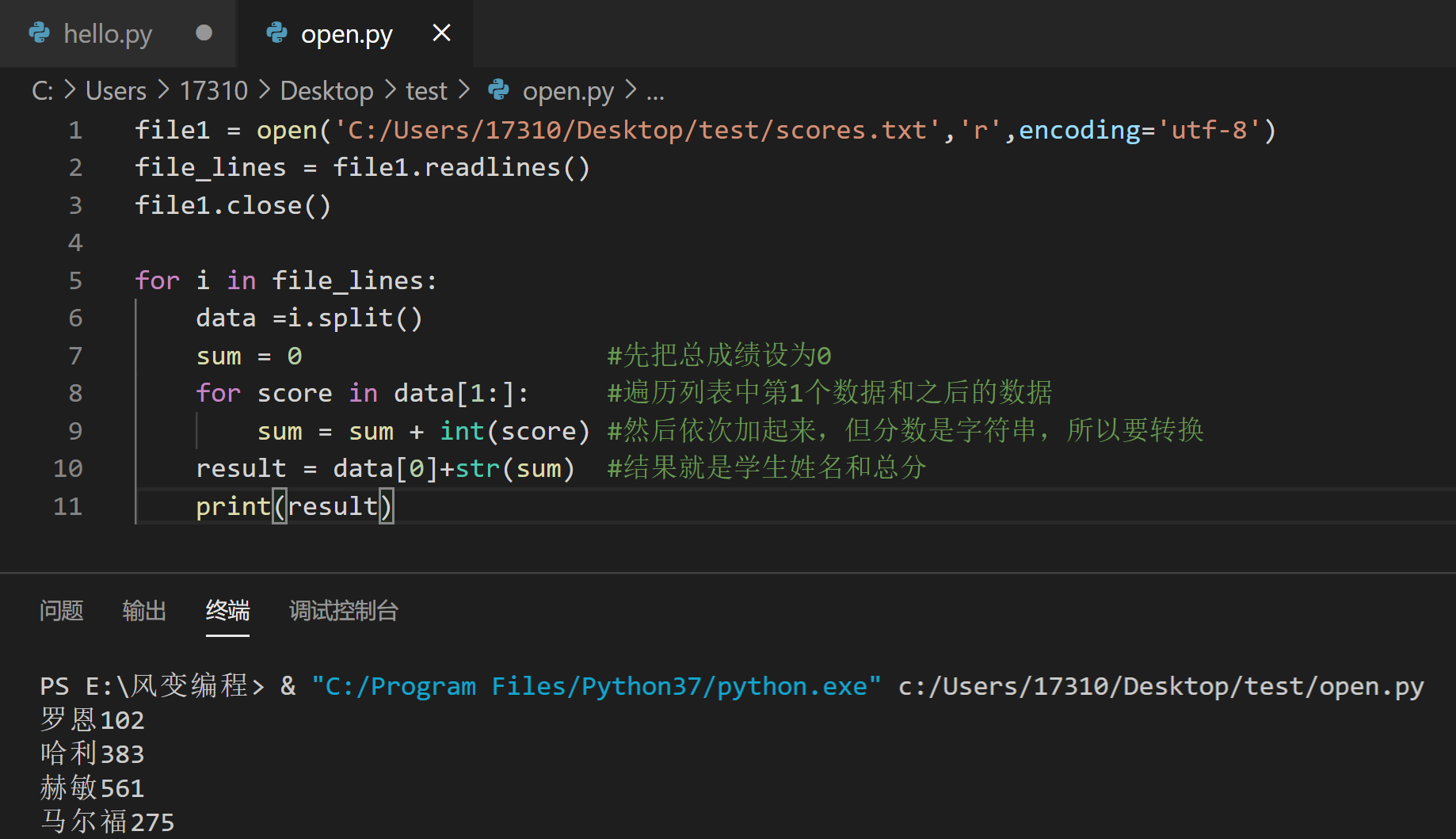
还是可以用for...in...循环进行加法的操作,请看第8行的代码:
file1 = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
for i in file_lines:
data =i.split()
sum = 0 #先把总成绩设为0
for score in data[1:]: #遍历列表中第1个数据和之后的数据
sum = sum + int(score) #然后依次加起来,但分数是字符串,所以要转换
result = data[0]+str(sum) #结果就是学生姓名和总分
print(result)
来看看终端:
好,接下来就是把成绩写入一个空的列表,因为这样才有助于我们之后写入一个txt文件。
file1 = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
final_scores = [] #新建一个空列表
for i in file_lines:
data =i.split()
sum = 0
for score in data[1:]:
sum = sum + int(score)
result = data[0]+str(sum)+'\n' #后面加上换行符,写入的时候更清晰。
final_scores.append(result)#每统计一个学生的总分,就把姓名和总分写入空列表
好啦,那我们就已经处理好了,就差写入文件啦。大家可以从第15行开始看:
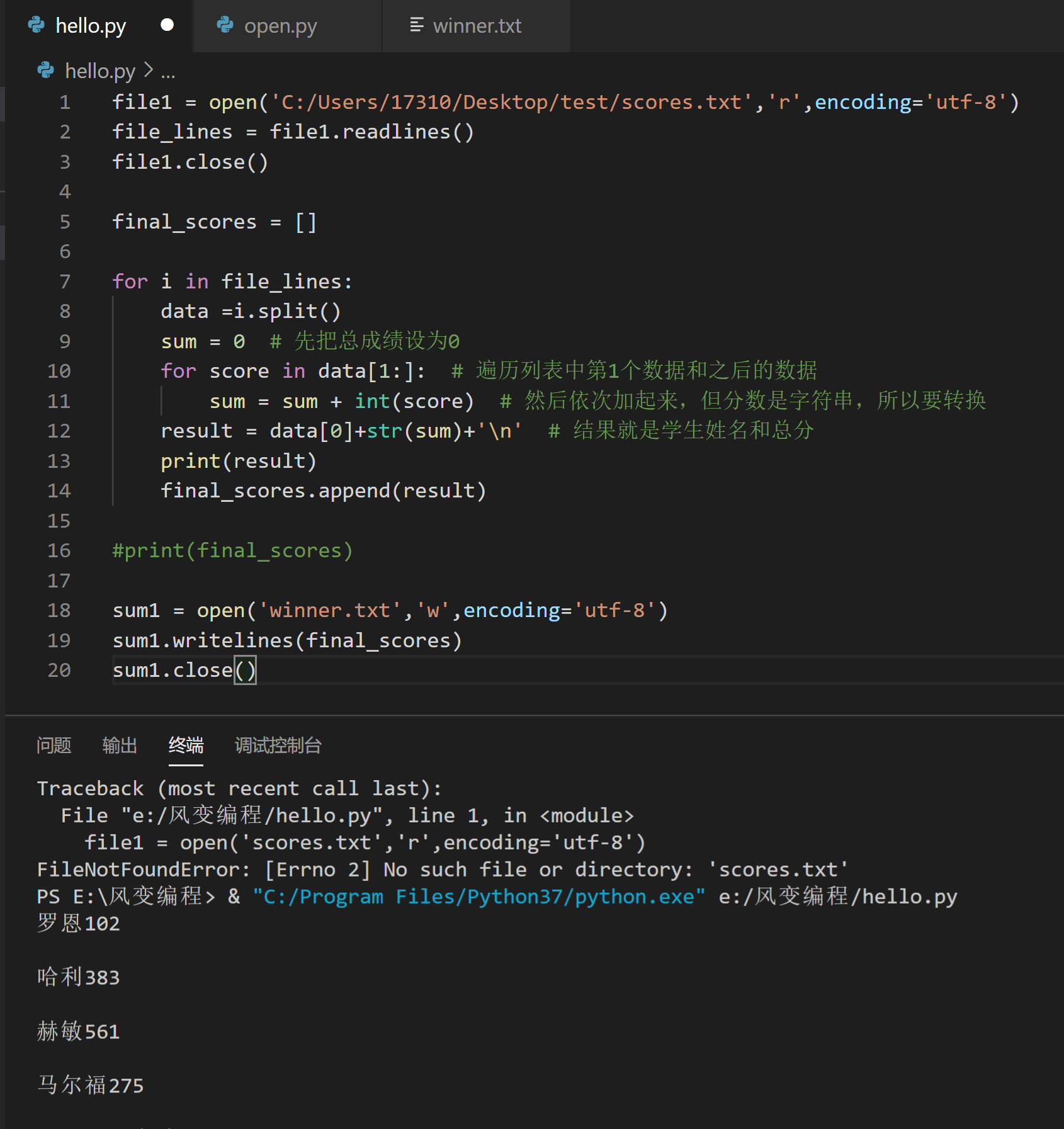
file = open('C:\\Users\\17310\\Desktop\\test\\scores.txt','r',encoding='utf-8')
file_lines = file.readlines()
file.close()
final_scores = []
for i in file_lines:
data =i.split()
sum = 0
for score in data[1:]:
sum = sum + int(score)
result = data[0]+str(sum)+'\n'
final_scores.append(result)
winner = open('C:\\Users\\17310\\Desktop\\test\\winner.txt','w',encoding='utf-8')
winner.writelines(final_scores)
winner.close()
15行的代码是打开一个叫winner.txt的文件。(如果电脑中不存在winner.txt的话,这行代码会帮你自动新建一个空白的winner.txt)
16行的代码是以writelines()的方式写进去,为什么不能用write()?因为final_scores是一个列表,而write()的参数必须是一个字符串,而writelines()可以是序列,所以我们使用writelines()。
17行代码是关闭文件。
3. 习题练习
3.1 习题一
1.练习介绍
我们会通过今天的作业,复习课堂上学到的知识:编码和解码以及文件读写。
2.练习要求
今天的练习包含3个小练习
练习1:主要是想要你自己来动手操作一下编码和解码;
练习2:尝试一下图片的读写;
练习3:完成文件转移之间的数据处理,让数据发生变化。
3.请你根据代码中的要求,一步一步完成。
4.练习2:通过文件读写,复制图片
请你通过文件读写命令,读取 photo1 里的数据(提示见代码区开头)。
然后,新建名为“photo2”的图片(在同一个文件夹),写入读到的数据。
这样,我们就通过文件读写的代码,完成了图片的复制(而非鼠标右键)。
# 先打开图片
file = open('C:\\Users\\17310\\Desktop\\test\\photo1.png','rb') #以“rb”模式打开图片
data = file.read()
newfile = open('C:\\Users\\17310\\Desktop\\test\\photo2.png','wb') #以“wb”模式写入
newfile.write(data)
5.练习3:在读写之间处理数据-1
在课堂上,我们已经见识过了:文件的一读一写之间,可以对数据进行一定的处理。
请你运行一次下侧的代码,重新体验一下那个过程。
file1 = open('C:\\Users\\17310\\Desktop\\test\\/scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
final_scores = []
for i in file_lines:
data =i.split()
sum = 0 # 先把总成绩设为0
for score in data[1:]: # 遍历列表中第1个数据和之后的数据
sum = sum + int(score) # 然后依次加起来,但分数是字符串,所以要转换
result = data[0]+str(sum)+'\n' # 结果就是学生姓名和总分
print(result)
final_scores.append(result)
#print(final_scores)
sum1 = open('C:\\Users\\17310\\Desktop\\test\\winner.txt','w',encoding='utf-8')
sum1.writelines(final_scores)
sum1.close()
6.练习3:在读写之间处理数据-2
现在,我们计划对课堂上得到的“winner”文档再行处理一下。
让学员的成绩从高到低排列,然后放到新文档“winner_new.txt”。
# 下面注释掉的代码,皆为检验代码(验证每一步的思路和代码是否达到目标,可解除注释后运行)。
file1 = open('C:\\Users\\17310\\Desktop\\test\\winner.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
dict_scores = {}
list_scores = []
final_scores = []
# print(file_lines)
# print(len('\n'))
# 打印结果为:['罗恩102\n', '哈利383\n', '赫敏570\n', '马尔福275\n']
# 经过测试,发现'\n'的长度是1。所以,名字是“第0位-倒数第5位”,分数是“倒数第4位-倒数第二位”。
# 再根据“左取右不取”,可知:name-[:-4],score-[-4:-1]
for i in file_lines: # i是字符串。
#print(i)
name = i[:-4] # 取出名字(注:字符串和列表一样,是通过偏移量来获取内部数据。)
score = int(i[-4:-1]) # 取出成绩
#print(name)
# print(score)
dict_scores[score] = name # 将名字和成绩对应存为字典的键值对(注意:这里的成绩是键)
list_scores.append(score)
# print(list_scores)
list_scores.sort(reverse=True) # reverse,逆行,所以这时列表降序排列,分数从高到低。
#print(list_scores)
for i in list_scores:
result = dict_scores[i] + str(i) + '\n'
# print(result)
final_scores.append(result)
#print(final_scores) # 最终结果
winner_new = open('C:\\Users\\17310\\Desktop\\test\\winner_new.txt','w',encoding='utf-8')
winner_new.writelines(final_scores)
winner_new.close()
3.2 习题二
1.练习介绍
这个练习,会让你学会一种方法,可以直接修改原文件中的数据。
2.练习要求
语文老师将一些古诗存在txt文档里,一句一行。
最近,他计划抽一些古诗,自己设置一些空来让学生默写。
请你用代码帮老师完成这项工作(只要处理了一个文档,加上循环就能处理无数个文档了)。
3.明确目标
请看下侧的讲解,明确我们要达成的目标。
我们以李商隐的《锦瑟》为例,这是原文档里的内容:
锦瑟
[唐] 李商隐
锦瑟无端五十弦,
一弦一柱思华年。
庄生晓梦迷蝴蝶,
望帝春心托杜鹃。
沧海月明珠有泪,
蓝田日暖玉生烟。
此情可待成追忆,
只是当时已惘然。
老师在这首诗想考学生“一弦一柱思华年。”和“只是当时已惘然。”,即他想得到的是:
锦瑟
[唐] 李商隐
锦瑟无端五十弦,
__。
庄生晓梦迷蝴蝶,
望帝春心托杜鹃。
沧海月明珠有泪,
蓝田日暖玉生烟。
此情可待成追忆,
__。
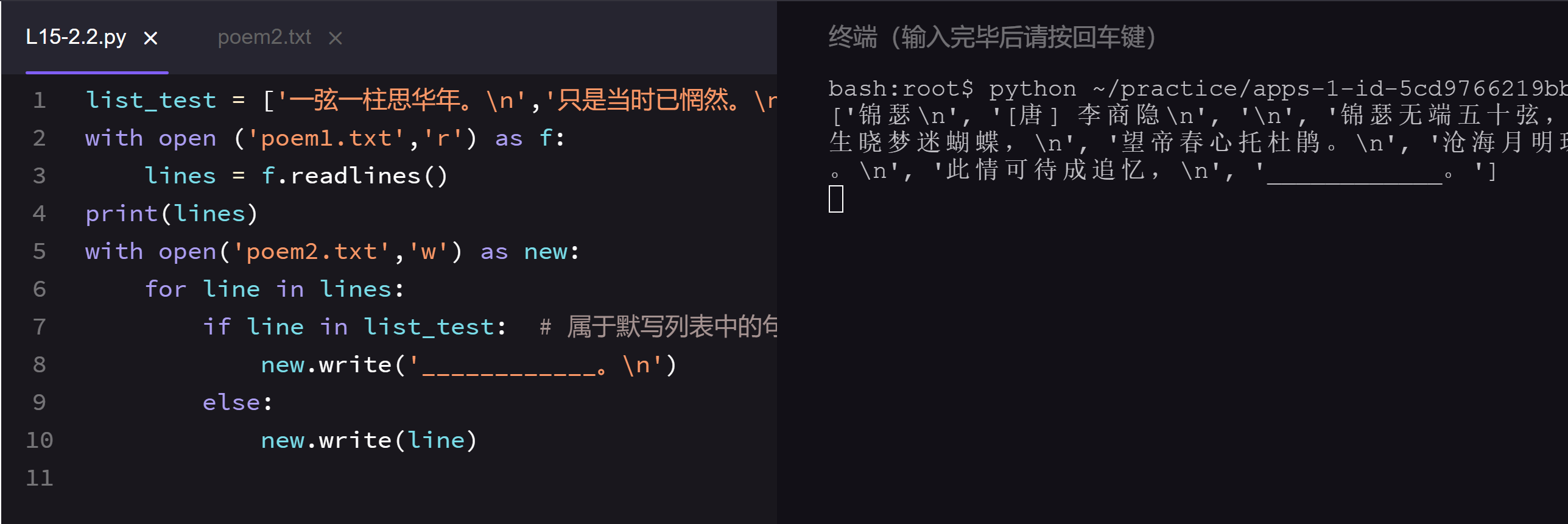
4.具体的方法见上侧的代码区,请认真阅读每一行代码和每一个注释。
然后,你就可以为老师在原文档上截取古诗了。