【第一部分】视频学习心得
1.PyTorch 和 TensorFlow 的区别
疫情居家期间了解过TensorFlow框架,是由Google团队开发,框架比较复杂而且配置环境要求也很高。
我们知道GPU对图形处理的能力是非常的强大,吴恩达教授也是将GPU应用于CNN网络中。
运用NVIDIA的GPU结合cuda加速,可以提速70倍。
基于TensorFlow框架,Google团队也研发了专门的TPU(张量处理器)图像处理器。
视频里也说明了
PyTorch 和 TensorFlow 的区别:
或许可以这样理解 “一个像 matlab,一个像 C++”,
TensorFlow 的编程更难一些,主要对静态图像的处理。
PyTorch 现在学术圈使用的更多 ,主要对动态图像的处理。

2.Hinton教授40年的贡献
被称为“神经网络之父”、“深度学习鼻祖”
我们都是站在巨人的肩膀上去探索,Hinton教授用40年开发了CNN(卷积神经网络)
他为现代深度学习奠定了基础,创立了加拿大先进研究院(Canadian Institute of Advanced Research, CIFAR)的基金
有了现在世界级的比赛神经信息处理系统大会(NeurIPS)提供图像分类数据集CIFAR-10分类、CIFAR-100分类

3.吴恩达、李飞飞、何恺明等华人在机器学习的研究
吴恩达:首个提出运用NVIDIA的GPU结合cuda加速,可以提速70倍。
李飞飞:斯坦福教授,建立大型机器学习和视觉理解知识库做出了贡献
何恺明:目前是Facebook AI Research(FAIR)的研究科学家,主要还是CV方向

这个何恺明的个人站点里面也会有他最新的科研论文http://kaiminghe.com/
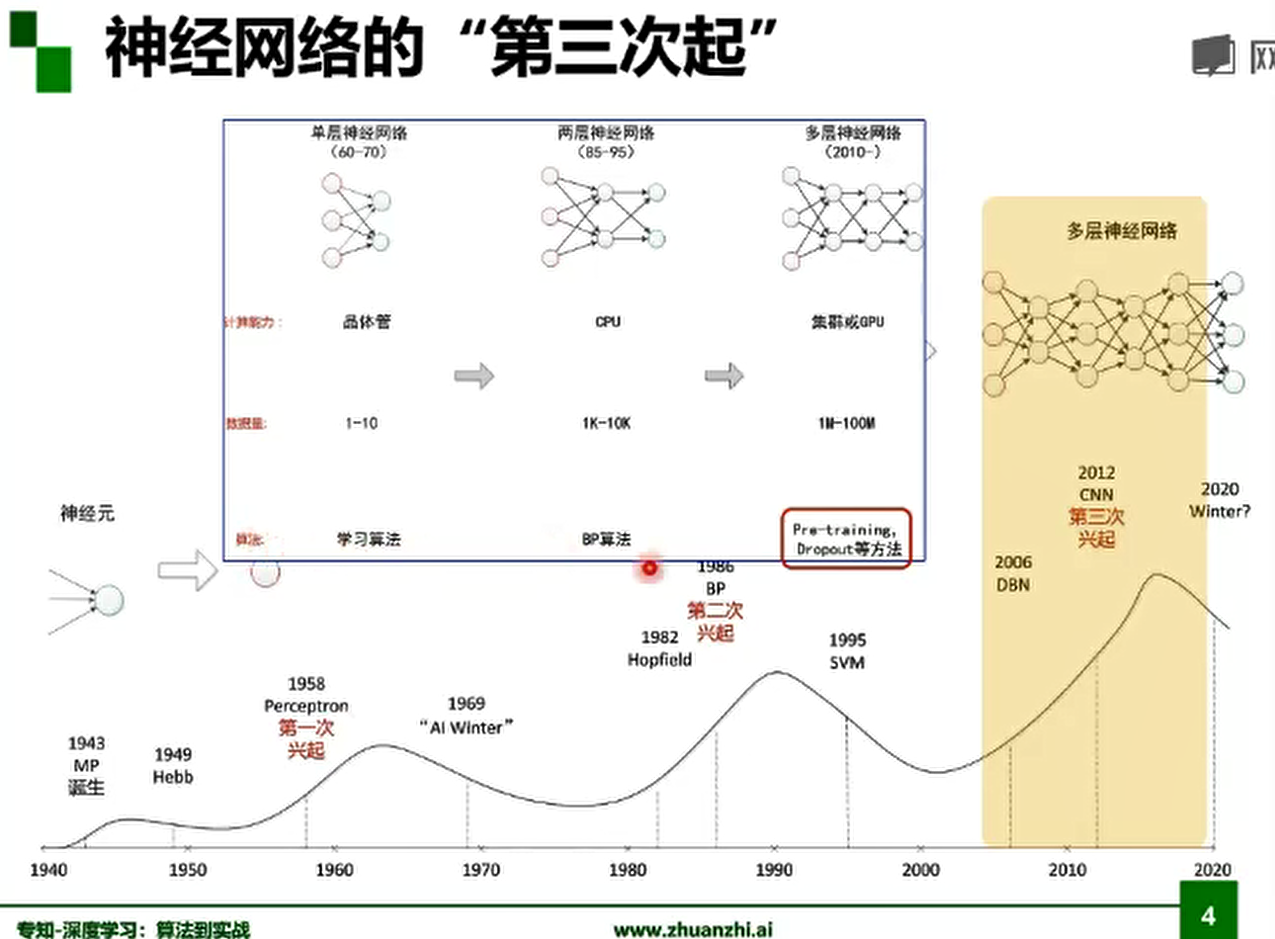
4.神经网络三起三落的思考
三起是我们人类突破了旧的神经网络,研发出更加高效的准确的神经网络。
三落是对新神经网络的运用没有达到我们想要的现实运用和对经济的推动作用。
但是,目前我们可以看到机器学习和人工智能在悄悄的改变和走进我们的生活。
自动驾驶出租车已经开始在上海运行了,达到无人驾只是时间的问题。
深度学习的基础是大量数据集的训练,不断增强模型的鲁棒性
2020不会是深度学习一个寒冬期的开始。
新冠的爆发,机器辅助医生识别肺片,阿里巴巴运用深度学习不断训练他们的模型
【第二部分】代码练习
1.搭建Colab环境
谷歌的 Colab,它是一个 Jupyter 笔记本云环境,已经默认安装好 PyTorch
不需要进行任何设置就可以使用,并且完全在云端运行。
云计算也是未来的趋势,我们的代码可以不用在本地配置不高的电脑上跑。
利用云端服务器集群集中算力,可以大大减少运行时间和资源的集中运用。
运用Google的Colab相当于虚拟出高性能的Linux云服务器,在上面跑代码可以在8s面内对图像的处理(如下图)。

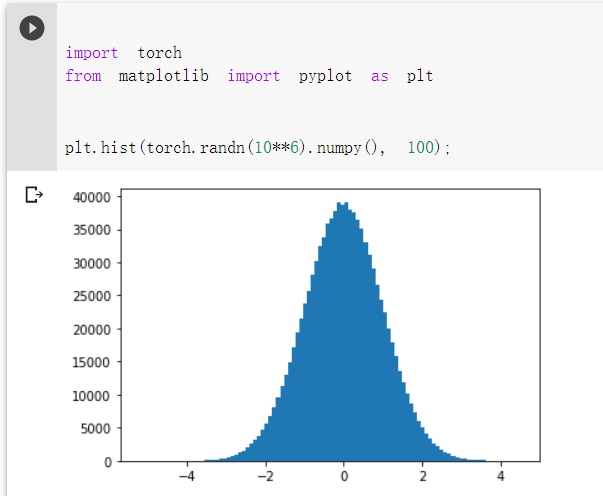
2.简单画图
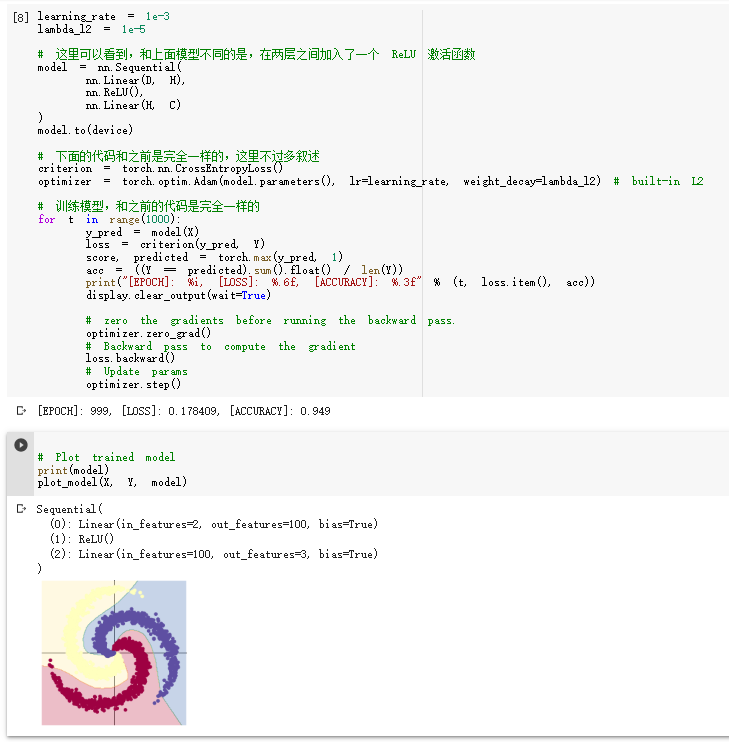
3.螺旋数据分类
4.回归分析

【第三部分】进阶练习
这一部分主要根据老师提供的源码,在Colab上跑,自己也在不断地尝试调参。
使结果的Loss减低,增加Acc的结果
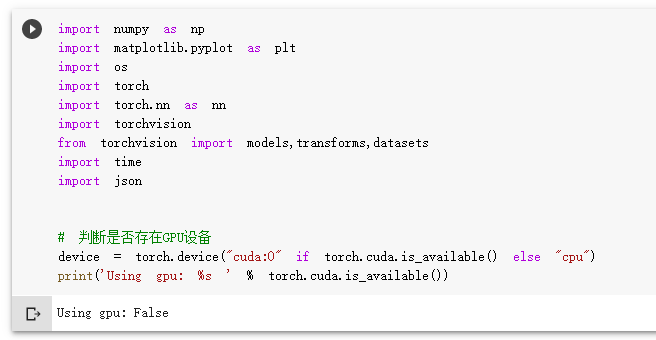
1.导入相关库
导入相关库
检查是否在使用GPU设备(Colab)
2.下载数据集
3.数据处理

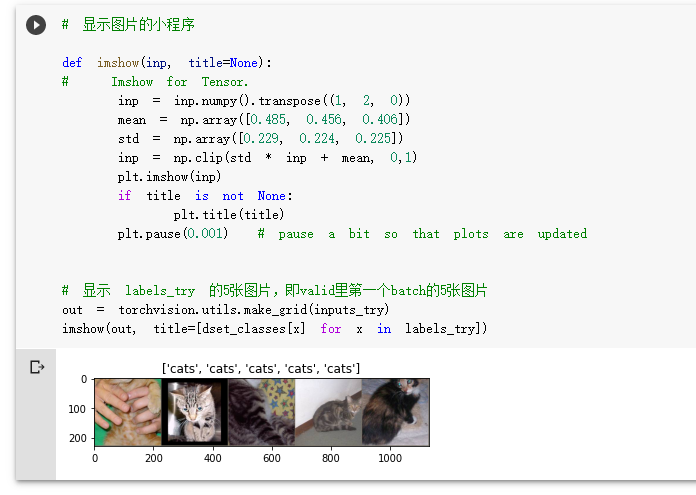
4.创建VGG Model
直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果。
在这部分代码中,对输入的5个图片利用VGG模型进行预测。
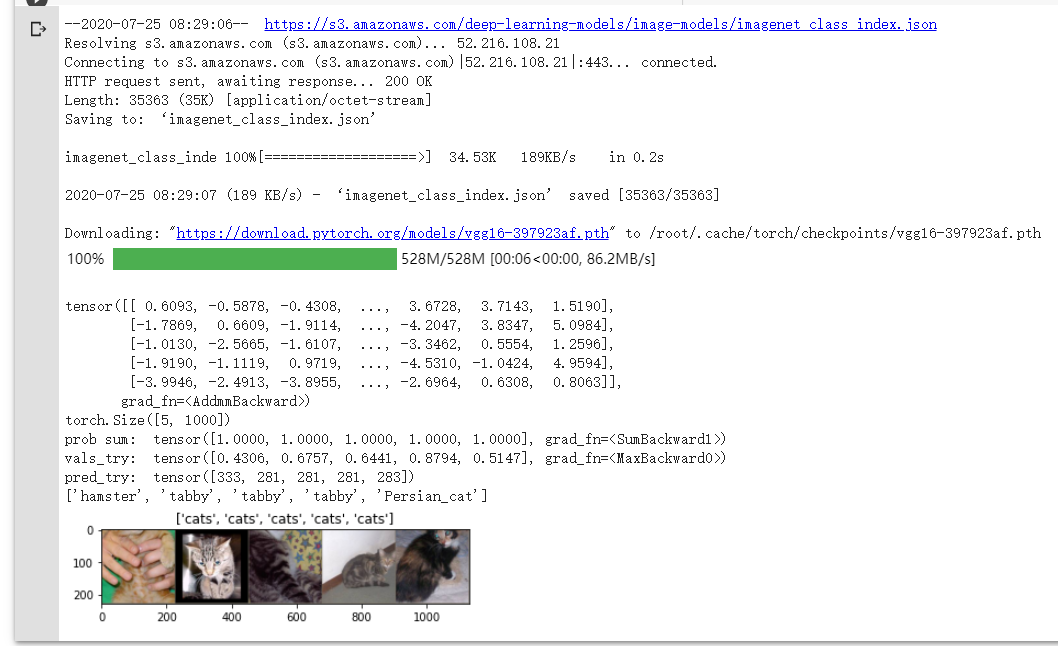
5.训练并测试模型
第1步,创建损失函数和优化器;
第2步,训练模型;
第3步,测试模型。
''' 第一步:创建损失函数和优化器 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签. 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络. ''' criterion = nn.NLLLoss() # 学习率 lr = 0.001 # 随机梯度下降 optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(), lr = lr) ''' 第二步:训练模型 ''' def train_model(model, dataloader, size, epochs = 1, optimizer = None): model.train() for epoch in range(epochs): running_loss = 0.0 running_corrects = 0 count = 0 for inputs, classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs, classes) optimizer = optimizer optimizer.zero_grad() loss.backward() optimizer.step() _,preds = torch.max(outputs.data, 1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) count += len(inputs) print('Training: No. ', count, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc)) # 模型训练 train_model(model_vgg_new, loader_train, size = dset_sizes['train'], epochs = 1, optimizer = optimizer_vgg)

# 测试两千个模型的准确率 def test_model(model,dataloader,size): model.eval() predictions = np.zeros(size) all_classes = np.zeros(size) all_proba = np.zeros((size,2)) i = 0 running_loss = 0.0 running_corrects = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) predictions[i:i+len(classes)] = preds.to('cpu').numpy() all_classes[i:i+len(classes)] = classes.to('cpu').numpy() all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() i += len(classes) print('Testing: No. ', i, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) return predictions, all_proba, all_classes predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])
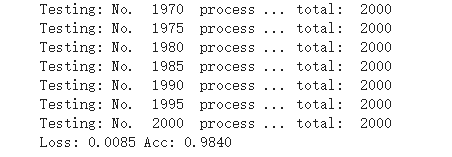
【第三部分】总结
第一部分视频的学习,初步对深度学习的了解。
第二部分简单demo的练习,了解了PyTorch对图像的不同处理方法。
第三部分主要还是根据老师提供的代码。在Colab上的训练,通过改变参数减低Loss,增强Acc的数值
也尝试将VGG16跟换成VGG19,对结果有所提高。
总觉得自己在学习过程中浮于表面,没有深入的去研究和试错。
最后,还是对VGG模型原理不了解,只是在不断地调试epochs的数值增强模型