简介: 在高性能的背后,Java 的启动性能差也令人印象深刻,大家印象中的 Java 笨重缓慢的印象也大多来源于此。高性能和快启动速度似乎有一些相悖,本文将和大家一起探究两者是否可以兼得。
作者 | 梁希
高性能和快启动速度,能否鱼和熊掌兼得?
Java 作为一门面向对象编程语言,在性能方面的卓越表现独树一帜。
《Energy Efficiency across Programming Languages,How Does Energy, Time, and Memory Relate?》这份报告调研了各大编程语言的执行效率,虽然场景的丰富程度有限,但是也能够让我们见微知著。
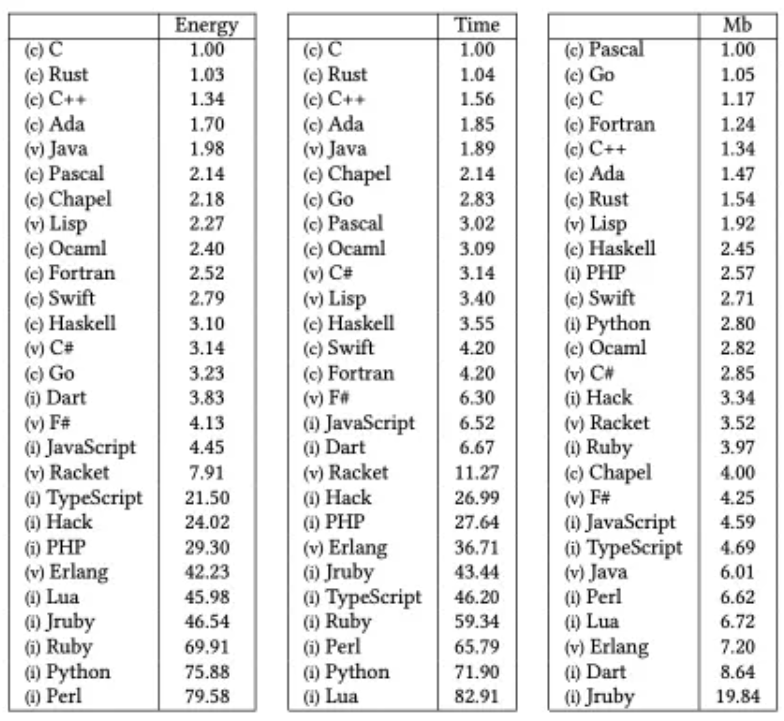
Java 的优异性能得益于 Hotspot 中非常优秀的 JIT 编译器。Java 的 Server Compiler(C2) 编译器是 Cliff Click 博士的作品,使用了 Sea-of-Nodes 模型。而这项技术,也通过时间证明了它代表了业界的最先进水平:
- 著名的 V8(JavaScript 引擎)的 TurboFan 编译器使用了相同的设计,只是用更加现代的方式去实现;
- Hotspot 使用 Graal JVMCI 做 JIT 时,性能基本与 C2 持平;
- Azul 的商业化产品将 Hotspot 中的 C2 compiler 替换成 LLVM,峰值性能和 C2 也是持平。
在高性能的背后,Java 的启动性能差也令人印象深刻,大家印象中的 Java 笨重缓慢的印象也大多来源于此。高性能和快启动速度似乎有一些相悖,本文将和大家一起探究两者是否可以兼得。
JAVA 启动慢的根因
1、框架复杂
JakartaEE 是 Oracle 将 J2EE 捐赠给 Eclipse 基金会后的新名字。Java 在1999年推出时便发布了 J2EE 规范,EJB(Java Enterprise Beans) 定义了企业级开发所需要的安全、IoC、AOP、事务、并发等能力。设计极度复杂,最基本的应用都需要大量的配置文件,使用非常不便。
随着互联网的兴起,EJB 逐渐被更加轻量和免费的 Spring 框架取代,Spring 成了 Java 企业开发的事实标准。Spring 虽然定位更加轻量,但是骨子里依然很大程度地受 JakartaEE 的影响,比如早期版本大量 xml 配置的使用、大量 JakartaEE 相关的注解(比如JSR 330依赖注入),以及规范(如JSR 340 Servlet API)的使用。
但 Spring 仍是一个企业级的框架,我们看几个 Spring 框架的设计哲学:
- 在每一层都提供选项,Spring 可以让你尽可能的推迟选择。
- 适应不同的视角,Spring 具有灵活性,它不会强制为你决定该怎么选择。它以不同的视角支持广泛的应用需求。
- 保持强大的向后兼容性。
在这种设计哲学的影响下,必然存在大量的可配置和初始化逻辑,以及复杂的设计模式来支撑这种灵活性。我们通过一个试验来看:
我们跑一个spring-boot-web的helloword,通过-verbose:class可以看到依赖的class文件:
$ java -verbose:class -jar myapp-1.0-SNAPSHOT.jar | grep spring | head -n 5
[Loaded org.springframework.boot.loader.Launcher from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar]
[Loaded org.springframework.boot.loader.ExecutableArchiveLauncher from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar]
[Loaded org.springframework.boot.loader.JarLauncher from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar]
[Loaded org.springframework.boot.loader.archive.Archive from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar]
[Loaded org.springframework.boot.loader.LaunchedURLClassLoader from file:/Users/yulei/tmp/myapp-1.0-SNAPSHOT.jar]
$ java -verbose:class -jar myapp-1.0-SNAPSHOT.jar | egrep '^\[Loaded' > classes
$ wc classes
7404 29638 1175552 classes
class 个数到达惊人的 7404 个。
我们再对比下 JavaScript 生态,使用常用的 express 编写一个基本应用:
const express = require('express')
const app = express()
app.get('/', (req, res) => {
res.send('Hello World!')
})
app.listen(3000, () => {
console.log(`Example app listening at http://localhost:${port}`)
})
我们借用 Node 的 debug 环境变量分析:
NODE_DEBUG=module node app.js 2>&1 | head -n 5
MODULE 18614: looking for "/Users/yulei/tmp/myapp/app.js" in ["/Users/yulei/.node_modules","/Users/yulei/.node_libraries","/usr/local/Cellar/node/14.4.0/lib/node"]
MODULE 18614: load "/Users/yulei/tmp/myapp/app.js" for module "."
MODULE 18614: Module._load REQUEST express parent: .
MODULE 18614: looking for "express" in ["/Users/yulei/tmp/myapp/node_modules","/Users/yulei/tmp/node_modules","/Users/yulei/node_modules","/Users/node_modules","/node_modules","/Users/yulei/.node_modules","/Users/yulei/.node_libraries","/usr/local/Cellar/node/14.4.0/lib/node"]
MODULE 18614: load "/Users/yulei/tmp/myapp/node_modules/express/index.js" for module "/Users/yulei/tmp/myapp/node_modules/express/index.js"
$ NODE_DEBUG=module node app.js 2>&1 | grep ': load "' > js
$ wc js
55 392 8192 js
这里只依赖了区区 55个 js 文件。
虽然拿 spring-boot 和 express 比并不公平。在 Java 世界也可以基于 Vert.X、Netty 等更加轻量的框架来构建应用,但是在实践中,大家几乎都会不假思索地选择 spring-boot,以便享受 Java 开源生态的便利。
2、一次编译,到处运行
Java 启动慢是因为框架复杂吗?答案只能说框架复杂是启动慢的原因之一。通过 GraalVM 的 Native Image 功能结合 spring-native 特性,可以将 spring-boot 应用的启动时间缩短约十倍。
Java 的 Slogan 是 "Write once, run anywhere"(WORA),Java 也确实通过字节码和虚拟机技术做到了这一点。
WORA 使得开发者在 MacOS 上开发调试完成的应用可以快速部署到 Linux 服务器,跨平台性也让 Maven 中心仓库更加易于维护,促成了 Java 开源生态的繁荣。
我们来看一下 WORA 对 Java 的影响:
- Class Loading
Java 通过 class 来组织源码,class 被塞进 JAR 包以便组织成模块和分发,JAR 包本质上是一个 ZIP 文件:
$ jar tf slf4j-api-1.7.25.jar | head META-INF/ META-INF/MANIFEST.MF org/slf4j/ org/slf4j/event/EventConstants.class org/slf4j/event/EventRecodingLogger.class org/slf4j/event/Level.class
每个 JAR 包都是功能上比较独立的模块,开发者就可以按需依赖特定功能的 JAR,这些 JAR 通过 class path 被JVM 所知悉,并进行加载。
根据,执行到 new 或者 invokestatic 字节码时会触发类加载。JVM 会将控制交给 Classloader ,最常见的实现 URLClassloader 会遍历 JAR 包,去寻找相应的 class 文件:
for (int i = 0; (loader = getNextLoader(cache, i)) != null; i++) {
Resource res = loader.getResource(name, check);
if (res != null) {
return res;
}
}
因此查找类的开销,通常和 JAR 包个数成正比,在大型应用的场景下个数会上千,导致整体的查找耗时很高。
当找到 class 文件后 JVM 需要校验 class 文件的是否合法,并解析成内部可用的数据结构,在 JVM 中叫做 InstanceKlass ,听过 javap 窥视一下class文件包含的信息:
$ javap -p SimpleMessage.class
public class org.apache.logging.log4j.message.SimpleMessage implements org.apache.logging.log4j.message.Message,org.apache.logging.log4j.util.StringBuilderFormattable,java.lang.CharSequence {
private static final long serialVersionUID;
private java.lang.String message;
private transient java.lang.CharSequence charSequence;
public org.apache.logging.log4j.message.SimpleMessage();
public org.apache.logging.log4j.message.SimpleMessage(java.lang.String);
这个结构包含接口、基类、静态数据、对象的 layout、方法字节码、常量池等等。这些数据结构都是解释器执行字节码或者JIT编译所必须的。
- Class initialize
当类被加载完成后,要完成初始化才能实际创建对象或者调用静态方法。类初始化可以简单理解为静态块:
public class A {
private final static String JAVA_VERSION_STRING = System.getProperty("java.version");
private final static Set<Integer> idBlackList = new HashSet<>();
static {
idBlackList.add(10);
idBlackList.add(65538);
}
}
上面的第一个静态变量 JAVA_VERSION_STRING 的初始化在编译成字节码后也会成为静态块的一部分。
类初始化有如下特点:
- 只执行一次;
- 有多线程尝试访问类时,只有一个线程会执行类初始化,JVM 保证其他线程都会阻塞等待初始化完成。
这些特点非常适合读取配置,或者构造一些运行时所需要数据结构、缓存等等,因此很多类的初始化逻辑会写的比较复杂。
- Just In Time compile
Java 类在被初始化后就可以实例对象,并调用对象上的方法了。解释执行类似一个大的 switch..case 循环,性能比较差:
while (true) {
switch(bytocode[pc]) {
case AALOAD:
...
break;
case ATHROW:
...
break;
}
}
我们用 JMH 来跑一个 Hessian 序列化的 Micro Benchmark 试验:
$ java -jar benchmarks.jar hessianIO Benchmark Mode Cnt Score Error Units SerializeBenchmark.hessianIO thrpt 118194.452 ops/s $ java -Xint -jar benchmarks.jar hessianIO Benchmark Mode Cnt Score Error Units SerializeBenchmark.hessianIO thrpt 4535.820 ops/s
第二次运行的 -Xint 参数控制了我们只使用解释器,这里差了26倍,这是直接机器执行的执行和解释执行的差异带来的。这个差距跟场景的关系很大,我们通常的经验值是50倍。
我们来进一步看下 JIT 的行为:
$ java -XX:+PrintFlagsFinal -version | grep CompileThreshold
intx Tier3CompileThreshold = 2000 {product}
intx Tier4CompileThreshold = 15000 {product}
这里是两项 JDK 内部的 JIT 参数的数值,我们暂不对分层编译原理做过多介绍,可以参考Stack Overflow。Tier3 可以简单理解为(client compiler)C1,Tier4 是 C2。当一个方法解释执行2000次会进行 C1 编译,当 C1 编译后执行15000次后就会 C2 编译,真正达到文章开头的 C 的一半性能完全体。
在应用刚启动阶段,方法还没有完全被JIT编译完成,因此大部分情况停留在解释执行,影响了应用启动的速度。
如何优化 Java 应用的启动速度
前面我们花了大量的篇幅分析了 Java 应用启动慢的主要原因,总结下就是:
- 受到 JakartaEE 影响,常见框架考虑复用和灵活性,设计得比较复杂;
- 为了跨平台性,代码是动态加载,并且动态编译的,启动阶段加载和执行耗时;
这两者综合起来造成了 Java 应用启动慢的现状。
Python 和 Javascript 都是动态解析加载模块的,CPyhton 甚至没有 JIT,理论上启动不会比 Java 快很多,但是它们并没有使用很复杂的应用框架,因此整体不会感受到启动性能的问题。
虽然我们无法轻易去改变用户对框架的使用习惯,但是可以在运行时层面进行增强,使启动性能尽量靠近 Native image。OpenJDK 官方社区也一直在努力解决启动性能问题,那么我们作为普通 Java 开发者,是否可以借助OpenJDK的最新特性来协助我们提升启动性能呢?
- Class Loading
- 通过 JarIndex 解决 JAR 包遍历问题,不过该技术过于古老,很难在现代的囊括了tomcat、fatJar的项目里使用起来
- AppCDS 可以解决 class 文件解析处理的性能问题
- Class Initialize: OpenJDK9 加入了 HeapArchive,可以持久化一部分类初始化相关的 Heap 数据,不过只有寥寥数个 JDK 内部 class (比如 IntegerCache )可以被加速,没有开放的使用方式。
- JIT预热: JEP295 实现了 AOT 编译,但是存在 bug,使用不当会引发程序正确性能问题。在性能上没有得到很好的 tuning,大部分情况下看不到效果,甚至会出现性能回退。
面对 OpenJDK 上述特性所存在的问题,Alibaba Dragonwell 对以上各项技术进行了研发优化,并与云产品进行了整合,用户不需要投入太多精力就可以轻松地优化启动时间。
1、AppCDS
CDS(Class Data Sharing)在 Oracle JDK1.5 被首次引入,在 Oracle JDK8u40 中引入了 AppCDS,支持 JDK 以外的类 ,但是作为商业特性提供。随后 Oracle 将 AppCDS 贡献给了社区,在 JDK10 中 CDS 逐渐完善,也支持了用户自定义类加载器(又称 AppCDS v2)。
面向对象语言将对象(数据)和方法(对象上的操作)绑定到了一起,来提供更强的封装性和多态。这些特性都依赖对象头中的类型信息来实现,Java、Python 语言都是如此。Java 对象在内存中的 layout 如下:
+-------------+| mark |+-------------+| Klass* |+-------------+| fields || |+-------------+
mark 表示了对象的状态,包括是否被加锁、GC 年龄等等。而 Klass*指向了描述对象类型的数据结构 InstanceKlass :
// InstanceKlass layout: // [C++ vtbl pointer ] Klass // [java mirror ] Klass // [super ] Klass // [access_flags ] Klass // [name ] Klass // [methods ] // [fields ] ...
基于这个结构,诸如 o instanceof String 这样的表达式就可以有足够的信息判断了。要注意的是 InstanceKlass 结构比较复杂,包含了类的所有方法、field 等等,方法又包含了字节码等信息。这个数据结构是通过运行时解析 class 文件获得的,为了保证安全性,解析 class 时还需要校验字节码的合法性( 非通过 Javac 产生的方法字节码很容易引起 JVM crash)。
CDS 可以将这个解析、校验产生的数据结构存储(dump)到文件,在下一次运行时重复使用。这个 dump 产物叫做 Shared Archive,以 jsa 后缀(Java shared archive)。
为了减少 CDS 读取 jsa dump 的开销,避免将数据反序列化到 InstanceKlass 的开销,jsa 文件中的存储 layout 和 InstanceKlass 对象完全一样,这样在使用 jsa 数据时,只需要将 jsa 文件映射到内存,并且让对象头中的类型指针指向这块内存地址即可,十分高效。
Object:+-------------+| mark | +-------------------------++-------------+ |classes.jsa file || Klass* +--------->java_mirror|super|methods|+-------------+ |java_mirror|super|methods|| fields | |java_mirror|super|methods|| | Object: +-------------+ | mark | +-------------------------+ +-------------+ |classes.jsa file | | Klass* +--------->java_mirror|super|methods| +-------------+ |java_mirror|super|methods| | fields | |java_mirror|super|methods| | | +-------------------------+ +-------------+ +-------------------------++-------------+
1、AppCDS 对 customer class loader 力不从心
jsa 中存储的 InstanceKlass 是对 class 文件解析的产物。对于 boot classloader (就是加载 jre/lib/rt.jar下面的类的 classloader)和 system(app) classloader (加载-classpath 下面的类的 classloader ),CDS 有内部机制可以跳过对 class 文件 的读取,仅仅通过类名在 jsa 文件中匹配对应的数据结构。
Java 还提供用户自定义类加载器(custom class loader)的机制,用户通过 Override 自己的 Classloader.loadClass() 方法可以高度定制化获取类的逻辑,比如从网络上获取、直接在代码中动态生成都是可行的。为了增强 AppCDS 的安全性,避免因为从 CDS 加载了类定义反而获得了非预期的类,AppCDS customer class loader 需要经过如下步骤:
- 调用用户定义的 Classloader.loadClass(),拿到 class byte stream
- 计算 class byte stream 的 checksum,与 jsa 中的同类名结构的 checksum 比较
- 如果匹配成功则返回jsa中的InstanceKlass,否则继续使用 slow path 解析 class文件
我们看到许多场景下,上述的第一步占据了类加载耗时的大头,此时 AppCDS 就显得力不从心了。举例来说:
bar.jar +- com/bar/Bar.class baz.jar +- com/baz/Baz.class foo.jar +- com/foo/Foo.class
class path 包含如上的三个 jar 包,在加载 class com.foo.Foo 时,大部分 Classloader 实现(包括 URLClassloader、tomcat、spring-boot)都选择了最简单的策略(过早的优化是万恶之源): 按照 jar 包出现在磁盘的顺序逐个尝试抽取 com/foo/Foo.class 这个文件。
JAR 包使用了 zip 格式作为存储,每次类加载都需要遍历 classpath 下的 JAR 包们,尝试从 zip 中抽取单个文件,来确保存在的类可以被找到。假设有 N个 JAR 包,那么平均一个类加载需要尝试访问 N/2 个 zip 文件。
在我们的一个真实场景下,N 到达 2000,此时 JAR 包查找开销非常大,并且远大于 InstanceKlass 解析的开销。面对此类场景 AppCDS 技术就力不从心了。
2、JAR Index
根据 jar 文件规范,JAR 文件是一种使用 zip封装,并使用文本在 META-INF 目录存储元信息的格式。该格式在设计时已经考虑了应对上述的查找场景,这项技术叫做 JAR Index。
假设我们要在上述的 bar.jar、baz.jar、foo.jar 中查找一个 class,如果能够通过类型 com.foo.Foo,立刻推断出具体在哪个 jar 包,就可以避免上述的扫描开销了。
JarIndex-Version: 1.0 foo.jar com/foo bar.jar com/bar baz.jar com/baz
通过 JAR Index 技术,可以生成出上述的索引文件 INDEX.LIST。加载到内存后成为一个 HashMap:
com/bar --> bar.jar com/baz --> baz.jar com/foo --> foo.jar
当我们看到类名com.foo.Foo,可以根据包名 com.foo 从索引中得知具体的 jar 包 foo.jar,迅速抽取 class 文件。
Jar Index 技术看似解决了我们的问题,但是这项技术十分古老,很难在现代应用中被使用起来:
- jar i 根据 META-INF/MANIFEST.MF 中的 Class-Path 属性产生索引文件,现代项目几乎不维护这个属性
- 只有 URLClassloader 支持 JAR Index
- 要求带索引的 jar 尽量出现在 classpath 的前面
Dragonwell 通过 agent 注入使得 INDEX.LIST 能够被正确地生成,并出现在 classpath 的合适位置来帮助应用提升启动性能。
2、类提前初始化
类的 static block 中的代码执行我们称之为类初始化,类加载完成后必须执行完初始化代码才能被使用(创建 instance、调用 static 方法)。
很多类的初始化本质上只是构造一些 static field:
class IntegerCache {
static final Integer cache[];
static {
Integer[] c = new Integer[size];
int j = low;
for(int k = 0; k < c.length; k++)
c[k] = new Integer(j++);
cache = c;
}
}
我们知道 JDK 对 box type 中常用的一段区间有缓存,避免过多的重复创建,这段数据就需要提前构造好。由于这些方法只会被执行一次,因此是以纯解释的方式执行的,如果可以持久化几个 static 字段的方式来避免调用类初始化器,我们就可以拿到提前初始化好的类,减少启动时间。
将持久化加载到内存使用最高效的方式是内存映射:
int fd = open("archive_file", O_READ);
struct person *persons = mmap(NULL, 100 * sizeof(struct person),
PROT_READ, fd, 0);
int age = persons[5].age;
C语言几乎是直接面向内存来操作数据的,而 Java 这样的高级语言都将内存抽象成了对象,有 mark、Klass*等元信息,每次运行之间都存在一定的变化,因此需要更加复杂的机智来获得高效的对象持久化。
1、Heap Archive 简介
OpenJDK9 引入了 HeapArchive 能力,OpenJDK12 中 heap archive 被正式使用。顾名思义,Heap Archive 技术可以将堆上的对象持久化存储下来。
对象图被提前被构建好后放进 archive,我们将这个阶段称为 dump;而使用 archive 里的数据称为运行时。dump 和运行时通常不是一个进程,但在某些场景下也可以是同一个进程。
回忆下使用 AppCDS 后的内存布局,对象的 Klass*指针指向了 SharedArchive 中的的数据。AppCDS 对 InstanceKlass 这个元信息进行了持久化,如果想要复用持久化的对象,那么对象头的类型指针必须也要指向一块被持久化过的元信息,因此 HeapArchive 技术是依赖 AppCDS 的。
为了适应多种场景,OpenJDK 的 HeapArchive 还提供了 Open 和 Closed 两种级别:
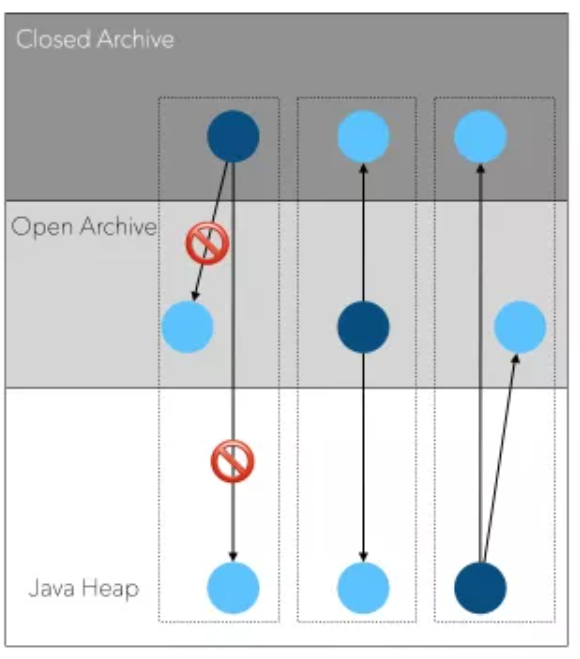
- Closed Archive
- 不允许引用 Open Archive 和 Heap 中的对象
- 可以引用 Closed Archive 内部的对象
- 只读,不可写
- Open Archive
- 可以引用任何对象
- 可写
这样设计的原因是对于一些只读结构,放在 Closed Archive 中可以做到对 GC 完全无开销。
为什么只读?想象一下,假如Closed Archive中的对象A引用了heap中的对象B,那么当对象B移动时,GC需要修正A中指向B的field,这会带来GC开销。
2、利用 Heap Archive 提前做类初始化
支持这种结构后,在类加载后,将 static 变量指向被 Archive 的对象,即可完成类初始化:
class Foo {
static Object data;
} +
|
<---------+
Open Archive Object:
+-------------+
| mark | +-------------------------+
+-------------+ |classes.jsa file |
| Klass* +--------->java_mirror|super|methods|
+-------------+ |java_mirror|super|methods|
| fields | |java_mirror|super|methods|
| | +-------------------------+
+-------------+
3、AOT 编译
除去类的加载,方法的前几次执行因为没有被 JIT 编译器给编译,字节码在解释模式下执行。根据本文上半部分的分析,解释执行速度约为 JIT 编译后的几十分之一,代码解释执行慢也启动慢的一大元凶。
传统的 C/C++等语言都是直接编译到目标平台的 native 机器码。随着大家意识到 Java、JS 等解释器 JIT 语言的启动预热问题,通过 AOT 将字节码直接编译到 native 代码这种方式逐渐进入公众视野。
wasm、GraalVM、OpenJDK 都不同程度地支持了 AOT 编译,我们主要围绕 JEP295 引入的 jaotc 工具优化启动速度。
注意这里的术语使用:
JEP295使用AOT是将class文件中的方法逐个编译到native代码片段,通过Java虚拟机在加载某个类后替换方法的的入口到AOT代码。而GraalVM的的Native Image功能是更加彻底的静态编译,通过一个用Java代码编写的小型运行时SubstrateVM,该运行时和应用代码一起被静态编译到可执行的文件(类似Go),不再依赖JVM。该做法也是一种AOT,但是为了区分术语,这里的AOT单指JEP295的方式。
1、AOT特性初体验
通过 JEP295 的介绍,我们可以快速体验 AOT
cat > HelloWorld.java <<EOF
public class HelloWorld {
public static void main(String[] args) { System.out.println("Hello World!"); }
}
EOF
jaotc --output libHelloWorld.so HelloWorld.class
java -XX:+UnlockExperimentalVMOptions -XX:AOTLibrary=./libHelloWorld.so HelloWorld
jaotc 命令会调用 Graal 编译器对字节码进行编译,产生 libHelloWorld.so 文件。这里产生的 so 文件容易让人误以为会直接像 JNI 一样调用进编译好的库代码。但是这里并没有完全使用 ld 的加载机制来运行代码,so 文件更像是当做一个 native 代码的容器。hotsopt runtime 在加载 AOT so 后需要进行进一步的动态链接。在类加载后 hotspot 会自动关联 AOT 代码入口,对于下次方法调用使用 AOT 版本。而 AOT 生成的代码也会主动与 hotspot 运行时交互,在 aot、解释器、JIT 代码间相互跳转。
1)AOT 的一波三折
看起来JEP295已经实现了一套完备的AOT体系,但是为何不见这项技术被大规模使用?在 OpenJDK 的各项新特性中,AOT 算得上是命途多舛。
2)多 Classloader 问题
JDK-8206963: bug with multiple class loaders
这是在设计上没有考虑到Java的多 Classloader 场景,当多个 Classloader 加载的同名类都使用了 AOT 后,他们的 static field 是共享的,而根据 Java 语言的设计,这部分数据应该是隔开的。
由于没有可以快速修复这个问题的方案,OpenJDK 仅仅是添加了如下代码:
ClassLoaderData* cld = ik->class_loader_data();
if (!cld->is_builtin_class_loader_data()) {
log_trace(aot, class, load)("skip class %s for custom classloader %s (%p) tid=" INTPTR_FORMAT,
ik->internal_name(), cld->loader_name(), cld, p2i(thread));
return false;
}
对于用户自定义类加载器不允许使用 AOT。从这里已经可以初步看出该特性在社区层面已经逐渐缺乏维护。
在这种情况下,虽然通过 class-path 指定的类依然可以使用 AOT,但是我们常用的 spring-boot、Tomcat 等框架都需要通过 Custom Classloader 加载应用代码。可以说这一改变切掉了 AOT 的一大块场景。
3)缺乏调优和维护,退回成实验特性
JDK-8227439: Turn off AOT by default
JEP 295 AOT is still experimental, and while it can be useful for startup/warmup when used with custom generated archives tailored for the application, experimental data suggests that generating shared libraries at a module level has overall negative impact to startup, dubious efficacy for warmup and severe static footprint implications.
从此打开 AOT 需要添加 experimental 参数:
java -XX:+UnlockExperimentalVMOptions -XX:AOTLibrary=...
根据 issue 的描述,这项特性编译整个模块的情况下,对启动速度和内存占用都起到了反作用。我们分析的原因如下:
- Java 语言本身过分复杂,动态类加载等运行时机制导致 AOT 代码没法运行得像预期一样快
- AOT 技术作为阶段性的项目在进入 Java 9 之后并没有被长期维护,缺乏必要的调优(反观AppCDS一直在迭代优化)
4)JDK16 中被删除
JDK-8255616:Disable AOT and Graal in Oracle OpenJDK
在 OpenJDK16 发布前夕,Oracle正式决定不再维护这项技术:
We haven't seen much use of these features, and the effort required to support and enhance them is significant.
其根本原因还是这项基于缺乏必要的优化和维护。而对于 AOT 相关的未来的规划,只能从只言片语中推测将来Java的AOT 有两种技术方向:
- 在 OpenJDK 的 C2 基础上做 AOT
- 在 GraalVM 的 native-image 上支持完整的 Java 语言特性,需要 AOT 的用户逐渐从 OpenJDK 过渡到native-image
上述的两个技术方向都没法在短期内看到进展,因此 Dragonwell 的技术方向是让现有的 JEP295 更好地工作,为用户带来极致的启动性能。
5)Dragonwell 上的快速启动
Dragonwell 的快速启动特性攻关了 AppCDS、AOT 编译技术上的弱点,并基于 HeapArchive 机制研发了类提前初始化特性。这些特性将 JVM 可见的应用启动耗时几乎全部消除。
此外,因为上述几项技术都符合 trace-dump-replay 的使用模式,Dragonwell 将上述启动加速技术统一了流程,并且集成到了 SAE 产品中。
SAE x Dragonwell : Serverless with Java 启动加速最佳实践
有了好的食材,还需要相匹配的佐料,以及一位烹饪大师。
将 Dragonwell 的启动加速技术和和以弹性著称的 Serverless 技术相结合更相得益彰,同时共同落地在微服务应用的全生命周期管理中,才能发挥他们缩短应用端到端启动时间的作用,因此 Dragonwell 选择了 SAE 来落地其启动加速技术。
SAE (Serverless 应用引擎)是首款面向 Serverless 的 PaaS 平台,他可以:
- Java 软件包部署:零代码改造享受微服务能力,降低研发成本
- Serverless 极致弹性:资源免运维,快速扩容应用实例, 降低运维与学习成本
1、难点分析
通过分析,我们发现微服务的用户在应用启动层面面临着一些难题:
- 软件包大:几百 MB 甚至 GB 级别
- 依赖包多:上百个依赖包,几千个 Class
- 加载耗时:从磁盘加载依赖包,再到 Class 按需加载,最高可占启动耗时的一半
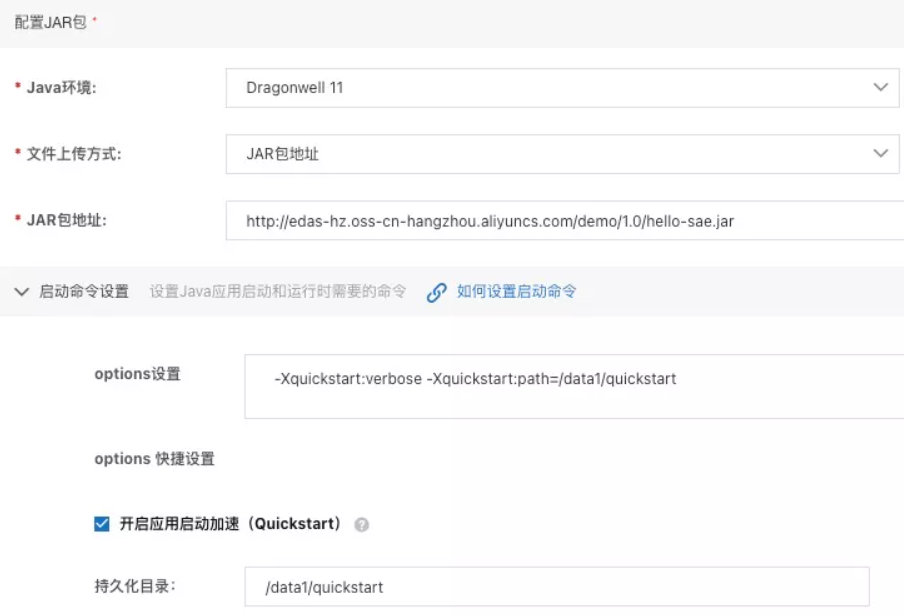
借助 Dragonwell 快速启动能力,SAE 为 Serverless Java 应用提供了一套,让应用尽可能加速启动的最佳实践,让开发者更专注于业务开发:
- Java 环境 + JAR/WAR 软件包部署:集成 Dragonwell 11 ,提供加速启动环境
- JVM 快捷设置:支持一键开启快速启动,简化操作
- NAS 网盘:支持跨实例加速,在新包部署时,加速新启动实例/分批发布启动速度
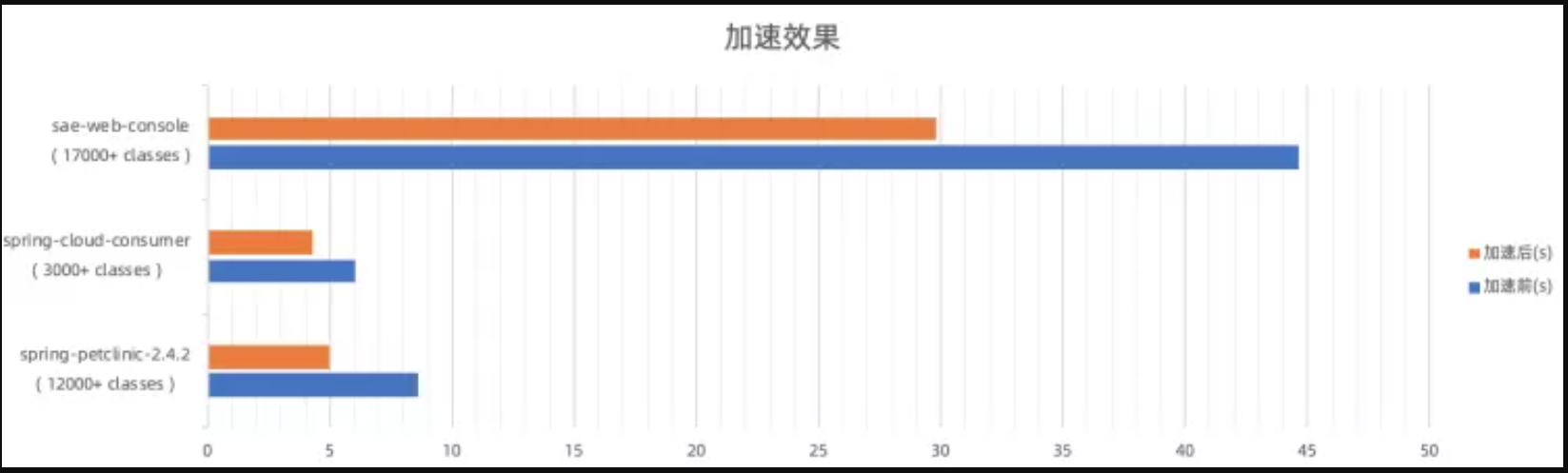
我们选择一些微服务、复杂依赖的业务场景典型 Demo 或内部应用,测试启动效果,发现应用普遍能降低 5%~45% 的启动耗时。若应用启动,存在下列场景,会有明显加速效果:
- 类加载多(spring-petclinic 启动加载约 12000+ classes)
- 依赖外部数据越少
- 阿里巴巴搜索推荐 Serverless 平台
阿里内部的搜索推荐 Serverless 平台通过类加载隔离机制,将多个业务的合并部署在同一个 Java 虚拟机中。调度系统会按需地将业务代码合并部署到空闲的容器中,让多个业务可以共享同一个资源池,大大提高部署密度和整体的 CPU 使用率。
由于要支撑大量不同的业务研发运行,平台本身需要提供足够丰富的功能,如缓存、RPC调用。因此搜索推荐Serverless 平台的每个 JVM 都需要拉起类似 Pandora Boot 的中间件隔离容器,这将加载大量的类,拖累了平台自身的启动速度。当突增的需求进入,调度系统需要拉起更多容器以供业务代码部署,此时容器本身的启动时间就显得尤为重要。
基于 Dragonwell 的快速启动技术,搜索推荐平台在预发布环境会执行 AppCDS、Jarindex 等优化,将产生的 archive 文件打入容器镜像中,这样每一个容器在启动时都能享受加速,减少约30%的启动耗时。
- 潮牌秒杀SAE极致弹性
某外部客户,借助 SAE 提供的 Jar 包部署与 Dragonwell 11,快速迭代上线了某潮牌商场 App。
在面对大促秒杀时,借助 SAE Serverless 极致弹性,与应用指标 QPS RT 指标弹性能力,轻松面对 10 倍以上快速扩容需求;同时一键开启 Dragonwell 增强的 AppCDS 启动加速能力,降低 Java 应用 20% 以上启动耗时,进一步加速应用启动,保证业务平稳健康运行。
总结
Dragonwell 上的快速启动技术方向上完全基于 OpenJDK 社区的工作,对各项功能进行了细致的优化与 bugfix,并降低了上手的难度。这样做既保证了对标准的兼容,避免内部定制,也能够为开源社区做出贡献。
作为基础软件,Dragonwell 只能生成/使用磁盘上的 archive 文件。结合 SAE 对 Dragonwell 的无缝集成,JVM 配置、archive 文件的分发都被自动化。客户可以轻松享受应用加速带来的技术红利。
作者介绍:
梁希,来自阿里云 Java 虚拟机团队,负责 Java Runtime 方向。主导了 Java 协程、启动优化等技术的研发和大规模落地。
代序,来自阿里云 SAE 团队,负责 Runtime 演进、 弹性能力与效率方向。主导应用弹性、Java 加速、镜像加速等技术的研发落地。
原文链接
本文为阿里云原创内容,未经允许不得转载。