简介: 《实时数仓入门训练营》由阿里云研究员王峰、阿里云资深技术专家金晓军、阿里云高级产品专家刘一鸣等实时计算 Flink 版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!
本文整理自直播《实时计算 Flink 版 SQL 实践-李麟(海豹)》
视频链接:https://c.tb.cn/F3.0dBssY
内容简要:
一、实时计算Flink版SQL简介
二、实时计算Flink版SQL上手示例
三、开发常见问题和解法
实时计算Flink版SQL简介
(一)关于实时计算Flink版SQL

![]()
实时计算Flink版选择了SQL这种声明式语言作为顶层API,比较稳定,也方便用户使用。Flink SQL具备流批统一的特性,给用户统一的开发体验,并且语义一致。另外,Flink SQL能够自动优化,包括屏蔽流计算里面State的复杂性,也提供了自动优化的Plan,并且还集成了AutoPilot自动调优的功能。Flink SQL的应用场景也比较广泛,包括数据集成、实时报表、实时风控,还有在线机器学习等场景。
(二)基本操作
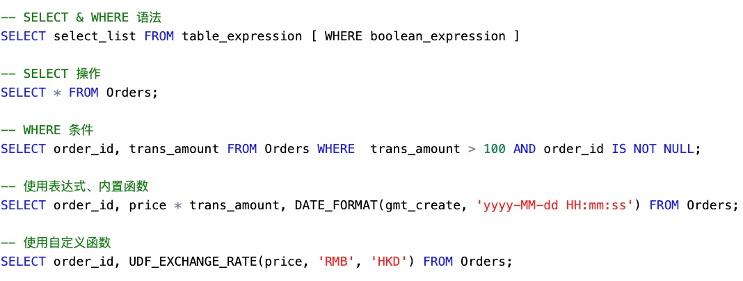
![]()
在基本操作上,可以看到SQL的语法和标准SQL非常类似。示例中包括了基本的SELECT、FILTER操作。,可以使用内置函数,如日期的格式化,也可以使用自定义函数,比如示例中的汇率转换就是一个用户自定义函数,在平台上注册后就可以直接使用。
(三)维表 Lookup Join
在实际的数据处理过程中,维表的Lookup Join也是一个比较常见的例子。
![]()
![]()
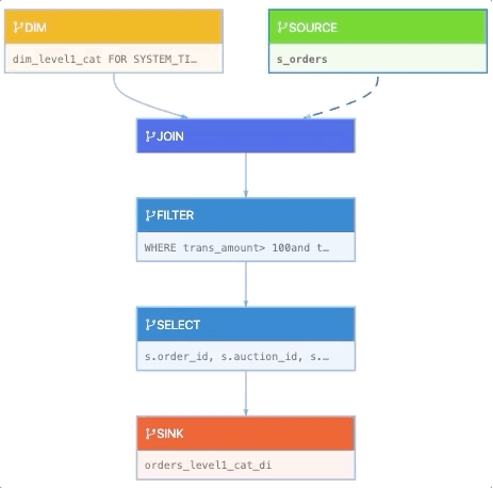
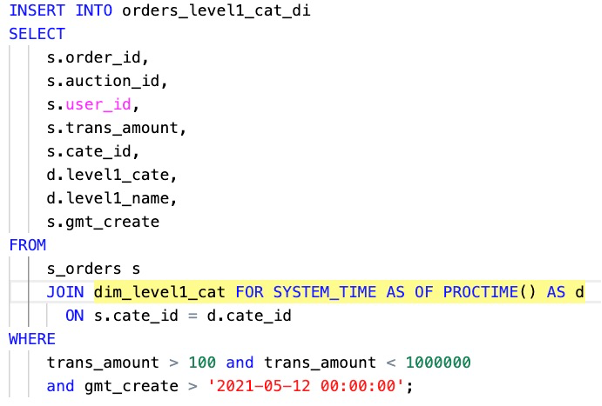
这里展示的是一个维表INNER JOIN示例。
例子中显示的SOURCE表是一个实时变化的订单信息表,它通过INNER JOIN去关联维表信息,这里标黄高亮的就是维表JOIN的语法,可以看到它和传统的批处理有一个写法上的差异,多了FOR SYSTEM_TIME AS OF这个子句来标明它是一个维表JOIN的操作。SOURCE表每来一条订单消息,它都会触发维表算子,去做一次对维表信息的查询,所以把它叫做一个Lookup Join。
(四)Window Aggregation
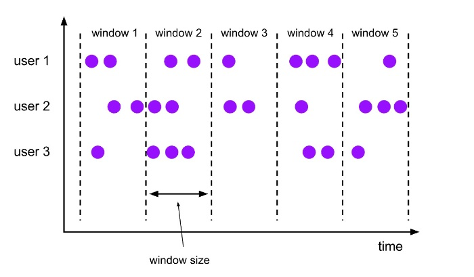
Window Aggregation(窗口聚合)操作也是常见的操作,Flink SQL中内置支持了几种常用的Window类型,比如Tumble Window,Session Window,Hop Window,还有新引入的Cumulate Window。
![]()
Tumble
Tumble Window可以理解成固定大小的时间窗口,也叫滚窗,比如说5分钟、10分钟或者1个小时的固定间隔的窗口,窗口之间没有重叠。
![]()
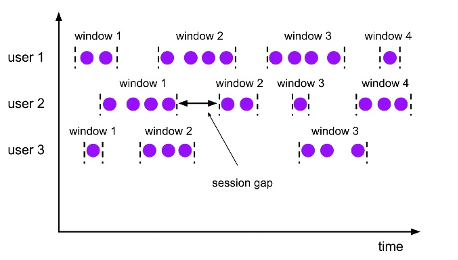
Session
Session Window(会话窗口) 定义了一个连续事件的范围,窗口定义中的一个参数叫做Session Gap,表示两条数据的间隔如果超过定义的时长,那么前一个Window就结束了,同时生成了一个新的窗口。
![]()
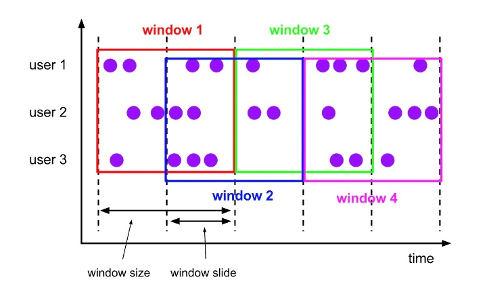
Hop
Hop Window不同于滚动窗口的窗口不重叠,滑动窗口的窗口之间可以重叠。滑动窗口有两个参数:size 和 slide。size 为窗口的大小,slide 为每次滑动的步长。如果slide < size,则窗口会重叠,同一条数据可能会被分配到多个窗口;如果 slide = size,则等同于 Tumble Window。如果 slide > size,窗口之间没有重叠且有间隙。
![]()
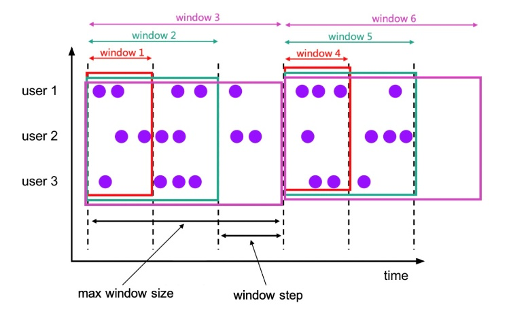
Cumulate
Cumulate Window(累积窗口),是Flink社区1.13版本里新引入的,可以对比 Hop Window来理解,区别是从Window Start开始不断去累积。示例中Window 1、Window 2、Window 3是在不断地增长的。它有一个最大的窗口长度,比如我们定义Window Size是一天,然后Step步长是1个小时,那么它会在一天中的每个小时产生累积到当前小时的聚合结果。
看一个具体的Window聚合处理示例。

![]()
如上图所示,比如说需要进行每5分钟单个用户的点击数统计。
源数据是用户的点击日志,我们期望算出每5分钟单个用户的点击总数, SQL 中使用的是社区最新的 WindowTVF语法,先对源表开窗,再 GROUP BY 窗口对应的属性 window_start和window_end, COUNT(*)就是点击数统计。
可以看到,当处理12:00到12:04的数据,有2个用户产生了4次点击,分别能统计出来用户Mary是3次,Bob是1次。在接下来一批数据里面,又来了3条数据,对应地更新到下一个窗口中,分别是1次和2次。
(五)Group Aggregation
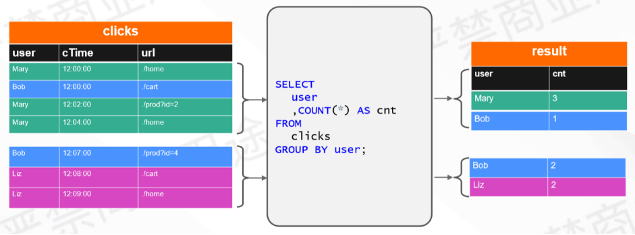
相对于Window Aggregation来说,Group Aggregation直接触发计算,并不需要等到窗口结束,适用的一个场景是计算累积值。
![]()
上图的例子是单个用户累积到当前的点击数统计。从Query上看,写法相对简单一点,直接 GROUP BY user 去计算COUNT(*),就是累积计数。
可以看到,在结果上和Window的输出是有差异的,在与Window相同的前4条输入数据,Group Aggregation输出的结果是Mary的点击数已更新到3次,具体的计算过程可能是从1变成2再变成3,Bob是1次,随着后面3条数据的输入,Bob对应的点击数又会更新成2次,对结果是持续更新的过程,这和Window的计算场景是有一些区别的。
之前Window窗口里面输出的数据,在窗口结束后结果就不会再改变,而在Group Aggregation里,同一个Group Key的结果是会产生持续更新的。
(六)Window Aggregation Vs Group Aggregation
更全面地对比一下Window和Group Aggregation的一些区别。

![]()
Window Aggregation在输出模式上是按时输出,是在定义的数据到期之后它才会输出。比如定义5分钟的窗口,结果是延迟输出的,比如00:00~00:05这个时间段,它会等整个窗口数据都到齐之后,才完整输出出来,并且结果只输出一次,不会再改变。
Group Aggregation是数据触发,比如第一条数据来它就会输出结果,同一个Key 的第二条数据来结果会更新,所以在输出流的性质上两者也是不一样的。Window Aggregation一般情况下输出的是Append Stream,而在Group Aggregation输出的是Update Stream。
在状态State处理上两者的差异也比较大。Window Aggregation会自动清理过期数据,用户就不需要额外再去关注 State的膨胀情况。Group Aggregation是基于无限的状态去做累积,所以需要用户根据自己的计算场景来定义State的TTL,就是State保存多久。
比如统计一天内累计的PV和UV,不考虑数据延迟的情况,也至少要保证State的TTL要大于等于一天,这样才能保证计算的精确性。如果State的TTL定义成半天,统计值就可能不准确了。
对输出的存储要求也是由输出流的性质来决定的。在Window的输出上,因为它是Append流,所有的类型都是可以对接输出的。而Group Aggregatio输出了更新流,所以要求目标存储支持更新,可以用Hologres、MySQL或者HBase这些支持更新的存储。
实时计算 Flink 版SQL上手示例
下面通过具体的例子来看每一种SQL操作在真实的业务场景中会怎么使用,比如SQL基本的语法操作,包括一些常见的Aggregation的使用。
(一)示例场景说明:电商交易数据 - 实时数仓场景

![]()
这里的例子是电商交易数据场景,模拟了实时数仓里分层数据处理的情况。
在数据接入层,我们模拟了电商的交易订单数据,它包括了订单ID,商品ID,用户ID,交易金额,商品的叶子类目,交易时间等基本信息,这是一个简化的表。
示例1会从接入层到数据明细层,完成一个数据清洗工作,此外还会做类目信息的关联,然后数据的汇总层我们会演示怎么完成分钟级的成交统计、小时级口径怎么做实时成交统计,最后会介绍下在天级累积的成交场景上,怎么去做准实时统计。
- 示例环境:内测版
![]()
演示环境是目前内测版的实时计算Flink产品,在这个平台可以直接做一站式的作业开发,包括调试,还有线上的运维工作。
- 接入层数据
使用 SQL DataGen Connector 生成模拟电商交易数据。

![]()
接入层数据:为了方便演示,简化了链路,用内置的SQL DataGen Connector来模拟电商数据的产生。
这里面order_id是设计了一个自增序列,Connector的参数没有完整贴出来。 DataGen Connector支持几种生成模式,比如可以用Sequence产生自增序列,Random模式可以模拟随机值,这里根据不同的字段业务含义,选择了不同的生成策略。
比如order_id是自增的,商品ID是随机选取了1~10万,用户ID是1~1000万,交易金额用分做单位, cate_id是叶子类目ID,这里共模拟100个叶子类目,直接通过计算列对商品ID取余来生成,订单创建时间使用当前时间模拟,这样就可以在开发平台上调试,而不需要去创建Kafka或者DataHub做接入层的模拟。
(二)示例1-1 数据清洗
- 电商交易数据-订单过滤

![]()
这是一个数据清洗的场景,比如需要完成业务上的订单过滤,业务方可能会对交易金额有最大最小的异常过滤,比如要大于1元,小于1万才保留为有效数据。
交易的创建时间是选取某个时刻之后的,通过WHERE条件组合过滤,就可以完成这个逻辑。
真实的业务场景可能会复杂很多,下面来看下SQL如何运行。
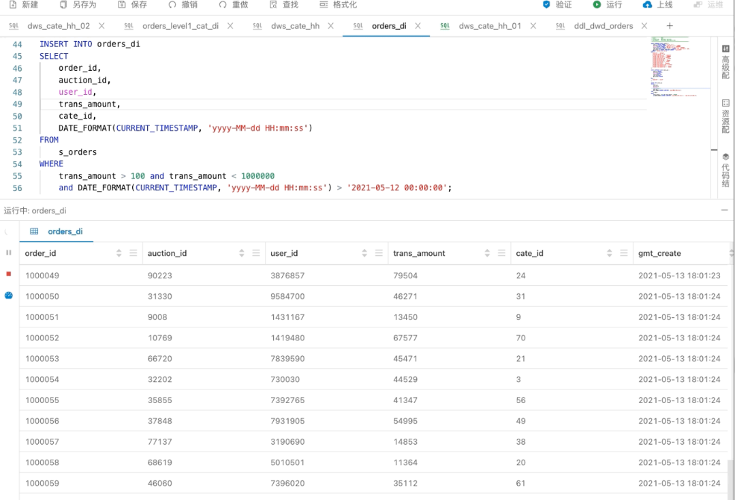
![]()
这是使用调试模式,在平台上点击运行按钮进行本地调试,可以看到金额这一列被过滤,订单创建时间也都是大于要求的时间值。
从这个简单的清洗场景可以看到,实时和传统的批处理相比,在写法上包括输出结果差异并不大,流作业主要的差异是运行起来之后是长周期保持运行的,而不像传统批处理,处理完数据之后就结束了。
(三)示例1-2 类目信息关联
接下来看一下怎么做维表关联。

![]()
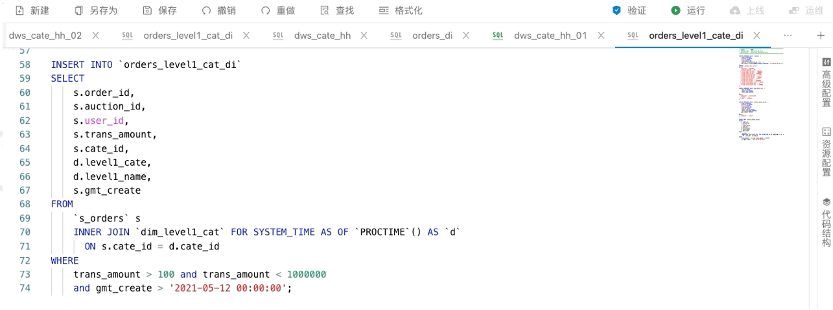
根据刚才接入层的订单数据,因为原始数据里面是叶子类目信息,在业务上需要关联类目的维度表,维度表里面记录了叶子类目到一级类目的关联关系,ID和名称,清洗过程需要完成的目标是用原始表里面叶子类目ID去关联维表,补齐一级类目的ID和Name。这里通过INNER JOIN维表的写法,关联之后把维表对应的字段选出来。
和批处理的写法差异仅仅在于维表的特殊语法FOR SYSTEM_TIME AS OF。
![]()
![]()
![]()
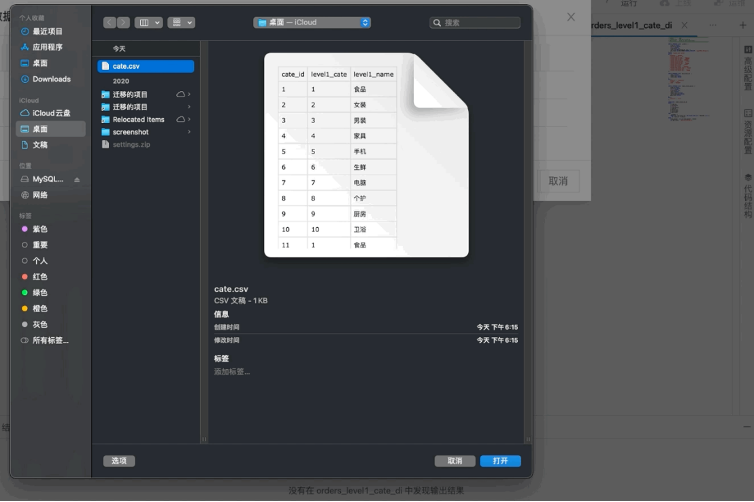
如上所示,平台上可以上传自己的数据用于调试,比如这里使用了1个CSV的测试数据,把100个叶子类目映射到10个一级类目上。
对应叶子类目ID的个位数就是它一级类目的ID,会关联到对应的一级类目信息,返回它的名称。本地调试运行优点是速度比较快,可以即时看到结果。在本地调试模式中,终端收到1000条数据之后,会自动暂停,防止结果过大而影响使用。
(四)示例2-1 分钟级成交统计
接下来我们来看一下基于Window的统计。

![]()
第一个场景是分钟级成交统计,这是在汇总层比较常用的计算逻辑。
分钟级统计很容易想到Tumble Window,每一分钟都是各算各的,需要计算几个指标,包括总订单数、总金额、成交商品数、成交用户数等。成交的商品数和用户数要做去重,所以在写法上做了一个Distinct处理。
窗口是刚刚介绍过的Tumble Window,按照订单创建时间去划一分钟的窗口,然后按一级类目的维度统计每一分钟的成交情况。
- 运行模式
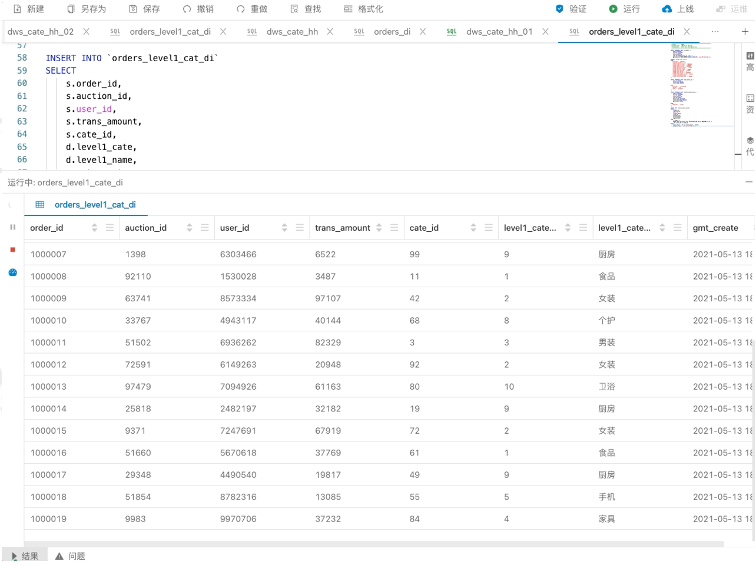
![]()
上图和刚才的调试模式有点区别,上线之后就真正提交到集群里去运行一个作业,它的输出采用了调试输出,直接Print到Log里。展开作业拓扑,可以看到自动开启了Local-Global的两阶段优化。
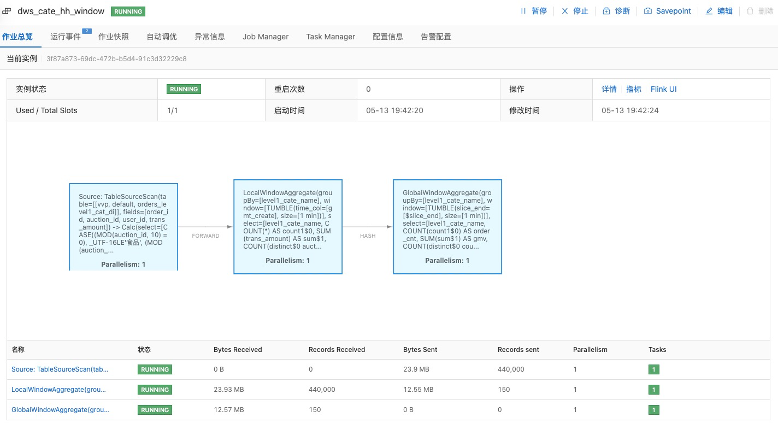
- 运行日志 - 查看调试输出结果
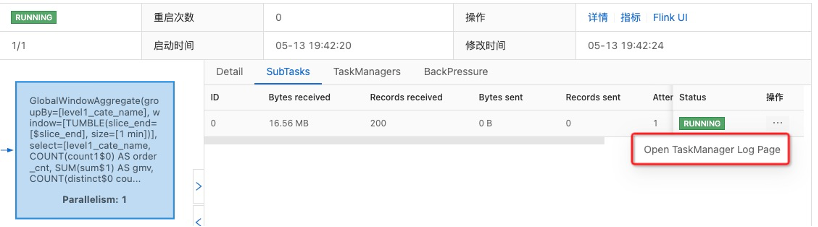
![]()

![]()
在运行一段时间之后,通过Task里面的日志可以看到最终的输出结果。
用的是Print Sink,会直接打到Log里面。在真实场景的输出上,比如写到Hologres/MySQL,那就需要去对应存储的数据库上查看。
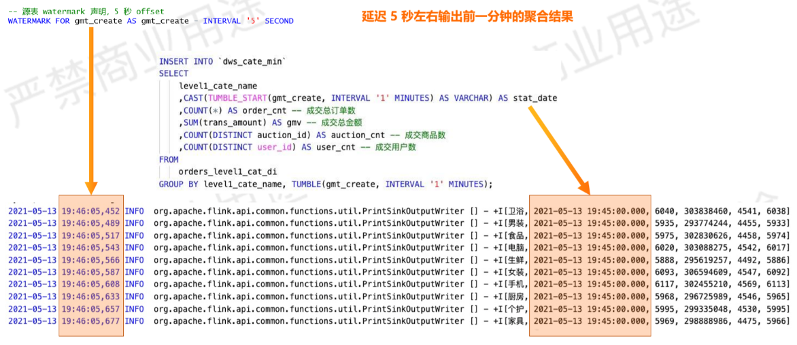
![]()
可以看到,输出的数据相对于数据的原始时间是存在一定滞后的。
在19:46:05的时候,输出了19:45:00这一个窗口的数据,延迟了5秒钟左右输出前1分钟的聚合结果。
这5秒钟实际上和定义源表时WATERMARK的设定是有关系的,在声明WATERMARK时是相对gmt_create字段加了5秒的offset。这样起到的效果是,当到达的最早数据是 19:46:00 时,我们认为水位线是到了19:45:55,这就是5秒的延迟效果,来实现对乱序数据的宽容处理。
(五)示例2-2 小时级实时成交统计
第二个例子是做小时级实时成交统计。

![]()
如上图所示,当要求实时统计,直接把Tumble Window开成1小时Size的Tumble Window,这样能满足实时性吗?按照刚才展示的输出结果,具有一定的延迟效果。因此开一个小时的窗口,必须等到这一个小时的数据都收到之后,在下一个小时的开始,才能输出上一个小时的结果,延迟在小时级别的,满足不了实时性的要求。回顾之前介绍的 Group Aggregation 是可以满足实时要求的。

![]()
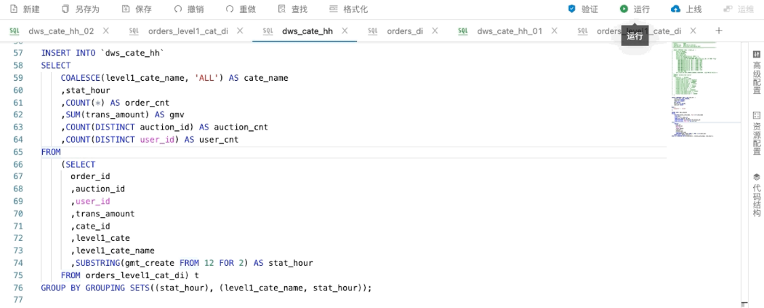
具体来看,比如需要完成小时+类目以及只算小时的两个口径统计,两个统计一起做,在传统批处理中常用的GROUPING SETS功能,在实时Flink上也是支持的。
我们可以直接GROUP BY GROUPING SETS,第一个是小时全口径,第二个是类目+小时的统计口径,然后计算它的订单数,包括总金额,去重的商品数和用户数。
这种写法对结果加了空值转换处理便于查看数据,就是对小时全口径的统计,输出的一级类目是空的,需要对它做一个空值转换处理。
![]()
![]()
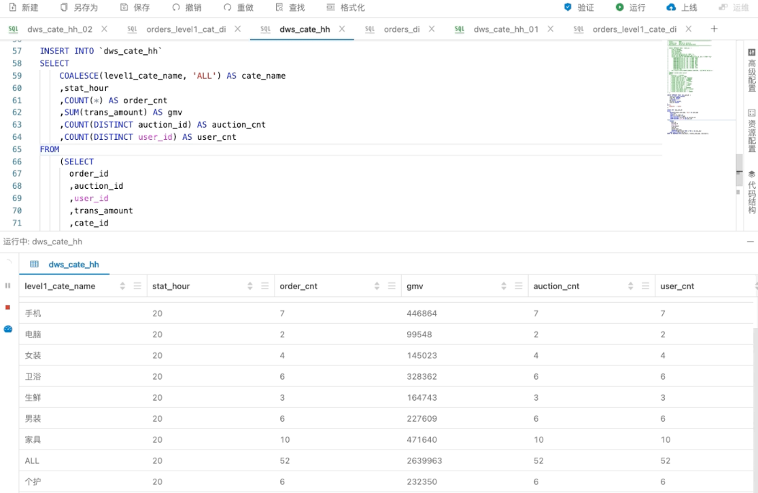
上方为调试模式的运行过程,可以看到Datagen生成的数据实时更新到一级类目和它对应的小时上。
这里可以看到,两个不同GROUP BY的结果在一起输出,中间有一列ALL是通过空值转换来的,这就是全口径的统计值。本地调试相对来说比较直观和方便,有兴趣的话也可以到阿里云官网申请或购买进行体验。
(六)示例2-3 天级累积成交准实时统计
第三个示例是天级累计成交统计,业务要求是准实时,比如说能够接受分钟级的更新延迟。
按照刚才Group Aggregation小时的实时统计,容易联想到直接把Query改成天维度,就可以实现这个需求,而且实时性比较高,数据触发之后可以达到秒级的更新。

![]()
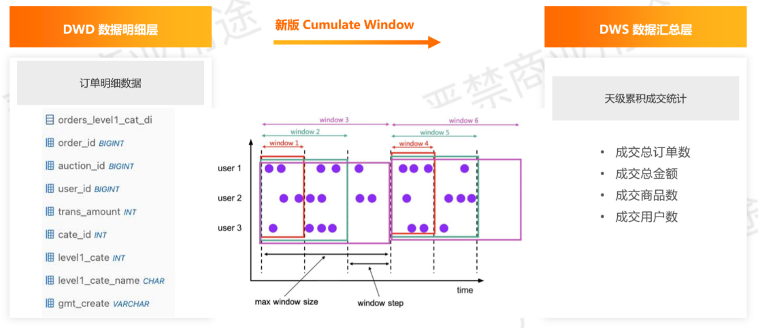
回顾下之前提到的Window和Group Aggregation对于内置状态处理上的区别,Window Aggregation可以实现State的自动清理,Group Aggregation需要用户自己去调整 TTL。由于业务上是准实时的要求,在这里可以有一个替代的方案,比如用新引入的Cumulate Window做累积的Window计算,天级的累积然后使用分钟级的步长,可以实现每分钟更新的准实时要求。
![]()
回顾一下Cumulate Window,如上所示。天级累积的话,Window的最大Size是到天,它的Window Step就是一分钟,这样就可以表达天级的累积统计。

![]()
具体的Query如上,这里使用新的TVF语法,通过一个TABLE关键字把Windows的定义包含在中间,然后 Cumulate Window引用输入表,接着定义它的时间属性,步长和size 参数。GROUP BY就是普通写法,因为它有提前输出,所以我们把窗口的开始时间和结束时间一起打印出来。
这个例子也通过线上运行的方式去看Log输出。
- 运行模式
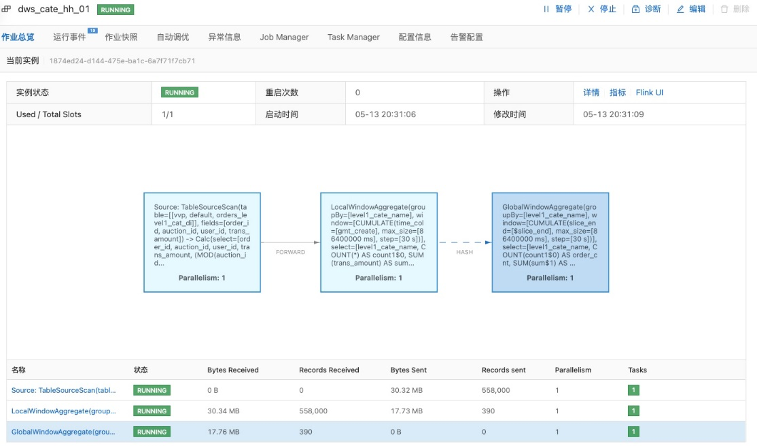
![]()
可以看到,它和之前Tumble Window运行的结构类似,也是预聚合加上全局聚合,它和Tumble Window的区别就是并不需要等到这一天数据都到齐了才输出结果。
- 运行日志 – 观察调试结果

![]()
从上方示例可以看到,在20:47:00的时候,已经有00:00:00到20:47:00的结果累积,还有对应的4列统计值。下一个输出就是接下来的累计窗口,可以看到20:47:00到20:48:00就是一个累计的步长,这样既满足了天级别的累计统计需求,也能够满足准实时的要求。
(七)示例小结:电商交易数据-实时数仓场景
然后我们来整体总结一下以上的示例。

![]()
在接入层到明细层的清洗处理特点是相对简单,也比较明确,比如业务逻辑上需要做固定的过滤条件,包括维度的扩展,这都是非常明确和直接的。
从明细层到汇总层,例子中的分钟级统计,我们是用了Tumble Window,而小时级因为实时性的要求,换成了Group Aggregation,然后到天级累积分别展示Group Aggregation和新引入的Cumulate Window。
从汇总层的计算特点来说,我们需要去关注业务上的实时性要求和数据准确性要求,然后根据实际情况选择Window聚合或者Group 聚合。
这里为什么要提到数据准确性?
在一开始比较Window Aggregation和Group Aggregation的时候,提到Group Aggregation的实时性非常好,但是它的数据准确性是依赖于State的TTL,当统计的周期大于TTL,那么TTL的数据可能会失真。
相反,在Window Aggregation上,对乱序的容忍度有一个上限,比如最多接受等一分钟,但在实际的业务数据中,可能99%的数据能满足这样的要求,还有1%的数据可能需要一个小时后才来。基于WATERMARK的处理,默认它就是一个丢弃策略,超过了最大的offset的这些数据就会被丢弃,不纳入统计,此时数据也会失去它的准确性,所以这是一个相对的指标,需要根据具体的业务场景做选择。
开发常见问题和解法
(一)开发中的常见问题

![]()
上方是实时计算真实业务接触过程中比较高频的问题。
首先是实时计算不知道该如何下手,怎么开始做实时计算,比如有些同学有批处理的背景,然后刚开始接触Flink SQL,不知道从哪开始。
另外一类问题是SQL写完了,也清楚输入处理的数据量大概是什么级别,但是不知道实时作业运行起来之后需要设定多大的资源
还有一类是SQL写得比较复杂,这个时候要去做调试,比如要查为什么计算出的数据不符合预期等类似问题,许多同学反映无从下手。
作业跑起来之后如何调优,这也是一个非常高频的问题。
(二)开发常见问题解法

![]()
1.实时计算如何下手?
对于上手的问题,社区有很多官方的文档,也提供了一些示例,大家可以从简单的例子上手,慢慢了解SQL里面不同的算子,在流式计算的时候会有一些什么样的特性。
此外,还可以关注开发者社区实时计算 Flink 版、 ververica.cn网站、 B 站的Apache Flink 公众号等分享内容。
逐渐熟悉了SQL之后,如果想应用到生产环境中去解决真实的业务问题,阿里云的行业解决方案里也提供了一些典型的架构设计,可以作为参考。
2.复杂作业如何调试?
如果遇到千行级别的复杂SQL,即使对于Flink的开发同学来也不能一目了然地把问题定位出来,其实还是需要遵循由简到繁的过程,可能需要借助一些调试的工具,比如前面演示的平台调试功能,然后做分段的验证,把小段SQL局部的结果正确性调试完之后,再一步一步组装起来,最终让这个复杂作业能达到正确性的要求。
另外,可以利用SQL语法上的特性,把SQL组织得更加清晰一点。实时计算Flink产品上有一个代码结构功能,可以比较方便地定位长SQL里具体的语句,这都是一些辅助工具。
3.作业初始资源设置,如何调优?
我们有一个经验是根据输入的数据,初始做小并发测试一下,看它的性能如何,然后再去估算。在大并发压测的时候,按照需求的吞吐量,逐步逼近,然后拿到预期的性能配置,这个是比较直接但也比较可靠的方式。
调优这一块主要是借助于作业的运行是情况,我们会去关注一些重点指标,比如说有没有产生数据的倾斜,维表的Lookup Join需要访问外部存储,有没有产生IO的瓶颈,这都是影响作业性能的常见瓶颈点,需要加以关注。
在实时计算Flink产品上集成了一个叫AutoPilot的功能,可以理解为类似于自动驾驶,在这种功能下,初始资源设多少就不是一个麻烦问题了。
在产品上,设定作业最大的资源限制后,根据实际的数据处理量,该用多少资源可以由引擎自动帮我们去调到最优状态,根据负载情况来做伸缩。