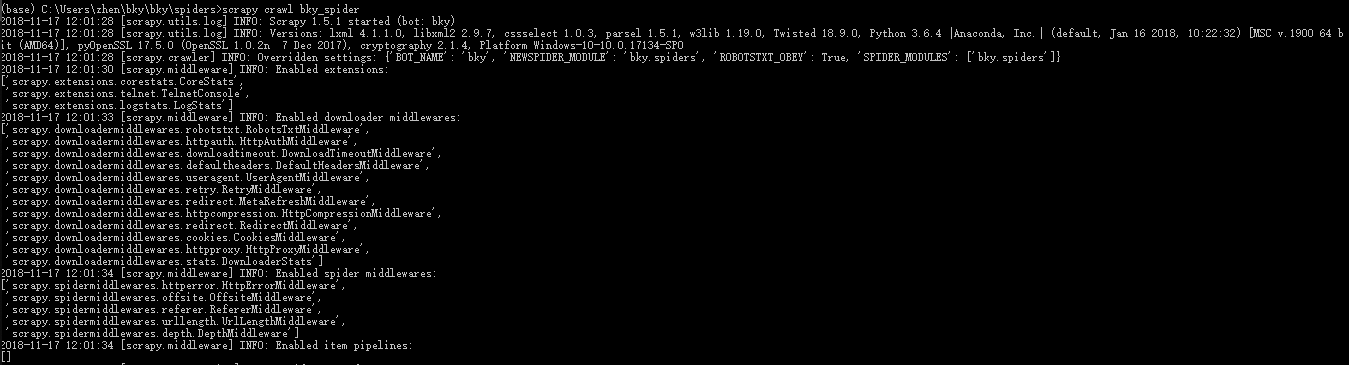
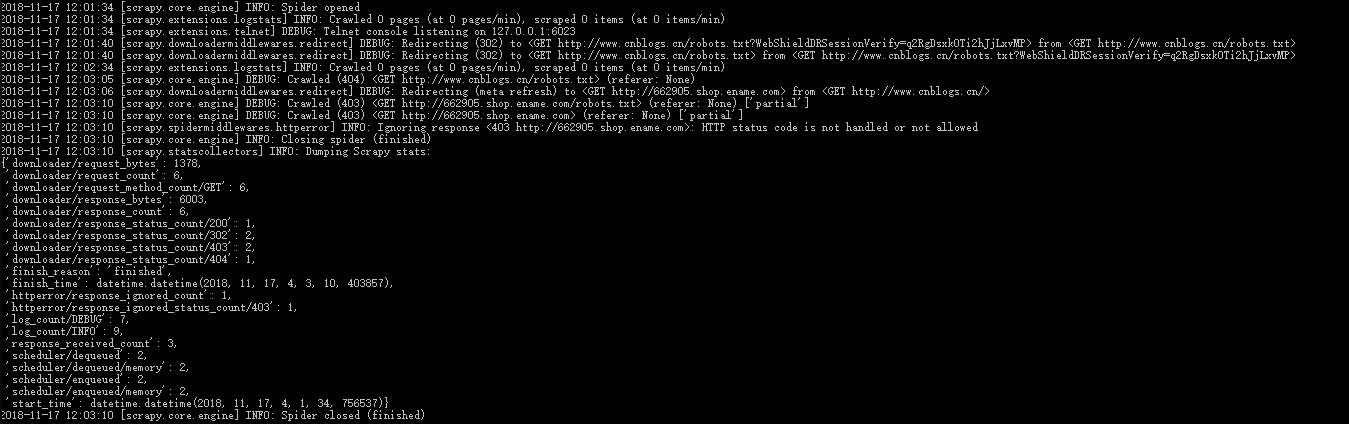
1.安装Scrapy
打开Anaconda Prompt,执行:pip install Scrapy执行安装!
注意:要是安装过程中抛出:
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools(或者类似信息)的需要提前安装(根据自己的python版本安装,cp36是指匹配python3.6.x版本,amd64是指64位系统):

下载网站:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
完成之后执行安装:
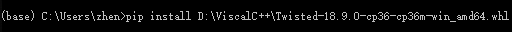
安装成功后再执行:pip install Scrapy执行安装即可!
2.查看scrapy
输入:scrapy,表示安装成功!

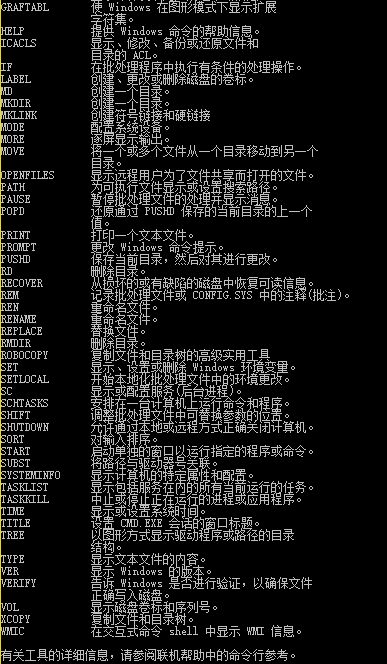
3.查看命令
输入:help

4.创建Scrapy项目
执行命令:scrapy startproject bky

这表示创建成功!
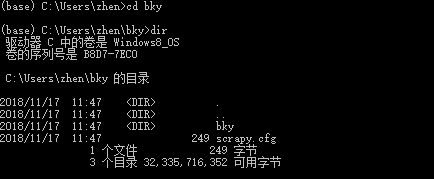
执行cd bky, dir命令查看详情:
5.创建spider
查看spiders目录

创建一个新的spider,执行命令:scrapy genspider bky_spider "www.cnblogs.cn"


6.执行spider,爬取网页数据
修改bky_spider.py代码:

执行命令:scrapy crawl bky_spider