一.SparkStreaming简介
SparkStreaming是核心Spark API的扩展,可以实现实时【准实时】数据流的可伸缩、高吞吐及容错处理。数据可以从像Kafka、Flume、HDFS/S3、Twitter或TCP套接字等许多来源获取。并且可以使用高级的算子例如,map,reduce,join和window等。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表盘。实际上,它还可以在数据集上应用Spark的机器学习和图像处理算法。

在内部,它的工作方式如下:SparkStreaming接收实时输入数据流,并将数据分成微批处理,然后由Spark引擎进行处理,以分批生成最终结果流。

SparkStreaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka,Flume和Kinesis等来源的输入数据流来创建DStream,也可以通过对其它DStream应用高级的算子来转换成新的DStream。在内部,DStream为RDD的序列。
二.SparkStreaming特点
1.便于使用
Spark Streaming将Apache Spark的 语言集成API 引入流处理,使您可以像编写批处理作业一样编写流式作业。它支持Java,Scala和Python。
2.容错
Spark Streaming可以开箱即用,恢复丢失的工作和操作状态【例如滑动窗口】,而无需任何额外的代码。
3.Spark集成
将流式传输与批量交互式查询相结合。通过在Spark上运行,Spark Streaming允许您重复使用相同的代码进行批处理,将流加入历史数据,或者在流状态下运行即席查询。构建强大的交互式应用程序,而不只是分析。
4.部署选项
Spark Streaming可以从HDFS, Flume,Kafka, Twitter和 ZeroMQ读取数据 。您还可以定义自己的自定义数据源。
在Spark的独立集群模式 或其它受支持的集群资源管理器上运行Spark Streaming 。它还包括一个本地运行模式进行开发。在生产中,Spark Streaming使用ZooKeeper和HDFS实现高可用性。
三.代码实现
package big.data.analyse.streaming import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} /** * Created by zhen on 2017/11/19. */ object StreamingDemo { Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别 def main(args: Array[String]) { val conf = new SparkConf().setMaster("local[2]").setAppName("StreaingTest") val ssc = new StreamingContext(conf,Seconds(10)) val lines = ssc.socketTextStream("master",9999) // 与nc端口对应 val words = lines.flatMap(_.split(" ")) val pairs = words.map(word=>(word,1)).reduceByKey(_+_) pairs.foreachRDD(row => row.foreach(println)) ssc.start() ssc.awaitTermination() ssc.stop() } }
注意:还可以使用sparkContext创建StreamingContext,例如:new StreamingContext(sc, Seconds(1))
四.启动nc和执行程序
1.简介
NetCat简称nc,在网络工具中有“瑞士军刀”美誉,其有Windows和Linux的版本。因为它短小精悍、功能实用,被设计为一个简单、可靠的网络工具,可通过TCP或UDP协议传输读写数据。同时,它还是一个网络应用Debug分析器,因为它可以根据需要创建各种不同类型的网络连接。
2.启动

3.执行
./bin/run-example streaming.NetworkWordCount master 9999
五.执行结果
nc端:

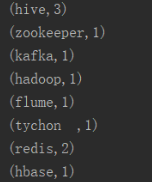
Spark Streaming端:

六.备注
1.streamingContext.start()表示开始接受数据并进行处理。
2.streamingContext.awaitTermination()表示等待停止使用【手动或由于任何错误】。
3.streamingContext.stop()表示可以是有手动停止。
4.一旦启动stremingContext,就无法设置新的流计算或将其添加到该流计算中。
5.streamingContext一旦停止,就无法重新启动。
6.streamingContext上的stop也会关闭sparkContext。要仅停止streamingContext,需要设置可选参数stopSparkContext为false。
7.只要在创建下一个streamingContext之前停止【不停止SparkContext】上一个StreamingContext,即可将SparkContext重新用于创建多个StreamingContext。
8.在本地模式时,请勿使用local或local[1]。这两种方式均意味着仅有一个线程用于运行本地任务。如果你使用的是基于接收器的输入DStream,则将使用单个线程来运行接收器,而不会留下线程来处理接收到的数据。因此,在本地运行时,请始终使用local[n],其中n>要运行的接收者数。