URL与资源
URI与URL
URL(统一资源定位器)与URN(统一资源名)共同构成了URI(统一资源标识符)。
URL是通过描述资源的位置来标识资源的,而URN是通过名字来标识资源的,是与资源所处位置无关的,HTTP中处理的只是URL,其组成为:
- 方案(scheme): 说明访问的协议方式。
- 位置(host): 说明资源的位置,通常是以主机IP或者域名表示。
- 路径(path): 说明对于资源在主机中的位置。

URL的语法
完整的URL由九部分构成,但是不是说URL要使用全部的九个部分,而是这九个部分构成了通用的格式。
<scheme> : //<user>:<password> @ <host>:<port>/<path>;<params> ? <query> # <flag>
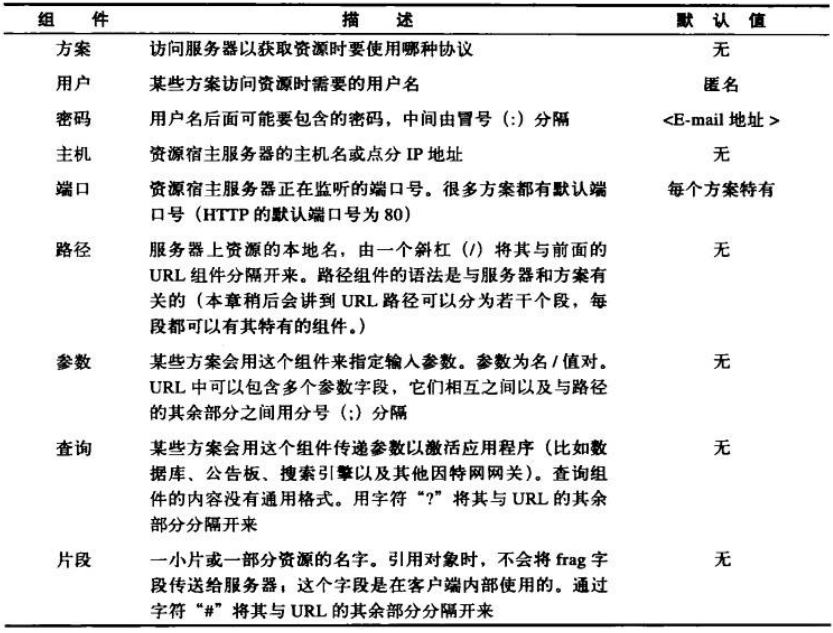
- scheme: 方案说明了对资源的访问方式,负责告知程序应当用什么协议,其大小写不敏感。
- host: 对应标注了主机的位置,可以是IP也可以是域名。
- port: 不同的协议对应不同的应用,相应的占用不同的端口。
- user与password: 有些应用协议是需要用户和密码进行身份认证的,比如ftp服务器,就可以使用user与password在URL中进行认证,ftp如果不指定用户与密码,则对应的会有一个匿名的用户名与一个默认的密码。
- path: 说明资源在主机中的对应位置,对应的每个路径段还可以添加额外的参数来辅助控制。
- params: 对应用于辅助资源获取的参数,可以在路径后面进行提供,也就是在最后一个路径端提供,或者在每个路径段都可以提供参数,得到这样的形式:
<scheme>: //<host>/<path>;<params>/<path>;<params>/<path>;<params>… - query: 查询字符串可以用来查询与缩小请求资源类型的范围。具体的查询参数以键值对的形式表示,键值对之间使用 ‘&’ 来进行分割。
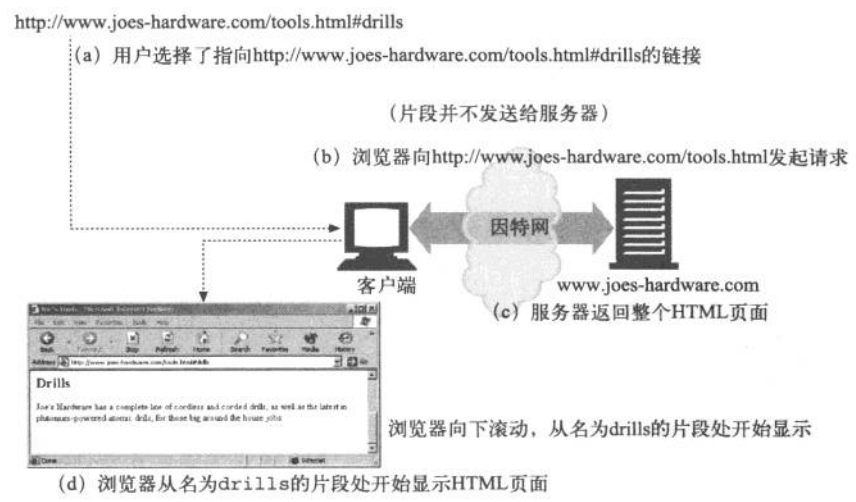
- flag: 对于一些资源类型可以进行进一步的细分,URL的前面部分指向的是一个大型的文档类型,可以将这一文档细分,得到对应的片段,进行分段的请求,使用 ‘#’ 字符来进行划分;但是相应的服务器处理的是整个资源,客户端无法传片段给服务器,相应的浏览器是获取全部的部分,之后再对用户感兴趣的部分进行展示。
字符与编码
ASCII码无法满足世界各个语言的要求,所以使用一种转义序列,将ASCII中的有限子集拿来对任意的字符值进行编码。
编码的过程为了保证安全性,使用一种转义的方式来表示一些敏感的字符串。其形式是以 ‘%’ 开始后面加上两个ASCII码的十六进制数。

相应的敏感字符就会被限制,有些是被保留他用,有的与其他的协议成分混淆。

在应用程序进行URL交流之前,其会先将不安全的字符进行编码,形成一种规范形式,之后就可以无顾虑的在程序间进行共享了。