clickhouse笔记
1 clickhouse特点
1.1 完备的DBMS功能
-
DDL(数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务。
-
DML(数据操作语言):可以动态查询、插入、修改或删除数据。
-
权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
-
分布式管理:提供集群模式,能够自动管理多个数据库节点。
-
数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
1.2 列式存储与数据压缩
-
按列存储与按行存储相比,前者可以有效减少查询时所需扫描的数据量
-
能更好的压缩数据,压缩前:abcdefghi_bcdefghi 压缩后:abcdefghi_(9,8)。数据库的瓶颈通常在IO,很高的压缩比,可以大大减轻数据读取的压力,提高响应速度
-
除去字符串类型,其他类型的字段通常是固定长度的,而且在磁盘和内存的字节顺序通常是一致的,可以直接映射,省去了解析的过程
-
列式存储可以向量化的处理一个字段。可以将一个列的一整块连续数据读入CPU cache,效率非常高
'B|C|D', 'B|D', 'A|C', 'B|D' ,'B|C', 'B|C|D' A,B,C,D [0,1,1,1] [0,1,0,1] [1,0,1,0] [0,1,0,1] [0,1,1,0] [0,1,1,1]
1.3 关系模型与SQL查询
ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。与此同时,ClickHouse完全使用SQL作为查询语言(支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL)
1.4 多线程与分布式
ClickHouse在数据存取方面,既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理),可以说是将多线程和分布式的技术应用到了极致。
1.5 多主架构
ClickHouse则采用多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景
1.6 数据分片与分布式查询
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现
ClickHouse提供了本地表(Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
第2章 安装与部署
2.1 ClickHouse的安装过程
1.centos7 取消打开文件限制
ulimit -n # 查看打开文件下载
ulimit -a # 查看详情
vim /etc/security/limits.conf
* soft nofile 1024000
* hard nofile 1024000
hive - nofile 1024000
hive - nproc 1024000
vim /etc/security/limits.d/20-nproc.conf
#加大普通用户限制 也可以改为unlimited
* soft nproc 409600
root soft nproc unlimited
shutdown -r now 重启服务
2.centos7取消selinux
getenforce # 查看
/usr/sbin/sestatus -v # 查看
vim /etc/selinux/config # 关闭selinux服务
将SELINUX=enforcing改为SELINUX=disabled
shutdown -r now 重启服务
3.关闭防火墙
firewall-cmd --state # 查看防火墙状态
systemctl stop firewalld # 禁用防火墙
systemctl start firewalld # 启动防火墙
4.安装依赖
yum install -y curl pygpgme yum-utils coreutils epel-release libtool *unixODBC*
5.下载安装包
http://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
clickhouse-client-20.6.6.7-2.noarch.rpm 11-Sep-2020 09:55 102K
clickhouse-client-20.6.7.4-2.noarch.rpm 18-Sep-2020 13:16 102K
clickhouse-client-20.7.2.30-2.noarch.rpm 31-Aug-2020 16:20 102K
clickhouse-client-20.7.3.7-2.noarch.rpm 18-Sep-2020 12:43 102K
clickhouse-client-20.8.2.3-2.noarch.rpm 08-Sep-2020 12:46 115K
clickhouse-client-20.8.3.18-2.noarch.rpm 18-Sep-2020 12:23 115K
clickhouse-common-static-20.6.6.7-2.x86_64.rpm 11-Sep-2020 09:55 120M
clickhouse-common-static-20.6.7.4-2.x86_64.rpm 18-Sep-2020 13:16 120M
clickhouse-common-static-20.7.2.30-2.x86_64.rpm 31-Aug-2020 16:20 120M
clickhouse-common-static-20.7.3.7-2.x86_64.rpm 18-Sep-2020 12:44 120M
clickhouse-common-static-20.8.2.3-2.x86_64.rpm 08-Sep-2020 12:46 137M
clickhouse-common-static-20.8.3.18-2.x86_64.rpm 18-Sep-2020 12:23 137M
clickhouse-server-20.6.6.7-2.noarch.rpm 11-Sep-2020 09:56 125K
clickhouse-server-20.6.7.4-2.noarch.rpm 18-Sep-2020 13:17 125K
clickhouse-server-20.7.2.30-2.noarch.rpm 31-Aug-2020 16:21 126K
clickhouse-server-20.7.3.7-2.noarch.rpm 18-Sep-2020 12:44 126K
clickhouse-server-20.8.2.3-2.noarch.rpm 08-Sep-2020 12:46 139K
clickhouse-server-20.8.3.18-2.noarch.rpm 18-Sep-2020 12:24 139K
6.创建安装目录
mkdir -p /usr/local/clickhouse
[root@localhost clickhouse]# ll
总用量 141008
-rw-r--r--. 1 root root 117705 9月 22 14:02 clickhouse-client-20.8.3.18-2.noarch.rpm
-rw-r--r--. 1 root root 144128776 9月 22 14:04 clickhouse-common-static-20.8.3.18-2.x86_64.rpm
-rw-r--r--. 1 root root 142403 9月 22 14:01 clickhouse-server-20.8.3.18-2.noarch.rpm
rpm -ivh *.rpm # 安装clickhouse
rpm -Uvh *.rpm # 在线升级clickhouse版本 在升级的过程中 原来的配置将会保存下来
rpm -e clickhouse-client-20.3.8.53-2.noarch # 卸载
rpm -e clickhouse-common-static-20.3.8.53-2.x86_64 # 卸载
rpm -e clickhouse-server-20.3.8.53-2.noarch # 卸载
7.配置文件
[root@localhost clickhouse-server]# pwd
/etc/clickhouse-server
[root@localhost clickhouse-server]# ll
总用量 76
drwxr-xr-x. 2 root root 6 8月 26 09:52 config.d
-rw-r--r--. 1 root root 22601 8月 26 09:54 config.xml # clickhouse配置文件
-rw-r--r--. 1 root root 33738 9月 18 06:29 config.xml.rpmnew
lrwxrwxrwx. 1 root root 41 8月 26 09:52 preprocessed -> /var/lib/clickhouse//preprocessed_configs
drwxr-xr-x. 2 root root 6 8月 26 09:52 users.d
-rw-r--r--. 1 root root 5522 8月 26 10:06 users.xml # 用户的配置文件
-rw-r--r--. 1 root root 5587 9月 18 06:29 users.xml.rpmnew
8.config.xml配置文件详解
<?xml version="1.0"?>
<yandex>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log> <!-- 日志存放目录 -->
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog> <!-- 错误日志存放目录 -->
<size>1000M</size> <!-- 文件的大小。文件达到大小后,ClickHouse将对其进行存档并重命名,并在其位置创建一个新的日志文件 -->
<count>10</count> <!-- ClickHouse存储的已归档日志文件的数量 -->
</logger>
<http_port>8123</http_port> <!-- 通过HTTP连接到服务器的端口 -->
<tcp_port>9000</tcp_port> <!--通过TCP协议与客户端进行通信的端口,即ClickHouse端口。-->
<mysql_port>9004</mysql_port> <!--通过MySQL协议与客户端通信的端口。-->
<https_port>8443</https_port> <!-- 通过HTTP连接到服务器的端口 -->
<tcp_port_secure>9440</tcp_port_secure> <!--通过TCP协议与客户端进行通信的端口,即ClickHouse端口。 与OpenSSL设置一起使用。-->
<openSSL>
<server>
<certificateFile>/etc/clickhouse-server/server.crt</certificateFile> <!--PEM格式的客户端/服务器证书文件的路径。如果privateKeyFile包含证书,则可以忽略它-->
<privateKeyFile>/etc/clickhouse-server/server.key</privateKeyFile> <!--具有PEM证书的秘密密钥的文件的路径。该文件可能同时包含密钥和证书-->
<dhParamsFile>/etc/clickhouse-server/dhparam.pem</dhParamsFile> <!--dh文件路径-->
<verificationMode>none</verificationMode> <!--检查节点证书的方法-->
<loadDefaultCAFile>true</loadDefaultCAFile> <!--指示将使用OpenSSL的内置CA证书。可接受的值:true,false-->
<cacheSessions>true</cacheSessions> <!--启用或禁用缓存会话。必须与sessionIdContext结合使用。可接受的值:true,false。-->
<disableProtocols>sslv2,sslv3</disableProtocols> <!--不允许使用的协议-->
<preferServerCiphers>true</preferServerCiphers> <!--首选服务器密码-->
</server>
<client>
<loadDefaultCAFile>true</loadDefaultCAFile> <!--指示将使用OpenSSL的内置CA证书。可接受的值:true,false-->
<cacheSessions>true</cacheSessions> <!--启用或禁用缓存会话。必须与sessionIdContext结合使用。可接受的值:true,false。-->
<disableProtocols>sslv2,sslv3</disableProtocols> <!--不允许使用的协议-->
<preferServerCiphers>true</preferServerCiphers> <!--首选服务器密码-->
<invalidCertificateHandler> <!--用于验证无效证书的类-->
<name>RejectCertificateHandler</name>
</invalidCertificateHandler>
</client>
</openSSL>
<interserver_http_port>9009</interserver_http_port> <!--于在ClickHouse服务器之间交换数据的端口。-->
<listen_host>0.0.0.0</listen_host> <!--限制来源主机的请求 允许所有-->
<listen_host>127.0.0.1</listen_host> <!--限制来源主机的请求 只允许本机访问-->
<max_connections>4096</max_connections> <!--最大连接数-->
<keep_alive_timeout>3</keep_alive_timeout> <!--ClickHouse在关闭连接之前等待传入请求的秒数。 默认为3秒。-->
<max_concurrent_queries>100</max_concurrent_queries> <!--同时处理的最大请求数。-->
<max_open_files>262144</max_open_files> <!--打开最大的文件数,默认最大值-->
<uncompressed_cache_size>8589934592</uncompressed_cache_size> <!--表引擎从MergeTree使用的未压缩数据的缓存大小(以字节为单位,8G)-->
<mark_cache_size>5368709120</mark_cache_size> <!--标记缓存的大小,用于MergeTree系列的表中(以字节为单位,5G)-->
<path>/var/lib/clickhouse/</path> <!--数据的目录路径-->
<storage_configuration> <!--多个存储路径-->
<disks>
<disk_name_a> <!--自定义磁盘名称 -->
<path>/var/lib/clickhouse1/</path> <!--必填项,用于指定磁盘路径 -->
<keep_free_space_bytes>1073741824</keep_free_space_bytes> <!--选填项,以字节为单位,用于定义磁盘的预留空间。-->
</disk_name_a>
<disk_name_b>
<path>/var/lib/clickhouse2/</path> <!--必填项,用于指定磁盘路径 -->
<keep_free_space_bytes>1073741824</keep_free_space_bytes> <!--选填项,以字节为单位,用于定义磁盘的预留空间。-->
</disk_name_b>
</disks>
</storage_configuration>
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path> <!--用于处理大型查询的临时数据的路径。-->
<tmp_policy>tmp</tmp_policy> <!--用于存储临时文件。如果未设置,则使用tmp_path,否则将忽略它。-->
<user_files_path>/var/lib/clickhouse/user_files/</user_files_path> <!--存储用户文件的目录-->
<users_config>users.xml</users_config> <!--用户配置文件,可以配置用户访问、profiles、quota、查询等级等-->
<default_profile>default</default_profile> <!--默认设置配置文件-->
<default_database>default</default_database> <!--默认数据库-->
<timezone>Europe/Moscow</timezone> <!--服务器的时区,定为UTC时区或地理位置 莫斯科时间-->
<!-- <umask>022</umask> -->
<mlock_executable>false</mlock_executable>
<include_from>/etc/metrica.xml</include_from> <!--带替换文件的路径-->
<zookeeper incl="zookeeper-servers" optional="true" /> <!--ClickHouse与ZooKeeper群集进行交互的设置-->
<macros incl="macros" optional="true" /> <!--复制表的参数替换,如果不使用复制表,则可以省略-->
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval> <!--重新加载内置词典的时间间隔(以秒为单位),默认3600。可以在不重新启动服务器的情况下“即时”修改词典-->
<max_session_timeout>3600</max_session_timeout> <!-- 最大会话超时时间 单位秒-->
<default_session_timeout>60</default_session_timeout> <!--默认会话超时时间 单位秒-->
<graphite> <!--将数据发送到Graphite,它是一款企业级监控。-->
<host>localhost</host> <!--Graphite服务器-->
<port>42000</port> <!--Graphite服务器上的端口-->
<timeout>0.1</timeout> <!--发送超时时间,以秒为单位-->
<interval>60</interval> <!--发送间隔,以秒为单位-->
<root_path>one_min</root_path> <!--密钥的前缀-->
<hostname_in_path>true</hostname_in_path> <!--讲机名追加到根路径(默认= true)-->
<metrics>true</metrics> <!--从system.metrics表发送数据-->
<events>true</events> <!--从system.events表发送在该时间段内累积的增量数据-->
<events_cumulative>false</events_cumulative> <!--从system.events表发送累积数据-->
<asynchronous_metrics>true</asynchronous_metrics> <!--从system.asynchronous_metrics表发送数据-->
</graphite>
<query_log> <!--通过log_queries = 1 在用户配置表中设置,记录了ClickHouse服务中所有已经执行的查询记录。查询记录在system.query_log表中-->
<database>system</database> <!--库名-->
<table>query_log</table> <!--表名-->
<partition_by>toYYYYMM(event_date)</partition_by> <!--自定义分区键-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds> <!--将数据从内存中的缓冲区刷新到表的时间间隔-->
</query_log>
<trace_log> <!--trace_log系统表操作的设置。 采样查询探查器收集的堆栈跟踪-->
<database>system</database> <!--库名-->
<table>trace_log</table> <!--表名-->
<partition_by>toYYYYMM(event_date)</partition_by> <!--自定义分区键-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds> <!--将数据从内存中的缓冲区刷新到表的时间间隔-->
</trace_log>
<query_thread_log> <!--使用log_query_threads = 1设置,在用户配置表中设置 记录了所有线程的执行查询的信息-->
<database>system</database> <!--库名-->
<table>query_thread_log</table> <!--表名-->
<partition_by>toYYYYMM(event_date)</partition_by> <!--自定义分区键-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds> <!--将数据从内存中的缓冲区刷新到表的时间间隔-->
</query_thread_log>
<part_log> <!--记录了MergeTree系列表引擎的分区操作日志。如添加或合并数据-->
<database>system</database> <!--库名-->
<table>part_log</table> <!--表名-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds> <!--将数据从内存中的缓冲区刷新到表的时间间隔-->
</part_log>
<text_log> <!--log日志记录了ClickHouse运行过程中产生的一系列打印日志,包括INFO、DEBUG和Trace-->
<database>system</database> <!--库名-->
<table>text_log</table> <!--表名-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds> <!--将数据从内存中的缓冲区刷新到表的时间间隔-->
<level></level>
</text_log>
<metric_log> <!--用于将system.metrics和system.events中的数据汇聚到一起-->
<database>system</database> <!--库名-->
<table>metric_log</table> <!--表名-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds> <!--将数据从内存中的缓冲区刷新到表的时间间隔-->
<collect_interval_milliseconds>1000</collect_interval_milliseconds> <!--收集间隔-->
</metric_log>
<dictionaries_config>*_dictionary.xml</dictionaries_config> <!--外部词典的配置文件的路径,在config配置文件中指定。路径可以包含通配符*和?的绝对或则相对路径-->
<compression incl="clickhouse_compression"> <!--MergeTree引擎表的数据压缩设置。配置模板如-->
<case>
<min_part_size>10000000000</min_part_size> <!-- 数据部分的最小大小 -->
<min_part_size_ratio>0.01</min_part_size_ratio> <!-- 数据部分大小与表大小的比率 -->
<method>LZ4</method> <!--压缩算法,zstd和lz4-->
</case>
</compression>
<distributed_ddl> <!--分布式ddl配置 create drop alter -->
<path>/clickhouse/task_queue/ddl</path> <!--分布式DDL在ZooKeeper内使用的根路径为-->
</distributed_ddl>
<max_table_size_to_drop>0</max_table_size_to_drop> <!--删除表的限制,默认50G,0表示不限制。如果MergeTree表的大小超过max_table_size_to_drop(以字节为单位),则无法使用DROP查询将其删除-->
<max_partition_size_to_drop>0</max_partition_size_to_drop> <!--删除分区限制 默认50G,0表示不限制-->
<format_schema_path>/var/lib/clickhouse/format_schemas/</format_schema_path> <!--包含输入格式文件的目录路径-->
<query_masking_rules> <!--基于Regexp的规则,应用于查询以及所有日志消息。再其存储在服务器日志中,system.query_log,system.text_log,system.processes表以及以日志形式发送给客户端。这样可以防止SQL查询中的敏感数据泄漏记录到日志中-->
<rule>
<name>hide SSN</name> <!--规则名称-->
<regexp>\b\d{3}-\d{2}-\d{4}\b</regexp> <!--正则表达式-->
<replace>000-00-0000</replace> <!--替换,敏感数据的替换字符串(默认为可选-六个星号)-->
</rule>
</query_masking_rules>
<disable_internal_dns_cache>1</disable_internal_dns_cache> <!--禁用内部DNS缓存,默认0-->
</yandex>
9.users.xml配置详解
<?xml version="1.0"?>
<yandex>
<profiles>
<default>
<max_memory_usage>10000000000</max_memory_usage> <!--单个查询最大内存使用量-->
<max_memory_usage_for_user>0</max_memory_usage_for_user> <!--在单个ClickHouse服务进程中,以用户为单位进行统计,单个用户在运行查询时,限制使用的最大内存用量,默认值为0,即不做限制-->
<max_memory_usage_for_all_queries>0</max_memory_usage_for_all_queries><!--在单个ClickHouse服务进程中,所有运行的查询累加在一起,限制使用的最大内存用量,默认为0不做限制-->
<max_partitions_per_insert_block>100</max_partitions_per_insert_block><!--在单次INSERT写入的时候,限制创建的最大分区个数,默认值为100个。如果超出这个阈值数目,将会得到异常-->
<max_rows_to_group_by>0</max_rows_to_group_by> <!--在执行GROUP BY聚合查询的时候,限制去重后的聚合KEY的最大个数,默认值为0,即不做限制-->
<max_bytes_before_external_group_by>0</max_bytes_before_external_group_by> <!--在执行GROUP BY聚合查询的时候,限制使用的最大内存用量,默认值为0,即不做限制-->
<use_uncompressed_cache>0</use_uncompressed_cache> <!--是否使用未压缩块的缓存。接受0或1。默认情况下,0(禁用)-->
<load_balancing>random</load_balancing> <!--指定用于分布式查询处理的副本选择算法 默认:Random
random是默认的负载均衡算法,在ClickHouse的服务节点中,拥有一个全局计数器errors_count,当服务发生任何异常时,该计数累积加1。而random算法会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,则在它们之中随机选择一个
nearest_hostname可以看作random算法的变种,首先它会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,则选择集群配置中host名称与当前host最相似的一个
in_order同样可以看作random算法的变种,首先它会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,则按照集群配置中replica的定义顺序逐个选择。
first_or_random可以看作in_order算法的变种,首先它会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,它首先会选择集群配置中第一个定义的replica,如果该replica不可用,则进一步随机选择一个其他的replica。
-->
<log_queries> 1</log_queries> <!--用户配置开启query_log查询日志,记录了ClickHouse服务中所有已经执行的查询记录-->
<log_query_threads> 1</log_query_threads> <!--用户配置开启query_thread_log日志 记录了所有线程的执行查询的信息-->
<part_log>1</part_log> <!--用户配置开启part_log日志,记录了MergeTree系列表引擎的分区操作日志-->
<text_log>1</text_log> <!--用户配置开启text_log日志 记录了ClickHouse运行过程中产生的一系列打印日志,包括INFO、DEBUG和Trace-->
<metric_log>1</metric_log> <!--用户配置开启metric_log日志 用于将system.metrics和system.events中的数据汇聚到一起-->
</default>
<readonly> <!--读权限、写权限和设置权限 readonly:用户名-->
<readonly>0</readonly> <!--不进行任何限制(默认值)-->
<readonly>1</readonly> <!--只拥有读权限(只能执行SELECT、EXISTS、SHOW和DESCRIBE)-->
<readonly>2</readonly> <!--拥有读权限和设置权限(在读权限基础上,增加了SET查询)-->
<allow_ddl>0</allow_ddl> <!--·当取值为0时,不允许DDL查询 create drop alter-->
<allow_ddl>1</allow_ddl> <!--·当取值为1时,允许DDL查询(默认值)-->
</readonly>
</profiles>
<users> <!--用户配置-->
<default> <!--用户名-->
<password></password> <!--置登录密码 免密码登入,支持明文、SHA256加密和double_sha1加密三种形式-->
<password>123</password> <!--明文密码-->
<password_sha256_hex>a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3</password_sha256_hex> <!--SHA256加密 # echo -n 123 | openssl dgst -sha256-->
<password_double_sha1_hex>23ae809ddacaf96af0fd78ed04b6a265e05aa257</password_double_sha1_hex> <!--double_sha1加密 # echo -n 123 | openssl dgst -sha1 -binary | openssl dgst -sha1-->
<networks incl="networks" replace="replace"> <!--限制IP访问-->
<ip>::/0</ip> --允许任何地址访问
<ip>127.0.0.1</ip> --允许本地访问
<ip>192.168.107.216</ip> --允许该IP访问
</networks>
<allow_databases> <!--限制访问数据库 不指定表示不限制-->
<database>default</database> <!--库名称-->
<database>test_dictionaries</database>
</allow_databases>
<databases> <!--限制访问表的数据 不指定表示不限制-->
<database_name><!--数据库名称-->
<table_name><!--表名称-->
<filter> id < 10</filter><!--数据过滤条件-->
</table_name>
</database_name>
</databases>
<profile>default</profile>
<quota>default</quota>
</default>
</users>
<quotas> <!--限制资源被过度使用,当使用的资源数量达到阈值时,那么正在进行的操作会被自动中断-->
<default> <!--自定义名称,全局唯一-->
<interval> <!--配置时间间隔,每个时间内的资源消耗限制-->
<duration>3600</duration> <!--表示累积的时间周期,单位是秒-->
<queries>0</queries> <!--表示在周期内允许执行的查询次数,0表示不限制-->
<errors>0</errors> <!--表示在周期内允许发生异常的次数,0表示不限制-->
<result_rows>0</result_rows> <!--表示在周期内允许查询返回的结果行数,0表示不限制-->
<read_rows>0</read_rows> <!--表示在周期内在分布式查询中,允许远端节点读取的数据行数,0表示不限制。-->
<execution_time>0</execution_time> <!--表示周期内允许执行的查询时间,单位是秒,0表示不限制。-->
</interval>
</default>
</quotas>
</yandex>
10.metrika.xml详解
vim /etc/metrika.xml
<yandex>
<clickhouse_remote_servers> <!-- 集群设置 -->
<shunwang> <!-- clickhouse显示名称 可以自己修改 -->
<shard> <!-- 一分片 -->
<weight>1</weight> <!--分片权重-->
<internal_replication>false</internal_replication> <!-- 是否开启自动复制 -->
<replica> <!-- 副本 -->
<host>192.168.104.91</host> <!--指定部署了ClickHouse节点的服务器地址-->
<port>9000</port> <!--指定ClickHouse服务的TCP端口-->
<user>default</user> <!--ClickHouse用户,默认为default 选填-->
<password></password> <!--ClickHouse的用户密码,默认为空字符串 选填-->
<secure>9440</secure> <!--SSL连接的端口,默认为9440 选填-->
<compression>true</compression> <!--是否开启数据压缩功能,默认为true 选填-->
</replica>
<replica> <!-- 副本 -->
<host>192.168.104.92</host> <!--指定部署了ClickHouse节点的服务器地址-->
<port>9000</port> <!--指定ClickHouse服务的TCP端口-->
<user>default</user> <!--ClickHouse用户,默认为default 选填-->
<password></password> <!--ClickHouse的用户密码,默认为空字符串 选填-->
<secure>9440</secure> <!--SSL连接的端口,默认为9440 选填-->
<compression>true</compression> <!--是否开启数据压缩功能,默认为true 选填-->
</replica>
</shard>
<shard>
<weight>1</weight> <!--分片权重-->
<internal_replication>false</internal_replication> <!-- 是否开启自动复制 -->
<replica> <!-- 副本 -->
<host>192.168.104.93</host> <!--指定部署了ClickHouse节点的服务器地址-->
<port>9000</port> <!--指定ClickHouse服务的TCP端口-->
<user>default</user> <!--ClickHouse用户,默认为default 选填-->
<password></password> <!--ClickHouse的用户密码,默认为空字符串 选填-->
<secure>9440</secure> <!--SSL连接的端口,默认为9440 选填-->
<compression>true</compression> <!--是否开启数据压缩功能,默认为true 选填-->
</replica>
<replica> <!-- 副本 -->
<host>192.168.104.94</host> <!--指定部署了ClickHouse节点的服务器地址-->
<port>9000</port> <!--指定ClickHouse服务的TCP端口-->
<user>default</user> <!--ClickHouse用户,默认为default 选填-->
<password></password> <!--ClickHouse的用户密码,默认为空字符串 选填-->
<secure>9440</secure> <!--SSL连接的端口,默认为9440 选填-->
<compression>true</compression> <!--是否开启数据压缩功能,默认为true 选填-->
</replica>
</shard>
</shunwang>
</clickhouse_remote_servers>
<macros>
<shard>01</shard> <!--分片编号不能重复 如果是副本要相同-->
<replica>192.168.104.91</replica> <!--副本名称,创建复制表时有用,每个节点不同,整个集群唯一,建议使用主机名-->
</macros>
<networks>
<ip>::/0</ip>
</networks>
<!-- zookeeper 配置 集群高可用 -->
<zookeeper-servers>
<node index="1">
<host>192.168.104.91</host>
<port>2181</port>
</node>
<node index="2">
<host>192.168.104.92</host>
<port>2181</port>
</node>
<node index="3">
<host>192.168.104.93</host>
<port>2181</port>
</node>
<session_timeout_ms>30000</session_timeout_ms> <!--客户端会话的最大超时(以毫秒为单位)-->
<operation_timeout_ms>10000</operation_timeout_ms>
<root>/path/to/zookeeper/node</root> <!--用作ClickHouse服务器使用的znode的根的znode-->
<identity>user:password</identity> <!--用户和密码,ZooKeeper可能需要这些用户和密码才能访问请求的znode-->
</zookeeper-servers>
<clickhouse_compression> <!--MergeTree引擎表的数据压缩设置。配置模板如-->
<case>
<min_part_size>10000000000</min_part_size> <!-- 数据部分的最小大小 -->
<min_part_size_ratio>0.01</min_part_size_ratio> <!-- 数据部分大小与表大小的比率 -->
<method>LZ4</method> <!--压缩算法,zstd和lz4-->
</case>
</clickhouse_compression>
</yandex>
11.其他配置文件
(1)/etc/security/limits.d/clickhouse.conf:文件句柄数量的配置,默认值如下所示。该配置也可以通过config.xml的max_open_files修改。
# cat /etc/security/limits.d/clickhouse.conf
clickhouse soft nofile 262144
clickhouse hard nofile 262144
(2)/etc/cron.d/clickhouse-server:cron定时任务配置,用于恢复因异常原因中断的ClickHouse服务进程,其默认的配置如下。
# cat /etc/cron.d/clickhouse-server
# */10 * * * * root (which service > /dev/null 2>&1 && (service clickhouse-server condstart ||:)) || /etc/init.d/clickhouse-server condstart > /dev/null 2>&1
12.启动clickhouse
service clickhouse-server start # 启动server端clickhouse-server 单机版clickhouse部署完成
service clickhouse-server stop # 停止server端clickhouse-server
service clickhouse-server restart # 重启server端clickhouse-server
service clickhouse-server status # 查看server端服务开启/关闭状态
clickhouse-client --multiline -h 192.168.104.91 --port 9000 -u ck --password shunwang
# multiline:可以同时执行多条语句默认 ; 结束
# -h:ip
# --port:端口
# -u:账号
# --password:密码
# --database/-d:登录的数据库,默认值为default
# --time/-t:在非交互式执行时,会打印每条SQL的执行时间
# --query/-q:只能在非交互式查询时使用,用于指定SQL语句 --query="SELECT 1;SELECT 2;"
select * from system.clusters # 查看是否成功 显示下面信息 集群搭建成功
第3章 数据定义
3.1 ClickHouse的数据类型
3.1.1 基础类型
基础类型只有数值、字符串和时间三种类型,没有Boolean类型,但可以使用整型的0或1替代。
1.数值类型
数值类型分为整数、浮点数和定点数三类
1)Int
Int8、Int16、Int32和Int64指代4种大小的Int类型,其末尾的数字正好表明了占用字节的大小(8位=1字节)
ClickHouse支持无符号的整数,使用前缀U表示

2)Float
ClickHouse直接使用Float32和Float64代表单精度浮点数以及双精度浮点数

:) SELECT toFloat32('0.12345678901234567890') as a , toTypeName(a)
┌──────a─┬─toTypeName(toFloat32('0.12345678901234567890'))─┐
│ 0.12345679 │ Float32 │
└────────┴───────────────────────────────┘
:) SELECT toFloat64('0.12345678901234567890') as a , toTypeName(a)
┌────────────a─┬─toTypeName(toFloat64('0.12345678901234567890'))─┐
│ 0.12345678901234568 │ Float64 │
└─────────────┴──────────────────────────────┘
3)Decimal
如果要求更高精度的数值运算,则需要使用定点数。ClickHouse提供了Decimal32、Decimal64和Decimal128三种精度的定点数。可以通过两种形式声明定点:简写方式有Decimal32(S)、Decimal64(S)、Decimal128(S)三种,原生方式为Decimal(P,S),其中:
·P代表精度,决定总位数(整数部分+小数部分),取值范围是1~38;
·S代表规模,决定小数位数,取值范围是0~P。

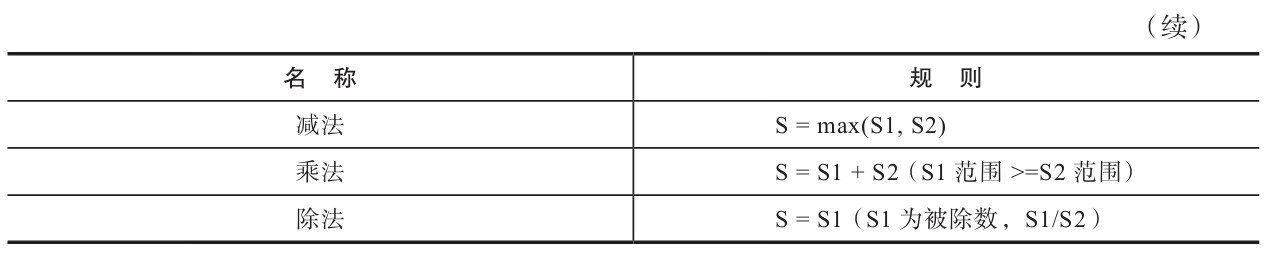
在进行加法运算时,S取最大值。例如下面的查询,toDecimal64(2,4)与toDecimal32(2,2)相加后S=4:
:) SELECT toDecimal64(2,4) + toDecimal32(2,2)
┌─plus(toDecimal64(2, 4), toDecimal32(2, 2))─┐
│ 4.0000 │
└───────────────────────────┘
在进行减法运算时,其规则与加法运算相同,S同样会取最大值。例如toDecimal32(4,4)与toDecimal64(2,2)相减后S=4:
:) SELECT toDecimal32(4,4) - toDecimal64(2,2)
┌─minus(toDecimal32(4, 4), toDecimal64(2, 2))┐
│ 2.0000 │
└────────────────────────────┘
在进行乘法运算时,S取两者S之和。例如下面的查询,toDecimal64(2,4)与toDecimal32(2,2)相乘后S=4+2=6:
:) SELECT toDecimal64(2,4) * toDecimal32(2,2)
┌─multiply(toDecimal64(2, 4), toDecimal32(2, 2))┐
│ 4.000000 │
└─────────────────────────────┘
在进行除法运算时,S取被除数的值,此时要求被除数S必须大于除数S,否则会报错。例如toDecimal64(2,4)与toDecimal32(2,2)相除后S=4:
:) SELECT toDecimal64(2,4) / toDecimal32(2,2)
┌─divide(toDecimal64(2, 4), toDecimal32(2, 2))┐
│ 1.0000 │
└───────────────────────────┘

2.字符串类型
1)String
字符串由String定义,长度不限。因此在使用String的时候无须声明大小。
2)FixedString
FixedString类型和传统意义上的Char类型有些类似,对于一些字符有明确长度的场合,可以使用固定长度的字符串。定长字符串通过FixedString(N)声明,其中N表示字符串长度。FixedString使用null字节填充末尾字符
:) SELECT toFixedString('abc',5) , LENGTH(toFixedString('abc',5)) AS LENGTH
┌─toFixedString('abc', 5)─┬─LENGTH─┐
│ abc │ 5 │
└────────────────┴──────┘
3)UUID
UUID是一种数据库常见的主键类型,在ClickHouse中直接把它作为一种数据类型。UUID共有32位,它的格式为8-4-4-4-12。如果一个UUID类型的字段在写入数据时没有被赋值,则会依照格式使用0填充,例如:
CREATE TABLE UUID_TEST (
c1 UUID,
c2 String
) ENGINE = Memory;
--第一行UUID有值
INSERT INTO UUID_TEST SELECT generateUUIDv4(),'t1'
--第二行UUID没有值
INSERT INTO UUID_TEST(c2) VALUES('t2')
:) SELECT * FROM UUID_TEST
┌─────────────────────c1─┬─c2─┐
│ f36c709e-1b73-4370-a703-f486bdd22749 │ t1 │
└───────────────────────┴────┘
┌─────────────────────c1─┬─c2─┐
│ 00000000-0000-0000-0000-000000000000 │ t2 │
└───────────────────────┴────┘
3.时间类型
时间类型分为DateTime、DateTime64和Date三类。ClickHouse目前没有时间戳类型。时间类型最高的精度是秒,也就是说,如果需要处理毫秒、微秒等大于秒分辨率的时间,则只能借助UInt类型实现。
1)DateTime
DateTime类型包含时、分、秒信息,精确到秒,支持使用字符串形式写入:
CREATE TABLE Datetime_TEST (
c1 Datetime
) ENGINE = Memory
--以字符串形式写入
INSERT INTO Datetime_TEST VALUES('2019-06-22 00:00:00')
SELECT c1, toTypeName(c1) FROM Datetime_TEST
┌──────────c1─┬─toTypeName(c1)─┐
│ 2019-06-22 00:00:00 │ DateTime │
└─────────────┴───────────┘
2)DateTime64
DateTime64可以记录亚秒,它在DateTime之上增加了精度的设置,例如:
CREATE TABLE Datetime64_TEST (
c1 Datetime64(2)
) ENGINE = Memory
--以字符串形式写入
INSERT INTO Datetime64_TEST VALUES('2019-06-22 00:00:00')
SELECT c1, toTypeName(c1) FROM Datetime64_TEST
┌─────────────c1─┬─toTypeName(c1)─┐
│ 2019-06-22 00:00:00.00 │ DateTime │
└───────────────┴──────────┘
3)Date
Date类型不包含具体的时间信息,只精确到天,它同样也支持字符串形式写入:
CREATE TABLE Date_TEST (
c1 Date
) ENGINE = Memory
--以字符串形式写入
INSERT INTO Date_TEST VALUES('2019-06-22')
SELECT c1, toTypeName(c1) FROM Date_TEST
┌─────────c1─┬─toTypeName(c1)─┐
│ 2019-06-22 │ Date │
└───────────┴──────────┘
3.1.2 复合类型
除了基础数据类型之外,ClickHouse还提供了数组、元组、枚举和嵌套四类复合类型。这些类型通常是其他数据库原生不具备的特性。拥有了复合类型之后,ClickHouse的数据模型表达能力更强了。
1.Array
数组有两种定义形式,常规方式array(T):
SELECT array(1, 2) as a , toTypeName(a)
┌─a───┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└─────┴────────────────┘
或者简写方式[T]:
SELECT [1, 2]
在定义表字段时,数组需要指定明确的元素类型
CREATE TABLE Array_TEST (
c1 Array(String)
) engine = Memory
2.Tuple
元组类型由1~n个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。
SELECT tuple(1,'a',now()) AS x, toTypeName(x)
┌─x─────────────────┬─toTypeName(tuple(1, 'a', now()))─┐
│ (1,'a','2019-08-28 21:36:32') │ Tuple(UInt8, String, DateTime) │
└───────────────────┴─────────────────────┘
或者简写方式(T):
SELECT (1,2.0,null) AS x, toTypeName(x)
┌─x──────┬─toTypeName(tuple(1, 2., NULL))───────┐
│ (1,2,NULL) │ Tuple(UInt8, Float64, Nullable(Nothing)) │
└───────┴──────────────────────────┘
在定义表字段时,元组也需要指定明确的元素类型:
CREATE TABLE Tuple_TEST (
c1 Tuple(String,Int8)
) ENGINE = Memory;
3.Enum
ClickHouse支持枚举类型,这是一种在定义常量时经常会使用的数据类型。ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二致。枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对应(String:Int8)和(String:Int16)
CREATE TABLE Enum_TEST (
c1 Enum8('ready' = 1, 'start' = 2, 'success' = 3, 'error' = 4)
) ENGINE = Memory;
在定义枚举集合的时候,有几点需要注意。首先,Key和Value是不允许重复的,要保证唯一性。其次,Key和Value的值都不能为Null,但Key允许是空字符串。在写入枚举数据的时候,只会用到Key字符串部分,但是在后续对枚举的所有操作中(包括排序、分组、去重、过滤等),会使用Int类型的Value值。
INSERT INTO Enum_TEST VALUES('ready');
INSERT INTO Enum_TEST VALUES('start');
4.Nested
嵌套类型,顾名思义是一种嵌套表结构。一张数据表,可以定义任意多个嵌套类型字段,但每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型
CREATE TABLE nested_test (
name String,
age UInt8 ,
dept Nested(
id UInt8,
name String
)
) ENGINE = Memory;
INSERT INTO nested_test VALUES ('bruce' , 30 , [10000,10001,10002], ['研发部','技术支持中心','测试部']);
--行与行之间,数组长度无须对齐
INSERT INTO nested_test VALUES ('bruce' , 30 , [10000,10001], ['研发部','技术支持中心']);
在访问嵌套类型的数据时需要使用点符号,例如:
SELECT name, dept.id, dept.name FROM nested_test
┌─name─┬─dept.id──┬─dept.name─────────────┐
│ bruce │ [16,17,18] │ ['研发部','技术支持中心','测试部'] │
└────┴───────┴────────────────────┘
4.1.3 特殊类型
1.Nullable
准确来说,Nullable并不能算是一种独立的数据类型,它更像是一种辅助的修饰符,需要与基础数据类型一起搭配使用。Nullable类型与Java8的Optional对象有些相似,它表示某个基础数据类型可以是Null值。其具体用法如下所示:
CREATE TABLE Null_TEST (
c1 String,
c2 Nullable(UInt8)
) ENGINE = TinyLog;
通过Nullable修饰后c2字段可以被写入Null值:
INSERT INTO Null_TEST VALUES ('nauu',null)
INSERT INTO Null_TEST VALUES ('bruce',20)
SELECT c1 , c2 ,toTypeName(c2) FROM Null_TEST
┌─c1───┬───c2─┬─toTypeName(c2)─┐
│ nauu │ NULL │ Nullable(UInt8) │
│ bruce │ 20 │ Nullable(UInt8) │
└─────┴──────┴───────────┘
在使用Nullable类型的时候还有两点值得注意:首先,它只能和基础类型搭配使用,不能用于数组和元组这些复合类型,也不能作为索引字段;其次,应该慎用Nullable类型,包括Nullable的数据表,不然会使查询和写入性能变慢。因为在正常情况下,每个列字段的数据会被存储在对应的[Column].bin文件中。如果一个列字段被Nullable类型修饰后,会额外生成一个[Column].null.bin文件专门保存它的Null值。这意味着在读取和写入数据时,需要一倍的额外文件操作。
2.Domain
域名类型分为IPv4和IPv6两类,本质上它们是对整型和字符串的进一步封装。IPv4类型是基于UInt32封装的,它的具体用法如下所示:
CREATE TABLE IP4_TEST (
url String,
ip IPv4
) ENGINE = Memory;
INSERT INTO IP4_TEST VALUES ('www.nauu.com','192.0.0.0')
SELECT url , ip ,toTypeName(ip) FROM IP4_TEST
┌─url──────┬─────ip─┬─toTypeName(ip)─┐
│ www.nauu.com │ 192.0.0.0 │ IPv4 │
└────────┴───────┴──────────┘
(1)出于便捷性的考量,例如IPv4类型支持格式检查,格式错误的IP数据是无法被写入的,例如:
INSERT INTO IP4_TEST VALUES ('www.nauu.com','192.0.0')
Code: 441. DB::Exception: Invalid IPv4 value.
(2)出于性能的考量,同样以IPv4为例,IPv4使用UInt32存储,相比String更加紧凑,占用的空间更小,查询性能更快。IPv6类型是基于FixedString(16)封装的,它的使用方法与IPv4别无二致
3.2 如何定义数据表
3.2.1 数据库
创建数据库的完整语法如下所示:
CREATE DATABASE IF NOT EXISTS db_name [ENGINE = engine]
IF NOT EXISTS表示如果已经存在一个同名的数据库,则会忽略后续的创建过程;
[ENGINE=engine]表示数据库所使用的引擎类型(是的,你没看错,数据库也支持设置引擎)。
数据库目前一共支持5种引擎,如下所示。
·Ordinary:默认引擎,在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引擎。
·Dictionary:字典引擎,此类数据库会自动为所有数据字典创建它们的数据表
·Memory:内存引擎,用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除。
·Lazy:日志引擎,此类数据库下只能使用Log系列的表引擎
·MySQL:MySQL引擎,此类数据库下会自动拉取远端MySQL中的数据,并为它们创建MySQL表引擎的数据表
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', 'database' , 'user', 'password')
--host:port — 链接的MySQL地址。
--database — 链接的MySQL数据库。
--user — 链接的MySQL用户。
--password — 链接的MySQL用户密码。
SHOW databases; -- 显示数据库
use cloud_joy_yun; -- 进入数据库
SHOW tables; -- 显示表
DROP DATABASE [IF EXISTS] db_name -- 删除数据库
3.2.2 数据表
第一种是常规定义方法,它的完整语法如下所示:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT] [COMMENT],
name2 [type] [DEFAULT] [COMMENT],
省略…
) ENGINE = engine
CREATE TABLE hits_v1 (
Title String,
URL String ,
EventTime DateTime
) ENGINE = Memory;
第二种定义方法是复制其他表的结构,具体语法如下所示:
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name AS [db_name2.] table_name2 [ENGINE = engine]
--创建新的数据库
CREATE DATABASE IF NOT EXISTS new_db
--将default.hits_v1的结构复制到new_db.hits_v1
CREATE TABLE IF NOT EXISTS new_db.hits_v1 AS default.hits_v1 ENGINE = TinyLog
上述语句将会把default.hits_v1的表结构原样复制到new_db.hits_v1,并且ENGINE表引擎可以与原表不同。
第三种定义方法是通过SELECT子句的形式创建,它的完整语法如下:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ENGINE = engine AS SELECT …
CREATE TABLE IF NOT EXISTS hits_v1_1 ENGINE = Memory AS SELECT * FROM hits_v1 --表结构和数据都会在
DROP TABLE [IF EXISTS] [db_name.]table_name
3.2.3 临时表
ClickHouse也有临时表的概念,创建临时表的方法是在普通表的基础之上添加temporary关键字,它的完整语法如下所示:
CREATE temporary TABLE [IF NOT EXISTS] table_name (
name1 [type] [DEFAULT] [COMMENT],
name2 [type] [DEFAULT] [COMMENT],
)
相比普通表而言,临时表有如下两点特殊之处:
- 它的生命周期是会话绑定的,所以它只支持Memory表引擎,如果会话结束,数据表就会被销毁;
- 临时表不属于任何数据库,所以在它的建表语句中,既没有数据库参数也没有表引擎参数。
- 临时表和普通可以同时存在,优先级临时表大于普通表
3.2.4 视图
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理。创建普通视图的完整语法如下所示:
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name AS SELECT ...
物化视图支持表引擎,数据保存形式由它的表引擎决定,创建物化视图的完整语法如下所示:
CREATE [materialized] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
物化视图创建好之后,如果源表被写入新数据,那么物化视图也会同步更新。物化视图目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保留。
3.2.5 追加新字段
假如需要对一张数据表追加新的字段,可以使用如下语法:
ALTER TABLE tb_name ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [AFTER name_after]
例如,在数据表的末尾增加新字段:
ALTER TABLE testcol_v1 ADD COLUMN OS String DEFAULT 'mac'
或是通过AFTER修饰符,在指定字段的后面增加新字段:
ALTER TABLE testcol_v1 ADD COLUMN IP String AFTER ID
对于数据表中已经存在的旧数据而言,新追加的字段会使用默认值补全。
3.2.6 修改数据类型
如果需要改变表字段的数据类型或者默认值,需要使用下面的语法:
ALTER TABLE tb_name modify COLUMN [IF EXISTS] name [type] [default_expr]
ALTER TABLE testcol_v1 modify COLUMN IP IPv4 --将String类型的IP字段修改为IPv4类型是可行的
3.2.7 修改备注
做好信息备注是保持良好编程习惯的美德之一,所以如果你还没有为列字段添加备注信息,那么就赶紧行动吧。追加备注的语法如下所示:
ALTER TABLE tb_name COMMENT COLUMN [IF EXISTS] name 'some comment'
ALTER TABLE testcol_v1 COMMENT COLUMN ID '主键ID' --为ID字段增加备注:
DESC testcol_v1 --使用DESC查询可以看到上述增加备注的操作已经生效:
┌─name─────┬─type──┬─comment─┐
│ ID │ String │ 主键ID │
└─────────┴─────┴──────┘
3.2.8 删除已有字段
假如要删除某个字段,可以使用下面的语句:
ALTER TABLE tb_name DROP COLUMN [IF EXISTS] name
ALTER TABLE testcol_v1 DROP COLUMN URL --执行下面的语句删除URL字段
3.2.9 移动数据表
在Linux系统中,mv命令的本意是将一个文件从原始位置A移动到目标位置B,但是如果位置A与位置B相同,则可以变相实现重命名的作用。ClickHouse的RENAME查询就与之有着异曲同工之妙,RENAME语句的完整语法如下所示:
RENAME TABLE [db_name11.]tb_name11 TO [db_name12.]tb_name12, [db_name21.]tb_name21 TO [db_name22.]tb_name22, ...
RENAME TABLE default.testcol_v1 TO db_test.testcol_v2 --testcol_v1从default默认数据库被移动到了db_test数据库,同时数据表被重命名为testcol_v2:
3.2.10 清空数据表
假设需要将表内的数据全部清空,而不是直接删除这张表,则可以使用TRUNCATE语句,它的完整语法如下所示:
TRUNCATE TABLE [IF EXISTS] [db_name.]tb_name
TRUNCATE TABLE db_test.testcol_v2 --将db_test.testcol_v2的数据一次性清空
3.3 数据分区的基本操作
目前只有MergeTree系列的表引擎支持数据分区。
3.3.1 查询分区信息
SELECT partition_id,name,table,database FROM system.parts WHERE table = 'partition_v2'
┌─partition_id─┬─name───────┬─table─────┬─database┐
│ 201905 │ 201905_1_1_0_6 │ partition_v2 │ default │
│ 201910 │ 201910_3_3_0_6 │ partition_v2 │ default │
│ 201911 │ 201911_4_4_0_6 │ partition_v2 │ default │
│ 201912 │ 201912_5_5_0_6 │ partition_v2 │ default │
└──────────┴──────────┴─────────┴──────┘
3.3.2 删除指定分区
ALTER TABLE tb_name DROP PARTITION partition_expr --删除一个指定分区
ALTER TABLE partition_v2 DROP PARTITION 201907 --假如现在需要更新partition_v2数据表整个7月份的数据,则可以先将7月份的分区删除:
INSERT INTO partition_v2 VALUES ('A004-update','www.bruce.com', '2019-07-02'),… --然后将整个7月份的新数据重新写入,就可以达到更新的目的:
3.3.3 复制分区数据
ClickHouse支持将A表的分区数据复制到B表,这项特性可以用于快速数据写入、多表间数据同步和备份等场景,它的完整语法如下:
ALTER TABLE B REPLACE PARTITION partition_expr FROM A
不过需要注意的是,并不是任意数据表之间都能够相互复制,它们还需要满足两个前提条件:
- ·两张表需要拥有相同的分区键;
- ·它们的表结构完全相同。
假设数据表partition_v2与先前的partition_v1分区键和表结构完全相同,那么应先在partition_v1中写入一批8月份的新数据:
INSERT INTO partition_v1 VALUES ('A006-v1','www.v1.com', '2019-08-05'),('A007-v1','www.v1.com', '2019-08-20')
-- 再执行下面的语句:
ALTER TABLE partition_v2 REPLACE PARTITION 201908 FROM partition_v1
--即能够将partition_v1的整个201908分区中的数据复制到partition_v2:
SELECT * from partition_v2 ORDER BY EventTime
┌─ID───────┬─URL──────┬─EventTime─┐
│ A000 │ www.nauu.com │ 2019-05-01 │
│ A001 │ www.nauu.com │ 2019-05-02 │
省略…
│ A004-update │ www.bruce.com │ 2019-07-02 │
│ A006-v1 │ www.v1.com │ 2019-08-05 │
│ A007-v1 │ www.v1.com │ 2019-08-20 │
└─────────┴─────────┴───────┘
3.3.4 重置分区数据
如果数据表某一列的数据有误,需要将其重置为初始值,此时可以使用下面的语句实现:
ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr
对于默认值的含义,笔者遵循如下原则:如果声明了默认值表达式,则以表达式为准;否则以相应数据类型的默认值为准。例如,执行下面的语句会重置partition_v2表内201908分区的URL数据重置。
ALTER TABLE partition_v2 CLEAR COLUMN URL in PARTITION 201908
查验数据后会发现,URL字段已成功被全部重置为空字符串了(String类型的默认值)。
SELECT * from partition_v2
┌─ID────┬─URL─┬──EventTime┐
│ A006-v1 │ │ 2019-08-05 │
│ A007-v1 │ │ 2019-08-20 │
└──────┴────┴────────┘
3.3.5 卸载与装载分区
表分区可以通过DETACH语句卸载,分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的子目录下。而装载分区则是反向操作,它能够将子目录下的某个分区重新装载回去。卸载与装载这一对伴生的操作,常用于分区数据的迁移和备份场景。卸载某个分区的语法如下所示:
ALTER TABLE tb_name DETACH PARTITION partition_expr
ALTER TABLE partition_v2 DETACH PARTITION 201908 --例如,执行下面的语句能够将partition_v2表内整个8月份的分区卸载:
此时再次查询这张表,会发现其中2019年8月份的数据已经没有了。而进入partition_v2的磁盘目录,则可以看到被卸载的分区目录已经被移动到了detached目录中:
# pwd
/chbase/data/data/default/partition_v2/detached
# ll
total 4
drwxr-x---. 2 clickhouse clickhouse 4096 Aug 31 23:16 201908_4_4_0
记住,一旦分区被移动到了detached子目录,就代表它已经脱离了ClickHouse的管理,ClickHouse并不会主动清理这些文件。这些分区文件会一直存在,除非我们主动删除或者使用ATTACH语句重新装载它们。装载某个分区的完整语法如下所示:
ALTER TABLE tb_name attach PARTITION partition_expr
ALTER TABLE partition_v2 attach PARTITION 201908 --再次执行下面的语句,就可以将刚才已被卸载的201908分区重新装载回去:
3.4 分布式DDL执行
将一条普通的DDL语句转换成分布式执行十分简单,只需加上ON CLUSTER cluster_name声明即可。例如,执行下面的语句后将会对ch_cluster集群内的所有节点广播这条DDL语句:
CREATE TABLE partition_v3 ON cluster ch_cluster(
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
3.5 数据的写入
第一种是使用VALUES格式的常规语法:第二种是使用指定格式的语法:
INSERT INTO [db.]table [(c1, c2, c3…)] FORMAT format_name data_set
INSERT INTO partition_v2 FORMAT CSV \
'A0017','www.nauu.com', '2019-10-01' \
'A0018','www.nauu.com', '2019-10-01' -- CSV格式写入为例:
第三种是使用SELECT子句形式的语法:
INSERT INTO [db.]table [(c1, c2, c3…)] SELECT ...
INSERT INTO partition_v2 SELECT * FROM partition_v1 --通过SELECT子句可将查询结果写入数据表,假设需要将partition_v1的数据写入partition_v2,则可以使用下面的语句:
3.6 数据的删除与修改
DELETE语句的完整语法如下所示:
ALTER TABLE [db_name.]table_name DELETE WHERE filter_expr
ALTER TABLE partition_v2 DELETE WHERE ID = 'A003' --删除partition_v2表内所有ID等于A003的数据:
数据修改除了需要指定具体的列字段之外,整个逻辑与数据删除别无二致,它的完整语法如下所示:
ALTER TABLE [db_name.]table_name UPDATE column1 = expr1 [, ...] WHERE filter_expr
ALTER TABLE partition_v2 UPDATE URL = 'www.wayne.com',OS = 'mac' WHERE ID IN (SELECT ID FROM partition_v2 WHERE EventTime = '2019-06-01') --根据WHERE条件同时修改partition_v2内的URL和OS字段:
3.7 表的查询
SELECT WatchID FROM hits_v1 --从数据表中取数
SELECT MAX_WatchID FROM (SELECT MAX(WatchID) AS MAX_WatchID FROM hits_v1) --从子查询中取数
第4章 MergeTree原理解析
属合并树(MergeTree)表引擎及其家族系列(*MergeTree)最为强大,在生产环境的绝大部分场景中,都会使用此系列的表引擎。只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性,同时也只有此系列的表引擎支持ALTER相关操作。
合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为家族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在MergeTree的基础之上各有所长。例如ReplacingMergeTree表引擎具有删除重复数据的特性,而SummingMergeTree表引擎则会按照排序键自动聚合数据。如果给合并树系列的表引擎加上Replicated前缀,又会得到一组支持数据副本的表引擎,例如ReplicatedMergeTree、ReplicatedReplacingMergeTree、ReplicatedSummingMergeTree等。合并树表引擎家族如图6-1所示。

4.1 MergeTree的创建方式与存储结构
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
4.1.1 MergeTree的创建方式
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略...
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, 省略...]
-
(1)PARTITION BY [选填]:分区键,用于指定表数据以何种标准进行分区。分区键既可以是单个列字段,也可以通过元组的形式使用多个列字段,同时它也支持使用列表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区
-
(2)ORDER BY [必填]:排序键,用于指定在一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。排序键既可以是单个列字段,例如ORDER BY CounterID,也可以通过元组的形式使用多个列字段,例如ORDER BY(CounterID,EventDate)。当使用多个列字段排序时,以ORDER BY(CounterID,EventDate)为例,在单个数据片段内,数据首先会以CounterID排序,相同CounterID的数据再按EventDate排序。
-
(3)PRIMARY KEY [选填]:主键,顾名思义,声明后会依照主键字段生成一级索引,用于加速表查询。默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用ORDER BY代为指定主键,无须刻意通过PRIMARY KEY声明。所以在一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree主键允许存在重复数据(ReplacingMergeTree可以去重)。
-
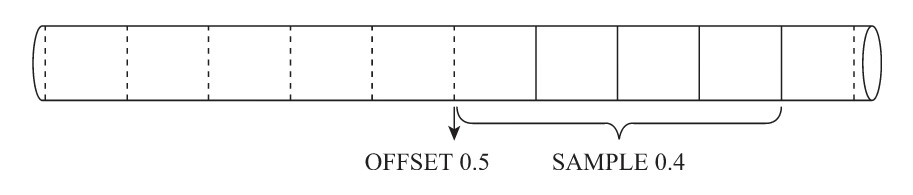
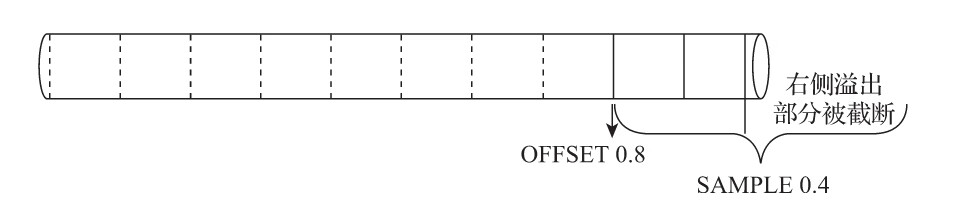
(4)sample BY [选填]:抽样表达式,用于声明数据以何种标准进行采样。如果使用了此配置项,那么在主键的配置中也需要声明同样的表达式,例如:
-
省略... ) ENGINE = MergeTree() ORDER BY (CounterID, EventDate, intHash32(UserID) SAMPLE BY intHash32(UserID) SELECT CounterID FROM hits_v1 SAMPLE 0.1 --随机返回10%的数据 SELECT count() FROM hits_v1 SAMPLE 10000 --随机返回1000条数据 SELECT CounterID FROM hits_v1 SAMPLE 0.4 OFFSET 0.5 --偏移50%数据开始采样40%数据 -
-
-
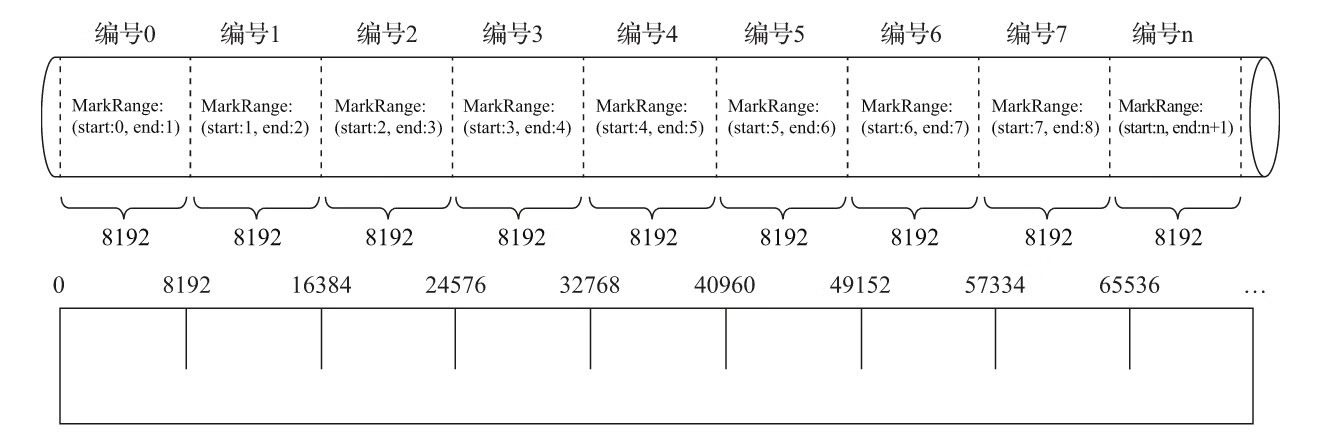
(5)SETTINGS:index_granularity [选填]:index_granularity对于MergeTree而言是一项非常重要的参数,它表示索引的粒度,默认值为8192。也就是说,MergeTree的索引在默认情况下,每间隔8192行数据才生成一条索引,其具体声明方式如下所示:
-
省略... ) ENGINE = MergeTree() 省略... SETTINGS index_granularity = 8192; -
(6)SETTINGS:enable_mixed_granularity_parts [选填]:设置是否开启自适应索引间隔的功能,默认开启。
-
(7)SETTINGS:index_granularity_bytes [选填]根据每一批次写入数据的体量大小,动态划分间隔大小。而数据的体量大小,正是由index_granularity_bytes参数控制的,默认为10M(10×1024×1024),设置为0表示不启动自适应功能
-
(8)SETTINGS:merge_with_ttl_timeout [选填]:TTL默认的合并频率,默认86400秒,即1天
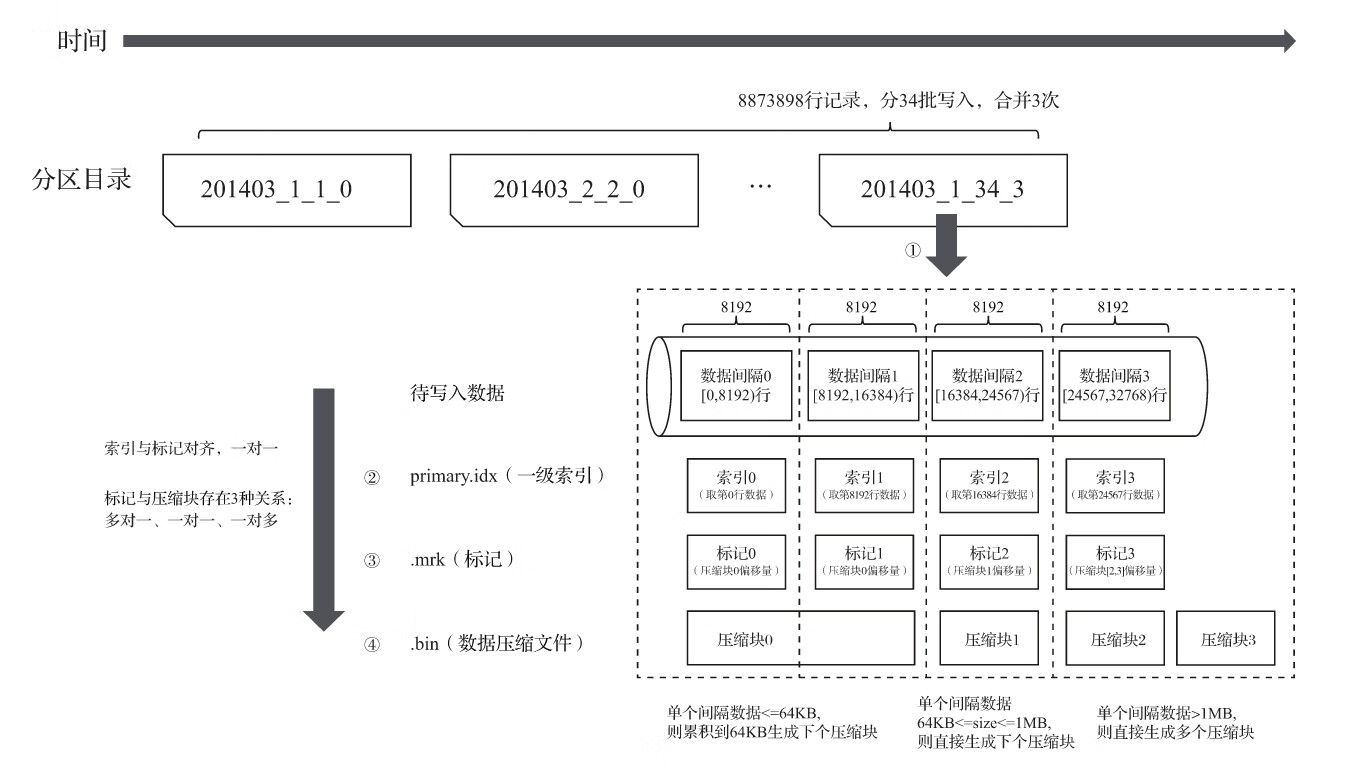
4.1.2 MergeTree的存储结构
MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上,其完整的存储结构如图6-2所示。
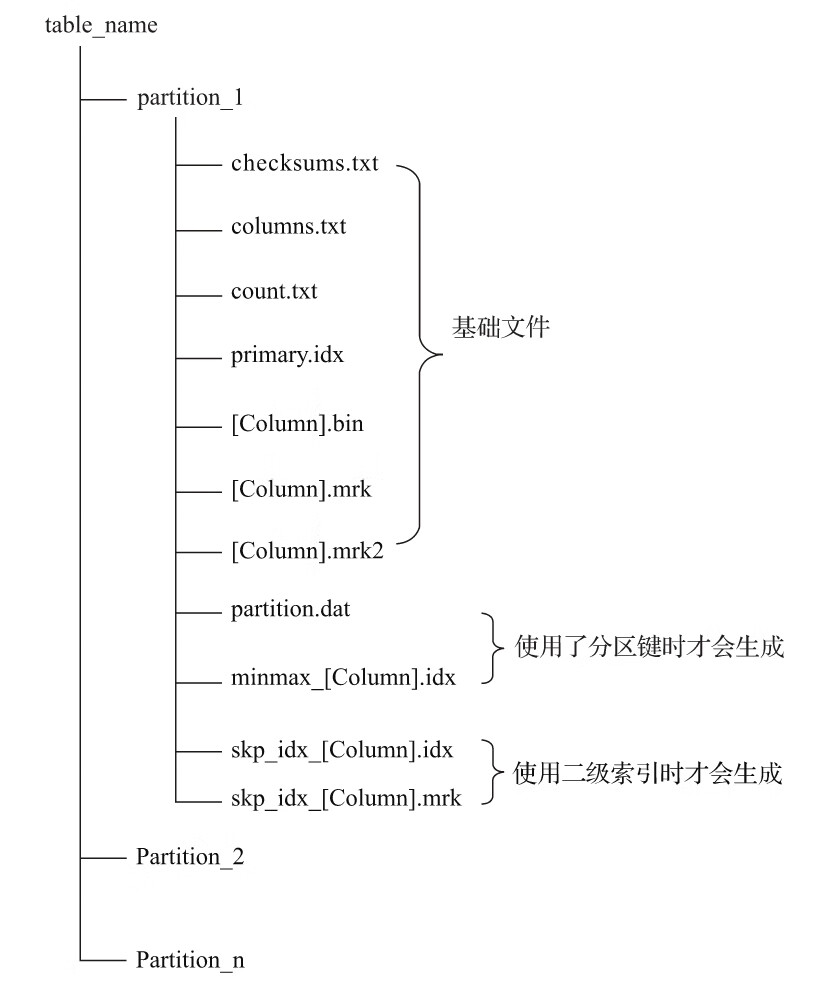
从图6-2中可以看出,一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件。接下来就逐一介绍它们的作用。
(1)partition:分区目录,余下各类数据文件(primary.idx、[Column].mrk、[Column].bin等)都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录
(2)checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
(3)columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息,例如:
$ cat columns.txt
columns format version: 1
4 columns:
'ID' String
'URL' String
'Code' String
'EventTime' Date
(4)count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数,例如:
$ cat count.txt
8
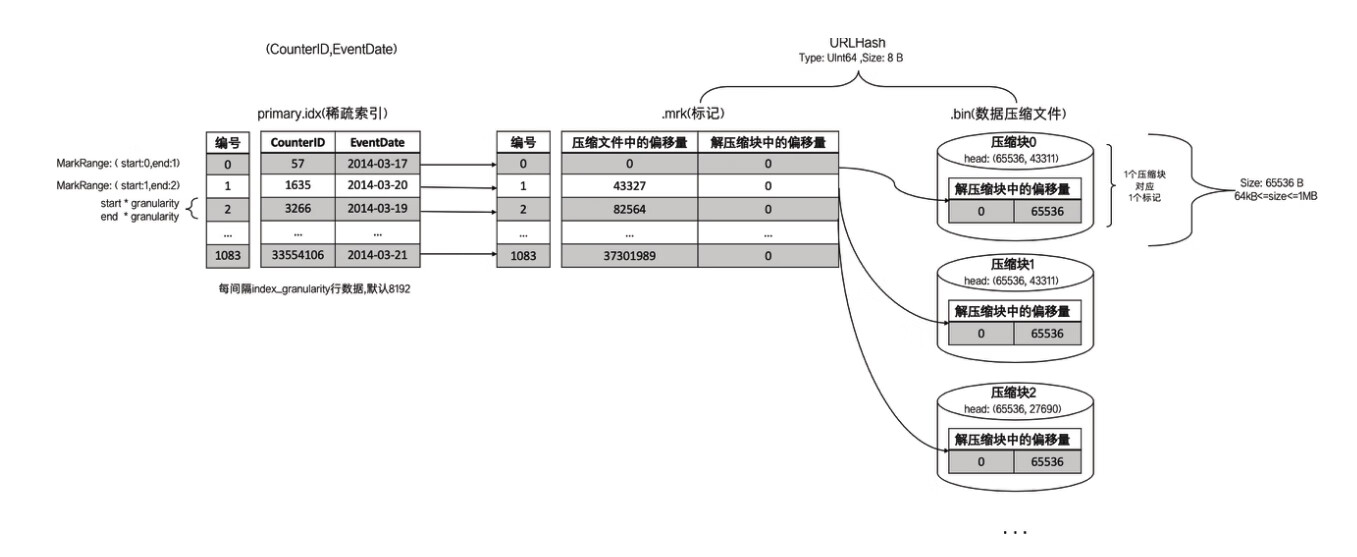
(5)primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDER BY或者PRIMARY KEY)。
(6)[Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据
(7)[Column].mrk:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息。标记文件与稀疏索引对齐,又与.bin文件一一对应,所以MergeTree通过标记文件建立了primary.idx稀疏索引与.bin数据文件之间的映射关系
(8)[Column].mrk2:如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。它的工作原理和作用与.mrk标记文件相同。
(9)partition.dat与minmax_[Column].idx:如果使用了分区键,例如PARTITION BY EventTime,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值
(10)skp_idx_[Column].idx与skp_idx_[Column].mrk:如果在建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件,它们同样也使用二进制存储。二级索引在ClickHouse中又称跳数索引
4.2 数据分区
4.2.1 数据的分区规则
- (1)不指定分区键:如果不使用分区键,即不使用PARTITION BY声明任何分区表达式,则分区ID默认取名为all,所有的数据都会被写入这个all分区。
- (2)使用整型:如果分区键取值属于整型(兼容UInt64,包括有符号整型和无符号整型),且无法转换为日期类型YYYYMMDD格式,则直接按照该整型的字符形式输出,作为分区ID的取值。
- (3)使用日期类型:如果分区键取值属于日期类型,或者是能够转换为YYYYMMDD格式的整型,则使用按照YYYYMMDD进行格式化后的字符形式输出,并作为分区ID的取值。
- (4)使用其他类型:如果分区键取值既不属于整型,也不属于日期类型,例如String、Float等,则通过128位Hash算法取其Hash值作为分区ID的取值。
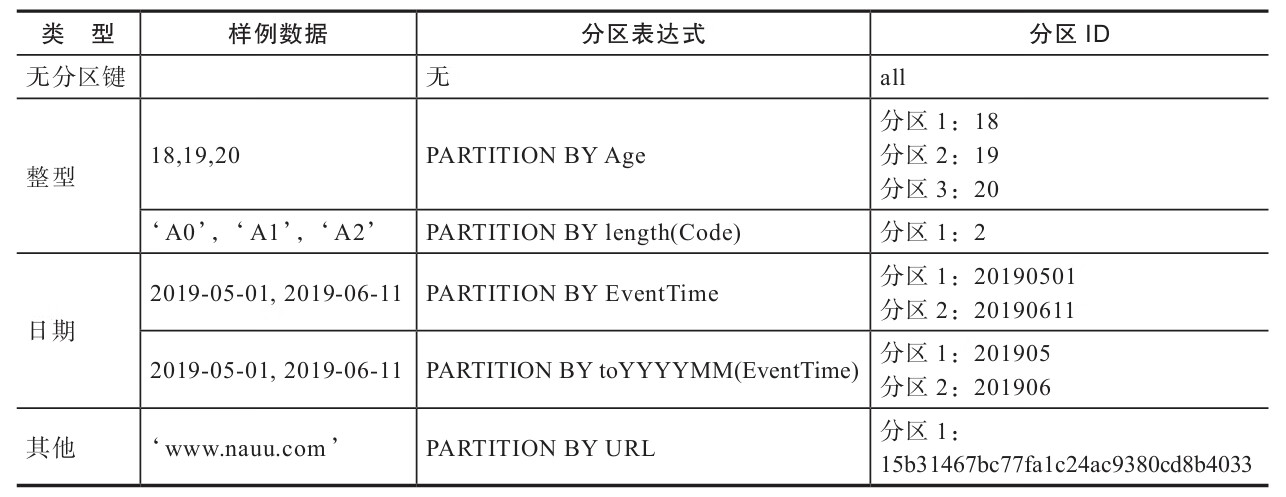
如果通过元组的方式使用多个分区字段,则分区ID依旧是根据上述规则生成的,只是多个ID之间通过“-”符号依次拼接。例如按照上述表格中的例子,使用两个字段分区:
PARTITION BY (length(Code),EventTime)
-- 则最终的分区ID会是下面的模样:
2-20190501
2-20190611
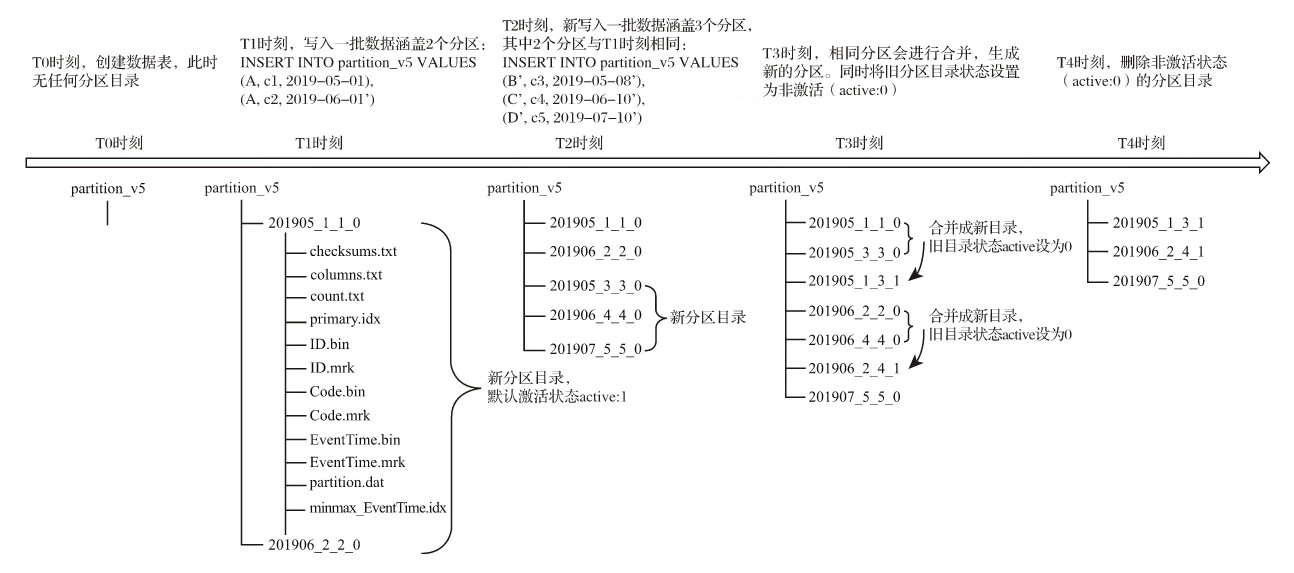
4.2.2 分区目录的命名规则
一个完整分区目录的命名公式如下所示:
PartitionID_MinBlockNum_MaxBlockNum_Level
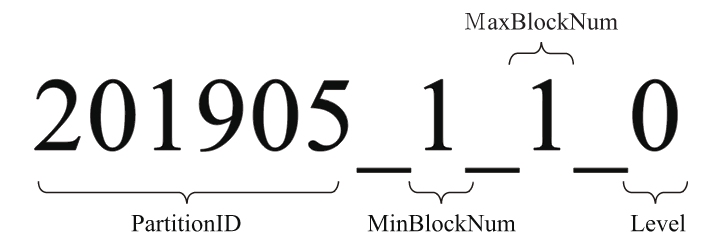
上图中,201905表示分区目录的ID;1_1分别表示最小的数据块编号与最大的数据块编号;而最后的_0则表示目前合并的层级。接下来开始分别解释它们的含义:
- (1)PartitionID:分区ID,无须多说,关于分区ID的规则在上一小节中已经做过详细阐述了。
- (2)MinBlockNum和MaxBlockNum:顾名思义,最小数据块编号与最大数据块编号。ClickHouse在这里的命名似乎有些歧义,很容易让人与稍后会介绍到的数据压缩块混淆。但是本质上它们毫无关系,这里的BlockNum是一个整型的自增长编号。如果将其设为n的话,那么计数n在单张MergeTree数据表内全局累加,n从1开始,每当新创建一个分区目录时,计数n就会累积加1。对于一个新的分区目录而言,MinBlockNum与MaxBlockNum取值一样,同等于n,例如201905_1_1_0、201906_2_2_0以此类推。但是也有例外,当分区目录发生合并时,对于新产生的合并目录MinBlockNum与MaxBlockNum有着另外的取值规则
- (3)Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄。数值越高表示年龄越大
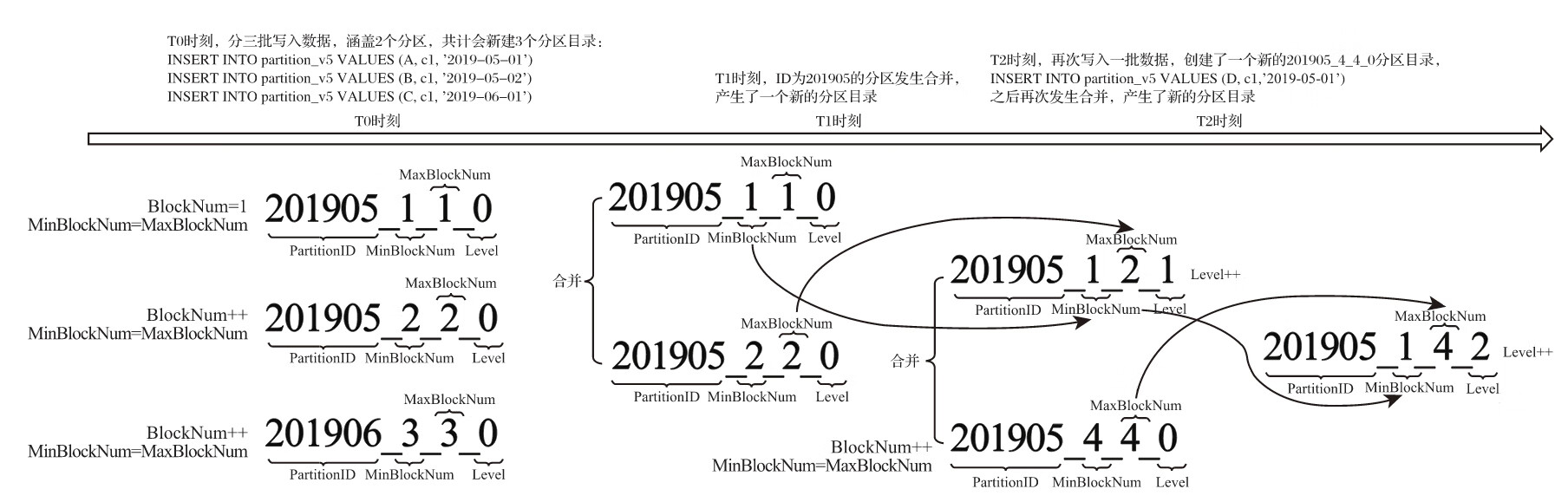
4.2.3 分区目录的合并过程
MergeTree完全不同,伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize TABLE table_name语句),ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认8分钟)。
属于同一个分区的多个目录,在合并之后会生成一个全新的目录,目录中的索引和数据文件也会相应地进行合并。新目录名称的合并方式遵循以下规则,其中:
- ·MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。
- ·MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。
- ·Level:取同一分区内最大Level值并加1。
4.3 一级索引
4.3.1 稀疏索引
primary.idx文件内的一级索引采用稀疏索引实现。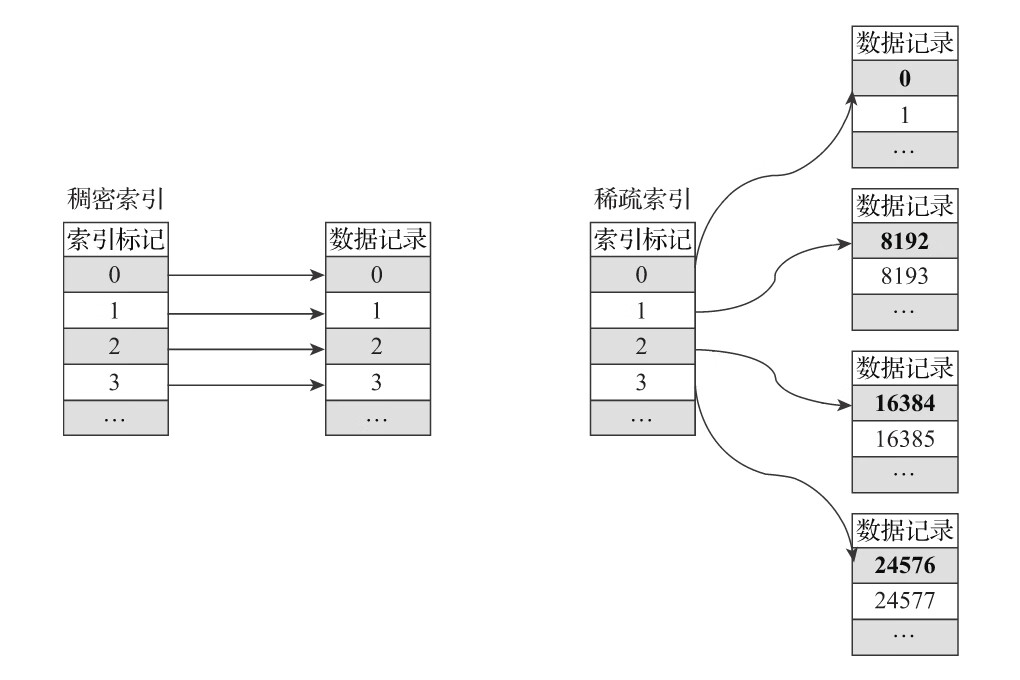
稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行
稀疏索引的优势是显而易见的,它仅需使用少量的索引标记就能够记录大量数据的区间位置信息,且数据量越大优势越为明显。以默认的索引粒度(8192)为例,MergeTree只需要12208行索引标记就能为1亿行数据记录提供索引。由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度自然极快。
4.3.2 索引粒度
MergeTree按照索引粒度
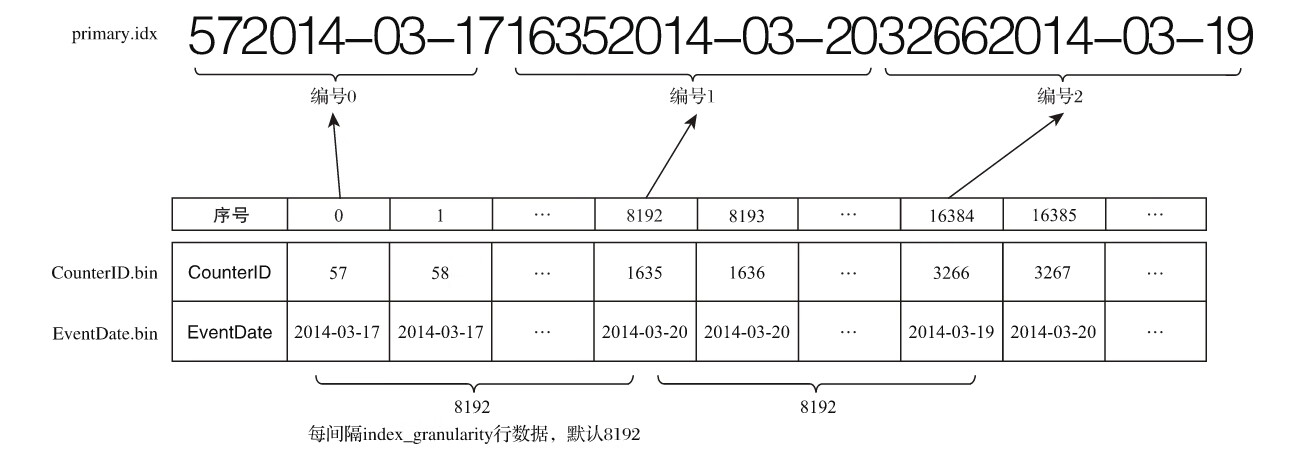
4.3.3 索引数据的生成规则
例如第0(81920)行CounterID取值57,第8192(81921)行CounterID取值1635,而第16384(8192*2)行CounterID取值3266,最终索引数据将会是5716353266。
如果使用多个主键,例如ORDER BY(CounterID,EventDate),则每间隔8192行可以同时取CounterID与EventDate两列的值作为索引值,具体如图6-9所示。
4.3.4 索引的查询过程
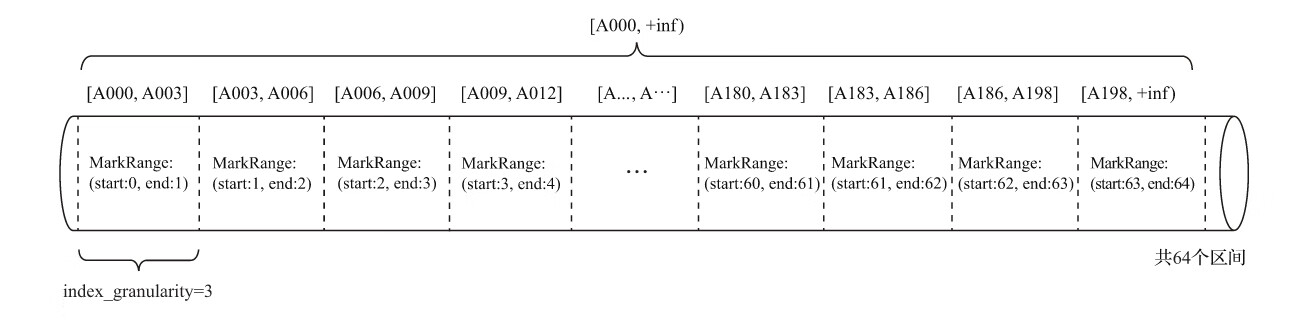
现在有一份测试数据,共192行记录。其中,主键ID为String类型,ID的取值从A000开始,后面依次为A001、A002……直至A192为止。MergeTree的索引粒度index_granularity=3,根据索引的生成规则,primary.idx文件内的索引数据。

根据索引数据,MergeTree会将此数据片段划分成192/3=64个小的MarkRange,两个相邻MarkRange相距的步长为1。其中,所有MarkRange(整个数据片段)的最大数值区间为[A000,+inf)。
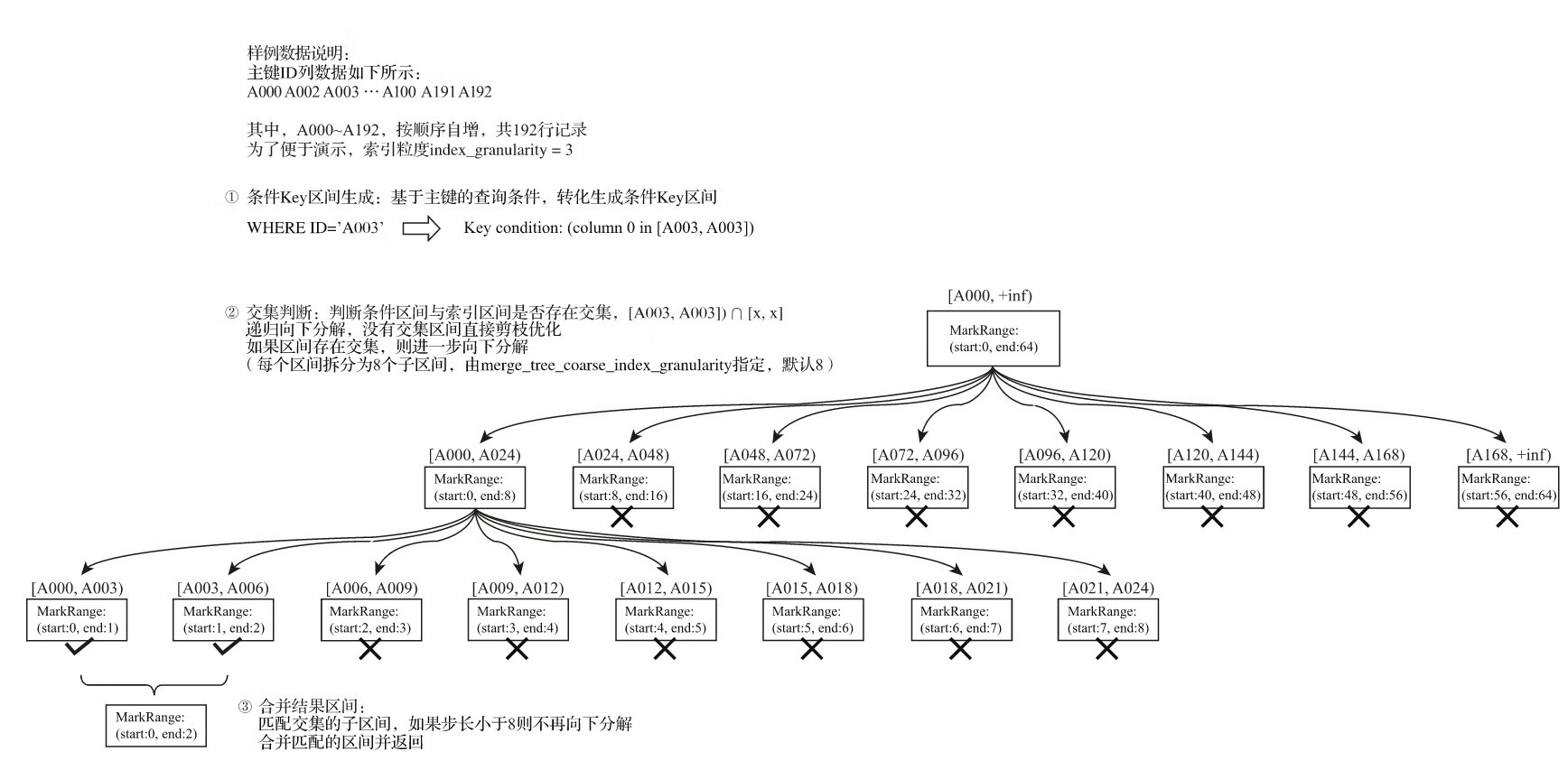
在引出了数值区间的概念之后,对于索引的查询过程就很好解释了。索引查询其实就是两个数值区间的交集判断。其中,一个区间是由基于主键的查询条件转换而来的条件区间;而另一个区间是刚才所讲述的与MarkRange对应的数值区间。
整个索引查询过程可以大致分为3个步骤。
(1)生成查询条件区间:首先,将查询条件转换为条件区间。即便是单个值的查询条件,也会被转换成区间的形式,例如下面的例子。
WHERE ID = 'A003'
['A003', 'A003']
WHERE ID > 'A000'
('A000', +inf)
WHERE ID < 'A188'
(-inf, 'A188')
WHERE ID LIKE 'A006%'
['A006', 'A007')
(2)递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最大的区间[A000,+inf)开始:
- ·如果不存在交集,数据不存在。
- ·如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间,并重复此规则,继续做递归交集判断。
- ·如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
(3)合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
4.4 二级索引
除了一级索引之外,MergeTree同样支持二级索引。二级索引又称跳数索引,由数据的聚合信息构建而成。根据索引类型的不同,其聚合信息的内容也不同。跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
SET allow_experimental_data_skipping_indices = 1 --跳数索引在默认情况下是关闭的,需要设置allow_experimental_data_skipping_indices才能使用:
跳数索引需要在CREATE语句内定义,它支持使用元组和表达式的形式声明,其完整的定义语法如下所示:
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity
与一级索引一样,如果在建表语句中声明了跳数索引,则会额外生成相应的索引与标记文件(skp_idx_[Column].idx与skp_idx_[Column].mrk)。
4.4.1 跳数索引的类型
目前,MergeTree共支持4种跳数索引,分别是minmax、set、ngrambf_v1和tokenbf_v1。一张数据表支持同时声明多个跳数索引,例如:
CREATE TABLE skip_test (
ID String,
URL String,
Code String,
EventTime Date,
INDEX a ID TYPE minmax GRANULARITY 5,
INDEX b(length(ID) * 8) TYPE set(2) GRANULARITY 5,
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5,
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
) ENGINE = MergeTree()
省略...
(1)minmax:minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录的minmax索引,能够快速跳过无用的数据区间,示例如下所示:
INDEX a ID TYPE minmax GRANULARITY 5 --上述示例中minmax索引会记录这段数据区间内ID字段的极值。极值的计算涉及每5个index_granularity区间中的数据。
(2)set:set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。如果max_rows=0,则表示无限制,例如:
INDEX b(length(ID) * 8) TYPE set(100) GRANULARITY 5 --set索引会记录数据中ID的长度*8后的取值。其中,每个index_granularity内最多记录100条。
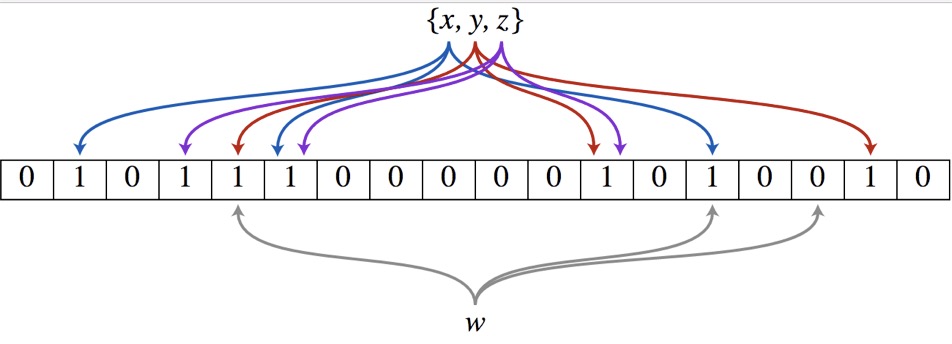
(3)ngrambf_v1:ngrambf_v1索引记录的是数据短语的布隆表过滤器,只支持String和FixedString数据类型。这些参数是一个布隆过滤器的标准输入,如果你接触过布隆过滤器,应该会对此十分熟悉。它们具体的含义如下:
- n:token长度,依据n的长度将数据切割为token短语。
- size_of_bloom_filter_in_bytes:布隆过滤器的大小。
- number_of_hash_functions:布隆过滤器中使用Hash函数的个数。
- random_seed:Hash函数的随机种子。
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5 --ngrambf_v1索引会依照3的粒度将数据切割成短语token,token会经过2个Hash函数映射后再被写入,布隆过滤器大小为256字节。
(4)tokenbf_v1:tokenbf_v1索引是ngrambf_v1的变种,同样也是一种布隆过滤器索引。tokenbf_v1去除了短语token的处理方法外,其他与ngrambf_v1是完全一样的。tokenbf_v1会自动按照非字符的、数字的字符串分割token,具体用法如下所示:
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
4.5 数据存储
4.5.1 各列独立存储
在MergeTree中,数据按列存储。而具体到每个列字段,数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件。也正是这些.bin文件,最终承载着数据的物理存储。数据文件以分区目录的形式被组织存放,所以在.bin文件中只会保存当前分区片段内的这一部分数据。按列独立存储的设计优势显而易见:一是可以更好地进行数据压缩(相同类型的数据放在一起,对压缩更加友好),二是能够最小化数据扫描的范围。
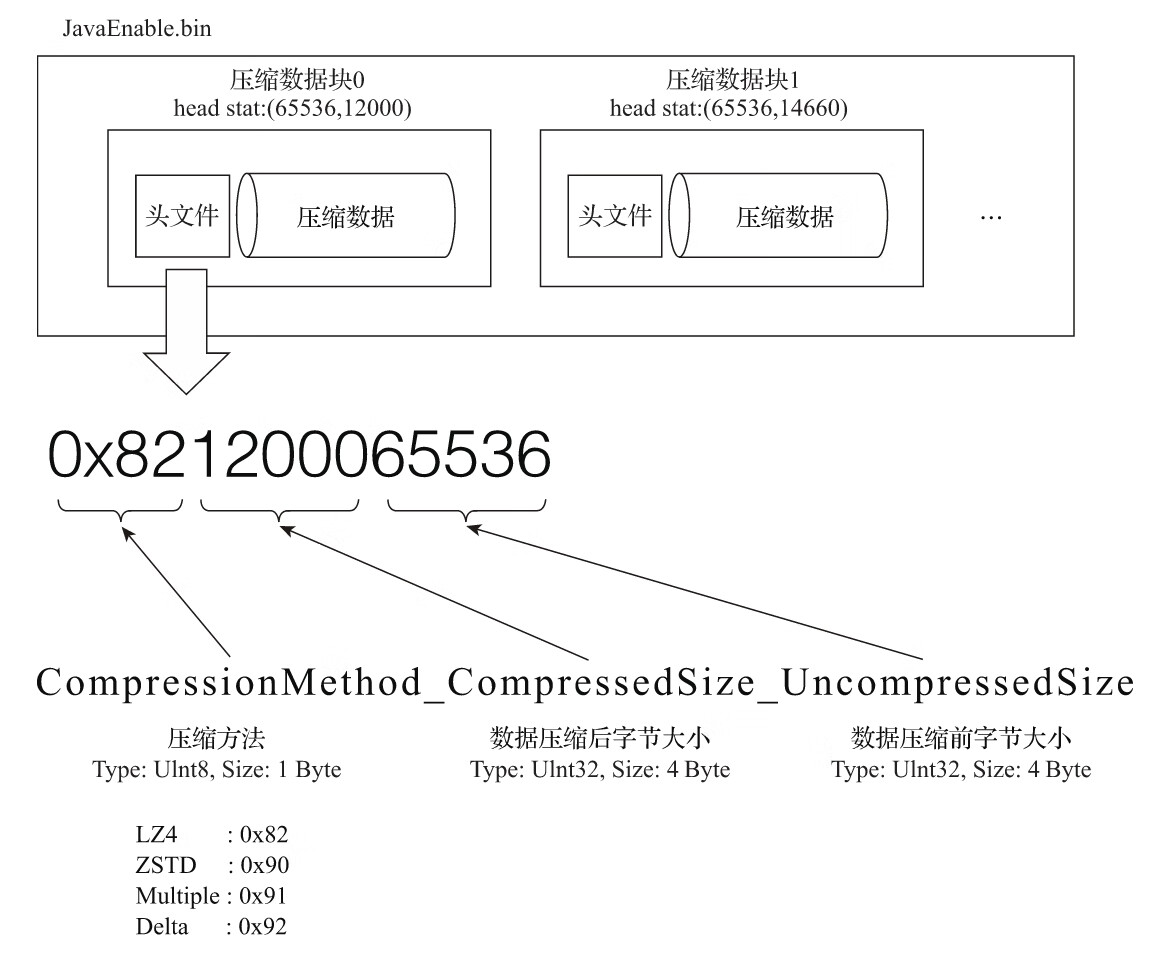
4.5.2 压缩数据块
一个压缩数据块由头信息和压缩数据两部分组成。头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小,具体如图6-14所示。
通过ClickHouse提供的clickhouse-compressor工具,能够查询某个.bin文件中压缩数据的统计信息
clickhouse-compressor --stat < /var/lib/clickhouse/data/cloud_joy_yun/cloud_friend/202007_1_1_0/cloud_id.bin
--执行后,会看到如下信息:
65536 12000
65536 14661
65536 4936
65536 7506
省略…
其中每一行数据代表着一个压缩数据块的头信息,其分别表示该压缩块中未压缩数据大小和压缩后数据大小。
每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB~1MB,其上下限分别由min_compress_block_size(默认65536)与max_compress_block_size(默认1048576)参数指定。而一个压缩数据块最终的大小,则和一个间隔(index_granularity)内数据的实际大小相关。
MergeTree在数据具体的写入过程中,会依照索引粒度(默认情况下,每次取8192行),按批次获取数据并进行处理。如果把一批数据的未压缩大小设为size,则整个写入过程遵循以下规则:
(1)单个批次数据size<64KB:如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size>=64KB时,生成下一个压缩数据块。
(2)单个批次数据64KB<=size<=1MB:如果单个批次数据大小恰好在64KB与1MB之间,则直接生成下一个压缩数据块。
(3)单个批次数据size>1MB:如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时,会出现一个批次数据生成多个压缩数据块的情况。
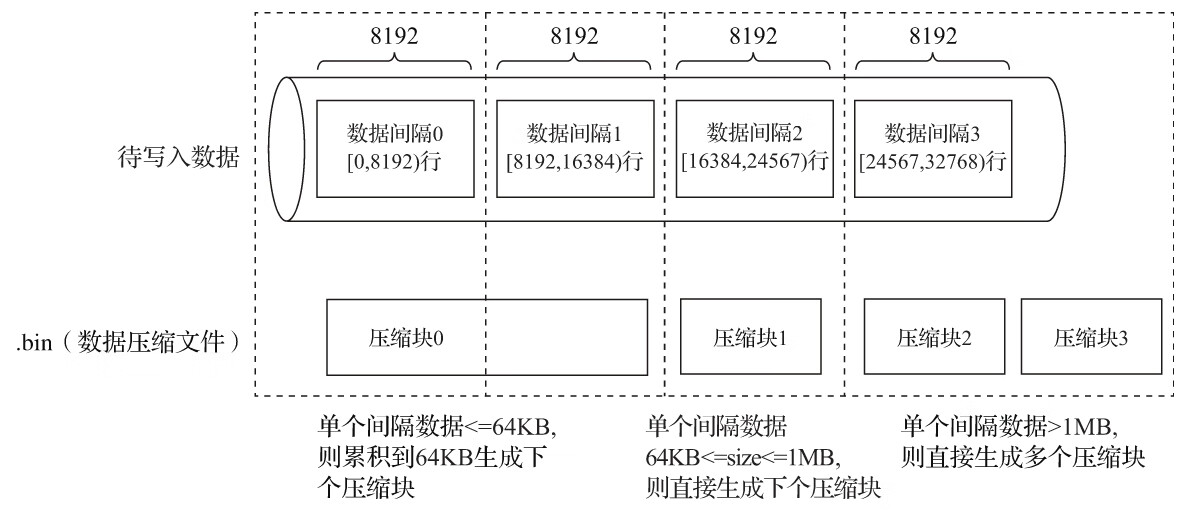
经过上述的介绍后我们知道,一个.bin文件是由1至多个压缩数据块组成的,每个压缩块大小在64KB~1MB之间。多个压缩数据块之间,按照写入顺序首尾相接,紧密地排列在一起。
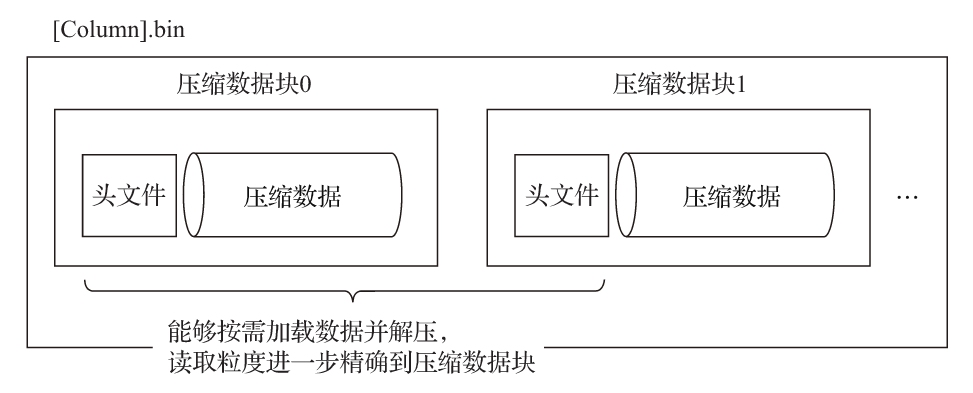
在.bin文件中引入压缩数据块的目的至少有以下两个:其一,虽然数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率。其二,通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取的范围。
4.6 数据标记
4.6.1 数据标记的生成规则
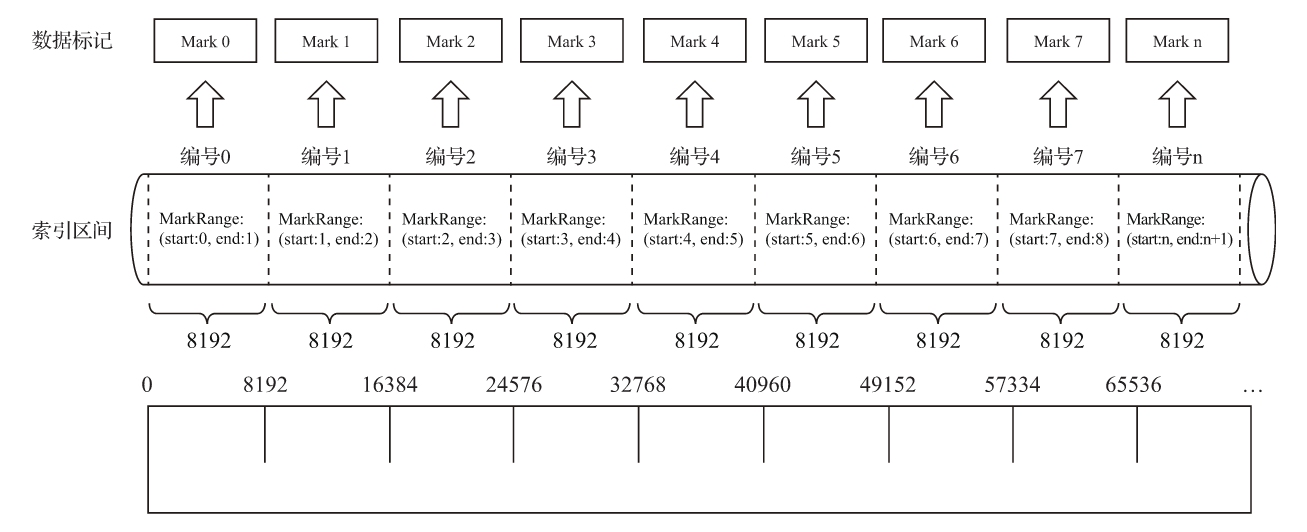
为了能够与数据衔接,数据标记文件也与.bin文件一一对应。即每一个列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息。
一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。它们分别表示在此段数据区间内,在对应的.bin压缩文件中,压缩数据块的起始偏移量;以及将该数据压缩块解压后,其未压缩数据的起始偏移量。.mrk文件内标记数据的示意。
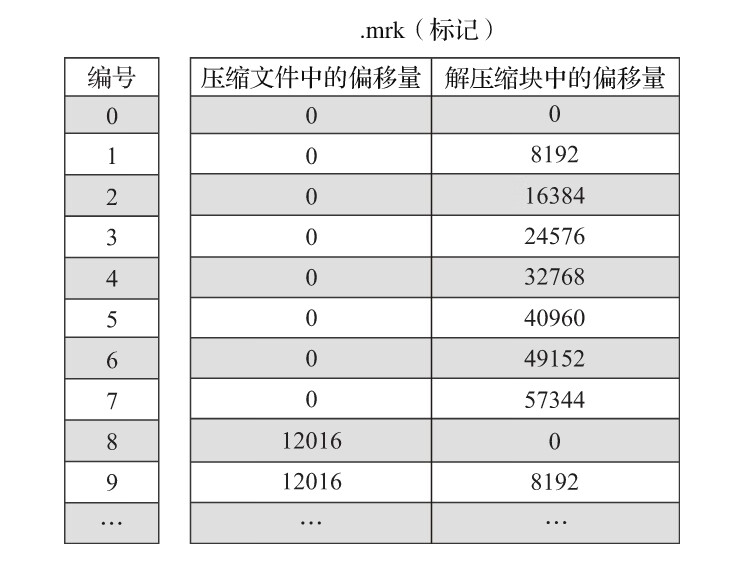
4.6.2 数据标记的工作方式
MergeTree在读取数据时,必须通过标记数据的位置信息才能够找到所需要的数据。整个查找过程大致可以分为读取压缩数据块和读取数据两个步骤。为了便于解释,这里继续使用测试表hits_v1中的真实数据进行说明。
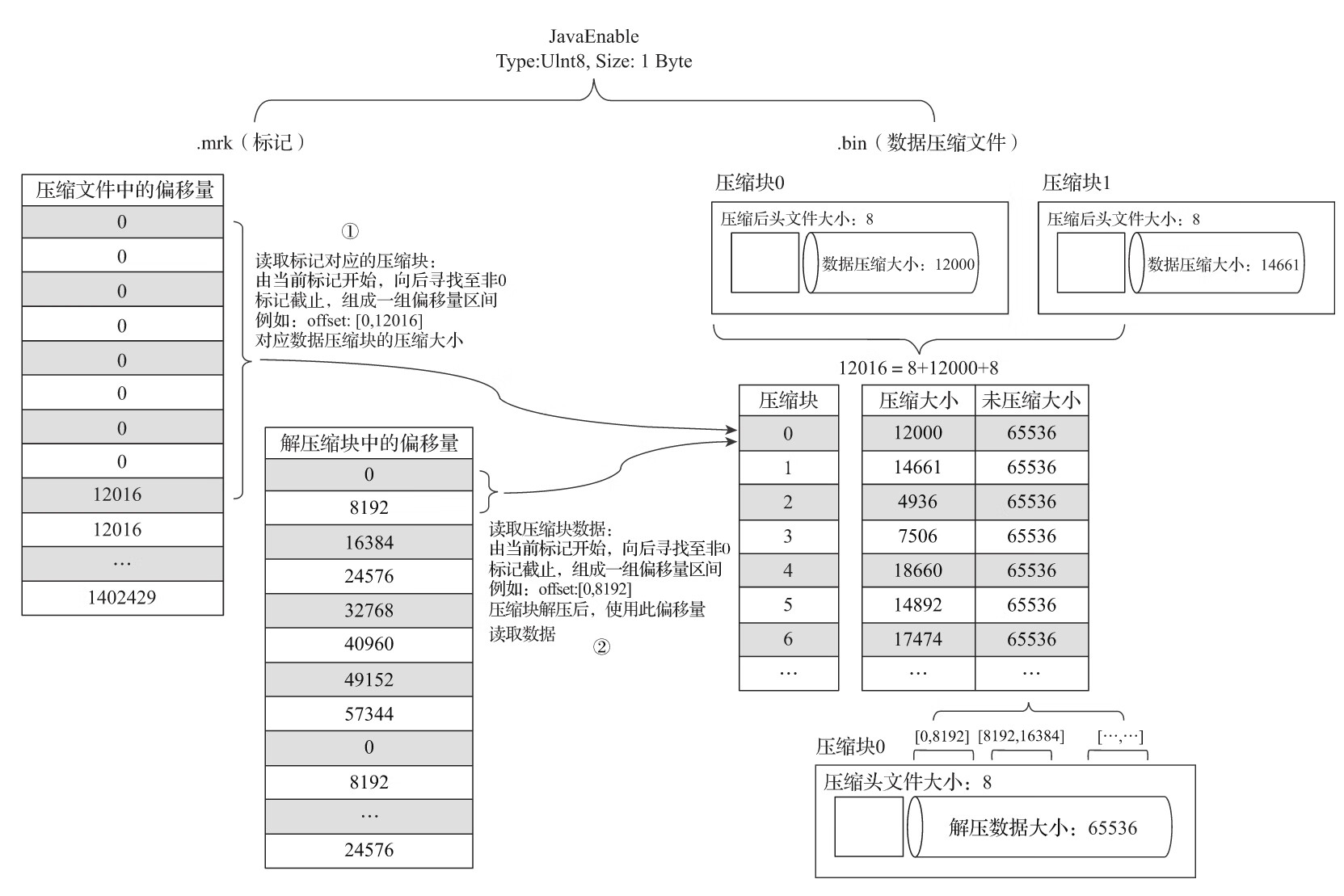
首先,左侧的标记数据做一番解释说明。JavaEnable字段的数据类型为UInt8,所以每行数值占用1字节。而hits_v1数据表的index_granularity粒度为8192,所以一个索引片段的数据大小恰好是8192B。压缩数据块的生成规则,如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size>=64KB时,生成下一个压缩数据块。因此在JavaEnable的标记文件中,每8行标记数据对应1个压缩数据块(1B*8192=8192B,64KB=65536B,65536/8192=8)。其左侧的标记数据中,8行数据的压缩文件偏移量都是相同的,因为这8行标记都指向了同一个压缩数据块。而在这8行的标记数据中,它们的解压缩数据块中的偏移量,则依次按照8192B(每行数据1B,每一个批次8192行数据)累加,当累加达到65536(64KB)时则置0。因为根据规则,此时会生成下一个压缩数据块。
理解了上述标记数据之后,接下来就开始介绍MergeTree具体是如何定位压缩数据块并读取数据的。
(1)读取压缩数据块:在查询某一列数据时,MergeTree无须一次性加载整个.bin文件,而是可以根据需要,只加载特定的压缩数据块。而这项特性需要借助标记文件中所保存的压缩文件中的偏移量。
(2)读取数据:在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据需要,以index_granularity的粒度加载特定的一小段。为了实现这项特性,需要借助标记文件中保存的解压数据块中的偏移量。
4.7 对于分区、索引、标记和压缩数据的协同总结
4.7.1 写入过程
数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录。在后续的某一时刻,属于相同分区的目录会依照规则合并到一起;接着,按照index_granularity索引粒度,会分别生成primary.idx一级索引(如果声明了二级索引,还会创建二级索引文件)、每一个列字段的.mrk数据标记和.bin压缩数据文件。
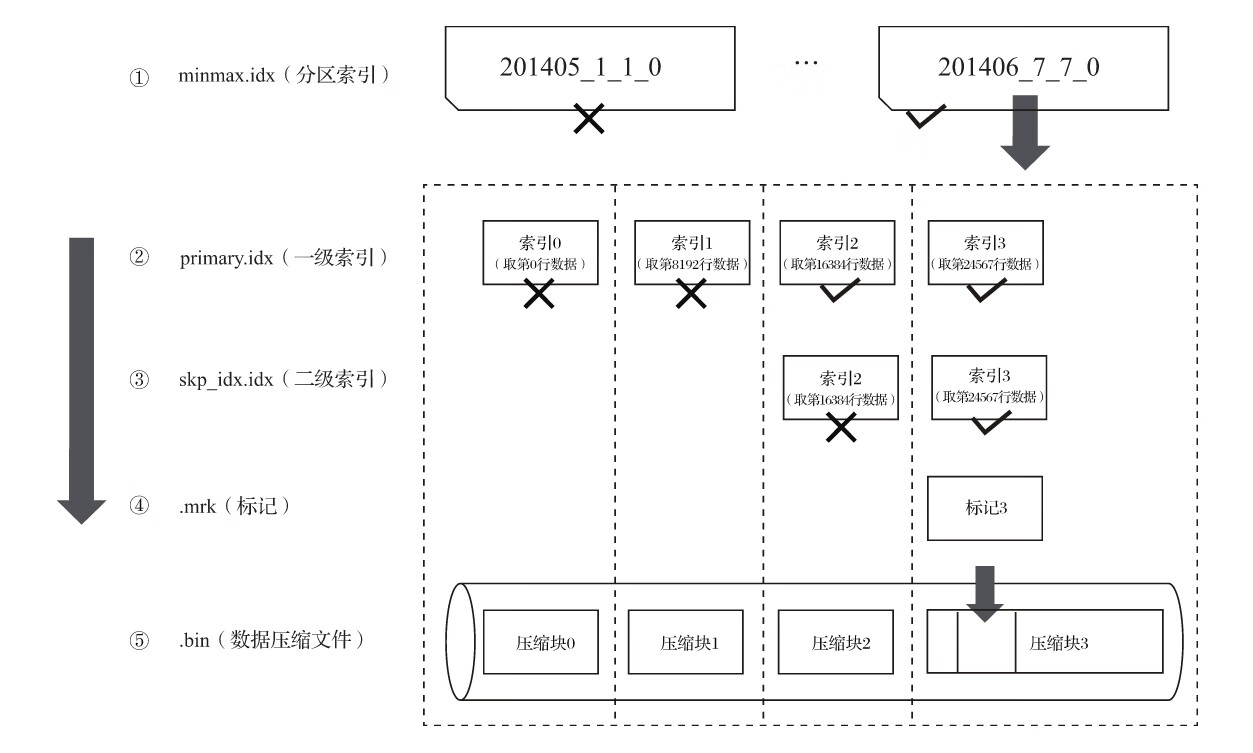
4.7.2 查询过程
数据查询的本质,可以看作一个不断减小数据范围的过程。在最理想的情况下,MergeTree首先可以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小
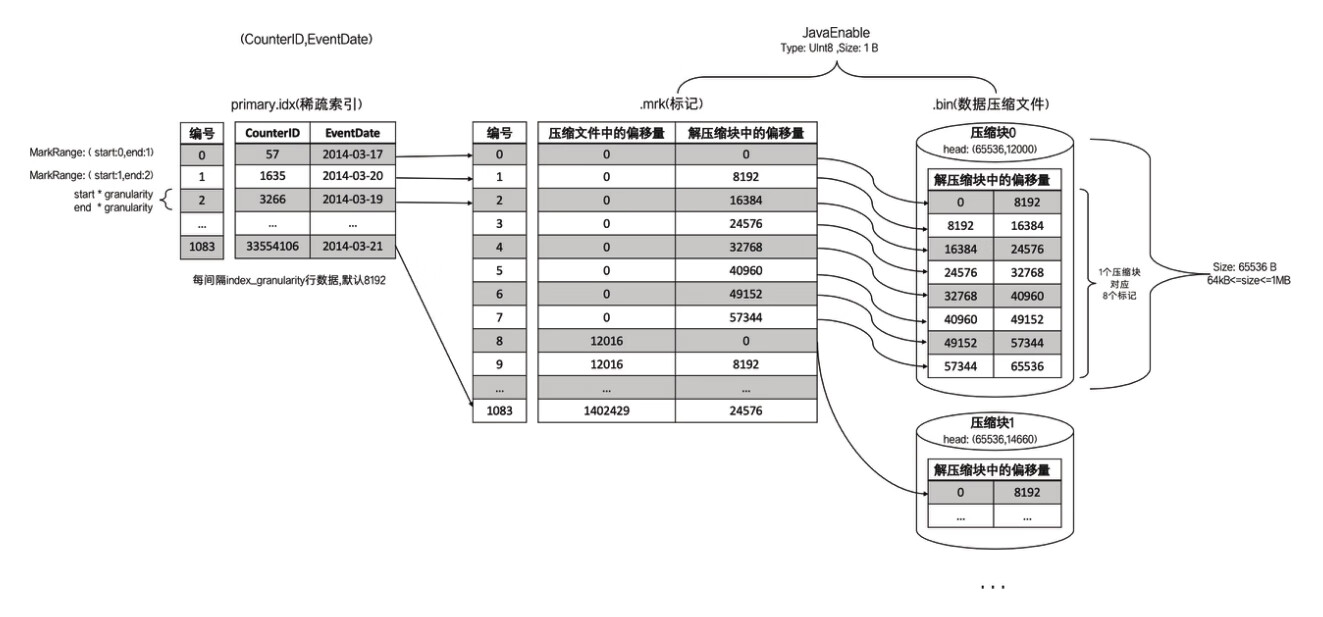
4.7.3 数据标记与压缩数据块的对应关系
1.多对一
多个数据标记对应一个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size小于64KB时,会出现这种对应关系。
以hits_v1测试表的JavaEnable字段为例。JavaEnable数据类型为UInt8,大小为1B,则一个间隔内数据大小为8192B。所以在此种情形下,每8个数据标记会对应同一个压缩数据块,如图6-22所示。
2.一对一
一个数据标记对应一个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size大于等于64KB且小于等于1MB时,会出现这种对应关系。
3.一对多
以hits_v1测试表的URL字段为例。URL数据类型为String,大小根据实际内容而定。如图6-24所示,编号45的标记对应了2个压缩数据块。
一个数据标记对应多个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size直接大于1MB时,会出现这种对应关系。
第5章 MergeTree系列表引擎
除了基础表引擎MergeTree之外,常用的表引擎还有ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree和VersionedCollapsingMergeTree。每一种合并树的变种,在继承了基础MergeTree的能力之后,又增加了独有的特性。其名称中的“合并”二字奠定了所有类型MergeTree的基因,它们的所有特殊逻辑,都是在触发合并的过程中被激活的。在本章后续的内容中,会逐一介绍它们的特点以及使用方法。
5.1 MergeTree
5.1.1 数据TTL
TTL即Time To Live,顾名思义,它表示数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的TTL,则会以先到期的那个为主。
1.列级别TTL
如果想要设置列级别的TTL,则需要在定义表字段的时候,为它们声明TTL表达式,主键字段不能被声明TTL。以下面的语句为例:
CREATE TABLE ttl_table_v1(
id String,
create_time DateTime,
code String TTL create_time + interval 10 SECOND,
type UInt8 TTL create_time + interval 10 SECOND
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
其中,create_time是日期类型,列字段code与type均被设置了TTL,它们的存活时间是在create_time的取值基础之上向后延续10秒。
INSERT INTO TABLE ttl_table_v1 VALUES('A000',now(),'C1',1),
('A000',now() + INTERVAL 10 MINUTE,'C1',1)
SELECT * FROM ttl_table_v1
┌─id───┬─────create_time──┬─code─┬─type─┐
│ A000 │ 2019-06-12 22:49:00 │ C1 │ 1 │
│ A000 │ 2019-06-12 22:59:00 │ C1 │ 1 │
└────┴───────────────┴────┴─────┘
optimize TABLE ttl_table_v1 FINAL --接着心中默数10秒,然后执行optimize命令强制触发TTL清理:
再次查询ttl_table_v1则能够看到,由于第一行数据满足TTL过期条件(当前系统时间>=create_time+10秒),它们的code和type列会被还原为数据类型的默认值:
┌─id───┬───────create_time─┬─code─┬─type─┐
│ A000 │ 2019-06-12 22:49:00 │ │ 0 │
│ A000 │ 2019-06-12 22:59:00 │ C1 │ 1 │
└─────┴───────────────┴─────┴─────┘
如果想要修改列字段的TTL,或是为已有字段添加TTL,则可以使用ALTER语句,示例如下:
ALTER TABLE ttl_table_v1 MODIFY COLUMN code String TTL create_time + INTERVAL 1 DAY
列级别TTL目前也没有取消的方法。
2.表级别TTL
如果想要为整张数据表设置TTL,需要在MergeTree的表参数中增加TTL表达式,例如下面的语句:
CREATE TABLE ttl_table_v2(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8
)ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
ttl_table_v2整张表被设置了TTL,当触发TTL清理时,那些满足过期时间的数据行将会被整行删除。同样,表级别的TTL也支持修改,修改的方法如下:
ALTER TABLE ttl_table_v2 MODIFY TTL create_time + INTERVAL 3 DAY
表级别TTL目前也没有取消的方法。
5.2 ReplacingMergeTree
在一定程度上解决了重复数据的问题
创建一张ReplacingMergeTree表的方法与创建普通MergeTree表无异,只需要替换Engine:
ENGINE = ReplacingMergeTree(ver)
其中,ver是选填参数,会指定一个UInt*、Date或者DateTime类型的字段作为版本号。这个参数决定了数据去重时所使用的算法。键ORDER BY所声明的表达式是后续作为判断数据是否重复的依据
CREATE TABLE replace_table(
id String,
code String,
create_time DateTime
)ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,code)
PRIMARY KEY id
┌─id───┬─code─┬───────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└─────┴─────┴───────────────┘
optimize TABLE replace_table FINAL --optimize强制触发合并后 ,保留分组内的最后一条
┌─id───┬─code─┬──────create_time─┐ --将其余重复的数据删除:
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└────┴────┴──────────────┘
INSERT INTO TABLE replace_table VALUES('A001','C1','2019-08-10 17:00:00')
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-08-22 17:00:00 │
└─────┴────┴─────────────────┘
┌─id──┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└────┴──────┴─────────────────┘
可以看到A001:C1依然出现了重复, 是因为ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。这就是上面说ReplacingMergeTree只是在一定程度上解决了重复数据问题的原因
现在接着说明ReplacingMergeTree版本号的用法。以下面的语句为例
CREATE TABLE replace_table_v(
id String,
code String,
create_time DateTime
)ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
┌─id──┬─code──┬───────────create_time─┐ --replace_table_v基于id字段去重,并且使用create_time字段作为版本号
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-25 17:00:00 │
│ A001 │ C1 │ 2019-05-13 17:00:00 │
└────┴─────┴───────────────────┘
┌─id────┬─code─┬──────────create_time─┐ --会保留同一组数据内create_time时间最长的那一行
│ A001 │ C1 │ 2019-05-25 17:00:00 │
└──────┴────┴──────────────────┘
- (1)使用ORBER BY排序键作为判断重复数据的唯一键。
- (2)只有在合并分区的时候才会触发删除重复数据的逻辑。
- (3)以数据分区为单位删除重复数据。当分区合并时,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
- (4)在进行数据去重时,因为分区内的数据已经基于ORBER BY进行了排序,所以能够找到那些相邻的重复数据。
- (5)数据去重策略有两种:
·如果没有设置ver版本号,则保留同一组重复数据中的最后一行。
·如果设置了ver版本号,则保留同一组重复数据中ver字段取值最大的那一行。
5.3 SummingMergeTree
假设有这样一种查询需求:终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的(GROUP BY条件明确,且不会随意改变)。
SummingMergeTree就是为了应对这类查询场景而生的。顾名思义,它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行,这样既减少了数据行,又降低了后续汇总查询的开销。
ENGINE = SummingMergeTree((col1,col2,…)) --ENGINE = SummingMergeTree((col1,col2,…))
其中,col1、col2为columns参数值,这是一个选填参数,用于设置除主键外的其他数值类型字段,以指定被SUM汇总的列字段。如若不填写此参数,则会将所有非主键的数值类型字段进行SUM汇总。接来下用一组示例说明它的使用方法:
CREATE TABLE summing_table(
id String,
city String,
v1 UInt32,
v2 Float64,
create_time DateTime
)ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, city)
PRIMARY KEY id
┌─id──┬─city───┬─v1─┬─v2─┬────────create_time─┐
│ A001 │ wuhan │ 10 │ 20 │ 2019-08-10 17:00:00 │
│ A001 │ wuhan │ 20 │ 30 │ 2019-08-20 17:00:00 │
│ A001 │ zhuhai │ 20 │ 30 │ 2019-08-10 17:00:00 │
└─────┴───────┴───┴───┴────────────────┘
┌─id──┬─city───┬─v1─┬─v2─┬────────create_time─┐
│ A001 │ wuhan │ 10 │ 20 │ 2019-02-10 09:00:00 │
└─────┴───────┴───┴───┴───────────────┘
┌─id──┬─city───┬─v1─┬─v2─┬────────create_time─┐
│ A002 │ wuhan │ 60 │ 50 │ 2019-10-10 17:00:00 │
└────┴──────┴───┴───┴───────────────┘
optimize TABLE summing_table FINAL --执行optimize强制进行触发和合并操作:
┌─id──┬─city───┬─v1─┬─v2─┬─────────create_time─┐
│ A001 │ wuhan │ 30 │ 50 │ 2019-08-10 17:00:00 │
│ A001 │ zhuhai │ 20 │ 30 │ 2019-08-10 17:00:00 │
└─────┴──────┴────┴────┴─────────────────┘
┌─id──┬─city───┬─v1─┬─v2─┬─────────create_time─┐
│ A001 │ wuhan │ 10 │ 20 │ 2019-02-10 09:00:00 │
└────┴──────┴────┴────┴─────────────────┘
┌─id──┬─city───┬─v1─┬─v2─┬─────────create_time─┐
│ A002 │ wuhan │ 60 │ 50 │ 2019-10-10 17:00:00 │
└────┴──────┴────┴────┴─────────────────┘
至此能够看到,在第一个分区内,同为A001:wuhan的两条数据汇总成了一行。其中,v1和v2被SUM汇总,不在汇总字段之列的create_time则选取了同组内第一行数据的取值。而不同分区之间,数据没有被汇总合并
- (1)用ORBER BY排序键作为聚合数据的条件Key。
- (2)只有在合并分区的时候才会触发汇总的逻辑。
- (3)以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。
- (4)如果在定义引擎时指定了columns汇总列(非主键的数值类型字段),则SUM汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段。
- (5)在进行数据汇总时,因为分区内的数据已经基于ORBER BY排序,所以能够找到相邻且拥有相同聚合Key的数据。
- (6)在汇总数据时,同一分区内,相同聚合Key的多行数据会合并成一行。其中,汇总字段会进行SUM计算;对于那些非汇总字段,则会使用第一行数据的取值。
5.4 CollapsingMergeTree
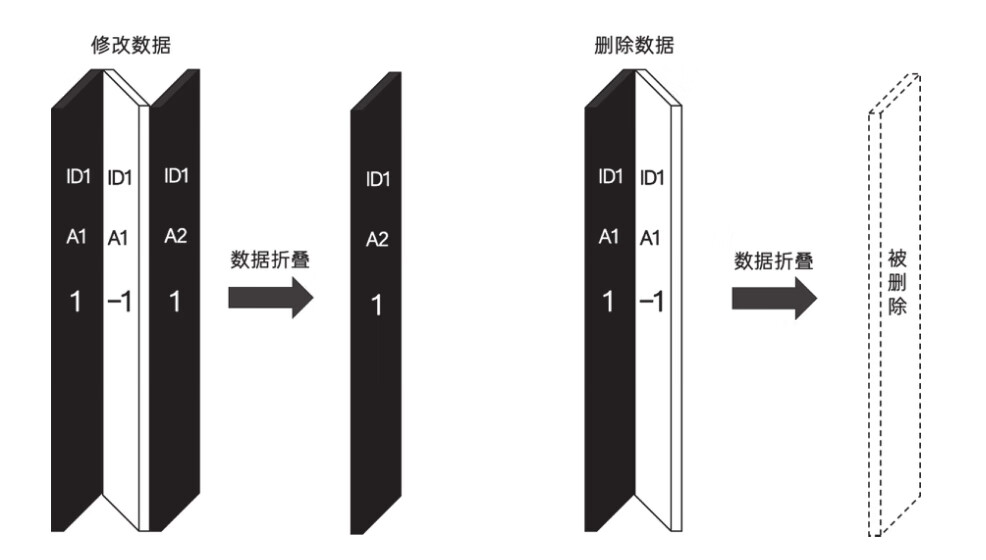
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。这种1和-1相互抵消的操作,犹如将一张瓦楞纸折叠了一般。这种直观的比喻,想必也正是折叠合并树(CollapsingMergeTree)名称的由来
声明CollapsingMergeTree的方式如下:
ENGINE = CollapsingMergeTree(sign)
其中,sign用于指定一个Int8类型的标志位字段。一个完整的使用示例如下所示:
CREATE TABLE collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8
)ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
与其他的MergeTree变种引擎一样,CollapsingMergeTree同样是以ORDER BY排序键作为后续判断数据唯一性的依据。按照之前的介绍,对于上述collpase_table数据表而言,除了常规的新增数据操作之外,还能够支持两种操作。
其一,修改一行数据:
--修改前的源数据, 它需要被修改
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1)
--镜像数据, ORDER BY字段与源数据相同(其他字段可以不同),sign取反为-1,它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1)
--修改后的数据 ,sign为1
INSERT INTO TABLE collpase_table VALUES('A000',120,'2019-02-20 00:00:00',1)
其二,删除一行数据:
--修改前的源数据, 它需要被删除
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1)
--镜像数据, ORDER BY字段与源数据相同, sign取反为-1, 它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1)
CollapsingMergeTree在折叠数据时,遵循以下规则。
- ·如果sign=1比sign=-1的数据多一行,则保留最后一行sign=1的数据。
- ·如果sign=-1比sign=1的数据多一行,则保留第一行sign=-1的数据。
- ·如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
- ·如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=-1,则什么也不保留。
在使用CollapsingMergeTree的时候,还有几点需要注意。
(1)折叠数据并不是实时触发的,和所有其他的MergeTree变种表引擎一样,这项特性也只有在分区合并的时候才会体现。所以在分区合并之前,用户还是会看到旧的数据。解决这个问题的方式有两种。
-
·在查询数据之前,使用optimize TABLE table_name FINAL命令强制分区合并,但是这种方法效率极低,在实际生产环境中慎用。
-
·需要改变我们的查询方式。以collpase_table举例,如果原始的SQL如下所示:
SELECT id,SUM(code * sign),COUNT(code * sign),AVG(code * sign),uniq(code * sign) FROM collpase_table GROUP BY id HAVING SUM(sign) > 0
--先写入sign=1 先写入sign=1,再写入sign=-1,则能够正常折叠:
INSERT INTO TABLE collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1)
--再写入sign=-1
INSERT INTO TABLE collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1)
--先写入sign=-1 先写入sign=-1,再写入sign=1,则不能够折叠:
INSERT INTO TABLE collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1)
--再写入sign=1
INSERT INTO TABLE collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1)
5.5 VersionedCollapsingMergeTree
VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作
在定义VersionedCollapsingMergeTree的时候,除了需要指定sign标记字段以外,还需要指定一个UInt8类型的ver版本号字段:
ENGINE = VersionedCollapsingMergeTree(sign,ver)
CREATE TABLE ver_collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8,
ver UInt8
)ENGINE = VersionedCollapsingMergeTree(sign,ver)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
VersionedCollapsingMergeTree是如何使用版本号字段的呢?其实很简单,在定义ver字段之后,VersionedCollapsingMergeTree会自动将ver作为排序条件并增加到ORDER BY的末端。以上面的ver_collpase_table表为例,在每个数据分区内,数据会按照ORDER BY id,ver DESC排序。所以无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。
第6章 其他常见类型表引擎
6.1 外部存储类型
6.1.1 HDFS
首先需要关闭HDFS的Kerberos认证(因为HDFS表引擎目前还不支持Kerberos);接着在HDFS上创建用于存放文件的目录:
hadoop fs -mkdir /clickhouse
最后,在HDFS上给ClickHouse用户授权。例如,为默认用户clickhouse授权的方法如下:
hadoop fs -chown -R clickhouse:clickhouse /clickhouse
HDFS表引擎的定义方法如下:
ENGINE = HDFS(hdfs_uri,format)
- ·hdfs_uri表示HDFS的文件存储路径;
- ·format表示文件格式(指ClickHouse支持的文件格式,常见的有CSV、TSV和JSON等)。
CREATE TABLE hdfs_table1(
id UInt32,
code String,
name String
)ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table1','CSV')
INSERT INTO hdfs_table1 SELECT number,concat('code',toString(number)),
concat('n',toString(number)) FROM numbers(5)
SELECT * FROM hdfs_table1
┌─id─┬─code─┬─name─┐
│ 0 │ code0 │ n0 │
│ 1 │ code1 │ n1 │
│ 2 │ code2 │ n2 │
│ 3 │ code3 │ n3 │
│ 4 │ code4 │ n4 │
└───┴─────┴────┘
接着再看看在HDFS上发生了什么变化。执行hadoop fs -cat查看文件:
$ hadoop fs -cat /clickhouse/hdfs_table1
0,"code0","n0"
1,"code1","n1"
2,"code2","n2"
3,"code3","n3"
4,"code4","n4"
可以发现,通过HDFS表引擎,ClickHouse在HDFS的指定目录下创建了一个名为hdfs_table1的文件,并且按照CSV格式写入了数据。不过目前ClickHouse并没有提供删除HDFS文件的方法,即便将数据表hdfs_table1删除:
DROP Table hdfs_table1
在HDFS上文件依然存在:
$ hadoop fs -ls /clickhouse
Found 1 items
-rwxrwxrwx 3 clickhouse clickhouse /clickhouse/hdfs_table1
接下来,介绍第二种形式的使用方法,这种形式类似Hive的外挂表,由其他系统直接将文件写入HDFS。通过HDFS表引擎的hdfs_uri和format参数分别与HDFS的文件路径、文件格式建立映射。其中,hdfs_uri支持以下几种常见的配置方法:
- ·绝对路径:会读取指定路径的单个文件,例如/clickhouse/hdfs_table1。
- ·通配符:匹配所有字符,例如路径为/clickhouse/hdfs_table/,则会读取/click-house/hdfs_table路径下的所有文件。
- ·?通配符:匹配单个字符,例如路径为/clickhouse/hdfs_table/organization_?.csv,则会读取/clickhouse/hdfs_table路径下与organization_?.csv匹配的文件,其中?代表任意一个合法字符。
- ·{M..N}数字区间:匹配指定数字的文件,例如路径为/clickhouse/hdfs_table/organization_{1..3}.csv,则会读取/clickhouse/hdfs_table/路径下的文件organization_1.csv、organization_2.csv和organization_3.csv。
现在用一个具体示例验证表引擎的效果。首先,将事先准备好的3个CSV测试文件上传至HDFS的/clickhouse/hdfs_table2路径(用于测试的CSV文件,可以在本书的github仓库获取):
--上传文件至HDFS
$ hadoop fs -put /chbase/demo-data/ /clickhouse/hdfs_table2
--查询路径
$ hadoop fs -ls /clickhouse/hdfs_table2
Found 3 items
-rw-r--r-- 3 hdfs clickhouse /clickhouse/hdfs_table2/organization_1.csv
-rw-r--r-- 3 hdfs clickhouse /clickhouse/hdfs_table2/organization_2.csv
-rw-r--r-- 3 hdfs clickhouse /clickhouse/hdfs_table2/organization_3.csv
接着,创建HDFS测试表:
CREATE TABLE hdfs_table2(
id UInt32,
code String,
name String
) ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV')
HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV') --*通配符:
HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_?.csv','CSV') --?通配符:
HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_{1..3}.csv','CSV') --{M..N}数字区间:
6.1.2 MySQL
MySQL表引擎可以与MySQL数据库中的数据表建立映射,并通过SQL向其发起远程查询,包括SELECT和INSERT,它的声明方式如下:
ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause'])
其中各参数的含义分别如下:
- ·host:port表示MySQL的地址和端口。
- ·database表示数据库的名称。
- ·table表示需要映射的表名称。
- ·user表示MySQL的用户名。
- ·password表示MySQL的密码。
- ·replace_query默认为0,对应MySQL的REPLACE INTO语法。如果将它设置为1,则会用REPLACE INTO代替INSERT INTO。
- ·on_duplicate_clause默认为0,对应MySQL的ON DUPLICATE KEY语法。如果需要使用该设置,则必须将replace_query设置成0。
现在用一个具体的示例说明MySQL表引擎的用法。假设MySQL数据库已准备就绪,则使用MySQL表引擎与其建立映射:
CREATE TABLE dolphin_scheduler_table(
id UInt32,
name String
)ENGINE = MySQL('10.37.129.2:3306', 'escheduler', 't_escheduler_process_definition', 'root', '')
创建成功之后,就可以通过这张数据表代为查询MySQL中的数据了,例如:
SELECT * FROM dolphin_scheduler_table
┌─id─┬─name───┐
│ 1 │ 流程1 │
│ 2 │ 流程2 │
│ 3 │ 流程3 │
└──┴────────┘
INSERT INTO TABLE dolphin_scheduler_table VALUES (4,'流程4') --接着,尝试写入数据:
不过比较遗憾的是,目前MySQL表引擎不支持任何UPDATE和DELETE操作,如果有数据更新方面的诉求,可以考虑使用CollapsingMergeTree作为视图的表引擎。
6.1.4 Kafka
Kafka是大数据领域非常流行的一款分布式消息系统。Kafka表引擎能够直接与Kafka系统对接,进而订阅Kafka中的主题并实时接收消息数据。
Kafka表引擎的声明方式如下所示:
ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port,... ',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol']
[kafka_schema = '']
[kafka_num_consumers = N]
[kafka_skip_broken_messages = N]
[kafka_commit_every_batch = N]
其中,带有方括号的参数表示选填项,现在依次介绍这些参数的作用。首先是必填参数:
- ·kafka_broker_list:表示Broker服务的地址列表,多个地址之间使用逗号分隔,例如'hdp1.nauu.com:6667,hdp2.nauu.com:6667'。
- ·kafka_topic_list:表示订阅消息主题的名称列表,多个主题之间使用逗号分隔,例如'topic1,topic2'。多个主题中的数据均会被消费。
- ·kafka_group_name:表示消费组的名称,表引擎会依据此名称创建Kafka的消费组。
- ·kafka_format:表示用于解析消息的数据格式,在消息的发送端,必须按照此格式发送消息。数据格式必须是ClickHouse提供的格式之一,例如TSV、JSONEachRow和CSV等。
- ·kafka_row_delimiter:表示判定一行数据的结束符,默认值为'\0'。
- ·kafka_schema:对应Kafka的schema参数。
- ·kafka_num_consumers:表示消费者的数量,默认值为1。表引擎会依据此参数在消费组中开启相应数量的消费者线程。在Kafka的主题中,一个Partition分区只能使用一个消费者。
- ·kafka_skip_broken_messages:当表引擎按照预定格式解析数据出现错误时,允许跳过失败的数据行数,默认值为0,即不允许任何格式错误的情形发生。在此种情形下,只要Kafka主题中存在无法解析的数据,数据表都将不会接收任何数据。如果将其设置为非0正整数,例如kafka_skip_broken_messages=10,表示只要Kafka主题中存在无法解析的数据的总数小于10,数据表就能正常接收消息数据,而解析错误的数据会被自动跳过。
- ·kafka_commit_every_batch:表示执行Kafka commit的频率,默认值为0,即当一整个Block数据块完全写入数据表后才执行Kafka commit。如果将其设置为1,则每写完一个Batch批次的数据就会执行一次Kafka commit(一次Block写入操作,由多次Batch写入操作组成)。
除此之外,还有一些配置参数可以调整表引擎的行为。在默认情况下,Kafka表引擎每间隔500毫秒会拉取一次数据,时间由stream_poll_timeout_ms参数控制(默认500毫秒)。数据首先会被放入缓存,在时机成熟的时候,缓存数据会被刷新到数据表。
触发Kafka表引擎刷新缓存的条件有两个,当满足其中的任意一个时,便会触发刷新动作:
- ·当一个数据块完成写入的时候(一个数据块的大小由kafka_max_block_size参数控制,默认情况下kafka_max_block_size=max_block_size=65536)。
- ·等待间隔超过7500毫秒,由stream_flush_interval_ms参数控制(默认7500 ms)。
6.1.5 File
File表引擎的声明方式如下所示:
ENGINE = File(format)
其中,format表示文件中的数据格式,其类型必须是ClickHouse支持的数据格式,例如TSV、CSV和JSONEachRow等。可以发现,在File表引擎的定义参数中,并没有包含文件路径这一项。所以,File表引擎的数据文件只能保存在config.xml配置中由path指定的路径下。
每张File数据表均由目录和文件组成,其中目录以表的名称命名,而数据文件则固定以data.format命名,例如:
<ch-path>/data/default/test_file_table/data.CSV
创建File表目录和文件的方式有自动和手动两种。首先介绍自动创建的方式,即由File表引擎全权负责表目录和数据文件的创建:
CREATE TABLE file_table (
name String,
value UInt32
) ENGINE = File("CSV")
当执行完上面的语句后,在
INSERT INTO file_table VALUES ('one', 1), ('two', 2), ('three', 3)
在数据写入之后,file_table目录下便会生成一个名为data.CSV的数据文件:
# pwd
/chbase/data/default/file_table
# cat ./data.CSV
"one",1
"two",2
"three",3
接下来介绍手动创建的形式,即表目录和数据文件由ClickHouse之外的其他系统创建,例如使用shell创建:
//切换到clickhouse用户,以确保ClickHouse有权限读取目录和文件
# su clickhouse
//创建表目录
# mkdir /chbase/data/default/file_table1
//创建数据文件
# mv /chbase/data/default/file_table/data.CSV /chbase/data/default/file_table1
在表目录和数据文件准备妥当之后,挂载这张数据表:
ATTACH TABLE file_table1(
name String,
value UInt32
)ENGINE = File(CSV)
查询file_table1内的数据:
SELECT * FROM file_table1
┌─name──┬─value─┐
│ one │ 1 │
│ two │ 2 │
│ three │ 3 │
└─────┴─────┘
INSERT INTO file_table1 VALUES ('four', 4), ('five', 5) --即便是手动创建的表目录和数据文件,仍然可以对数据表插入数据,例如:
6.2 内存类型
6.2.1 Memory
Memory表的创建方法如下所示:
CREATE TABLE memory_1 (
id UInt64
)ENGINE = Memory()
6.2.2 Set
Set表引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中。所以当服务重启时,它的数据不会丢失,当数据表被重新装载时,文件数据会再次被全量加载至内存。众所周知,在Set数据结构中,所有元素都是唯一的。Set表引擎具有去重的能力,在数据写入的过程中,重复的数据会被自动忽略。然而Set表引擎的使用场景既特殊又有限,它虽然支持正常的INSERT写入,但并不能直接使用SELECT对其进行查询,Set表引擎只能间接作为IN查询的右侧条件被查询使用。
CREATE TABLE set_1 (
id UInt8
)ENGINE = Set()
6.2.3 Join
Join表引擎可以说是为JOIN查询而生的,它等同于将JOIN查询进行了一层简单封装。在Join表引擎的底层实现中,它与Set表引擎共用了大部分的处理逻辑,所以Join和Set表引擎拥有许多相似之处。例如,Join表引擎的存储也由[num].bin数据文件和tmp临时目录两部分组成;数据首先会被写至内存,然后被同步到磁盘文件。但是相比Set表引擎,Join表引擎有着更加广泛的应用场景,它既能够作为JOIN查询的连接表,也能够被直接查询使用。
ENGINE = Join(join_strictness, join_type, key1[, key2, ...])
其中,各参数的含义分别如下:
- ·join_strictness:连接精度,它决定了JOIN查询在连接数据时所使用的策略,目前支持ALL、ANY和ASOF三种类型。
- ·join_type:连接类型,它决定了JOIN查询组合左右两个数据集合的策略,它们所形成的结果是交集、并集、笛卡儿积或其他形式,目前支持INNER、OUTER和CROSS三种类型。当join_type被设置为ANY时,在数据写入时,join_key重复的数据会被自动忽略。
- ·join_key:连接键,它决定了使用哪个列字段进行关联。
6.2.4 Buffer
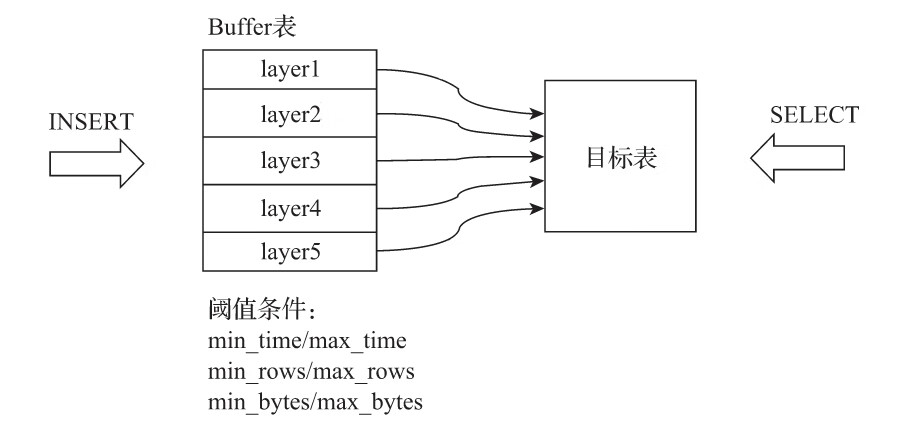
Buffer表引擎完全使用内存装载数据,不支持文件的持久化存储,所以当服务重启之后,表内的数据会被清空。Buffer表引擎不是为了面向查询场景而设计的,它的作用是充当缓冲区的角色。假设有这样一种场景,我们需要将数据写入目标MergeTree表A,由于写入的并发数很高,这可能会导致MergeTree表A的合并速度慢于写入速度(因为每一次INSERT都会生成一个新的分区目录)。此时,可以引入Buffer表来缓解这类问题,将Buffer表作为数据写入的缓冲区。数据首先被写入Buffer表,当满足预设条件时,Buffer表会自动将数据刷新到目标表。
Buffer表引擎的声明方式如下所示:
ENGINE = Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)
其中,参数可以分成基础参数和条件参数两类,首先说明基础参数的作用:
- database:目标表的数据库。
- ·table:目标表的名称,Buffer表内的数据会自动刷新到目标表。
- ·num_layers:可以理解成线程数,Buffer表会按照num_layers的数量开启线程,以并行的方式将数据刷新到目标表,官方建议设为16。
- ·min_time和max_time:时间条件的最小和最大值,单位为秒,从第一次向表内写入数据的时候开始计算;
- 假设一张Buffer表的max_bytes=100000000(约100 MB),num_layers=16,那么这张Buffer表能够同时处理的最大数据量约是1.6 GB。
6.3 接口类型
有这么一类表引擎,它们自身并不存储任何数据,而是像黏合剂一样可以整合其他的数据表。在使用这类表引擎的时候,不用担心底层的复杂性,它们就像接口一样,为用户提供了统一的访问界面,所以我将它们归为接口类表引擎。
6.3.1 Merge
Merge表引擎就如同一层使用了门面模式的代理,它本身不存储任何数据,也不支持数据写入。它的作用就如其名,即负责合并多个查询的结果集。Merge表引擎可以代理查询任意数量的数据表,这些查询会异步且并行执行,并最终合成一个结果集返回。
ENGINE = Merge(database, table_name) --其中:database表示数据库名称;table_name表示数据表的名称,它支持使用正则表达式,例如^test表示合并查询所有以test为前缀的数据表。
CREATE TABLE test_table_all as test_table_2018
ENGINE = Merge(currentDatabase(), '^test_table_')
6.3.2 Dictionary
Dictionary表引擎是数据字典的一层代理封装,它可以取代字典函数,让用户通过数据表查询字典。字典内的数据被加载后,会全部保存到内存中,所以使用Dictionary表对字典性能不会有任何影响。声明Dictionary表的方式如下所示:
ENGINE = Dictionary(dict_name)
CREATE TABLE tb_test_flat_dict ( --其中,dict_name对应一个已被加载的字典名称,例如下面的例子:
id UInt64,
code String,
name String
)Engine = Dictionary(test_flat_dict);
SELECT * FROM tb_test_flat_dict --tb_test_flat_dict等同于数据字典test_flat_dict的代理表,现在对它使用SELECT语句进行查询:
┌─id─┬─code──┬─name─┐
│ 1 │ a0001 │ 研发部 │
│ 2 │ a0002 │ 产品部 │
│ 3 │ a0003 │ 数据部 │
│ 4 │ a0004 │ 测试部 │
└───┴─────┴────┘
第7章 副本与分片
10.4 数据分片
10.4.1 集群的配置方式
1.不包含副本的分片
如果直接使用node标签定义分片节点,那么该集群将只包含分片,不包含副本。以下面的配置为例:
<yandex>
<!--自定义配置名,与config.xml配置的incl属性对应即可 -->
<clickhouse_remote_servers>
<shard_2><!--自定义集群名称-->
<node><!--定义ClickHouse节点-->
<host>ch5.nauu.com</host>
<port>9000</port>
<!--选填参数
<weight>1</weight>
<user></user>
<password></password>
<secure></secure>
<compression></compression>
-->
</node>
<node>
<host>ch6.nauu.com</host>
<port>9000</port>
</node>
</shard_2>
……
</clickhouse_remote_servers>
该配置定义了一个名为shard_2的集群,其包含了2个分片节点,它们分别指向了是CH5和CH6服务器。现在分别对配置项进行说明:
- ·shard_2表示自定义的集群名称,全局唯一,是后续引用集群配置的唯一标识。在一个配置文件内,可以定义任意组集群。
- ·node用于定义分片节点,不包含副本。
- ·host指定部署了ClickHouse节点的服务器地址。
- ·port指定ClickHouse服务的TCP端口。
- ·weight分片权重默认为1,在后续小节中会对其详细介绍。
- ·user为ClickHouse用户,默认为default。
- ·password为ClickHouse的用户密码,默认为空字符串。
- ·secure为SSL连接的端口,默认为9440。
- ·compression表示是否开启数据压缩功能,默认为true。
2.自定义分片与副本
1)不包含副本的分片
<!-- 2个分片、0个副本 -->
<sharding_simple> <!-- 自定义集群名称 -->
<shard> <!-- 分片 -->
<replica> <!-- 副本 -->
<host>ch5.nauu.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>ch6.nauu.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_simple>
2)N个分片和N个副本
<!-- 1个分片 1个副本-->
<sharding_simple_1>
<shard>
<replica>
<host>ch5.nauu.com</host>
<port>9000</port>
</replica>
<replica>
<host>ch6.nauu.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_simple_1>
3)下面所示集群sharding_ha拥有2个分片,而每个分片拥有1个副本:
<sharding_ha>
<shard>
<replica>
<host>ch5.nauu.com</host>
<port>9000</port>
</replica>
<replica>
<host>ch6.nauu.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>ch7.nauu.com</host>
<port>9000</port>
</replica>
<replica>
<host>ch8.nauu.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_ha>
在完成上述配置之后,可以查询系统表验证集群配置是否已被加载:
SELECT cluster, host_name FROM system.clusters
┌─cluster────────┬─host_name──┐
│ shard_2 │ ch5.nauu.com │
│ shard_2 │ ch6.nauu.com │
│ sharding_simple │ ch5.nauu.com │
│ sharding_simple │ ch6.nauu.com │
│ sharding_simple_1 │ ch5.nauu.com │
│ sharding_simple_1 │ ch6.nauu.com │
└─────────────┴─────────┘
10.4.2 基于集群实现分布式DDL
在加入集群配置后,就可以使用新的语法实现分布式DDL执行了,其语法形式如下:
CREATE/DROP/RENAME/ALTER TABLE ON CLUSTER cluster_name
其中,cluster_name对应了配置文件中的集群名称,ClickHouse会根据集群的配置信息顺藤摸瓜,分别去各个节点执行DDL语句。
CREATE TABLE test_1_local ON CLUSTER shard_2(
id UInt64
--这里可以使用任意其他表引擎,
)ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_1', '{replica}')
ORDER BY id
┌─host──────┬─port─┬─status─┬─error─┬─num_hosts_active─┐
│ ch6.nauu.com │ 9000 │ 0 │ │ 0 │
│ ch5.nauu.com │ 9000 │ 0 │ │ 0 │
└─────────┴────┴──────┴─────┴───────────┘
如果要删除test_1_local,则执行下面的分布式DROP:
DROP TABLE test_1_local ON CLUSTER shard_2
┌─host──────┬─port─┬─status─┬─error─┬─num_hosts_active─┐
│ ch6.nauu.com │ 9000 │ 0 │ │ 0 │
│ ch5.nauu.com │ 9000 │ 0 │ │ 0 │
└─────────┴────┴──────┴─────┴───────────┘
在CH5节点的config.xml配置中预先定义了分区01的宏变量:
<macros>
<shard>01</shard>
<replica>ch5.nauu.com</replica>
</macros>
在CH6节点的config.xml配置中预先定义了分区02的宏变量:
<macros>
<shard>02</shard>
<replica>ch6.nauu.com</replica>
</macros>
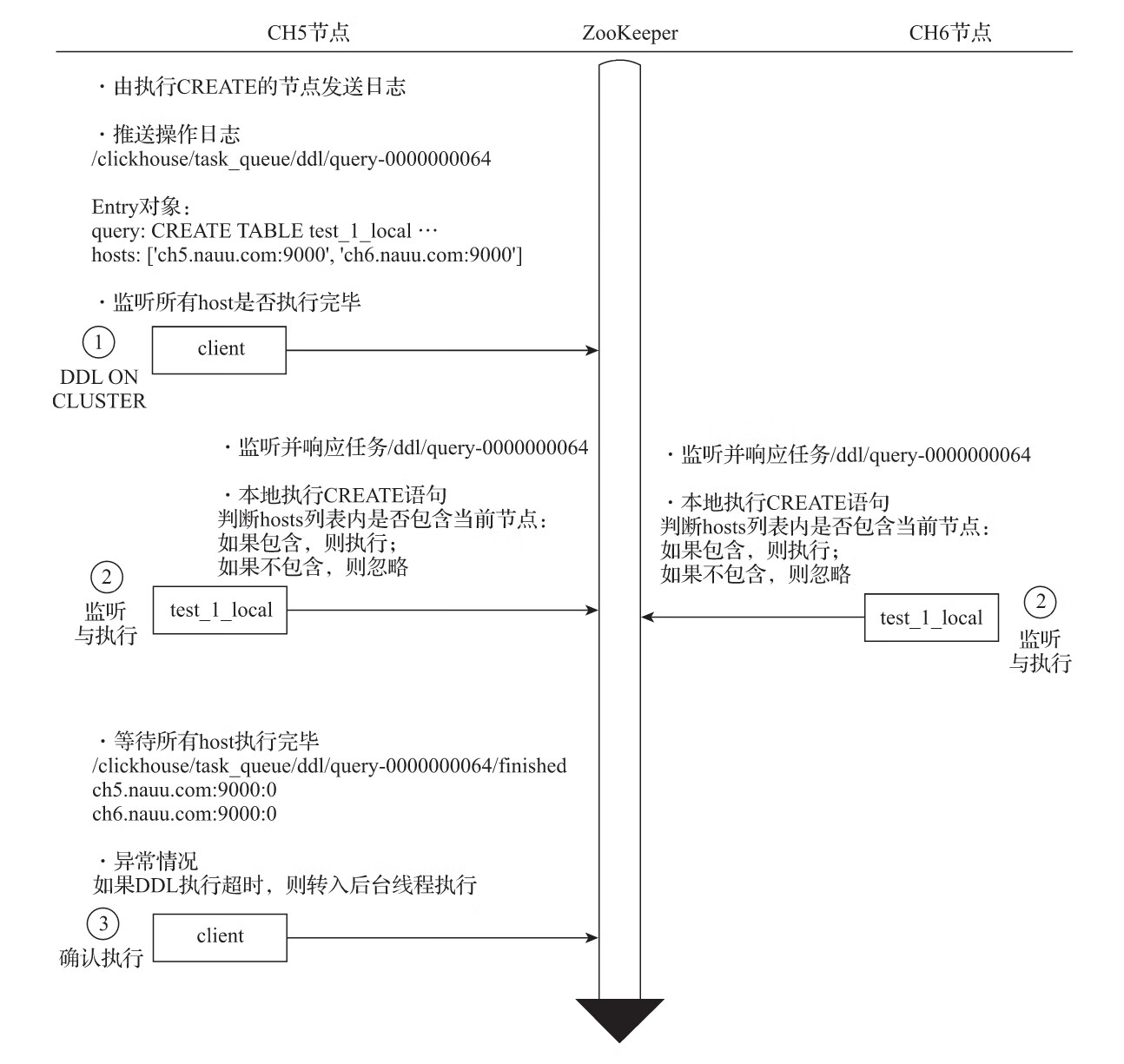
1.数据结构
1)ZooKeeper内的节点结构
在默认情况下,分布式DDL在ZooKeeper内使用的根路径为:
/clickhouse/task_queue/ddl
该路径由config.xml内的distributed_ddl配置指定:
<distributed_ddl>
<!-- Path in ZooKeeper to queue with DDL queries -->
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
2)DDLLogEntry日志对象的数据结构
在/query-[seq]下记录的日志信息由DDLLogEntry承载,它拥有如下几个核心属性:
(1)query记录了DDL查询的执行语句,例如:
query: DROP TABLE default.test_1_local ON CLUSTER shard_2
(2)hosts记录了指定集群的hosts主机列表,集群由分布式DDL语句中的ON CLUSTER指定,例如:
hosts: ['ch5.nauu.com:9000','ch6.nauu.com:9000']
(3)initiator记录初始化host主机的名称,hosts主机列表的取值来自于初始化host节点上的集群,例如:
initiator: ch5.nauu.com:9000
2.分布式DDL的核心执行流程
10.5 Distributed原理解析
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,而是作为数据分片的透明代理,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
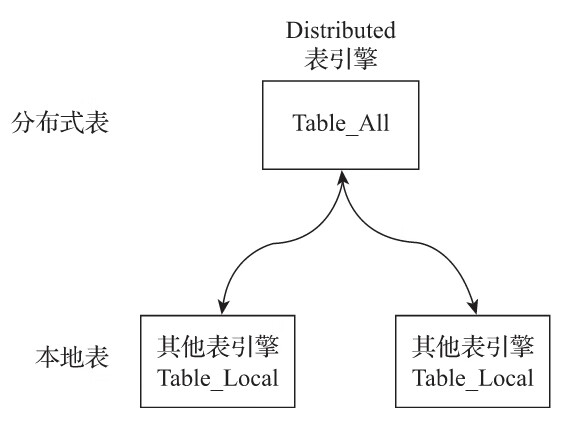
从实体表层面来看,一张分片表由两部分组成:
- ·本地表:通常以_local为后缀进行命名。本地表是承接数据的载体,可以使用非Distributed的任意表引擎,一张本地表对应了一个数据分片。
- ·分布式表:通常以_all为后缀进行命名。分布式表只能使用Distributed表引擎,它与本地表形成一对多的映射关系,日后将通过分布式表代理操作多张本地表。
10.5.1 定义形式
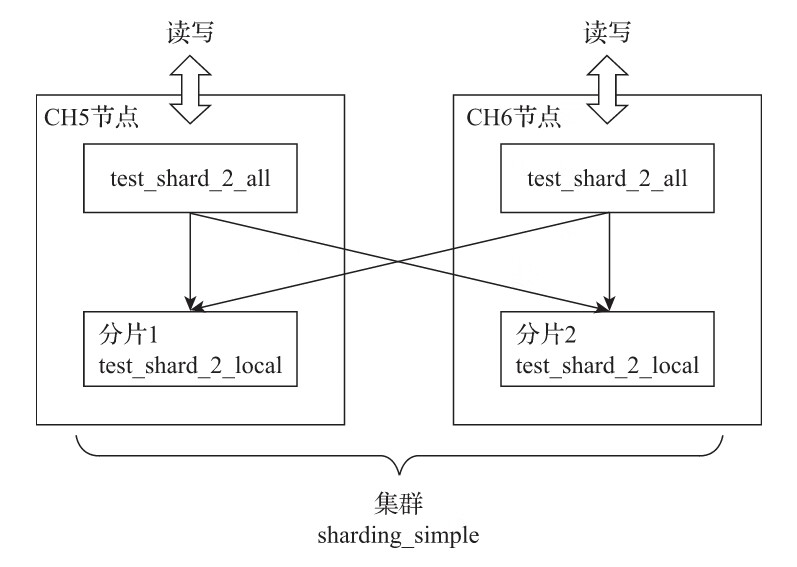
Distributed表引擎的定义形式如下所示:
ENGINE = Distributed(cluster, database, table [,sharding_key])
CREATE TABLE test_shard_2_all ON CLUSTER sharding_simple (
id UInt64
)ENGINE = Distributed(sharding_simple, default, test_shard_2_local,rand())
其中,各个参数的含义分别如下:
- ·cluster:集群名称,与集群配置中的自定义名称相对应。在对分布式表执行写入和查询的过程中,它会使用集群的配置信息来找到相应的host节点。
- ·database和table:分别对应数据库和表的名称,分布式表使用这组配置映射到本地表。
- ·sharding_key:分片键,选填参数。在数据写入的过程中,分布式表会依据分片键的规则,将数据分布到各个host节点的本地表。
10.5.3 分片规则
关于分片的规则这里将做进一步的展开说明。分片键要求返回一个整型类型的取值,包括Int系列和UInt系列。例如分片键可以是一个具体的整型列字段:
--按照用户id的余数划分
Distributed(cluster, database, table ,userid)
--按照随机数划分
Distributed(cluster, database, table ,rand())
--按照用户id的散列值划分
Distributed(cluster, database, table , intHash64(userid))
10.5.4 分布式写入的核心流程
在向集群内的分片写入数据时,通常有两种思路:一种是借助外部计算系统,事先将数据均匀分片,再借由计算系统直接将数据写入ClickHouse集群的各个本地表,如图10-15所示。
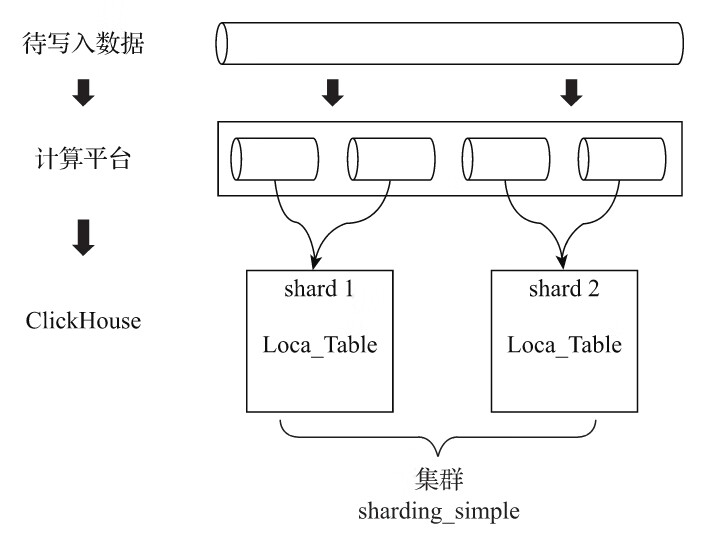
第二种思路是通过Distributed表引擎代理写入分片数据的,接下来开始介绍数据写入的核心流程。
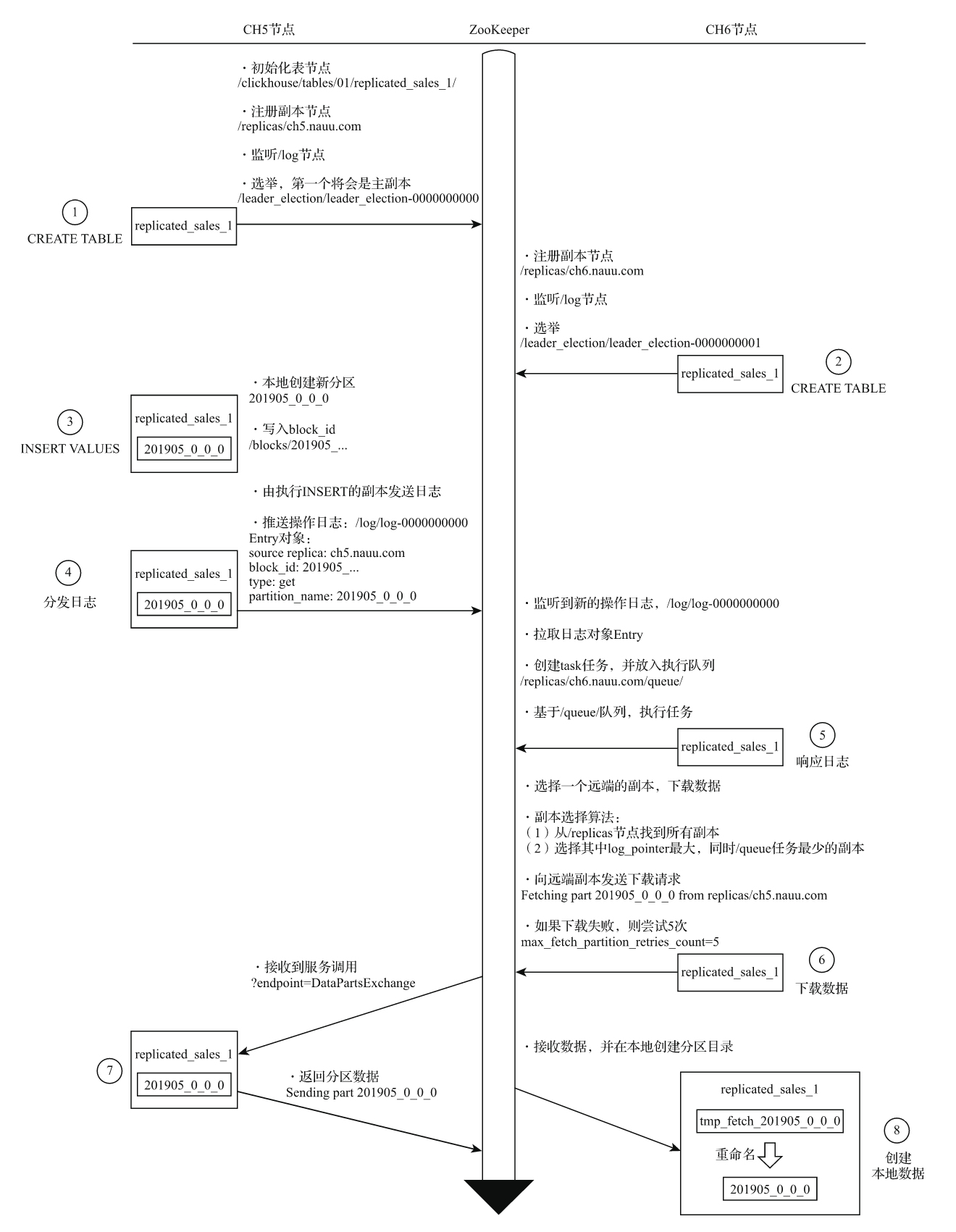
为了便于理解整个过程,这里会将分片写入、副本复制拆分成两个部分进行讲解。在讲解过程中,会使用两个特殊的集群分别进行演示:第一个集群拥有2个分片和0个副本,通过这个示例向大家讲解分片写入的核心流程;第二个集群拥有1个分片和1个副本,通过这个示例向大家讲解副本复制的核心流程。
1.将数据写入分片的核心流程
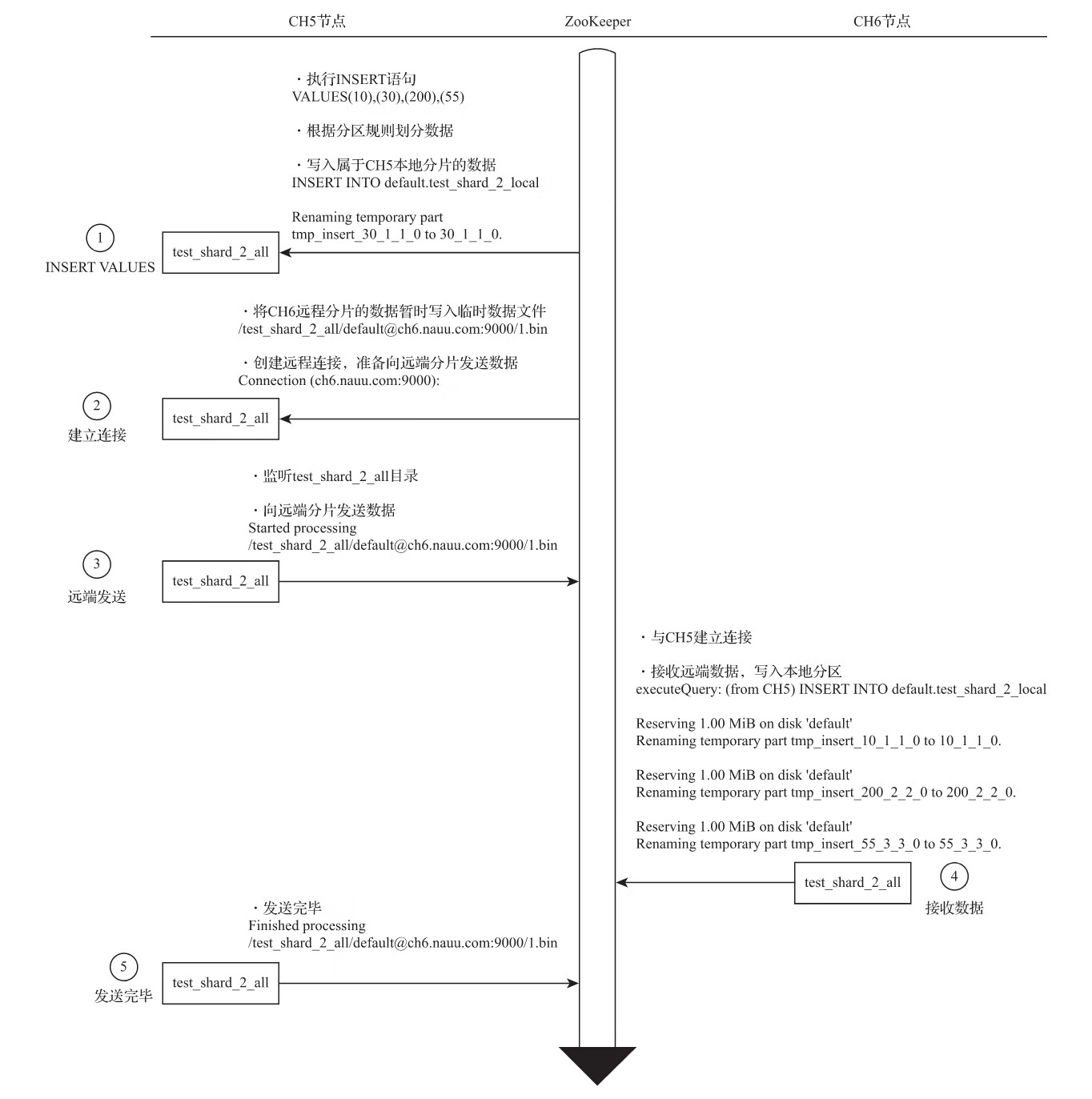
10.5.5 分布式查询的核心流程
1.多副本的路由规则
在查询数据的时候,如果集群中的一个shard,拥有多个replica,那么Distributed表引擎需要面临副本选择的问题。它会使用负载均衡算法从众多replica中选择一个,而具体使用何种负载均衡算法,则由load_balancing参数控制:
load_balancing = random/nearest_hostname/in_order/first_or_random
1)random
random是默认的负载均衡算法,正如前文所述,在ClickHouse的服务节点中,拥有一个全局计数器errors_count,当服务发生任何异常时,该计数累积加1。而random算法会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,则在它们之中随机选择一个。
2)nearest_hostname
nearest_hostname可以看作random算法的变种,首先它会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,则选择集群配置中host名称与当前host最相似的一个。而相似的规则是以当前host名称为基准按字节逐位比较,找出不同字节数最少的一个,例如CH5-1-1和CH5-1-2.nauu.com有一个字节不同:
3)in_order
in_order同样可以看作random算法的变种,首先它会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,则按照集群配置中replica的定义顺序逐个选择。
4)first_or_random
first_or_random可以看作in_order算法的变种,首先它会选择errors_count错误数量最少的replica,如果多个replica的errors_count计数相同,它首先会选择集群配置中第一个定义的replica,如果该replica不可用,则进一步随机选择一个其他的replica。
第11章 管理与运维
11.1 用户配置
11.1.3 用户定义
1.username
username用于指定登录用户名,这是全局唯一属性。该属性比较简单,这里就不展开介绍了。
2.password
(1)明文密码:在使用明文密码的时候,直接通过password标签定义,例如下面的代码。
<password>123</password>
<password></password> !--如果password为空,则表示免密码登录--
(2)SHA256加密:在使用SHA256加密算法的时候,需要通过password_sha256_hex标签定义密码,例如下面的代码。
<password_sha256_hex>a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3</password_sha256_hex>
可以执行下面的命令获得密码的加密串,例如对明文密码123进行加密:
# echo -n 123 | openssl dgst -sha256
(stdin)= a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3
(3)double_sha1加密:在使用double_sha1加密算法的时候,则需要通过password_double_sha1_hex标签定义密码,例如下面的代码。
<password_double_sha1_hex>23ae809ddacaf96af0fd78ed04b6a265e05aa257</password_double_sha1_hex>
可以执行下面的命令获得密码的加密串,例如对明文密码123进行加密:
# echo -n 123 | openssl dgst -sha1 -binary | openssl dgst -sha1
(stdin)= 23ae809ddacaf96af0fd78ed04b6a265e05aa257
3.networks
4.profile
用户所使用的profile配置,直接引用相应的名称即可,例如:
<default>
<profile>default</profile>
</default>
5.quota
quota用于设置该用户能够使用的资源限额,可以理解成一种熔断机制。关于这方面的介绍将会在11.3节展开。
<yandex>
<profiles>
……
</profiles>
<users>
<default><!—默认用户 -->
……
</default>
<user_plaintext>
<password>123</password>
<networks>
<ip>::/0</ip>
</networks>
<profile>normal_1</profile>
<quota>default</quota>
</user_plaintext>
由于配置了密码,所以在登录的时候需要附带密码参数:
# clickhouse-client -h 10.37.129.10 -u user_plaintext --password 123
Connecting to 10.37.129.10:9000 as user user_plaintext.
11.2 权限管理
11.2.1 访问权限
1.网络访问权限
(1)IP地址:直接使用IP地址进行设置。
<ip>127.0.0.1</ip>
(2)host主机名称:通过host主机名称设置。
<host>ch5.nauu.com</host>
(3)正则匹配:通过表达式来匹配host名称。
<host>^ch\d.nauu.com$</host>
2.数据库与字典访问权限
在客户端连入服务之后,可以进一步限制某个用户数据库和字典的访问权限,它们分别通过allow_databases和allow_dictionaries标签进行设置。如果不进行任何定义,则表示不进行限制。现在继续在用户user_normal的定义中增加权限配置:
<user_normal>
……
<allow_databases>
<database>default</database>
<database>test_dictionaries</database>
</allow_databases>
<allow_dictionaries>
<dictionary>test_flat_dict</dictionary>
</allow_dictionaries>
</user_normal>
11.2.2 查询权限
查询权限是整个权限体系的第二层防护,它决定了一个用户能够执行的查询语句。查询权限可以分成以下四类:
- ·读权限:包括SELECT、EXISTS、SHOW和DESCRIBE查询。
- ·写权限:包括INSERT和OPTIMIZE查询。
- ·设置权限:包括SET查询。
- ·DDL权限:包括CREATE、DROP、ALTER、RENAME、ATTACH、DETACH和TRUNCATE查询。
上述这四类权限,通过以下两项配置标签控制:
(1)readonly:读权限、写权限和设置权限均由此标签控制,它有三种取值。
- ·当取值为0时,不进行任何限制(默认值)。
- ·当取值为1时,只拥有读权限(只能执行SELECT、EXISTS、SHOW和DESCRIBE)。
- ·当取值为2时,拥有读权限和设置权限(在读权限基础上,增加了SET查询)。
(2)allow_ddl:DDL权限由此标签控制,它有两种取值。
- ·当取值为0时,不允许DDL查询。
- ·当取值为1时,允许DDL查询(默认值)。
现在继续用一个示例说明。与刚才的配置项不同,readonly和allow_ddl需要定义在用户profiles中,例如:
<profiles>
<normal> <!-- 只有read读权限-->
<readonly>1</readonly>
<allow_ddl>0</allow_ddl>
</normal>
<normal_1> <!-- 有读和设置参数权限-->
<readonly>2</readonly>
<allow_ddl>0</allow_ddl>
</normal_1>
11.2.3 数据行级权限
数据权限是整个权限体系中的第三层防护,它决定了一个用户能够看到什么数据。数据权限使用databases标签定义,它是用户定义中的一项选填设置。database通过定义用户级别的查询过滤器来实现数据的行级粒度权限,它的定义规则如下所示:
<databases>
<database_name><!--数据库名称-->
<table_name><!--表名称-->
<filter> id < 10</filter><!--数据过滤条件-->
</table_name>
</database_name>
其中,database_name表示数据库名称;table_name表示表名称;而filter则是权限过滤的关键所在,它等同于定义了一条WHERE条件子句,与WHERE子句类似,它支持组合条件。现在用一个示例说明。这里还是用user_normal,为它追加databases定义:
<user_normal>
……
<databases>
<default><!--默认数据库-->
<test_row_level><!—表名称-->
<filter>id < 10</filter>
</test_row_level>
<!—支持组合条件
<test_query_all>
<filter>id <= 100 or repo >= 100</filter>
</test_query_all> -->
</default>
</databases>
11.3 熔断机制
1.根据时间周期的累积用量熔断
在这种方式下,系统资源的用量是按照时间周期累积统计的,当累积量达到阈值,则直到下个计算周期开始之前,该用户将无法继续进行操作。这种方式通过users.xml内的quotas标签来定义资源配额。以下面的配置为例:
<quotas>
<default> <!-- 自定义名称 -->
<interval>
<duration>3600</duration><!-- 时间周期 单位:秒 -->
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
其中,各配置项的含义如下:
- ·default:表示自定义名称,全局唯一。
- ·duration:表示累积的时间周期,单位是秒。
- ·queries:表示在周期内允许执行的查询次数,0表示不限制。
- ·errors:表示在周期内允许发生异常的次数,0表示不限制。
- ·result_row:表示在周期内允许查询返回的结果行数,0表示不限制。
- ·read_rows:表示在周期内在分布式查询中,允许远端节点读取的数据行数,0表示不限制。
- ·execution_time:表示周期内允许执行的查询时间,单位是秒,0表示不限制。
2.根据单次查询的用量熔断
首先介绍一组针对普通查询的熔断配置。
(1)max_memory_usage:在单个ClickHouse服务进程中,运行一次查询限制使用的最大内存量,默认值为10 GB,其配置形式如下。
<max_memory_usage>10000000000</max_memory_usage>
(2)max_memory_usage_for_user:在单个ClickHouse服务进程中,以用户为单位进行统计,单个用户在运行查询时限制使用的最大内存量,默认值为0,即不做限制。
(3)max_memory_usage_for_all_queries:在单个ClickHouse服务进程中,所有运行的查询累加在一起所限制使用的最大内存量,默认为0,即不做限制。
(4)max_partitions_per_insert_block:在单次INSERT写入的时候,限制创建的最大分区个数,默认值为100个。如果超出这个阈值,将会出现如下异常:
(5)max_rows_to_group_by:在执行GROUP BY聚合查询的时候,限制去重后聚合
(6)group_by_overflow_mode:当max_rows_to_group_by熔断规则触发时,group_by_overflow_mode将会提供三种处理方式。
(7)max_bytes_before_external_group_by:在执行GROUP BY聚合查询的时候,限制使用的最大内存量,默认值为0,即不做限制。当超过阈值时,聚合查询将会进一步借用本地磁盘。
11.4 数据备份
11.4.1 导出文件备份
如果数据的体量较小,可以通过dump的形式将数据导出为本地文件。例如执行下面的语句将test_backup的数据导出:
#clickhouse-client --query="SELECT * FROM test_backup" > /chbase/test_backup.tsv
# cat /chbase/test_backup.tsv | clickhouse-client --query "INSERT INTO test_backup FORMAT TSV" --将备份数据再次导入,则可以执行下面的语句:
上述这种dump形式的优势在于,可以利用SELECT查询并筛选数据,然后按需备份。如果是备份整个表的数据,也可以直接复制它的整个目录文件,例如:
# mkdir -p /chbase/backup/default/ & cp -r /chbase/data/default/test_backup /chbase/backup/default/
11.4.2 通过快照表备份
快照表实质上就是普通的数据表,它通常按照业务规定的备份频率创建,例如按天或者按周创建。所以首先需要建立一张与原表结构相同的数据表,然后再使用INSERT INTO SELECT句式,点对点地将数据从原表写入备份表。假设数据表test_backup需要按日进行备份,现在为它创建当天的备份表:
CREATE TABLE test_backup_0206 AS test_backup
有了备份表之后,就可以点对点地备份数据了,例如:
INSERT INTO TABLE test_backup_0206 SELECT * FROM test_backup
如果考虑到容灾问题,也可以将备份表放置在不同的ClickHouse节点上,此时需要将上述SQL语句改成远程查询的形式:
INSERT INTO TABLE test_backup_0206 SELECT * FROM remote('ch5.nauu.com:9000', 'default', 'test_backup', 'default')
11.4.3 按分区备份
1.使用FREEZE备份
FREEZE的完整语法如下所示:
ALTER TABLE tb_name FREEZE PARTITION partition_expr
分区在被备份之后,会被统一保存到ClickHouse根路径/shadow/N子目录下。其中,N是一个自增长的整数,它的含义是备份的次数(FREEZE执行过多少次),具体次数由shadow子目录下的increment.txt文件记录。而分区备份实质上是对原始目录文件进行硬链接操作,所以并不会导致额外的存储空间。整个备份的目录会一直向上追溯至data根路径的整个链路:
/data/[database]/[table]/[partition_folder]
例如执行下面的语句,会对数据表partition_v2的201908分区进行备份:
:) ALTER TABLE partition_v2 FREEZE PARTITION 201908
进入shadow子目录,即能够看到刚才备份的分区目录:
# pwd
/chbase/data/shadow/1/data/default/partition_v2
# ll
total 4
drwxr-x---. 2 clickhouse clickhouse 4096 Sep 1 00:22 201908_5_5_0
对于备份分区的还原操作,则需要借助ATTACH装载分区的方式来实现。这意味着如果要还原数据,首先需要主动将shadow子目录下的分区文件复制到相应数据表的detached目录下,然后再使用ATTACH语句装载。
11.5 服务监控
11.5.1 系统表
1.metrics
metrics表用于统计ClickHouse服务在运行时,当前正在执行的高层次的概要信息,包括正在执行的查询总次数、正在发生的合并操作总次数等。该系统表的查询方法如下所示:
SELECT * FROM system.metrics LIMIT 5
┌─metric──────┬─value─┬─description─────────────────────┐
│ Query │ 1 │ Number of executing queries │
│ Merge │ 0 │ Number of executing background merges │
│ PartMutation │ 0 │ Number of mutations (ALTER DELETE/UPDATE) │
│ ReplicatedFetch │ 0 │ Number of data parts being fetched from replica │
│ ReplicatedSend │ 0 │ Number of data parts being sent to replicas │
└──────────┴─────┴─────────────────────────────┘
2.events
events用于统计ClickHouse服务在运行过程中已经执行过的高层次的累积概要信息,包括总的查询次数、总的SELECT查询次数等,该系统表的查询方法如下所示:
SELECT event, value FROM system.events LIMIT 5
┌─event─────────────────────┬─value─┐
│ Query │ 165 │
│ SelectQuery │ 92 │
│ InsertQuery │ 14 │
│ FileOpen │ 3525 │
│ ReadBufferFromFileDescriptorRead │ 6311 │
└─────────────────────────┴─────┘
3.asynchronous_metrics
asynchronous_metrics用于统计ClickHouse服务运行过程时,当前正在后台异步运行的高层次的概要信息,包括当前分配的内存、执行队列中的任务数量等。该系统表的查询方法如下所示:
SELECT * FROM system.asynchronous_metrics LIMIT 5
┌─metric───────────────────────┬─────value─┐
│ jemalloc.background_thread.run_interval │ 0 │
│ jemalloc.background_thread.num_runs │ 0 │
│ jemalloc.background_thread.num_threads │ 0 │
│ jemalloc.retained │ 79454208 │
│ jemalloc.mapped │ 531341312 │
└────────────────────────────┴──────────┘
11.5.2 查询日志
查询日志目前主要有6种类型,它们分别从不同角度记录了ClickHouse的操作行为。所有查询日志在默认配置下都是关闭状态,需要在config.xml配置中进行更改,接下来分别介绍它们的开启方法。在配置被开启之后,ClickHouse会为每种类型的查询日志自动生成相应的系统表以供查询。
1.query_log
query_log是最常用的查询日志,它记录了ClickHouse服务中所有已经执行的查询记录,它的全局定义方式如下所示:
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<!—刷新周期-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
如果只需要为某些用户单独开启query_log,也可以在user.xml的profile配置中按照下面的方式定义:
<log_queries> 1</log_queries>
query_log开启后,即可以通过相应的系统表对记录进行查询:
SELECT type,concat(substr(query,1,20),'...')query,read_rows,
query_duration_ms AS duration FROM system.query_log LIMIT 6
┌─type──────────┬─query───────────┬─read_rows─┬─duration─┐
│ QueryStart │ SELECT DISTINCT arra... │ 0 │ 0 │
│ QueryFinish │ SELECT DISTINCT arra... │ 2432 │ 11 │
│ QueryStart │ SHOW DATABASES... │ 0 │ 0 │
│ QueryFinish │ SHOW DATABASES... │ 3 │ 1 │
│ ExceptionBeforeStart │ SELECT * FROM test_f... │ 0 │ 0 │
│ ExceptionBeforeStart │ SELECT * FROM test_f... │ 0 │ 0 │
└─────────────┴───────────────┴───────┴───────┘
2.query_thread_log
query_thread_log记录了所有线程的执行查询的信息,它的全局定义方式如下所示:
<query_thread_log>
<database>system</database>
<table>query_thread_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_thread_log>
同样,如果只需要为某些用户单独开启该功能,可以在user.xml的profile配置中按照下面的方式定义:
<log_query_threads> 1</log_query_threads>
query_thread_log开启后,即可以通过相应的系统表对记录进行查询:
SELECT thread_name,concat(substr(query,1,20),'...')query,query_duration_ms AS duration,memory_usage AS memory FROM system.query_thread_log LIMIT 6
┌─thread_name───┬─query───────────┬─duration─┬─memory─┐
│ ParalInputsProc │ SELECT DISTINCT arra... │ 2 │ 210888 │
│ ParalInputsProc │ SELECT DISTINCT arra... │ 3 │ 252648 │
│ AsyncBlockInput │ SELECT DISTINCT arra... │ 3 │ 449544 │
│ TCPHandler │ SELECT DISTINCT arra... │ 11 │ 0 │
│ TCPHandler │ SHOW DATABASES... │ 2 │ 0 │
└──────────┴───────────────┴───────┴──────┘
3.part_log
part_log日志记录了MergeTree系列表引擎的分区操作日志,其全局定义方式如下所示:
<part_log>
<database>system</database>
<table>part_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>
part_log开启后,即可以通过相应的系统表对记录进行查询:
SELECT event_type AS type,table,partition_id,event_date FROM system.part_log
┌─type────┬─table─────────────┬─partition_id─┬─event_date─┐
│ NewPart │ summing_table_nested_v1 │ 201908 │ 2020-01-29 │
│ NewPart │ summing_table_nested_v1 │ 201908 │ 2020-01-29 │
│ MergeParts │ summing_table_nested_v1 │ 201908 │ 2020-01-29 │
│ RemovePart │ ttl_table_v1 │ 201505 │ 2020-01-29 │
│ RemovePart │ summing_table_nested_v1 │ 201908 │ 2020-01-29 │
│ RemovePart │ summing_table_nested_v1 │ 201908 │ 2020-01-29 │
└───────┴─────────────────┴─────────┴────────┘
4.text_log
text_log日志记录了ClickHouse运行过程中产生的一系列打印日志,包括INFO、DEBUG和Trace,它的全局定义方式如下所示:
<text_log>
<database>system</database>
<table>text_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</text_log>
text_log开启后,即可以通过相应的系统表对记录进行查询:
SELECT thread_name,
concat(substr(logger_name,1,20),'...')logger_name,
concat(substr(message,1,20),'...')message
FROM system.text_log LIMIT 5
┌─thread_name──┬─logger_name───────┬─message────────────┐
│ SystemLogFlush │ SystemLog (system.me... │ Flushing system log... │
│ SystemLogFlush │ SystemLog (system.te... │ Flushing system log... │
│ SystemLogFlush │ SystemLog (system.te... │ Creating new table s... │
│ SystemLogFlush │ system.text_log... │ Loading data parts... │
│ SystemLogFlush │ system.text_log... │ Loaded data parts (0... │
└──────────┴───────────────┴─────────────────┘
5.metric_log
metric_log日志用于将system.metrics和system.events中的数据汇聚到一起,它的全局定义方式如下所示:
<metric_log>
<database>system</database>
<table>metric_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<collect_interval_milliseconds>1000</collect_interval_milliseconds>
</metric_log>
其中,collect_interval_milliseconds表示收集metrics和events数据的时间周期。metric_log开启后,即可以通过相应的系统表对记录进行查询。