HBase工作原理概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
我们知道面向行存储的关系型数据库擅长处理查询的操作,而面向列的存储的数据库擅长统计分析数据。HBase是分布式面向列存储的数据库。
一.HBase概述
1>.什么是HBase
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
HBase重大事件: 2006年Google发表BigTable白皮书 2006年开始开发HBase 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目 2010年HBase成为Apache顶级项目
现在很多公司二次开发出了很多发行版本,你也开始使用了。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
HBase官方网站:
http://hbase.apache.org
2>.HBase特点
海量存储 Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
列式存储 这里的列式存储其实说的是列族(ColumnFamily)存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
极易扩展 Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。 通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。 备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
高并发(多核) 由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
稀疏 稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
3>.HBase架构
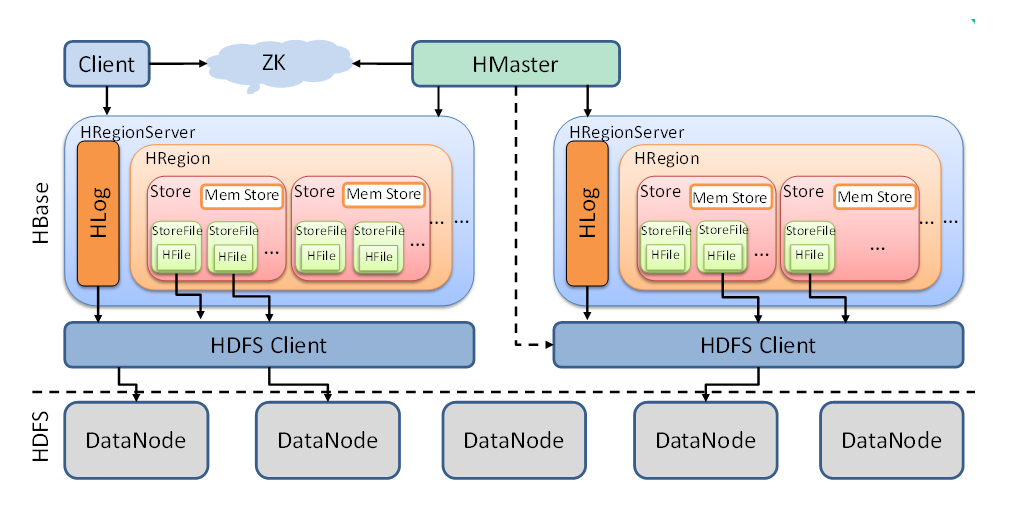
如上图所示,可以看出Hbase是由Client、Zookeeper、Master、HRegionServer、HDFS等几个组件组成,下面来介绍一下几个组件的相关功能。 Client功能: Client包含了访问Hbase的接口,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。 Zookeeper功能: (1)保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务 (2)监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知HMaster关于HRegionServer上下线的信息 (3)存储元数据的统一入口地址 Hmaster功能: (1)监控RegionServer (2)处理RegionServer故障转移 (3)处理元数据的变更 (4)处理region的分配或转移 (5)在空闲时间进行数据的负载均衡 (6)通过Zookeeper发布自己的位置给客户端 HregionServer功能: (1)负责存储HBase的实际数据 (2)处理分配给它的Region (3)刷新缓存到HDFS (4)维护Hlog (5)执行压缩 (6)负责处理Region分片 HregionServer节点的内部组件: Write-Ahead logs(HLog)功能: HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。 但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。 所以在系统出现故障的时候,数据可以通过这个日志文件重建。 HRegion功能: Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。 Store功能: HFile存储在Store中,一个Store对应HBase表中的一个列族(列簇, Column Family)。 MemStore功能: 顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。 HFile: 这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。 HDFS功能: (1)提供元数据和表数据的底层分布式存储服务 (2)数据多副本,保证的高可靠和高可用性 HBase集群搭建: https://www.cnblogs.com/yinzhengjie2020/p/12239031.html
4>.HBase在商业项目中的能力
每天: (1)消息量:发送和接收的消息数超过60亿 (2)将近1000亿条数据的读写 (3)高峰期每秒150万左右操作 (4)整体读取数据占有约55%,写入占有45% (5)超过2PB的数据,涉及冗余共6PB数据 (6)数据每月大概增长300千兆字节。
5>.HBase2.0新特性
2017年8月22日凌晨2点左右,HBase发布了2.0.0 alpha-2,相比于上一个版本,修复了500个补丁,我们来了解一下2.0版本的HBase新特性。
最新文档: http://hbase.apache.org/book.html#ttl
二.HBase数据结构
1>.RowKey
与nosql数据库们一样,RowKey是用来检索记录的主键。访问HBASE table中的行,只有三种方式: (1)通过单个RowKey访问(get) (2)通过RowKey的range(正则)(like) (3)全表扫描(scan)
RowKey行键 (RowKey)可以是任意字符串(最大长度是64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,RowKey保存为字节数组。
存储时,数据按照RowKey的字典序(byte order)排序存储(换句话说,就是按照ASCII表的顺序进行排序)。设计RowKey时,要充分排序存储这个特性,将经常一起读取的行存储放到一起(位置相关性,有点类似于HDD的预读技术)。
为什么RowKey保存为字节数组,而不保存为字符串呢?
答:为了方便压缩"RowKey",从而更好的利用内存空间。
举个例子:
假设RowKey为"a1a2a3",如果以字符串保存的话会占用6个字节,而使用字节数组对应[97,49,97,50,97,51]。
看到这里估计很多小伙伴已经想原因了,我们知道一个字节的范围是[-128~127],很明显使用字节数组保存RowKey为"a1a2a3"要比使用字符串保存更节省bit,根本原因是更适合压缩(比如记录字符"a"出现的次数,"a:[0,2,4]")。
2>.Column Family
HBASE表中的每个列,都归属于某个列族(Column Family)。
列族是表的schema的一部分(而列不是),必须在使用表之前定义。
列名都以列族作为前缀。例如"student"表中的"courses:history","courses:math"都属于courses这个列族。
3>.Cell
HBase由{rowkey, column Family:columu, version} 来唯一确定的单元称之为"cell"。
cell中的数据是没有类型的,全部是字节码形式存贮。
4>.TimeStamp
每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是64位整型。时间戳可以由HBASE(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。 如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。 为了避免数据存在过多版本造成的的管理(包括存贮和索引)负担,HBASE提供了两种数据版本回收方式(用户可以针对每个列族进行设置): (1)保存数据的最后n个版本; (2)保存最近一段时间内的版本(比如最近七天)。
5>.命名空间结构
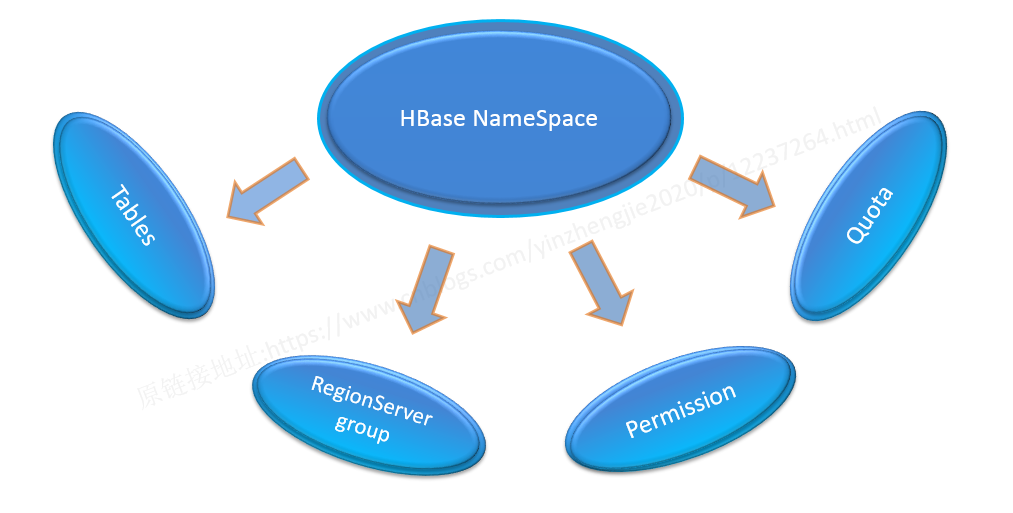
Tables:
所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在default默认的命名空间中。
RegionServer group:
一个命名空间包含了默认的RegionServer Group。
Permission:
权限,命名空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
Quota:
限额,可以强制一个命名空间可包含的region的数量。
三.HBase写入流程剖析
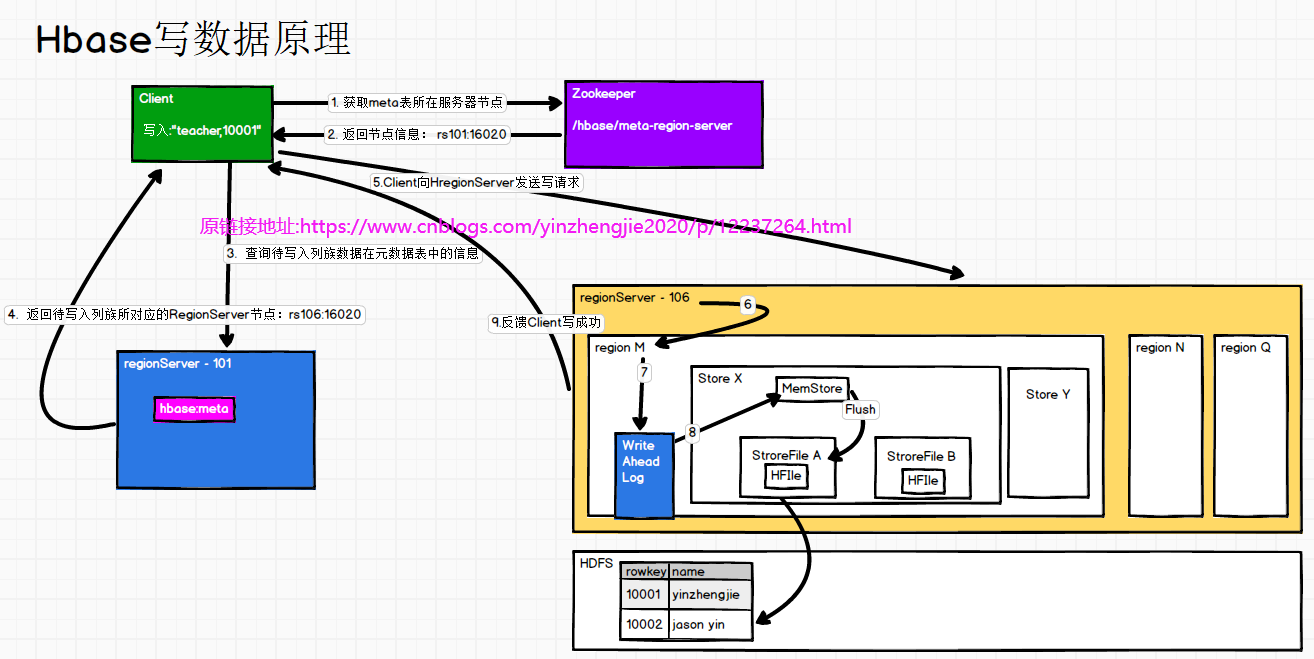
如上图所示,Client想要写入"teacher,10001",此时HBase的写入流程大致如下所示: (1)Client发起第一次请求先访问zookeeper(/hbase/meta-region-server)获取元数据信息表; (2)Zookeeper返回Client元数据表所在的RegionServer(rs101:16020); (3)Client发起第二次请求访问RegionServer(rs101:16020)查询待写入列族数据在元数据表中的信息; (4)根据namespace、表名和rowkey在meta表中找到对应的region信息并返回给Client; (5)Cleint找到这个region对应的regionserver并发起第三次请求向HregionServer(rs106:16020)发送写请求; (6)regionserver找到查找对应的region; (7)HRegionServer先将数据写到HLog(write ahead log),目的为了防止数据丢失; (8)HRegionServer在将数据写到内存(MemStore); (9)最后反馈Client写成功; 由于MemStore的数据是存放在内存中的,因此不能持续存放数据,其flush过程如下: (1)当MemStore数据达到阈值(默认是128M,老版本是64M,该默认值参考了HDFS的Block默认值),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据; (2)并将数据存储到HDFS中; (3)在HLog中做标记点。 温馨提示: 当数据成功写入到Region的Hlog后,会再将数据写入到MemStore,当MemStore写不进去(该区域内存已满),此时会做回滚(RockBack)操作,即将成功写入HLog的数据的数据删除掉,并返回给客户端写入失败,其目的是保证数据的一致性。 需要注意的,HBase并不支持事务。
四.HBase读取流程剖析
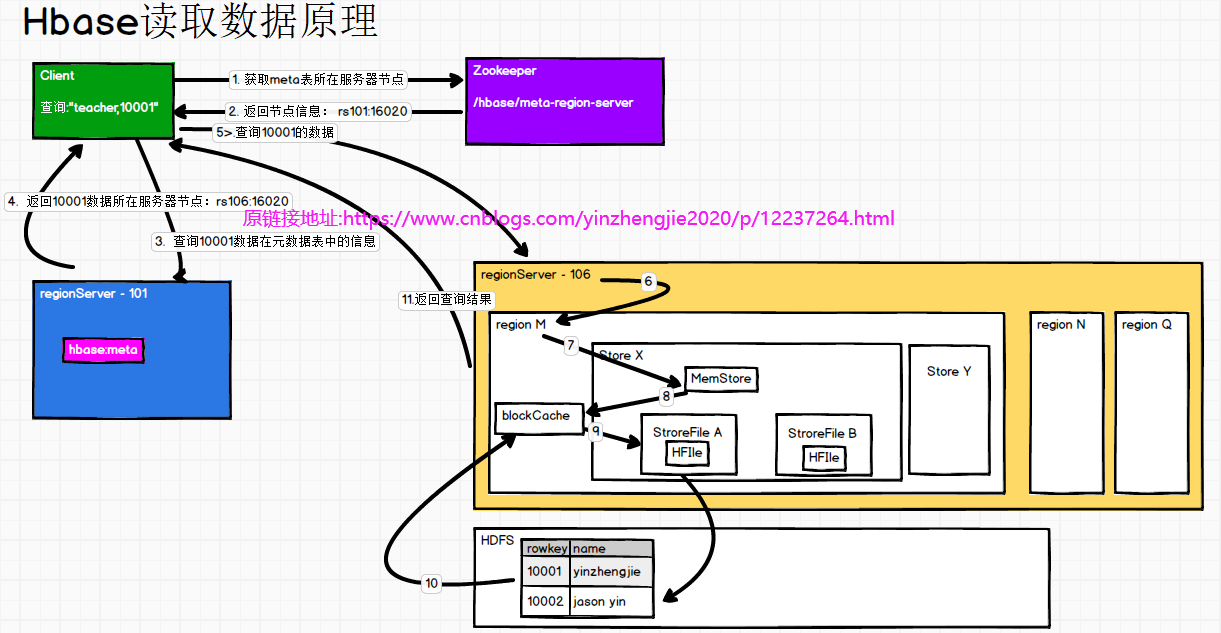
如上图所示,Client想要读取"teacher,10001",此时HBase的读取流程大致如下所示: (1)Client发起第一次请求先访问zookeeper(/hbase/meta-region-server)获取元数据信息表; (2)Zookeeper返回Client元数据表所在的RegionServer(rs101:16020); (3)Client发起第二次请求访问RegionServer(rs101:16020)获取"teacher,10001"在元数据(meta)表中的信息; (4)根据namespace、表名和rowkey在meta表中找到对应的region信息并返回给Client; (5)Cleint找到这个region对应的regionserver(rs106:16020)并发起第三次请求访问"teacher,10001"数据; (6)regionserver找到查找对应的region; (7)先从MemStore(写缓存,还没有写入到HFile)找数据; (8)如果MemStore没有找到数据,再到BlockCache(读缓存)里面找数据; (9)BlockCache也没有找到数据,再到StoreFile(HFile)上读(为了读取的效率); (10)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache; (11)将查询结果返回给客户端; 温馨提示: 综上所述,HBase查询效率流程比较复杂,因此查询效率并不高。我们不应该用HBase来做即席查询,而用它来做统计分析。如果你非要用作查询操作的话请考虑使用MySQL。
五.HBase数据合并过程剖析
我们知道当MemStore数据达到阈值是会将数据flush到磁盘,但有的时候不一定要达到阈值时才会溢写到磁盘,比如当服务器的Region数量过多时,此时MemStroe数量也会增多,单台服务器的资源是有限的,因此未必是每个MemStore都达到128MB才会写入。 举个例子: 一个HRegionServer内存为1GB,其有100个Region,即每个MemStore很有可能在10MB左右就开始溢写到磁盘,这样就会导致HDFS集群存在大量小文件。而HDFS存储大量小文件无疑是浪费集群资源,因此HBase需要对其进行优化,将大量的小文件进行合并。 数据合并过程 (1)当数据块达到3块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并; (2)当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HRegionServer管理(由HMaster负责调度分配); (3)当HregionServer宕机后(数据并没有丢失,因为数据存储在HDFS集群),将HRegionServer上的HLog拆分,然后分配给不同的HRegionServer加载,修改".META."; (4)注意:HLog会同步到HDFS。 温馨提示: 在HBase 1.3.1版本中存在以下一行源码: Math.min(getDesiredMaxFileSize(),initialSize * tableRegionsCount * tableRegionsCount * tableregionsCount) 各变量解释如下: getDesiredMaxFileSize: 对应常量"hbase.hregion.max.filesize",该常量默认是10G initialSize: 默认是常量"hbase.hregion.memstore.flush.size"(默认128MB)的2倍,即256MB. tableRegionsCount: 一个未被预分区的表默认Region数量是1。 结论: 当一个未被预分区的Region数量为1时,当第一次合并的数据块超过256MB时会被切分,而第二次合并的数据块就不是256MB啦,原因很简单,因为在第一次切分后tableRegionsCount的数量变为2。 以此类推:
第二次切分的大小应该为:"256 * 2 * 2 * 2" = 2048MB(2G),该值小于10G,因此第二次切分大小应该为2G
第三次切分的大小应该为:"256 * 3 * 3 * 3" = 6912MB(约为7G),该值小于10G,因此第三次切分大小应该为6912MB
第四次切分的大小应该为:"256 * 4 * 4 * 4" = 16384MB(16G),该值大于10G,因此第四次切分大小应该为10G
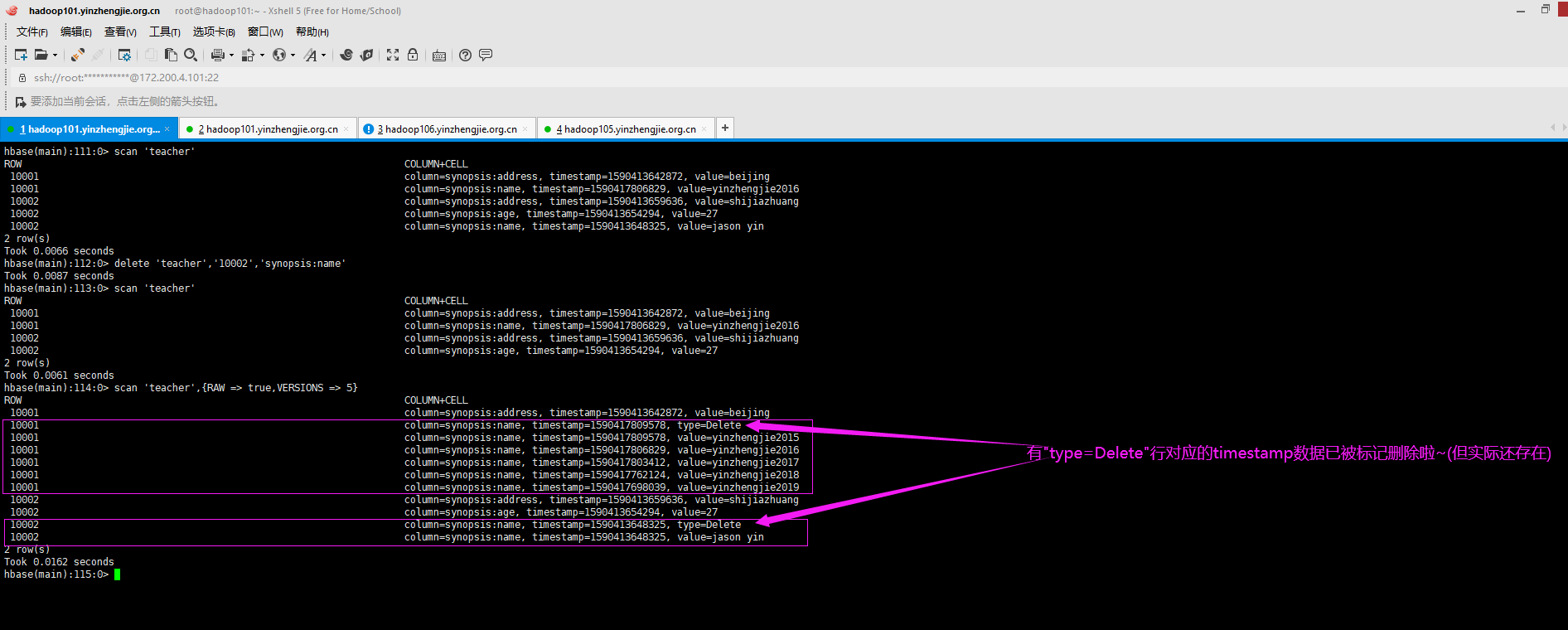
六.HBase删除流程剖析
HBase无论时修改还是删除,其实本质上并没有删除,而是增加了一些标记,比如"type=Delete"之类的。如下图所示,删除字段时看似被删除但实际并没有被立刻删除,而是被标记删除啦。
HBase会在集群空闲的时间删除它。当然在HBase重量级合并HBase上的小文件时,也会顺便将标记删除的数据删除后在合并。


hbase(main):105:0> scan 'teacher',{STARTROW =>'10001',STOPROW => '10001',VERSIONS => 5} ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417809578, value=yinzhengjie2015 10001 column=synopsis:name, timestamp=1590417806829, value=yinzhengjie2016 10001 column=synopsis:name, timestamp=1590417803412, value=yinzhengjie2017 10001 column=synopsis:name, timestamp=1590417762124, value=yinzhengjie2018 10001 column=synopsis:name, timestamp=1590417698039, value=yinzhengjie2019 1 row(s) Took 0.0110 seconds hbase(main):106:0> scan 'teacher',{STARTROW =>'10001',STOPROW => '10001'} ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417809578, value=yinzhengjie2015 1 row(s) Took 0.0057 seconds hbase(main):107:0> delete 'teacher','10001','synopsis:name' Took 0.0662 seconds hbase(main):108:0> hbase(main):108:0> scan 'teacher',{STARTROW =>'10001',STOPROW => '10001'} ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417806829, value=yinzhengjie2016 1 row(s) Took 0.0147 seconds hbase(main):109:0> scan 'teacher',{STARTROW =>'10001',STOPROW => '10001',VERSIONS => 5} ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417806829, value=yinzhengjie2016 10001 column=synopsis:name, timestamp=1590417803412, value=yinzhengjie2017 10001 column=synopsis:name, timestamp=1590417762124, value=yinzhengjie2018 10001 column=synopsis:name, timestamp=1590417698039, value=yinzhengjie2019 10001 column=synopsis:name, timestamp=1590413634375, value=yinzhengjie 1 row(s) Took 0.0089 seconds hbase(main):110:0>
hbase(main):111:0> scan 'teacher' ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417806829, value=yinzhengjie2016 10002 column=synopsis:address, timestamp=1590413659636, value=shijiazhuang 10002 column=synopsis:age, timestamp=1590413654294, value=27 10002 column=synopsis:name, timestamp=1590413648325, value=jason yin 2 row(s) Took 0.0066 seconds hbase(main):112:0> delete 'teacher','10002','synopsis:name' Took 0.0087 seconds hbase(main):113:0> scan 'teacher' ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417806829, value=yinzhengjie2016 10002 column=synopsis:address, timestamp=1590413659636, value=shijiazhuang 10002 column=synopsis:age, timestamp=1590413654294, value=27 2 row(s) Took 0.0061 seconds hbase(main):114:0> scan 'teacher',{RAW => true,VERSIONS => 5} ROW COLUMN+CELL 10001 column=synopsis:address, timestamp=1590413642872, value=beijing 10001 column=synopsis:name, timestamp=1590417809578, type=Delete 10001 column=synopsis:name, timestamp=1590417809578, value=yinzhengjie2015 10001 column=synopsis:name, timestamp=1590417806829, value=yinzhengjie2016 10001 column=synopsis:name, timestamp=1590417803412, value=yinzhengjie2017 10001 column=synopsis:name, timestamp=1590417762124, value=yinzhengjie2018 10001 column=synopsis:name, timestamp=1590417698039, value=yinzhengjie2019 10002 column=synopsis:address, timestamp=1590413659636, value=shijiazhuang 10002 column=synopsis:age, timestamp=1590413654294, value=27 10002 column=synopsis:name, timestamp=1590413648325, type=Delete 10002 column=synopsis:name, timestamp=1590413648325, value=jason yin 2 row(s) Took 0.0162 seconds hbase(main):115:0>
七.博主推荐阅读
HBase shell常用命令总结 https://www.cnblogs.com/yinzhengjie2020/p/12239339.html HBase完全分布式集群搭建: https://www.cnblogs.com/yinzhengjie2020/p/12239031.html HBase API实战案例: https://www.cnblogs.com/yinzhengjie2020/p/12271220.html