目录
- YOLO V2简介
- V2主要改进方面
- 论文细节介绍
arxiv: https://arxiv.org/abs/1612.08242
code: http://pjreddie.com/yolo9000/
github(PyTorch): https://github.com/longcw/yolo2-pytorch
github(Tensorflow): https://github.com/hizhangp/yolo_tensorflow
github(Windows): https://github.com/AlexeyAB/darknet
一、YOLO V2简介
经过Joseph Redmon等的改进,YOLOv2和YOLO9000算法在2017年CVPR上被提出,并获得较佳论文提名,重点解决召回率和定位精度方面的误差。采用Darknet-19作为特征提取网络,增加了批量归一化(Batch Normalization)的预处理,并使用224×224和448×448两阶段训练ImageNet预训练模型后fine-tuning。
相比于原来的YOLO是利用全连接层直接预测bounding box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入anchor机制,利用K-Means聚类的方式在训练集中聚类计算出更好的anchor模板,在卷积层使用anchorboxes操作,增加候选框的预测,同时采用较强约束的定位方法,大大提高算法召回率。结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
YOLOv1对于bounding box的定位不是很好,在精度上比同类网络还有一定的差距,所以YOLOv2对于速度和精度做了很大的优化,并且吸收了同类网络的优点,一步步做出尝试。
更快:YOLO 使用的是 GoogLeNet 架构,比 VGG-16 快,YOLO 完成一次前向过程只用 85.2 亿次运算,而 VGG-16 要 306.9 亿次,但是 YOLO 精度稍低于 VGG-16。
二、V2主要改进方面
2.1 Darknet-19网络的使用
- 使用了BN,使得训练更加稳定;
- 增加卷积层,去掉最后的全连接层FC,因为全连接层会破坏空间的相对位置信息,而且增加复杂度。
2.2 pre-defined anchors
YOLO1,xywh的位置不固定,取值范围为是±无穷大。
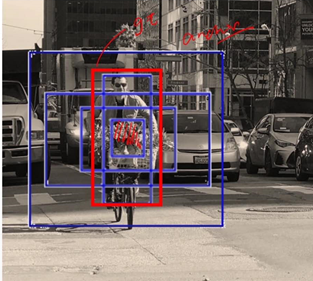
YOLO2使用anchors(标杆)的思维,给你一个大致范围,比如给你几个特定的标杆类型:比如使用5个标杆,根据IOU计算进行选取标杆。比如下图使用5个标杆(蓝色部分)
2.3 bias的应用
为避免Anchor Box回归导致模型不稳定的问题,作者在预测位置参数时采用了强约束方法:
- 对应 Cell 距离左上角的边距为(Cx,Cy),σ定义为sigmoid激活函数,将函数值约束到[0,1],用来预测相对于该Cell 中心的偏移(不会偏离cell);
- 预定Anchor(文中描述为bounding box prior)对应的宽高为(Pw,Ph),预测 Location 是相对于Anchor的宽高 乘以系数得到;
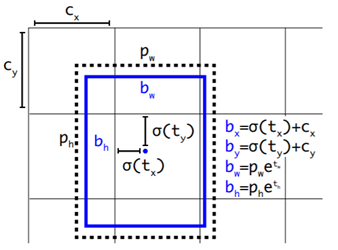
现在,神经网络在特征图(13 *13 )的每个cell上预测5个bounding boxes(聚类得出的值),同时每一个bounding box预测5个坐值,分别为 tx,ty,tw,th,to 其中前四个是坐标,to是置信度。如果这个cell距离图像左上角的边距为 (cx,cy)以及该cell对应box(bounding box prior)的长和宽分别为 (pw,ph) ,那么预测值可以表示为上图所示,这样对于较远距离的预测就能够得到很大的限制。
三、论文细节介绍
2.1 创新点-更准
1. Batch Normalization

Batch Normalization是2015年Google研究员在论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》一文中提出的,同时也将BN应用到了2014年的GoogLeNet上,也就是Inception-v2。
对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。批量规范化 正是基于这个假设的实践,对每一层输入的数据进行加工。
2. High Resolution Classifier
YOLO 从 224*224 增加到了 448*448,这就意味着网络需要适应新的输入分辨率。为了适应新的分辨率,YOLO v2 的分类网络以 448*448 的分辨率先在 ImageNet上进行微调,微调 10 个 epochs,让网络有时间调整滤波器(filters),好让其能更好的运行在新分辨率上,还需要调优用于检测的 Resulting Network。最终通过使用高分辨率,mAP 提升了 4%。
3. Convolutional With Anchor Boxes
之前的YOLO利用全连接层的数据完成边框的预测,导致丢失较多的空间信息,定位不准。作者在这一版本中借鉴了Faster R-CNN中的anchor思想,回顾一下,anchor是RNP网络中的一个关键步骤,说的是在卷积特征图上进行滑窗操作,每一个中心可以预测K种不同大小的建议框。
YOLO V1包含有全连接层,从而能直接预测 Bounding Boxes 的坐标值。 Faster R-CNN 的方法只用卷积层与 Region Proposal Network 来预测 Anchor Box 偏移值与置信度,而不是直接预测坐标值。作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。YOLOv2 去掉了全连接层,使用 Anchor Boxes 来预测 Bounding Boxes。同时去掉了网络中一个池化层,这让卷积层的输出能有更高的分辨率。收缩网络让其运行在 416*416 而不是 448*448。由于图片中的物体都倾向于出现在图片的中心位置,特别是那种比较大的物体,所以有一个单独位于物体中心的位置用于预测这些物体。YOLO 的卷积层采用 32 这个值来下采样图片,所以通过选择 416*416 用作输入尺寸最终能输出一个 13*13 的特征图。 使用 Anchor Box 会让精确度稍微下降,但用了它能让 YOLO 能预测出大于一千个框,同时 recall 达到88%,mAP 达到 69.2%。
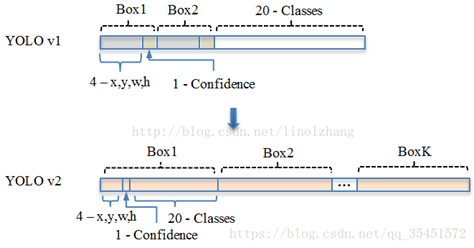
YOLO v1: S*S* (B*5 + C) => 7*7(2*5+20)
其中B对应Box数量,5对应 Rect 定位+置信度。每个Grid只能预测对应两个Box,这两个Box共用一个分类结果(20 classes),这是很不合理的临时方案。
YOLO v2: S*S*K* (5 + C) => 13*13*9(5+20)
4. Dimension Clusters——K-means(IOU)
之前 Anchor Box 的尺寸是手动选择的,所以尺寸还有优化的余地。 为了优化,在训练集的 Bounding Boxes 上跑一下 k-means聚类,来找到一个比较好的值。
如果我们用标准的欧式距离的 k-means,尺寸大的框比小框产生更多的错误。因为我们的目的是提高 IOU 分数,这依赖于 Box 的大小,所以距离度量的使用:
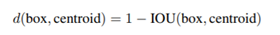
作者也做了实验来对比两种策略的优劣,使用聚类方法,仅仅5种boxes的召回率就和Faster R-CNN的9种相当。说明K-means方法的引入使得生成的boxes更具有代表性,为后面的检测任务提供了便利。
5.Direct location prediction
直接Anchor Box回归导致模型不稳定,对应公式也可以参考 Faster-RCNN论文,该公式没有任何约束,中心点可能会出现在图像任何位置,这就有可能导致回归过程震荡,甚至无法收敛:

针对这个问题,作者在预测位置参数时采用了强约束方法:
- 对应 Cell 距离左上角的边距为(Cx,Cy),σ定义为sigmoid激活函数,将函数值约束到[0,1],用来预测相对于该Cell 中心的偏移(不会偏离cell);
- 预定Anchor(文中描述为bounding box prior)对应的宽高为(Pw,Ph),预测 Location 是相对于Anchor的宽高 乘以系数得到;
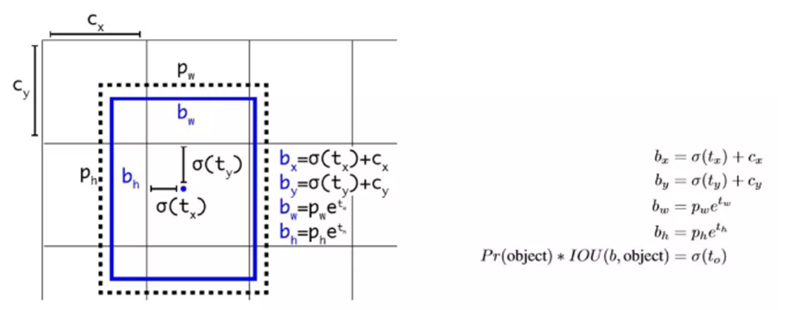
现在,神经网络在特征图(13 *13 )的每个cell上预测5个bounding boxes(聚类得出的值),同时每一个bounding box预测5个坐值,分别为 tx,ty,tw,th,to 其中前四个是坐标,to是置信度。如果这个cell距离图像左上角的边距为 (cx,cy)以及该cell对应box(bounding box prior)的长和宽分别为 (pw,ph) ,那么预测值可以表示为上图所示,这样对于较远距离的预测就能够得到很大的限制。
6. Fine-Grained Features
YOLO 修改后的特征图大小为 13*13,这个尺寸对检测图片中尺寸大物体来说足够了,同时使用这种细粒度的特征对定位小物体的位置可能也有好处。Faster-RCNN、SSD 都使用不同尺寸的特征图来取得不同范围的分辨率,而 YOLO 采取了不同的方法,YOLO 加上了一个 Passthrough Layer 来取得之前的某个 26*26 分辨率的层的特征。这个 Passthrough layer 能够把高分辨率特征与低分辨率特征联系在一起,联系起来的方法是把相邻的特征堆积在不同的 Channel 之中,这一方法类似与 Resnet 的 Identity Mapping,从而把 26*26*512 变成 13*13*2048。YOLO 中的检测器位于扩展后(expanded )的特征图的上方,所以他能取得细粒度的特征信息,这提升了 YOLO 1% 的性能。
7. Multi-Scale Training
作者希望 YOLOv2 能健壮地运行于不同尺寸的图片之上,所以把这一想法用于训练模型中。
区别于之前的补全图片的尺寸的方法,YOLOv2 每迭代几次都会改变网络参数。每 10 个 Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是 32,所以不同的尺寸大小也选择为 32 的倍数 {320,352…..608},最小 320*320,最大 608*608,网络会自动改变尺寸,并继续训练的过程。
这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,所以你可以在 YOLOv2 的速度和精度上进行权衡。
2.2 创新点-更快
YOLO 使用的是 GoogLeNet 架构,比 VGG-16 快,YOLO 完成一次前向过程只用 85.2 亿次运算,而 VGG-16 要 306.9 亿次,但是 YOLO 精度稍低于 VGG-16。
New Network——Darknet-19
YOLOv2使用了一个新的分类网络作为特征提取部分,参考了前人的先进经验,比如类似于VGG,作者使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化(global average pooling),把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。也用了batch normalization(前面介绍过)稳定模型训练。

最终得出的基础模型就是Darknet-19,如上图,其包含19个卷积层、5个最大值池化层(maxpooling layers )。Darknet-19运算次数为55.8亿次,imagenet图片分类top-1准确率72.9%,top-5准确率91.2%。
Training for classication
在训练时,把整个网络在更大的448*448分辨率上Fine Turnning 10个 epoches,初始学习率设置为0.001,这种网络达到达到76.5%top-1精确度,93.3%top-5精确度。
2.3 创新点-更强
交叉数据训练
作者提出了一种在分类数据集和检测数据集上联合训练的机制。使用检测数据集的图片去学习检测相关的信息,例如bounding box 坐标预测,是否包含物体以及属于各个物体的概率。使用仅有类别标签的分类数据集图片去扩展可以检测的种类。
作者通过ImageNet训练分类、COCO和VOC数据集来训练检测,这是一个很有价值的思路,可以让我们在公网上达到比较优的效果。 通过将两个数据集混合训练,如果遇到来自分类集的图片则只计算分类的Loss,遇到来自检测集的图片则计算完整的Loss。
但是ImageNet对应分类有9000种,而COCO则只提供80种目标检测,作者使用multi-label模型,即假定一张图片可以有多个label,并且不要求label间独立。
通过作者Paper里的图来说明,由于ImageNet的类别是从WordNet选取的,作者采用以下策略重建了一个树形结构(称为分层树):
- 遍历Imagenet的label,然后在WordNet中寻找该label到根节点(指向一个物理对象)的路径;
- 如果路径直有一条,那么就将该路径直接加入到分层树结构中;
- 否则,从剩余的路径中选择一条最短路径,加入到分层树。
这个分层树我们称之为 Word Tree,作用就在于将两种数据集按照层级进行结合。

分类时的概率计算借用了决策树思想,某个节点的概率值等于 该节点到根节点的所有条件概率之积。
最终结果是一颗 WordTree (视觉名词组成的层次结构模型)。用WordTree执行分类时,预测每个节点的条件概率。例如: 在"terrier"节点会预测:
如果想求得特定节点的绝对概率,只需要沿着路径做连续乘积。例如 如果想知道一张图片是不是"Norfolk terrier "需要计算:

另外,为了验证这种方法作者在WordTree(用1000类别的ImageNet创建)上训练了Darknet-19模型。为了创建WordTree1k作者天添加了很多中间节点,把标签由1000扩展到1369。训练过程中ground truth标签要顺着向根节点的路径传播:例如 如果一张图片被标记为"Norfolk terrier"它也被标记为"dog" 和"mammal"等。为了计算条件概率,模型预测了一个包含1369个元素的向量,而且基于所有"同义词集"计算softmax,其中"同义词集"是同一概念的下位词。
softmax操作也同时应该采用分组操作,下图上半部分为ImageNet对应的原生Softmax,下半部分对应基于Word Tree的Softmax:

通过上述方案构造WordTree,得到对应9418个分类,通过重采样保证Imagenet和COCO的样本数据比例为4:1。
2.4总结
通过对YOLOv1网络结构和训练方法的改进,提出了YOLOv2/YOLO9000实时目标检测系统。YOLOv2在YOLOv1的基础上进行了一系列的改进,在快速的同时达到state of the art。同时,YOLOv2可以适应不同的输入尺寸,根据需要调整检测准确率和检测速度(值得参考)。作者综合了ImageNet数据集和COCO数据集,采用联合训练的方式训练,使该系统可以识别超过9000种物品。除此之外,作者提出的WordTree可以综合多种数据集的方法可以应用于其它计算机数觉任务中。但是对于重叠的分类,YOLOv2依然无法给出很好的解决方案。