一 redo log
Oracle数据库中的三大核心文件分别是数据文件(data file)、重做日志(redo log)和控制文件(control file)。数据文件保证了数据库的持久性,是保存修改结果的地方;重做日志保证了数据库的可恢复性,是保存修改操作(包括对数据文件、控制文件等各类文件的修改)的地方;控制文件的作用是确定数据数据文件和重做日志文件的路径、数据库字符集、数据库当前的状态、检查点信息、保存其他文件头部的部分信息及提供备份信息资料库等。
重做日志可分为在线重做日志(online redo log)和归档重做日志(archive redo log),涉及的5个概念
--RBA(redo byte address)重做字节地址
--SCN(system change number)系统变更号
--DBA(相对数据块地址)
--数据块版本号(SCN+SEQ)
--检查点(checkpoint)
1 Redo record重做记录
重做日志是数据库的日记,记录着每一个对数据库的更改。日志中所记载的数据称为重做记录(redo record),是它提供了数据库具备了恢复能力。
只要对数据库做出任何形式的更改,就会在真正执行更改操作之前产生一条重做记录,该记录包含了一个或多个操作,记载了数据库如何从一个状态改变到另外一个状态的具体步骤,
往往包含对多个数据块的修改,也可能包含对控制文件和其他文件的修改。创建表、创建用户、插入数据、更新、删除数据,修改表空间属性、创建表空间、添加数据文件等任何变更都属于数据块状态的更改。
数据库状态的变更与事务两个概念不同。
SCN是内核产生的一个数,两部分6个字节组成。在正常工作的情况下,oracle不停地按照不同的频率将SCN写入不同的文件,在数据库关闭之后不担心丢失SCN的进度。判断数据文件是否需要恢复的指标就是SCN。
v$database视图的信息大部分来自控制文件,current_scn可以得到一个最新的SCN
select current_scn from v$database
union all
select current_scn from v$database;
select current_scn from v$database
union all
select dbms_flashback.get_system_change_number from dual;
每个能够修改数据库状态的操作,都会将从内核申请到的SCN标记在该操作对应的重做记录,这样两条重做记录之间就可以分清在时间顺序上其对应的操作,scn在文件中的表示
scn: 0x0000.0012fc0a
不能排除多个重做记录的SCN一样的情况,这说明有一个以上的修改操作分配到同样的SCN,由某些oracle内部操作导致的,所以oracle又创建了SUBSCN,用以标记同一个SCN下的多次变更,该值范围1~254,比如
scn: 0x0000.0012fc0a subscn:1 ,scn: 0x0000.0012fc0a subscn:2 分别表示同一个SCN的先后两个操作。
修改完成,SCN和SUBSCN会被保存在修改的数据块的头部,占7个字节。SUBSCN改称为SEQ(序列号)。这就是数据块版本号(SCN+SEQ),经常scn: 0x0000.0012fc0a seq:n形式出现在转储文件中。
如此一来,修改操作的SCN就出现在:重做日志和数据文件中。
RBA(重做字节地址),即重做记录的物理地址,4部分组成:日志线程号、日志序列号、日志文件块编号和日志文件块字节偏移量,长度为10个字节。
low cache rba:(0x6a.2650.0) on disk rba:(0x6a.266c.0)
查看
SYS@ orcl >select rowid,empno,job,ename from SCOTT.EMP where empno=7566; ROWID EMPNO JOB ENAME ------------------ ---------- --------- ---------- AAAVUyAAEAAAACVAAD 7566 MANAGER JONES
ROWID以base64的形式体现,前6位代表段号(AAAVUy),随后3位代表数据文件号(AAE),接下来6位代表数据块编号(AAAACV),最后的三位代表行号(AAD)
变更矢量
--AFN:绝对文件编号,对应v$datafile.file#字段
SYS@ orcl >select name from v$datafile where file#=3; NAME -------------------------------------------------------------------------------- /u01/app/oracle/oradata/orcl/undotbs01.dbf
--DBA:相对数据块地址,包含相对文件编号与数据块编号,4个字节。
---dbms_utility.data_block_address_file()
--SCN和SEQ:数据块当前的(被修改之前的)的版本号
第一个矢量负责创建事务表,而第二个矢量负责在事务表中创建具体的撤销数据。
日志缓冲(log buffer)是重做记录在内存中的临时保存点,大小由参数
SYS@ orcl >show parameter log_buffer NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_buffer integer 6479872
重做记录进入日志缓冲之后由后台进程LGWR将其写入在线重做日志,只要符合下面其中一个条件,LGWR就会把log buffer中的所有重做记录推入在线日志中
--1 每隔3秒
--2 日志缓冲内有1MB的日志记录
--3 日志缓冲1/3写满
--4 执行提交(commit)命令
--5 在DBWn进程中将脏数据块写入数据文件之前。
2 Online redo log 在线重做日志
在线重做日志是重做记录在磁盘上的临时保存点,是数据库正常打开不可缺少的文件之一,之所以是临时的,原因是LGWR会不断的覆盖在线日志,它的作用是支持实例恢复和介质恢复。
Oracle出于管理性的考虑把重做日志分为:在线日志和归档日志
在线日志是数据库启动时一定要被打开的文件,而归档日志则不必,如果在线日志损坏,db将无法启动,因为允许被LGWR重写覆盖,除非手动修改,其数量和大小都不会变化而归档日志不管理,则会越来越多,视图v$log,v$logfile
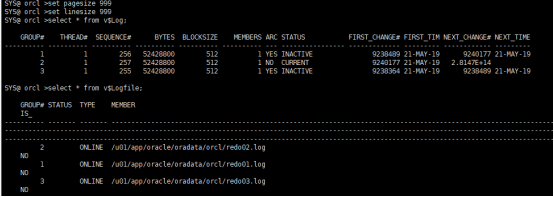
SQL>select lg.group#,lg.members,lf.member from v$log lg,v$logfile lf where lg.group#=lf.group# order by group#; 1 1 /u01/app/oracle/oradata/orcl/redo01.log 2 1 /u01/app/oracle/oradata/orcl/redo02.log 3 1 /u01/app/oracle/oradata/orcl/redo03.log
这里有3个日志组,一般建议每组至少2个在线日志互为镜像备份,不要把同组的日志放在易单点损坏的存储上,添加日志组成员
--alter database add logfile member '/u01/app/oracle/oradata/orcl/redo11.log' to group 1;
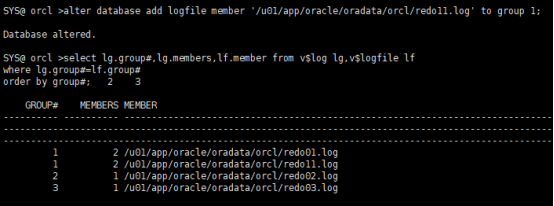
SYS@ orcl >select group#,sequence#,status from v$log; GROUP# SEQUENCE# STATUS ---------- ---------- ---------------- 1 256 INACTIVE 2 257 CURRENT ##正在写入的日志组 3 255 INACTIVE 观察日志组的使用情况, SYS@ orcl >alter system switch logfile; System altered. SYS@ orcl >select group#,sequence#,status from v$log; GROUP# SEQUENCE# STATUS ---------- ---------- ---------------- 1 256 INACTIVE 2 257 ACTIVE 3 258 CURRENT
3 Checkpoint 检查点
数据库中的任何一个更改操作,ddl、dml会产生两种不同类型的数据
--重做记录,其目的是确保数据库具有可恢复性
--另一种是被修改的数据库本身(撤销数据和修改数据),其目的是确保数据库的持久性
这两类数据的临时存储地点和永久存储地点均不相同
重做记录记载了该更改需要修改哪些数据块及如何更改,重做记录在日志缓冲区产生由LGWR写入在线日志,最后在线日志由ARCn归档进程备份为归档日志。
被修改的数据块称为脏块,产生了脏块临时保存区域database buffer cache,这些数据块根据重做记录的RBA按顺序在一个检查点的队列中,由进程DBWn写入数据文件,数据块从检查点中踢出。数据块内存中的状态和数据文件中的状态一致。
DBWn进程的频率低于LGWR,保证重做记录先于对应的脏数据块写入持久层,所以,令同一个更改产生的重做记录为R、脏数据块为D,那么,在LGWR没有把R写入在线日志的情况下,
oracle是不允许DBWn把D先行写入数据文件的,即便是DBWn首先发起请求,也必须等待LGWR先清空日志缓冲。--即数据更改必须先写online redo log再写datafile。
这样数据文件的内存永远没有在线日志的内容更新块,在数据库打开的情况下,数据文件永远比在线日志“旧”。
为了标识数据文件旧到什么程度,oracle使用了检查点,检查点是一系列操作的集合,其最终目的是将检查点目标写入数据文件头部和控制文件,检查点目标就是某条重做记录,以其头部中的RBA及SCN表示。
参与检查点的进程主要包括LGWR、DBWn和CKPT,分为完全检查点和增量检查点。
发起一次完全检查点主要步骤:
--1 在日志缓冲中确定当前的重做记录,提取RBA和SCN作为检查点的目标
--2 LGWR清空log buffer,将重做记录写入online redo log。
--3 DBWn将检查点目标(RBA与SCN)产生的及检查点目标之前产生的脏数据块,按RBA的顺序写入数据文件
--4 最后,CKPT进程将检查点目标(RBA与SCN)写入数据文件头部和控制文件。
这样,数据文件头部的检查点目标(RBA与SCN)能提供一下两个重要信息:
--1 读取其中的scn与online redo log中的scn做比较,就可以知道数据文件是否需要恢复,检查点目标中的scn简称检查点SCN。
--2 如果该数据文件需要恢复,RBA用来表示从哪个日志中那一项重做记录开始恢复,检查点目标中的RBA简称检查点RBA.
完全检查点发生的时机:
--1 执行shutdown,shutdown norma,shutdown immediate,shutdown transaction命令关闭数据库
--2 执行alter system checkpoint命令
--3 LGWR切换online redo log,不论是因为日志写满还是手工执行alter system switch logfile命令
--4 执行部分表空间维护命令,比如alter tablespace test offine|online|begin backup|end backup|read only| read write,但此类完全检查点并不完整,DBWn仅将特定表空间内的所有脏数据块写回到数据文件而已。
完全检查点高优先级:shutdown(除shutdown abort外)与alter system checkpoint命令发起的就是高优先级的检查点,检查点没有完成,命令不会返回。
SYS@ orcl >alter system checkpoint; System altered. SYS@ orcl >alter system switch logfile; System altered. Tue May 21 14:49:02 2019 Thread 1 advanced to log sequence 259 (LGWR switch) Current log# 1 seq# 259 mem# 0: /u01/app/oracle/oradata/orcl/redo01.log Current log# 1 seq# 259 mem# 1: /u01/app/oracle/oradata/orcl/redo11.log Tue May 21 14:49:02 2019 Archived Log entry 172 added for thread 1 sequence 258 ID 0x5b6f4ecf dest 1: 查看v$datafile_header字段,可以得到最近一次已经完成的完全检查点SCN SYS@ orcl >select file#,checkpoint_change# from v$datafile_header; FILE# CHECKPOINT_CHANGE# ---------- ------------------ 1 9249678 2 9249678 3 9249678 4 9249678 5 9249678 SYS@ orcl >select file#,checkpoint_change# from v$datafile; FILE# CHECKPOINT_CHANGE# ---------- ------------------ 1 9249678 2 9249678 3 9249678 4 9249678 5 9249678
增量检查点,发起时机由oracle自动控制,也可以修改FAST_START_MTTR_TARGET初始化参数影响它的频率,一次增量检查点主要步骤:
--1 首先确定一条重做记录(不是当前的),提取RBA和SCN号作为检查点的目
--2 LGWR情况log buffer,将重做记录写入online redo log
--3 DBWn将检查点目标(RBA与SCN)产生的及检查点目标之前的脏数据按RBA顺序写入数据文件
--4 CKPT将检查点目标(RBA与SCN)写入控制文件--注意这里与完全检查点,这里只写了控制文件
增量检查点会在告警日志中写
Incremental checkpoint up to RBA [ ],current log tail at RBA [ ]
将初始化参数log_checkpoint_to_alert为true再观察
增量检查点的意义:
--1 减少发生完全检查点时DBWn进程的工作负担
--2 提高实例恢复的速度。
4 实例恢复
实例是一系列oracle内存结构和进程的总称,这些结构是访问数据库各种文件的方法,没有它们,数据库将不能被访问,所谓启动数据库就是指启动实例。
当通过shutdown (abort除外)关闭数据库,oracle会先发起一个完全检查点,此时数据库不允许任何变更,log buffer被清除,LGWR进程停止,online redo log更新停止,数据库缓存中的脏数据完全写入数据文件。
如果实例崩溃(断点)或者shutdown abort强制关闭数据库,没来及完成一次完全检查点。在下一次启动数据库时候,只要控制文件、redo log和数据文件没有损坏(只是不同步而已),
为了使数据库能打开,oracle会自动发起称为实例恢复的操作同步数据文件,会在alert中写入
Begining crash recover of
...
Completed crash recover at
实例恢复(instance recovery)的定义是在启动数据库时发现文件不同步后,自动利用redo log中的重做记录自动对旧的数据文件进行修复的过程,分前滚和回滚
实例恢复的第一步前滚,将数据文件头部中的检查点SCN和当前redo log中最新的重做记录的SCN做对比,得知该数据文件是否为旧的,如果判断为旧,即不同步,前滚发起
前滚--读取数据文件头部检查点RBA,将RBA在redo log文件中找到并作为前滚起点,一直利用完redo log中的最后一条记录为止。已经提交的变更及没有提交的变更都写入数据文件
回滚--需要撤销数据块,即便数据库强制停止时,撤销数据块没有及时写回数据文件(属于撤销表空间),自动前滚也会将他们回复出来
--1 startup命令--手动
--2 参数文件打开,实例启动
--3 控制文件被打开
--4 校验数据文件和redo log是否同步(控制文件也参与校验),结果为否
--5 自动前滚
--6 打开数据库
--7 自动回滚
牢记实例恢复的一个规定:只能使用在线日志(redo log),并且不要忘记LGWR”喜新厌旧”的品性,以循环覆盖的方式写redo log。
在线日志redo log三种状态:current代表lgwr正在写的日志组,active最近一次完全检查点 的RBA(SCN)小于该日志中最后一个重做记录的RBA(SCN),inactive指最近一次完全检查点的RBA(SCN)大于该日志中最后一个重组记录的RBA(SCN).
只有inactive的redo log是实例恢复需要的,active和current都是实例恢复所必需的。
如果LGWR的下一个日志状态时active,那么LGWR进程会挂起,alert日志报checkpoint not complete.oracle会立刻发起一个新的高优先级检查点,进一步推进BRA(SCN).除非发生介质问题、文件损坏。
如果只是断点或实例崩溃,在线日志一定和数据文件是连续的。Oracle总能依靠实例恢复能自动回到完整一致的状态。
通过v$log.status直接了解到假如现在断点,实例恢复需要哪些日志
select lg.group#,lg.members,lg.status from v$log lg,v$logfile lf where lg.group#=lf.group# order by group#;
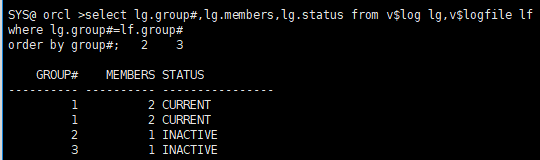
根据结果,应该是日志组1,日志组2和3实例恢复不需要。
5 归档重做日志
从介质恢复的角度,在线日志就有可能不行,因为介质恢复应对的是数据文件损坏的情况,一旦数据文件损坏,往往第一步操作是从备份中将损坏的文件还原,
文件头的检查点scn也就回到备份的时候,如果超过了redo log中的重做记录范围,就无法修复,通过视图观察到lgwr写redo log的速度。
SYS@ orcl >select group#,sequence#,status,to_char(first_time,'yyyy-mm-dd hh24:mi:ss') first_time from v$log; GROUP# SEQUENCE# STATUS FIRST_TIME ---------- ---------- ---------------- ------------------- 1 259 CURRENT 2019-05-21 14:49:02 2 257 INACTIVE 2019-05-21 10:00:58 3 258 INACTIVE 2019-05-21 11:16:08
简单的说,归档日志就是redo log的备份,由后台进程ARCn在LGWR覆盖之前将redo log复制而来。在数据库打开时不会打开,不允许覆盖,在没有维护的情况下数量不断增加,是重做记录的永久保存点。主要作用是支持介质恢复和rman在线备份。
开启归档模式,如何开启归档模式这里不做介绍
SYS@ orcl >select log_mode from v$database; LOG_MODE ------------ ARCHIVELOG SYS@ orcl >select group#,sequence#,status,archived from v$log; GROUP# SEQUENCE# STATUS ARC ---------- ---------- ---------------- --- 1 259 CURRENT NO 2 257 INACTIVE YES ##已经归档 3 258 INACTIVE YES ##已经归档 --shutdown immediate --startup mount --alter database archivelog --alter database open
归档日志保存的路径由参数log_archive_desc_N和db_recovery_file_dest指定,N最大为31,1~10为本地归档,其他为远程归档
SYS@ orcl >show parameter log_archive_dest NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_archive_dest string log_archive_dest_1 string location=/u01/app/oracle/arch --SQL> alter system set log_archive_dest_1=’location=/u01/app/oracle/arch’; 归档文件的格式,该参数一定要包含%t,%s和%r SYS@ orcl >show parameter log_archive_format NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_archive_format string %t_%s_%r.db select sequence#,first_change#,next_change#,name from v$archived_log;

6 介质恢复
在文件有物理损坏的情况下,将其还原、恢复,最后使数据库得以正常打开的操作称为介质恢复。
实例恢复的前提是数据文件、控制文件和在线日志均没有损坏的情况
比如,system01.dbf文件损坏
SQL> startup ORACLE instance started. Total System Global Area 784998400 bytes Fixed Size 2257352 bytes Variable Size 511708728 bytes Database Buffers 264241152 bytes Redo Buffers 6791168 bytes Database mounted. ORA-01122: database file 1 failed verification check ORA-01110: data file 1: '/u01/app/oracle/oradata/orcl/system01.dbf' ORA-01210: data file header is media corrupt
#只能启动到mount阶段,提示需要介质恢复
首先查看所有数据文件的检查点SCN
SYS@ orcl >select file#,name,checkpoint_change# from v$datafile;
冻结1号文件的头部,oracle会对1号文件发起完全检查点,属于1号文件的脏数据块将全部写入磁盘
SYS@ orcl >alter tablespace system begin backup; Tablespace altered. SYS@ orcl >col name format a50 SYS@ orcl >select file#,name,checkpoint_change# from v$datafile; FILE# NAME CHECKPOINT_CHANGE# ---------- -------------------------------------------------- ------------------ 1 /u01/app/oracle/oradata/orcl/system01.dbf 9252840 2 /u01/app/oracle/oradata/orcl/sysaux01.dbf 9249773 3 /u01/app/oracle/oradata/orcl/undotbs01.dbf 9249773 4 /u01/app/oracle/oradata/orcl/users01.dbf 9249773 5 /u01/app/oracle/oradata/orcl/test01.dbf 9249773 然后用os命令备份 [oracle@DSI ~]$ cp /u01/app/oracle/oradata/orcl/system01.dbf /home/oracle/systm01.dbf SYS@ orcl >alter tablespace system end backup; ##解冻 Tablespace altered. 然后在把刚备份的system01复制原处,此时alter database open就会报错,因为scn不一致。 SYS@ orcl >shutdown immediate; [oracle@DSI ~]$ cp /home/oracle/systm01.dbf /u01/app/oracle/oradata/orcl/system01.dbf SYS@ orcl >startup; ORACLE instance started. Total System Global Area 784998400 bytes Fixed Size 2257352 bytes Variable Size 511708728 bytes Database Buffers 264241152 bytes Redo Buffers 6791168 bytes Database mounted. ORA-01113: file 1 needs media recovery ORA-01110: data file 1: '/u01/app/oracle/oradata/orcl/system01.dbf' 查看还原1号文件的scn SYS@ orcl >select file#,change# from v$recover_file; FILE# CHANGE# ---------- ---------- 1 9252840 查看非INACTIVE状态的redo log的低位SCN SYS@ orcl >select min(first_change#) from v$log where status !='INACTIVE'; MIN(FIRST_CHANGE#) ------------------ 9249773 还原的scn大于非inactive的redo log的低位scn 查看归档最小的scn号 SYS@ orcl >select min(first_change#) from v$archived_log; MIN(FIRST_CHANGE#) ------------------ 1121577 这里1121577明显小于9252840,可以恢复 SYS@ orcl >recover automatic datafile 1; Media recovery complete. SYS@ orcl >alter database open; Database altered. SYS@ orcl >select file#,name,checkpoint_change# from v$datafile; FILE# NAME CHECKPOINT_CHANGE# ---------- -------------------------------------------------- ------------------ 1 /u01/app/oracle/oradata/orcl/system01.dbf 9253054 2 /u01/app/oracle/oradata/orcl/sysaux01.dbf 9253054 3 /u01/app/oracle/oradata/orcl/undotbs01.dbf 9253054 4 /u01/app/oracle/oradata/orcl/users01.dbf 9253054 5 /u01/app/oracle/oradata/orcl/test01.dbf 9253054
介质恢复的步骤
--1 手动还原,数据文件遭到破坏,导致实例恢复这个流程无法进行,所以第一步是将之前备份的数据文件复制到原位置,完整性没有问题,但是其头部的检查点scn与redo log的不连续,实例恢复还是无法进行,此时不能使用alter database open打开
--2 手动恢复,sqlplus的recover命令能够分析数据文件头部中的检查点scn和RBA,了解数据文件是否需要恢复、从哪里开始恢复,并且能够读取到归档日志和redo log中的重做记录,将变更重做,把数据文件中丢失的变更重新找回。
--3 自动回滚,在执行alter database open打开数据库后自动执行
介质恢复需要人为干预的只有两部分:还原操作(restore)和恢复操作(recover)
SYS@ orcl >alter system dump logfile '/u01/app/oracle/oradata/orcl/redo01.log' dba min 5 319 dba max 5 400; System altered. SYS@ orcl >select value from v$diag_info where name='Default Trace File'; VALUE ----------------------------------------------------------------- /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_10017.trc