爬虫比较关键的一步就是解析下载后的网页,我这几天在用的是requests-html库自带的xpath方法,但是我在爬取一个小说页面的时候遇到了困难,这是一个静态页面,我通过右键检查复制xpath路径,但是却得到了一个空对象,打开源代码,对比右键检查的代码,我发现两者之间居然不相同。有点意思的坑
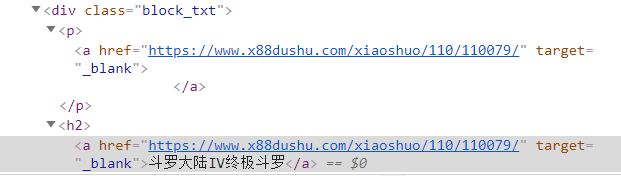

记录一下,免得再踩坑。
爬虫比较关键的一步就是解析下载后的网页,我这几天在用的是requests-html库自带的xpath方法,但是我在爬取一个小说页面的时候遇到了困难,这是一个静态页面,我通过右键检查复制xpath路径,但是却得到了一个空对象,打开源代码,对比右键检查的代码,我发现两者之间居然不相同。有点意思的坑
记录一下,免得再踩坑。