一、Hbase集成Phoneix
1、下载
在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本。本地使用的1.2.5,故下载的apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz包。
2、上传并解压
tar -zxvf apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz
mv apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz phoenix
3、将phoenix-core-4.13.1-HBase-1.2.jar、phoenix-4.13.1-HBase-1.2-server.jar发送到hregionserver所在的hbase的lib目录下:
cp phoenix-core-4.13.1-HBase-1.2.jar /mnt/hbase/lib/ scp phoenix-core-4.13.1-HBase-1.2.jar slave01:/mnt/hbase/lib/ scp phoenix-core-4.13.1-HBase-1.2.jar slave02:/mnt/hbase/lib/ cp phoenix-4.13.1-HBase-1.2-server.jar /mnt/hbase/lib/ scp phoenix-4.13.1-HBase-1.2-server.jar slave02:/mnt/hbase/lib/ scp phoenix-4.13.1-HBase-1.2-server.jar slave01:/mnt/hbase/lib/
4、重启Hbase
start-hbase.sh
5、启动phoneix
# 进入phoenix下的bin目录 cd phoenix/bin # 启动 ./sqlline.py master:2181
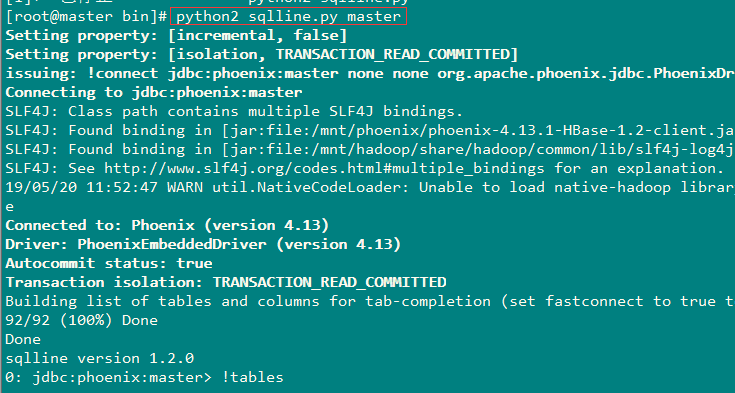
6、创建一张简单的 表测试
0: jdbc:phoenix:master> create table user(id varchar primary key,name varchar,age varchar,phone varchar,email varchar); No rows affected (1.47 seconds)
7、插入数据
upsert into user values('1001','caocao','26','13800000000','caocao@163.com'); upsert into user values('1002','liubei','24','13800000001','liubei@163.com'); upsert into user values('1003','guanyu','23','13800000002','guanyu@163.com'); upsert into user values('1004','zhangfei','22','13800000003','zhangfei@163.com'); upsert into user values('1005','sunquan','20','13800000004','sunquan@163.com');
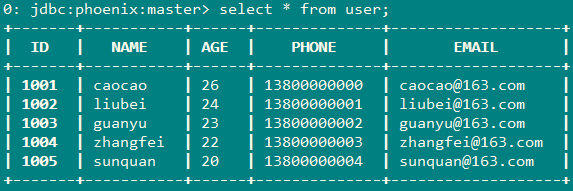
8、通过hbase shell查看


因此配置完成了。。。
二、Phoneix集成Hbase创建二级索引
索引最常用的三个类型:覆盖索引、全局索引、本地索引
1、配置(如果使用的phoneix版本在4.8之后则不需要如下配置,我这里使用的是4.13因此不需要配置)
在每一个RegionServer的hbase-site.xml中加入如下的属性
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value>
</property>
在每一个Master的hbase-site.xml中加入如下的属性(phoneix版本在4.8之后不用添加):
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property
2、使用phoneix创建表、导入数据(数据量10W条)
https://www.cnblogs.com/yfb918/p/10895754.html
3、覆盖索引(Covered Indexes)
说明:只需要通过索引就能返回所要查询的数据,所以索引的列必须包含所需查询的列(select 的列和where的列)
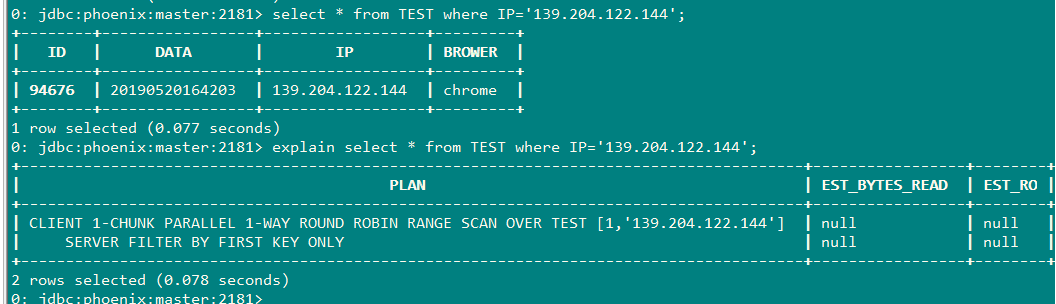
3.1不带索引的查询,查询ip='139.204.122.144'(普通查询)
由于数据量不大,经过多次查询,查询时间在0.13s-0.150s左右
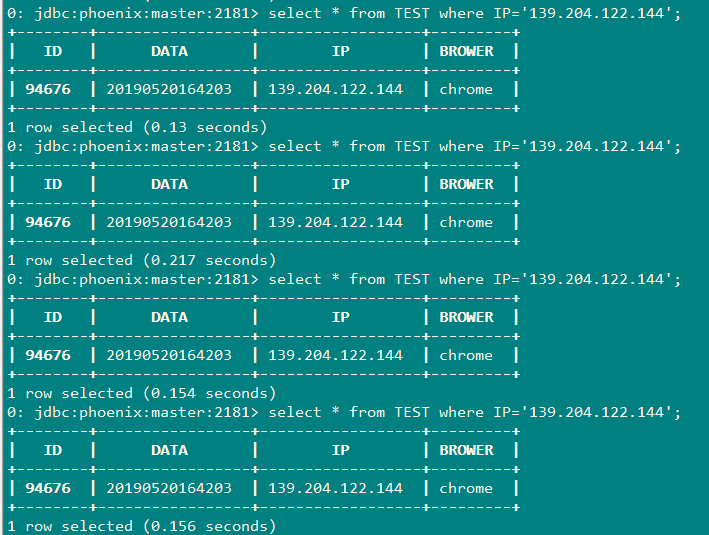
3.1.1查询计划
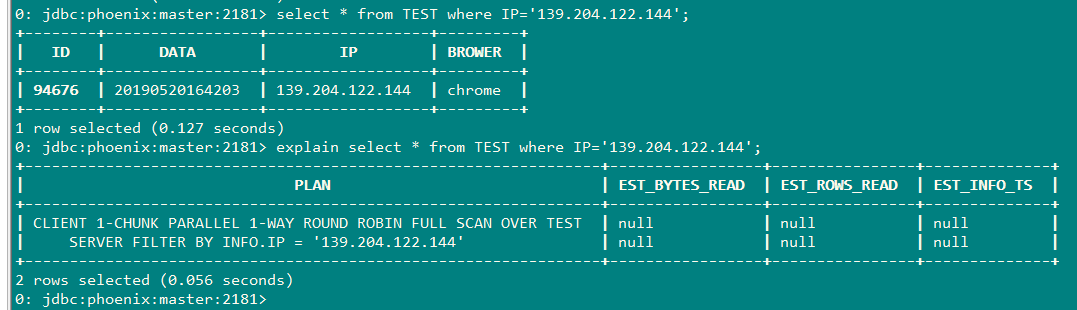
由图看出该执行过程线进行了full scan(全表扫描)再通过Filter(过滤器)进行筛选数据。
3.2创建基于ID的覆盖索引并绑定IP列上的数据
CREATE INDEX COVERINDEX ON TEST(ID) INCLUDE(IP)
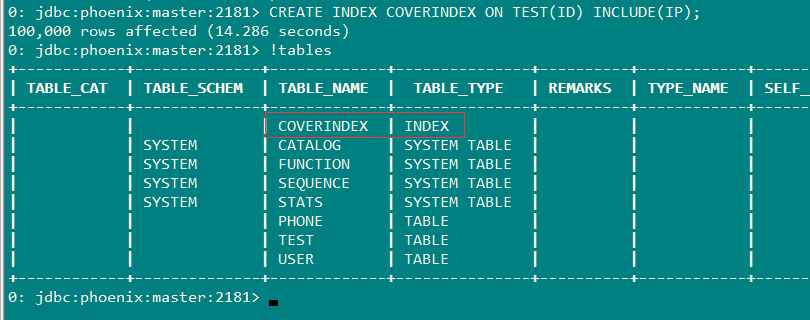
当我要通过ID来查询IP时就直接可以从索引上取回数据而无需先得到索引再去数据表中查询数据
查询语句:
说明:这里ID=''94676"正是上面IP=‘139.204.122.144’的该条数据
SElECT IP FROM TEST WHERE ID='94676';
经过多次查询:耗时在:0.016s-0.02s左右

3.2.1查询计划

3.3测试后删除索引

4、全局索引(Global Indexes)
全局索引适用于多读少写的场景,在写操作上会给性能带来极大的开销,因为所有的更新和写操作都会引起索引的更新,在读取数据时,Phoneix将通过索引表达式来快速查询结果。
在使用全局索引之前需要在每个RegionServer上的hbase-site.xml添加如下属性:
<property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property>
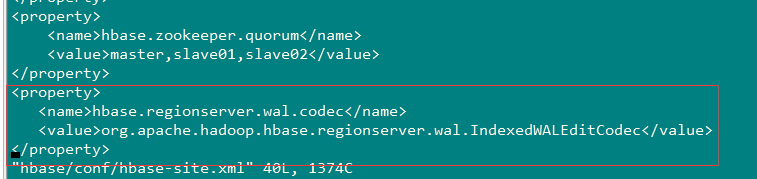
4.1这里在IP字段上创建索引
CREATE INDEX IPINDEX ON TEST(IP);

以下查询才会使用到索引
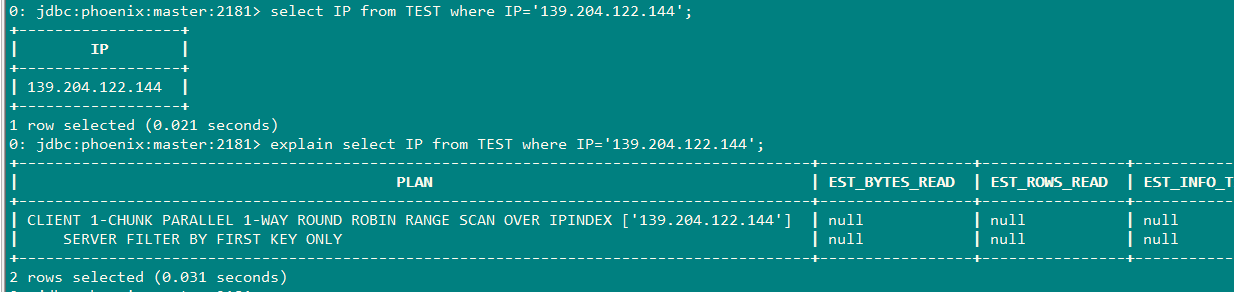
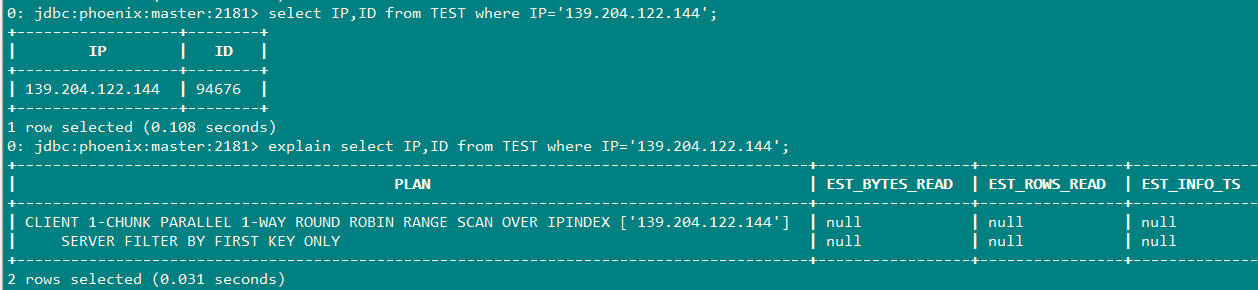

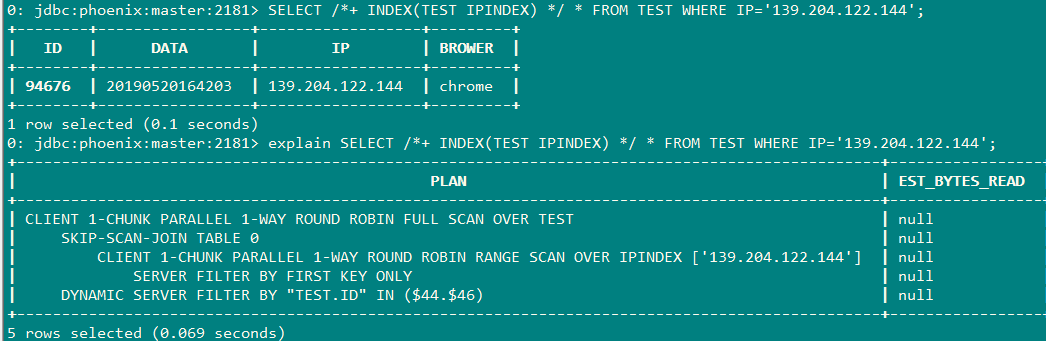
下面这个是采用强制索引的方式:
以下查询不会使用到索引
语句一:
select IP,BROWER from TEST where IP='139.204.122.144';
虽然IP是索引字段,但是BROWER不是索引字段,所以不会使用到索引
语句二:
select BROWER from TEST where IP='139.204.122.144';
BROWER不是索引字段,其他同理
但是使用以下几种方式,执行查询语句二时也将使用到索引
a、创建包含字段BROWER的覆盖索引
CREATE INDEX BROWERINDEX ON TEST(IP) INCLUDE(BROWER);
b、强制使用索引
SELECT /*+ INDEX(INDEXIP,IPINDEX) */ IP FROM TEST WHERE IP='139.204.122.144';
如果IP是索引字段,那么就会直接从索引表中查询
c、使用本地索引
CREATE LOCAL INDEX BROWERINDEX ON CSVTABLES(BROWER);
5、本地索引(Local indexes)
本地索引适用于写多读少,空间有限的场景,和全局索引一样,Phoneix在查询时会自动选择是否使用本地索引,使用本地索引,为避免进行写操作所带来的网络开销,索引数据和表数据都存放在相同的服务器中,当查询的字段不完全是索引字段时本地索引也会被使用,与全局索引不同的是,所有的本地索引都单独存储在同一张共享表中,由于无法预先确定Region的位置,所以在读取数据时会检查每个Region上的数据因而带来一定性能开销。
在使用本地索引之前需要在hbase master的hbase-site.xml上添加一下配置:
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>
创建本地索引
CREATE LOCAL INDEX IPINDEX ON TEST(IP);
查询