GraphQL 是一种针对 Graph(图状数据)进行查询特别有优势的 Query Language(查询语言),所以叫做 GraphQL。它跟 SQL 的关系是共用 QL 后缀,就好像「汉语」和「英语」共用后缀一样,但他们本质上是不同的语言。GraphQL 跟用作存储的 NoSQL 没有必然联系,虽然 GraphQL 背后的实际存储可以选择 NoSQL 类型的数据库,但也可以用 SQL 类型的数据库,或者任意其它存储方式(例如文本文件、存内存里等等)。
GraphQL 最大的优势是查询图状数据。GraphQL 是 Facebook 发明的,我可以用 Facebook 做例子。例如说,你要在 Facebook 上打开我的页面查看我的信息,你需要请求如下信息:
- 我的名字
- 我的头像
- 我的好友(按他们跟你的亲疏程度排序取前 6):
- 好友 1 的名字、头像及链接
- 好友 2 的名字、头像及链接
- ……
- 我的照片(按时间倒序排序取前 6):
- 照片 1 及其链接
- 照片 2 及其链接
- ……
- 我的帖子(按时间倒序排序):
- 帖子 1:
- 帖子 1 内容
- 帖子 1 评论:
- 帖子 1 评论 1:
- 帖子 1 评论 1 内容
- 帖子 1 评论 1 作者名字
- 帖子 1 评论 1 作者头像
- 帖子 1 评论 2:
- ……
- ……
- 帖子 2:
- 帖子 2 内容
- 帖子 2 评论:
- ……
- ……
这是一个超级复杂的树状结构,如果我们用常见的 RESTful API 涉及,每个 API 负责请求一种类型的对象,例如用户是一个类型,帖子是另一个类型,那就需要非常多个请求才能把这个页面所需的所有数据拿回来。而且这些请求直接还存在依赖关系,不能平行地发多个请求,例如说在获得帖子数据之前,无法请求评论数据;在获得评论数据之后,才能开始请求评论作者数据。
如何解决这种问题?一个简单粗暴的办法是专门写一个 RESTful API,请求上述树状复杂数据。但很快新问题就会出现。现在 Facebook 想要做一个新的产品,例如说是宠物,然后要在我的页面上显示我的宠物信息,那这个 RESTful API 的实现就要跟着改。
GraphQL 能够很好地解决这个问题,但前提是数据已经以图的数据结构进行保存。例如上面说到的用户、帖子、评论是顶点,而用户跟用户发过的帖子存在边的关系,帖子跟帖子评论存在一对多的边,评论跟评论作者存在一对一的边。这时候如果新产品引入了新的对象类型(也就是顶点类型)和新的边类型,那没有关系。在查询数据时用 GraphQL 描述一下要查询的这些边和顶点就行,不需要去改 API 实现。
说完了 GraphQL 是什么和能解决什么问题,说说不够好的地方吧。
第一,Facebook 从来没有公开自己的 GraphQL 后端设计,使得大家必需要用第三方的,但体验显然不如我们在 Facebook 内部使用 GraphQL 好。我上面说了,数据必需已经以图的数据结构进行存储才有优势。Facebook 内部有非常好的后端做好了这件事情,而且还内置了基于隐私设置的访问控制。例如说你发的帖子有些是所有人可见的、有些是好友可见的、有些是仅同事可见的,我在打开你的页面时 Facebook 有一个中间层保证了根据我和你的关系我只能看到我该看到的帖子。GraphQL 在这一层之上,所以无论 GraphQL 怎么写我都不可能看到我不该看到的信息。
第二,并不是所有场景都适用于 GraphQL 的,有些很简单的事情就应该用 RESTful API 来实现。Facebook 内部用户增长部门的很多 API 都还不是 GraphQL,因为没必要迁移到 GraphQL。用户增长部门的 API 处理新用户注册、填写短信验证码之类的事情,这些事情都是围绕着一个用户的具体某项或多项信息发生的,根本没有任何图的概念。可以强行写作 GraphQL,但得不到显著的好处。既然老的 API 早就写好了,需要的时候做一些小改动,但没必要重写。
第三,GraphQL 尽管查询的数据是图状数据结构,但实际获得的数据视图是树状数据结构。每一个 GraphQL 查询或更新都有自己的根节点,然后所有的数据都是从根结点展开出去的。查询后获得的数据如果要在前端重新变回图的状态,那前端就不能简单地缓存查询得到的数据,必须用对用的 GraphQL 存储库,然后通过顶点的 ID 把不同节点之间的某些边重新连接起来。


没有关系,QL = Query Language, 是查询语言的简称,但它其实是一种规范~ 更多的是类比于 RESTful API。正好最近总结了一篇文章,暂时粘贴过来~
GraphQL 浅谈,从理解 Graph 开始
前言
GraphQL is a data query language developed internally by Facebook in 2012 before being publicly released in 2015. It provides an alternative to RESTful architectures. —— from wikipedia.
GraphQL 是 Facebook 于 2012 年在内部开发的数据查询语言,在 2015 年开源,旨在提供 RESTful 架构体系的替代方案。
掘金翻译计划在今年 10 月上线了 GraphQL 中文官网,最近它的讨论和分享逐渐增多。其实阿里内不少业务线早有尝试和分享,听闻基于 GraphQL 再造了个 TQL。也在其开源的Node.js企业级框架egg中,发布了对应的 plugin。感觉这是一个让广大(前端)开发者(重新)认识学习GraphQL的好机会,就让我们来回顾一下它~
从 Graph 字面开始
先看官网的解释~
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。
总结的稍显高深,简单拆解一下:
SQL (Structured Query Language) 是结构化查询语言的简称。所以Graph+ QL =图表化(可视化)查询语言,是一种描述客户端如何向服务端请求数据的API语法,类似于 RESTful API 规范。
注:不要联想到 MySQL、NoSQL,它不是图形数据库,比如 Neo4j。
GraphQL 有配套的数据库服务, graphcool 可以部署在 Docker 上或运行在基于 BaaS(Backend as a Service) 的 Graphcool Cloud。但它不依赖任何数据库,且能和任何后端(SQL、MongoDB、Redis 等)一起使用,也可以包裹在 RESTful API 之上。
GraphQL 的特性
它定义了一套类型系统(Type System),类似于持续演进(相互借鉴)的Flow和TypeScript,用来描述你的数据,先看官网的例子(细节再议)
项目的type
type Project {
name: String
tagline: String
contributors: [User] // 数组表示多个,type 为下面的 User
}
type User {
name: String
photo: String,
friends: [User] // User 的朋友们, type 还是 User
}
接下来你可以把GraphQL的查询语言(Queries)当成是没有值只有属性的对象,返回的结果就是有对应值的对象,也就是标准的JSON。
请求你所要的数据 // 基于 Queries
{ // 查找 name 为 GraphQL 的 project
project(name: "GraphQL") {
tagline
}
}
得到可预测的结果
{ // 返回 json
"project": {
"tagline": "A query language for APIs"
}
}
虽然 project 在类型系统里定义了三个字段,但我们(客户端)只需要 tagline 这个字段,服务端就只返回这个字段,而 contributors 里的 User 和其对应字段,本次查询(Query)并不关心。这个 demo 看似简单,其实带来了很多特性~
- 强类型:
GraphQL与 C 和 Java 等后端语言相得益彰,服务端能对响应的形状和性质做出一定保证,而RESTful是弱类型的,缺少机器可读的元数据; - 分工:
GraphQL让服务端定义好支持哪些Queries,把对数据的Query需求下放到客户端管理,分工明确的同时保持对 API 的聚焦; - 分层:
GraphQL的Query本身是一组分层的字段,查询就像返回的数据一样,是一种产品(工程师)描述数据和需求的自然方式;(PS:部分翻译的,国外好像都把产品叫做 Product Engineers 而不是 Product Manager。感觉在吐槽的样子) - 预测性:
GraphQL的Query只返回客户端要求的内容,没有任何冗余(不浪费流量),而且它只有一个接口地址,由此衍生了另一个特性; - 兼容性:需求变动带来的新增字段不影响老客户端,服务端再也不需要版本号了,极大简化了兼容问题;(App 通常是 1-2 周的固定周期发版,在原生应用不强制升级的世界里,会出现用户 1-2 年都不升级的情况。 这意味可能同时有 52 个版本的客户端查询我们的服务端,而在 Fackbook 中 GraphQL API 曾支持了横跨 3 年的移动端)
- 自检性:
GraphQL能在执行Query之前(即在开发时)提供描述性错误消息,在给定查询的情况下,工具可以确保其句法是正确有效的,这使得构建高质量的客户端变得更加容易; - Doc & Mock:
GraphQL的文档永远和代码同步,开发无需维护散落多处的文档,调用者也无需担心过期问题,而且基于类型系统的强力支撑和 graphql-tools,mocking 会变得无比容易。
GraphQL通过它的特性解决了不少问题,当然它不是没缺点的,这个下期再聊~
我的观点:当技术栈的缺点因其演进不再明显之时,必是它优点大放光彩之日 。与此同时GraphQL伴随着 graph 又带来了很多新的思考~
GraphQL 的延伸,graphical & graph(s)
图像天然更生动形象易于理解,这意味着GraphQL有交互极强的工具和生态,比如:
- graphiql —— A graphical interactive in-browser GraphQL IDE. 一个让我们在浏览器里用图形交互的方式探索及书写
GraphQL的 IDE。 - graphql-voyager —— Represent any GraphQL API as an interactive graph. It's time to finally see the graph behind GraphQL! 用交互式图表展示任意的 GraphQL API,总算能看见
GraphQL背后的 graph 了!
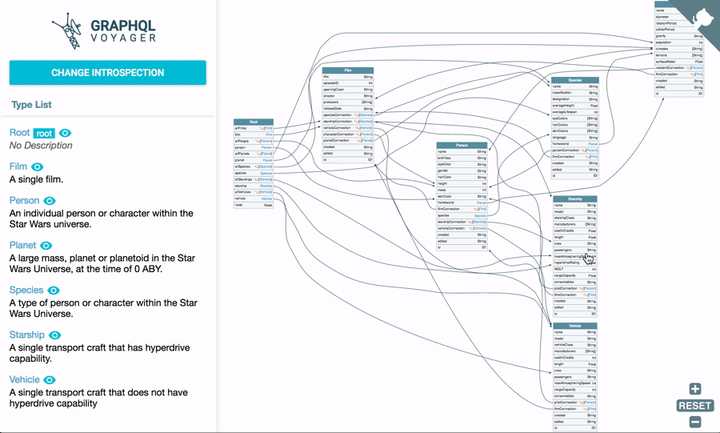
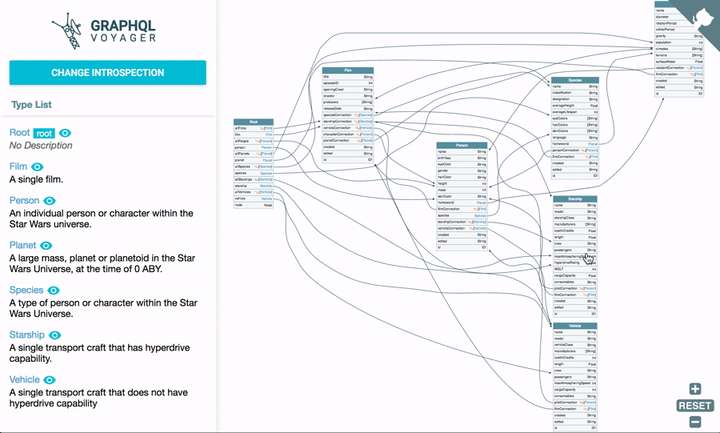
今年 5 月 22 日 GitHub 发文宣布,去年推出的 GitHub GraphQL API 已经正式可用 (production-ready),并推荐集成商在 GitHub App 中使用最新版本的GraphQL API V4。我们可以用 graphql-voyager 探索(但因 Types、Queries、Mutations 较多数据加载略慢)。
后一个工具可把笔者惊艳坏了,想了解它的生态可以在 awesome-graphql 里寻找。通过它们,所有人都能快速阅读查询文档,调试我们的查询。
PS:主要是方便调用者和团队新人的,不过可以思考一个问题,每天是写代码还是看代码多?看接口文档呢?
另一种思维模式 —— Thinking in graphs
图是将很多真实世界现象变成模型的强大工具,因为它们和我们天然的心理模型和基本过程的口头描述很相似。大家应该都没忘在学校做的数据库设计,笔者简单回顾下当年手绘 E-R 图的过程
- 一个班级有一个班主任,
1:1的关系; - 一个班级有多学生多个教师,
1:n的关系; - 每个学生可以上不同的课程,
n:m的关系。
OK,然后大概就成了下面这个样子,原谅我从百度找的图:

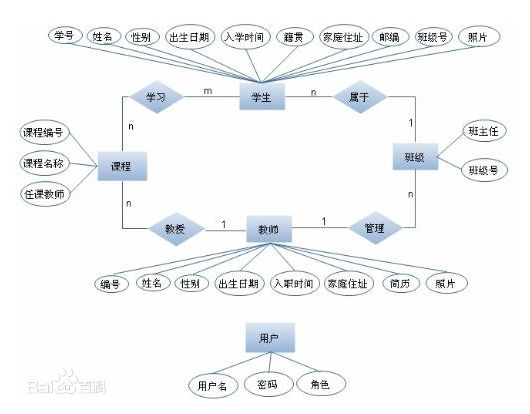 E-R 图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
E-R 图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
- 真实世界的数据在本质上是分层的:今天大多数的产品开发涉及视图层次的创建和操作,这与应用程序的结构保持一致;
- 我们的开发模式本身也是产品需求驱动的,客户端关注需求(怎么取、取哪些),服务端关注能力(可用性、性能),这样的协作模式更现代更高效;
- 数据和实体背后的本质也是关系图:我们的服务端用对象和关系的形式处理,只不过在数据库用扁平的表格存储它们;(以前你可以将负责的业务数据通过导出 E-R 图展现给同事和老板。如今你还可以通过
GraphQL把到对外暴露的API也建模成一张图。) GraphQL沉淀出来的数据模型(Schema)也可以作为一种给你的团队(后端前端客户端甚至产品)及第三方沟通的共同语言,让大家对这些业务领域的规则形成共同的理解,最终达成共识。
GraphQL的原理、和RESTful的优劣对比以及最佳实践等等,未完再续~
参考资料 —— 需要FQ
来自官方的介绍:
GraphQL Introduction
GraphQL: A data query language
来自 InfoQ 的采访:Facebook开源数据查询语言GraphQL
来自官方的 Talks:GraphQL: Designing a Data Language
30分钟内现场演示用Python、Ruby、Nodejs.js,设计3次 GraphQL Sever:Zero to GraphQL in 30 Minutes
转载自:https://www.zhihu.com/question/264629587/answer/949588861