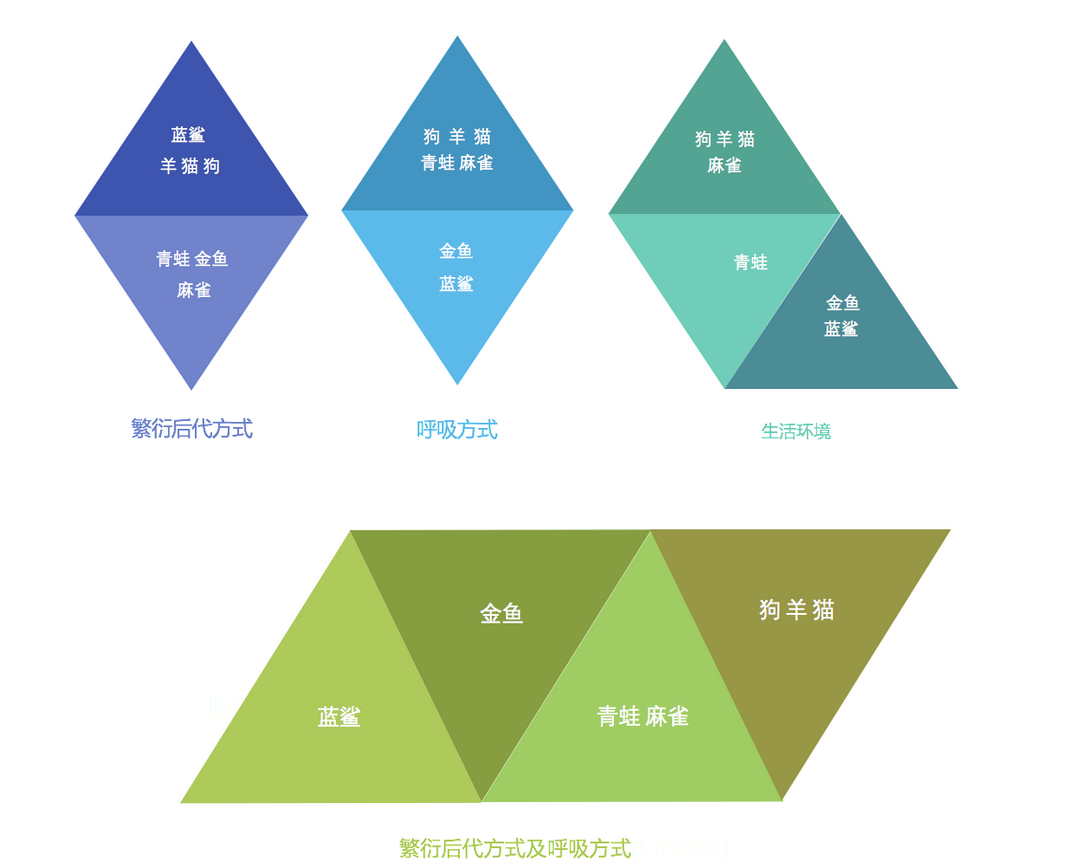
使用不同的聚类准则,产生的聚类结果不同。
** 聚类算法在现实中的应用**
- 用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
- 基于位置信息的商业推送,新闻聚类,筛选排序
- 图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
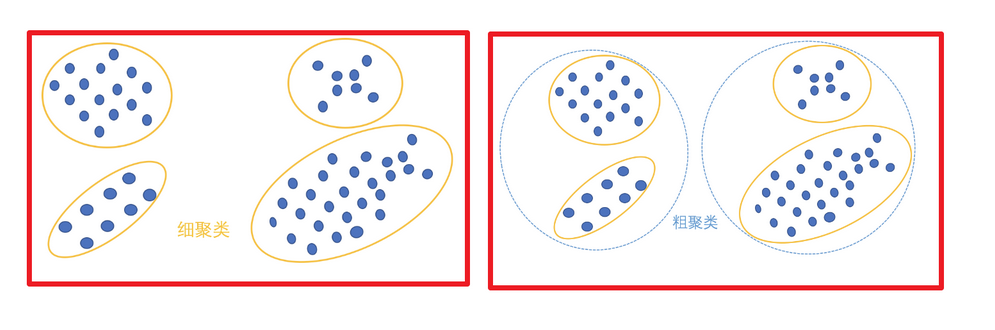
聚类算法的概念
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
聚类算法与分类算法最大的区别
聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabaz_score
# 创建数据集
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇,
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=9)
# 数据集可视化
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
# 使用k-means进行聚类,并使用CH方法评估
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X)
# 分别尝试n_cluses=234,然后查看聚类效果
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
# 用Calinski-Harabasz Index评估的聚类分数
print(calinski_harabaz_score(X, y_pred))