游戏循环和实时模拟
渲染循环
Windows的GUI中某时刻只有少部分视窗会改变,因此采用矩形失效技术仅让屏幕有改动的部位重绘。现代3D游戏中,摄像机在三维场景中移动,屏幕和视窗的一切都会改变,所以采用和电影相同的方式产生运动的错觉和互动性——对观众快速连续地显示一连串静止映像。
快速连续的显示一连串静止影像,需要写一个循环。在实时渲染应用中,这种循环称为渲染循环。
while (!quit) { // 基于输入或预设的路径更新摄像机变换 updateCamera(); // 更新场景中所有动态元素的位置、定向及其他相关的视觉状态 updateSceneElements(); // 把静止的场景渲染至屏幕外的帧缓冲(称为“背景缓冲”) renderScene(); // 交换背景缓冲和前景缓冲,令最近渲染的影像显示于屏幕之上 // (或是在视窗模式下,把背景缓冲复制至前景缓冲) swapBuffers(); }
游戏循环
在游戏运行时,多数游戏引擎子系统都需要周期性地提供服务,而它们所需的服务频率各有不同。动画子系统通常需要30Hz或60Hz的更新率,和渲染子系统同步。动力学模拟可能需要更频繁地更新(如120Hz)。像人工智能这种更高级的系统,可能只需要每秒1-2次更新,而且完全不需要和渲染循环同步。
最简单的游戏循环,是采用单一循环更新所有子系统,即在一个无限循环中计算逻辑并渲染画面。
游戏循环的架构风格
视窗消息泵
Windows平台下,游戏除了要服务引擎本身的子系统,还要处理来自操作系统的消息。因此需要一段称为消息泵的代码来处理,基本原理是先处理来自Windows的消息,无消息时才执行引擎的任务。这种方法的副作用是设置了处理Windows消息为先,渲染和模拟游戏为后的优先次序,导致当玩家在桌面上改变游戏的视窗大小或移动视窗时,游戏就会愣住不动。典型消息泵代码如下:
while (true) { // 处理所有Windows消息 MSG msg; while (PeekMessage(&msg, NULL, 0, 0) > 0) { TranslateMessage(&msg); DispatchMessage(&msg); } // 再无Windows消息需要处理,执行“真正”的游戏循环迭代一次 RunOneIterationOfGameLoop(); }
回调驱动框架
游戏引擎子系统和第三方游戏中间套件既可以以程序库方式构成(提供函数和类供随意调用),也有以框架构成的。这种情况下,游戏主循环已经准备好了,程序员需提供框架中空缺的自定义实现(编写回调函数)。
OGRE引擎提供一套框架,程序员需要从Ogre::FrameListener派生一个类,并覆写两个虚函数:frameStarted()和frameEnded(),OGRE在渲染主三维场景的前后会调用这两个函数。
class GameFrameListener : public Ogre::FrameListener { public: virtual void frameStarted(const FrameEvent &event){ //于三维场景渲染前所需执行的事情(如执行所有游戏引擎子系统) pollJopad(event); updatePalyerControls(event); updateDynamicSimulation(event); resolveCollisions(event); updateCamera(event); //等等 } virtual void frameEnded(const FrameEvent &event){ //于三维场景渲染后所需执行的事情 drawHud(event); //等等 } }; //Orge的游戏循环实现方式:OrgeRoot.cpp中的Orge::Root::renderOneFrame()的实现 ... renderOneFrame(...){ ... while (true){ for (each frameListener){ frameListener.frameStarted(); } renderCurrentScene(); for (each frameListener){ frameListener.feameEnded(); } finalizeSceneAndSwapBuffers(); } ... }
基于事件的更新
在游戏中,事件是指游戏状态的改变或游戏环境状态的有趣改变,如玩家按下手柄上的按钮、发生爆炸、敌方角色发现玩家等等。多数游戏引擎都有一个事件系统,让各个引擎子系统登记其关注的某类型事件,当那些事件发生时就可以一一回应。
有些游戏引擎会使用事件系统对所有或部分子系统进行周期性更新,这样事件系统就需要容许发送未来的事件。即事件先置于队列,在设定的时间间隔之后才取出处理。接着,代码可以发送一个新事件,并设定该事件在未来1/30s或1/60s生效,那么这个周期性更新就能一直延续下去。
抽象时间线
真实事件
使用CPU的高分辨率计时寄存器来量度时间,这种时间是真实时间线。
游戏时间
游戏时间线从技术上说独立于真实事件。正常情况下,游戏时间和真实时间相同。但是如果希望暂停游戏,就可以临时停止对游戏时间的更新。暂停或减慢游戏时间也是很有用的调试工具。
局部及全局时间线
其他资源或对象也有自己的局部时间线,例如每个动画片段或音频片段都含有一个局部时间线。这样动画的加速、减速播放、反向播放等效果可以视觉化为局部和全局时间线之间的映射。

测量及处理时间
帧率及时间增量
实时游戏的帧率是指一连串三维帧以多快的速度向观众显示,单位是赫兹(Hz),而两帧之间所经过的时间称为帧时间、时间增量或增量时间。增量时间∆t = 1/f;f是帧率。
从帧率到速率
如果游戏中一个物体以大致恒定的速度移动,则可以通过∆x = v∆t来计算它的位移。这是数值积分的简单形式,称为显示欧拉法。实际上物体可能不是恒定速度,但是游戏中的物体的感知速度都与帧时间∆t相关。
如果直接忽略∆t,则游戏会受到CPU速度的影响。如何避免?只需读取CPU高分辨率计时器两次(帧开始时一次,帧结束时一次),取两者之差,就能得到∆t。然后把它供所有子系统使用,就可以和CPU速度脱钩。但是,第K帧度量的时间不一定是第K+1帧需要的时间。下一帧可能因为某些原因,消耗更多时间,这种情况被称为帧率尖峰。而且使用上一帧的∆t估算下一帧的∆t可能会出现很坏的情况。如果上一帧的时间很慢,那么下一帧就要步进两次,导致它和上一帧一样慢,这样只会使问题加剧或延长。
移动平均
可以使用计算连续几帧的平均时间,来估算下一帧的∆t。它能使游戏适应转变中的帧率,同时缓和帧率尖峰的影响。
帧率调控
尝试是每一帧都准确耗时在一个理想的∆t上。限度量本帧的耗时,如果比∆t小,就是主线程休眠一会;如果比∆t大,就白等下一个目标时间。这种方法称为帧率调控。
只有当游戏的平均帧率接近目标帧率时,这种方法才比较有效。如果帧率经常波动,就会影响游戏质量。帧率连续维持稳定,对游戏的很多方面都很重要。例如,稳定的帧率可以避免画面撕裂,也可以是游戏的录播功能更可靠。
垂直消隐区间
CRT显示器的电子枪在扫描中途交换背景缓冲区和前景缓冲区会出现画面撕裂的问题。为避免这个问题,许多渲染引擎会在交换缓冲区之前,等待显示器的垂直消隐区间(Vertiacl blanking interval,即电子枪重归到屏幕上角的时间区间)。
等待垂直消隐区间是另一种帧率调控。实际上它能限制主游戏循环的帧率,是其必然为屏幕刷新率的倍数。
使用高分辨率计时器测量实时
大多数操作系统都提供获取系统时间的函数,但是对于游戏引擎,它们分辨率太差,例如C标准库的time(),因此,游戏引擎需要使用CPU的高分辨率计时器测量时间。而大多数CPU的高分辨率计时器是64位的,这样它的周期大约是1.8×1019个周期。而3GHz的奔腾处理器,这个计时器大约195年才会溢出一次。
但是高分辨率计时器也存在问题,某些情况下,会有精确的时间测量。例如,多核处理器中,每核有独立高分辨率计时器时,这些计时器可能会彼此漂移。
时间单位和时钟变量
关于时间度量,需要搞清楚需要多少精度,期望多大范围?
64位整数时钟
上面可以看出64位整数时钟是最好的方法,只要能负担得起它的存储。
32位整数时钟
如果是32位的整数时钟,它能保证精度,但是对于3GHz的奔腾处理器,它大概1.4s就会溢出1次。因此,它只适用于短时间。
U64 tBegin = readHiResTimer(); //一下是想度量性能的代码 ... //度量经过时间 U64 tEnd = readHiResTimer(); U32 dtCycles = static_cast<U32>(tEnd - tBegin);
注意:原始的时间度量仍然使用64位存储,为了避免溢出,使dtCycles得到的是负数的情况。
32位浮点时钟
把时间以秒为单位存成32位浮点数,将32位整数除以CPU时钟频率。
//开始时假设为理想的帧时间 F32 dtSeconds = 1.0f / 30.0f; //开始时先读取一个时间 U64 tBegin = readHiResTimer(); //游戏主循环 while (true){ runOneIterationOfGameLoop(dtSeconds); //再读取时间 U64 tEnd = readHiResTimer(); dtSeconds = (F32)(tEnd - tBegin) / (F32)getHirestTimerFrequency(); //更新下一帧的tBegin tBegin = tEnd; }
必须先使用64位的时间相减,这样能避免把很大的值存进32位浮点数中,提高精度。
浮点时钟的极限
使用浮点时钟时,必须小心,避免用浮点时钟变量存储很长的持续时间。如果使用浮点变量存储自游戏开始至今的秒数,最后会变得极不准确。浮点时钟只适合存储相对较短的持续时间,最多度量几分钟,更常见的是存储单帧或更短的时间。若游戏中使用了浮点时钟,需要定期重置。
其他时间单位
有些引擎支持把时间单位设为自定义的值,例如1/300s为时间单位,这样使用32位整数时钟,既有精度又不会很快溢出。它的优点:很多情况下精度足够;约165.7天才会溢出;是NTSC和PAL刷新率的倍数。
应付断点
游戏运行遇到断点时,CPU时钟仍然在计时,这样会产生很大的时间度量帧,若把这个时间度量传到其他子系统会引起问题。简单的方法是在游戏主循环中,判断如果某帧的时间超过一个预设的上限,则认为是从断点恢复执行,手动将它设为期望值。
一个简单的时钟类
有的引擎会把时间变量封装成一个类,它由多个实例,表示真实时间、游戏时间、局部时间等等。这类需要记录始终创建以来经过的绝对时间,也可以支持例如时间放缩,暂停等功能。
class Clock{ U64 m_timeCycles; F32 m_timeScale; bool m_isPaused; static F32 s_cyclesPerSecond; static inline U64 secondsToCycles(F32 timeSeconds){ return (U64)(timeSeconds * s_cyclesPerSecond); } //警告:危险——只能转换很短的经过时间至秒 static inline F32 cyclesToSeconds(U64 timeCycles){ return (U64)(timeCycles / s_cyclesPerSecond); } public: //在游戏启动时调用此函数 static void init(){ s_cyclesPerSecond = (F32)readHiResTimerFrequency(); } //构建一个时钟 explicit Clock(F32 startTimeSeconds = 0.0f) :m_timeCycles(secondsToCycles(startTimeSeconds)), m_timeScale(1.0f), m_isPaused(false){} //一周期为单位返回当前时间。注意不是返回以浮点秒表示的绝对时间 //因为32位浮点没有足够的精度 U64 getTimeCycles()const { return m_timeCycles; } //以秒为单位,计算此时钟与另一个时钟的绝对时间差 //因为32位浮点没有足够的精度,所以时间差以秒表示 F32 calcDeltaSeconds(const Clock &other){ U64 dt = m_timeCycles - other.m_timeCycles; return cyclesToSeconds(dt); } //在每帧调用此函数一次,并给与真实度量帧时间(以秒为单位) void update(F32 dtRealSeconds){ if (!m_isPaused){ U64 dtScaledCycles = secondsToCycles(dtRealSeconds * m_timeScale); m_timeCycles += dtScaledCycles; } } void setPaused(bool isPaused){ m_isPaused = isPaused; } bool isPaused()const { return m_isPaused; } void setTimeScale(F32 scale){ m_timeScale = scale; } F32 getTimeScale()const { return m_timeScale; } void singleStep(){ if (!m_isPaused){ U64 dtScaledCycles = secondsToCycles((1.0f / 30.0f) * m_timeScale); m_timeCycles += dtScaledCycles; } } };
多处理器的游戏循环
多处理器游戏机的架构
Xbox 360和PlayStation 3都是多处理器游戏机,为了有意义地讨论并行软件架构,需要先简单了解它们的内核架构。
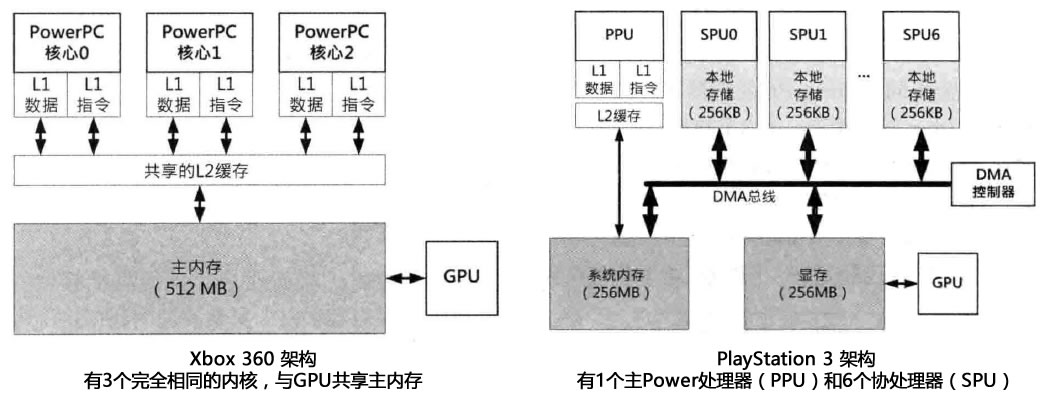
上图可以看出,Xbox360是三个CPU处于相同的地位,共同执行程序;而PlayStation 3则是由一个主CPU(称为Power处理部件,Power Processing Unit,PPU)和6个副CPU(称为协同处理器,Synergistic Processing Unit,SPU)组成,其中SPU使用显存,PPU使用内存,6个SPU需要通过DMA将内存数据拷贝到局部存储(256k的高速缓存)中。
SIMD
多数现代CPU都会提供单指令多数据(SIMD)指令集,其可以让一个运算同时执行于多个数据之上,此乃一种细粒度形式的硬件并行。游戏中最常用的是并行操作4个32位浮点数,可以让三维矢量和矩阵运算加速至4倍。实际使用SIMD指令时,一般要采用封装良好的三维数学库中的函数来计算。
分叉与汇合
基本原理是把一个单位的工作分割成更小的子单位,再把这些工作量分配到多个核或硬件线程(分叉),最后待所有工作完成后再合并结果(汇合)。游戏循环应用分治法后,其结构看上去和单线程循环相似,不过更新循环的几个主要阶段都能并行化。
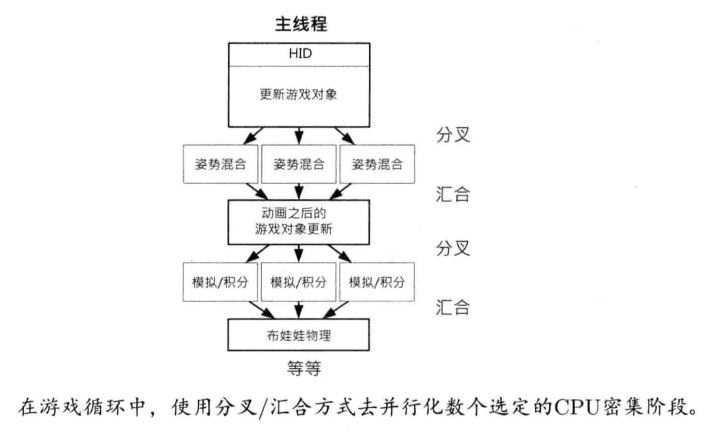
举个例子,若动画混合使用线性插值(LERP),其操作可以独立地施于骨骼上所有关节。假设要混合5个角色的一对骨骼姿势,每个骨骼有100个关节,总共要处理500对关节姿势,可以切割成N个批次,每批次含约500/N对关节姿势。其中N按可用的处理器资源来定,如Xbox 360是3或6(3个核,每核有2个硬件线程),PS3是1-6(视有多少个SPU可用)。
子系统独立线程
把每个引擎子系统置于独立线程上运行。主控线程负责控制及同步这些子系统的次级子系统,并继续应付游戏的大部分高级逻辑(游戏主循环)。它适合某些需重复执行且较有隔离性的子系统,如渲染引擎、物理模拟、动画管道、音频引擎等。
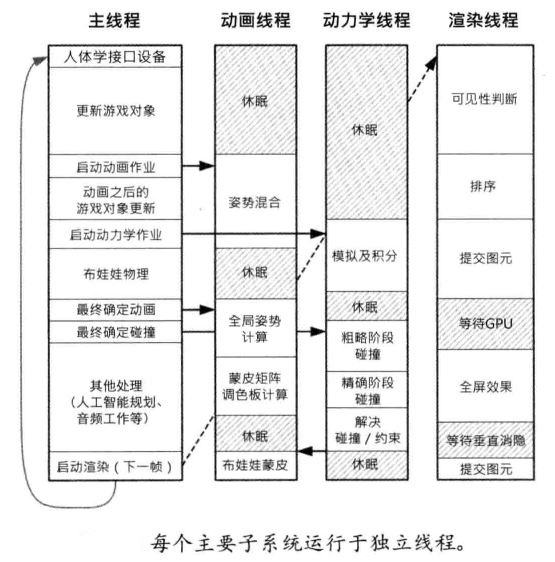
多线程架构需要线程库支持,Windows上会使用Win32的线程API,UNIX上用类似pthread的库。PlayStation 3上的SPURS的库,他提供任务模型和作业模型两种在SPU上运行程序的方法。下面会介绍作业模型。
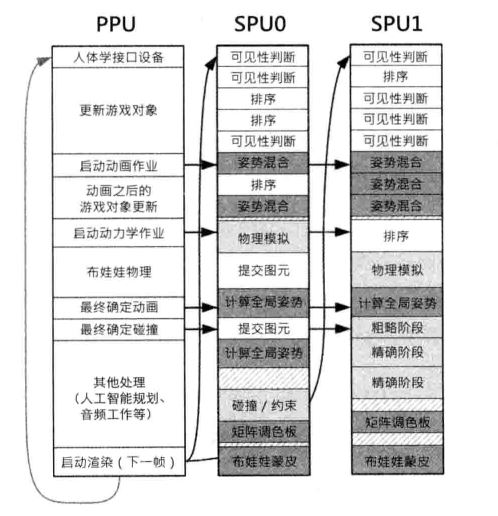
作业模型
使用多线程的问题之一就是,每个线程都代表相对较粗粒度的工作量(例如把所有动画任务都置于一个线程,把所有物理任务置于另一线程),这会限制多个处理器的利用率。若某个子系统线程未完成其工作,就可能阻塞主线程和其他线程。为充分利用并行硬件架构,另一种方法是把工作分割成多个细小、比较独立的作业(一组数据与操作代码结合成对),作业准备就绪就加入队列,待有闲置的处理器,作业才会从队列取出执行。PS3的SPURS库的作业模型就实现这种方法,其6个SPU只要有闲置就投入处理细粒度的作业。这样有助于最大化处理器的利用率,也可减少对主线程的限制,自然地对任何数量的处理单元进行扩展或缩减。
网络多人游戏循环
主从式模型
网游在在C/S模型下,大部分游戏逻辑运行在服务器上,服务器和非网络的单机游戏很相似;客户端则类似一个“非智能”的渲染引擎,它仅接收设备输入,渲染,处理音频,处理网络请求,以及加上一些预测玩家的代码(为了不让玩家觉得控制的游戏角色反应非常缓慢),甚至客户端要渲染什么都要服务器告知。
客户端和服务器不一定要运行于两个独立的机器上,运行在同一个机器上也很常见(单人游戏模式)。网游的游戏循环可以实现为客户端和服务器为完全独立的进程;当两者在同一机器上时,可以置于同一进程的两个线程,或者为了节省本地通信的开销,都置于单个线程,由单游戏循环控制。
必须注意,客户端和服务器的代码可能以不同频率进行更新。假设服务器以20FPS运行(50ms/f),客户端以60FPS运行(16.6ms/f),可以让主游戏循环以频率快者运行(60FPS),服务器每次循环会计算上次更新至今的经过时间,若超过50ms,服务器就会运行一帧,然后重置计时器。
点对点模型
在这种架构下,游戏中每个动态对象,都由其对应的单一机器所管辖。每个机器对其拥有管辖权的对象就如同服务器,对于其他无管辖权的对象就如同是客户端,只负责渲染远端管辖者所提供的对象状态。主从模型中,客户端和服务器代码分离得比较开,而在点对点模型中,许多代码都要处理(或实现)为两种游戏对象,一种是本机有管辖权的完整“真实”游戏对象,另一种是“代理版本”,仅含远程对象状态的最小子集。
注意点对点架构可以设计得更复杂,如其中一机器离开游戏,则该机器所有对象的管辖权必须转移至其他参与该游戏的机器。若有新机器加入游戏,理想地该机器应接管其他机器的一些游戏对象,以平衡每部机器的工作量。以上的讨论带出的重点是,多人架构对于游戏主循环的结构有深远影响。