摘要:本文分别介绍了线性回归、局部加权回归和岭回归,并使用python进行了简单实现。
在这之前,已经学习过了Logistic回归,今天继续看回归。首先说一下回归的由来:回归是由达尔文的表兄弟Francis Galton发明的。Galton于1877年完成了第一次回归预测,目的是根据上一代豌豆的种子(双亲)的尺寸来预测下一代豌豆种子(孩子)的尺寸(身高)。Galton在大量对象上应用了回归分析,甚至包括人的身高。他得到的结论是:如果双亲的高度比平均高度高,他们的子女也倾向于平均身高但尚不及双亲,这里就可以表述为:孩子的身高向着平均身高回归。Galton在多项研究上都注意到了这一点,并将此研究方法称为回归,接下来就上文提到的三种回归一一介绍:
一 线性回归(Linear Regression)
1. 线性回归概述
回归的目的是预测数值型数据的目标值,最直接的方法就是根据输入写出一个求出目标值的计算公式,也就是所谓的回归方程,例如y = ax1+bx2,其中求回归系数的过程就是回归。那么回归是如何预测的呢?当有了这些回归系数,给定输入,具体的做法就是将回归系数与输入相乘,再将结果加起来就是最终的预测值。说到回归,一般指的都是线性回归,当然也存在非线性回归,在此不做讨论。
假定输入数据存在矩阵x中,而回归系数存放在向量w中。那么对于给定的数据x1,预测结果可以通过y1 = x1Tw给出,那么问题就是来寻找回归系数。一个最常用的方法就是寻找误差最小的w,误差可以用预测的y值和真实的y值的差值表示,由于正负差值的差异,可以选用平方误差,也就是对预测的y值和真实的y值的平方求和,用矩阵可表示为:(y - xw)T(y - xw),现在问题就转换为寻找使得上述矩阵值最小的w,对w求导为:xT(y - xw),令其为0,解得:w = (xTx)-1xTy,这就是采用此方法估计出来的
2.python实现
结合上述的分析,采用python实现,首先,导入数据:
#导入数据 def loadData(fileName): numFeat = len(open(fileName).readline().split(' ')) - 1 dataMat = [] labelMat = [] fr = open(fileName) for line in fr.readlines(): linArr = [] curline = line.strip().split(' ')#得到每行,并以tab作为间隔 for i in range(numFeat): linArr.append(float(curline[i])) dataMat.append(linArr) labelMat.append(float(curline[-1])) return dataMat,labelMat
之后,求解回归系数:
#计算回归系数
from numpy import * def standRegres(x,y): xMat = mat(x) yMat = mat(y).T xTx = xMat.T*xMat #采用numpy中的线性代数库linalg,其中linalg.det直接可以计算行列式 if linalg.det(xTx) == 0.0: print "这个行列式是错误的的,不能求逆" return #求回归系数 w = xTx.I * (xMat.T * yMat) return w
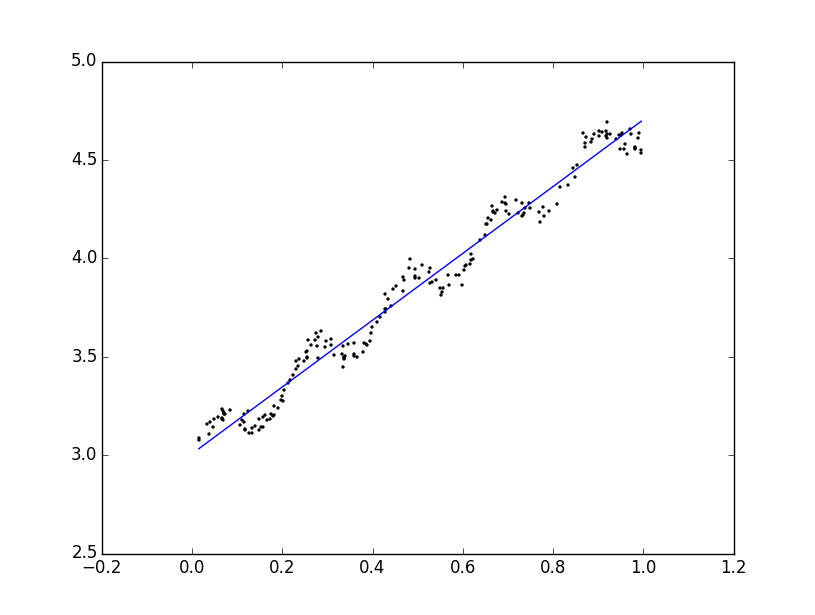
求得了回归系数,结合输入就可以得到回归方程,为了直观的表示,采用Matplotlib绘图:
x,y = loadData("ex0.txt") w = standRegres(x,y) xMat = mat(x) yMat = mat(y) #绘制原数据点 fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0]) #<matplotlib.collections.CircleCollectin object at 0x04ED9D30> #plt.show() #在之前的图像上绘制出拟合直线 xCopy = xMat.copy() xCopy.sort(0) yHat = xCopy*w ax.plot(xCopy[:,1],yHat) plt.show()
结果如下图:

至此拟合就结束了,那么如何评判拟合的好坏?numpy库提供了相关系数的计算方法,通过命令corrcoef()可以来计算预测值和真实值的相关性。
yHat = xMat * w print corrcoef(yHat.T,yMat)
分析结果我们可以看出线性回归得到的相关性还是挺理想的,但是从图像中明显可以看出线性回归未能捕获到一些数据点,没能很好的表示数据的变化趋势,在某种情况下存在欠拟合的情况,这是线性回归的一个缺点。在此想要说明的一点是,要只是简单的实现拟合的话,不妨采用MATLAB中的cftool的工具,简单高效直观。
二 局部加权线性回归
(Locally Weighted Linear Regression,LWLR)
1.概述
针对于线性回归存在的欠拟合现象,可以引入一些偏差得到局部加权线性回归对算法进行优化。在该算法中,给待测点附近的每个点赋予一定的权重,进而在所建立的子集上进行给予最小均方差来进行普通的回归,分析可得回归系数w可表示为:
w = (xTWx)-1xTWy,其中W为每个数据点赋予的权重,那么怎样求权重呢,核函数可以看成是求解点与点之间的相似度,在此可以采用核函数,相应的根据预测点与附近点之间的相似程度赋予一定的权重,在此选用最常用的高斯核,则权重可以表示为:w(i,i) = exp(|x(i) - x| / -2k2),其中K为宽度参数,至于此参数的取值,目前仍没有一个确切的标准,只有一个范围的描述,所以在算法的应用中,可以采用不同的取值分别调试,进而选取最好的结果。
2.python实现
结合上述的分析,采用python编程实现,代码如下:
def lwlr(testPoint,xArr,yArr,k): xMat = mat(xArr) yMat = mat(yArr).T m = shape(xMat)[0] weights = mat(eye((m))) for i in range(m): weights[i,i] = exp((testPoint - xMat[i,:])*(testPoint - xMat[i,:]).T / (-2.0*k**2)) xTx = xMat.T * (weights * xMat) if linalg.det(xTx) == 0: print "输入有误" return ws = xTx.I * xMat.T * weights * yMat return testPoint * ws #为数据点中的每个数据调用lwlr def lwlrTest(testArr,xArr,yArr,k): m = shape(testArr)[0] yHat = zeros(m) for i in range(m): yHat[i] = lwlr(testArr[i],xArr,yArr,k) return yHat
结合上述分析,我们可以选取不同的k值分别求得结果,进而采用Matplotlib绘图直观的表示,在此,分别选取k = 1,0.01,0.002,代码如下:
#test x,y = loadData("ex0.txt") a = lwlr(x[0],x,y,0.002) b = lwlrTest(x,x,y,0.002) #采用matplotlib绘制图像 xMat = mat(x) srtInd = xMat[:,1].argsort(0)#按升序排序,返回下标 xSort = xMat[srtInd][:,0,:]#将xMat按照升序排列 fig = plt.figure() ax = fig.add_subplot(111) ax.plot(xSort[:,1],b[srtInd]) ax.scatter(xMat[:,1].flatten().A[0],mat(y).T.flatten().A[0],s = 2,c = 'red') plt.show()
最终结果分别如下,依次为k = 1,0.01,0.002对应的结果:


可以看出,当k = 1时,结果和线性回归使用最小二乘法的结果相似,而k=0.001时噪声太多,属于过拟合的情况,相比之下,k = 0.01得到的结果更理想。虽然LWLR得到了较为理想的结果,但是此种方法的缺点是在对每个点进行预测时都必须遍历整个数据集,这样无疑是增加了工作量,并且该方法中的的宽度参数的取值对于结果的影响也是蛮大的。同时,当数据的特征比样本点还多当然是用线性回归和之前的方法是不能实现的,当特征比样本点还多时,表明输入的矩阵X不是一个满秩矩阵,在计算(XTX)-1时会出错。
三 岭回归
1.概述
为了解决上述问题,统计学家引入了“岭回归”的概念。简单说来,岭回归就是在矩阵XTX上加上一个λr,从而使得矩阵非奇异,从而能对XTX + λx求逆。其中矩阵r为一个m*m的单位矩阵,对角线上的元素全为1,其他元素全为0,而λ是一个用户定义的数值,这种情况下,回归系数的计算公式将变为:w = (xTx+λI)-1xTy,其中I是一个单位矩阵。
岭回归就是用了单位矩阵乘以常量λ,因为只I贯穿了整个对角线,其余元素为0,形象的就是在0构成的平面上有一条1组成的“岭”,这就是岭回归中岭的由来。
岭回归最先是用来处理特征数多与样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里引入λ限制了所有w的和,通过引入该惩罚项,能够减少不重要的参数,这个技术在统计学上也叫做缩减。缩减方法可以去掉不重要的参数,因此能更好的理解数据。在此,选取不同的λ进行测试,最后得到一个使得误差最小的λ。
2.python实现
结合上述的分析,同样采用python实现,代码如下:
def ridgeRegress(xMat,yMat,lam = 0.2):#在没给定lam的时候,默认为0.2 xTx = xMat.T*xMat denom = xTx + eye(shape(xMat)[1])*lam if linalg.det(denom) == 0.0: print "这个矩阵是错误的,不能求逆" return ws = denom.I * (xMat.T * yMat) return ws #对数据进行标准化之后,调用30个不同的lam进行计算 def ridgeTest(xArr,yArr): xMat = mat(xArr) yMat = mat(yArr).T yMean = mean(yMat,0) yMat = yMat - yMean xMeans = mean(xMat,0) xVar = var(xMat,0) xMat = (xMat - xMeans)/xVar numTestPts = 30 wMat = zeros((numTestPts,shape(xMat)[1])) for i in range(numTestPts): ws = ridgeRegress(xMat,yMat,exp(i-10)) wMat[i,:]=ws.T return wMat
进而采用matplotlib绘图得到在30个不同的lam下回归系数的变化情况,如下图:

由该图可以看出,lam很小时,系数和普通回归一样,而当lam非常大时,所有的回归系数缩减为0,可以看出在中间某处可以找到使得预测结果最好的lam值。 为了选取最优的lam值,可以采取交叉验证法。
总结:与分类一样,回归是预测目标值的过程。回归与分类的不同在于回归预测的是连续型变量,而分类预测的是离散型的变量。回归是统计学中最有力的工具之一。如果给定输入矩阵x,xTx的逆如果存在的话回归法可以直接使用,回归方程中的求得特征对应的最佳回归系数的方法是最小化误差的平方和,判断回归结果的好坏可以利用预测值和真实值之间的相关性判断。当数据样本总个数少于特征总数时,矩阵x,xTx的逆不能直接计算,这时可以考虑岭回归。