一、生产者端
首先,我们要知道生产者在生产数据时是靠ack应答机制来传输数据的,当
ack=0时,生成者无需等待brokder的ack,一直发送消息
ack=1时,生产者接收到leader的ack信号,就会发送下一条数据
ack=-1时,生产者必须等到所有broker返回ack信号,才会发送下一条数据
1.1数据丢失的情况
当ack=0时,如果有一台broker挂掉,那么那台broker就会接收不到这条消息
当ack=1时,如果有一台follower挂掉,那么这台follower也会丢失这条消息,
或者follower还未同步leader的数据,leader挂了,也会丢失消息
1.2数据重复的情况
当ack=-1时,只要有一台follower没有与leader同步,生产者就会重新发送消息,这就照成了消息的重复
1.3避免方法
开启精确一次性,也就是幂等性, 再引入producer事务 ,即客户端传入一个全局唯一的Transaction ID,这样即使本次会话挂掉也能根据这个id找到原来的事务状态
enable.idempotence=true
开启后,kafka首先会让producer自动将 acks=-1,再将producer端的retry次数设置为Long.MaxValue,再在集群上对每条消息进行标记去重!
去重原理:
在cluster端,对每个生产者线程生成的每条数据,都会添加由生产者id,分区号,随机的序列号组成的标识符: (producerid,partition,SequenceId),通过标识符对数据进行去重!
但是只能当次会话有效,如果重启了就没有效果,所以需要事务的支持
二、消费者端
消费者是以维护offset的方式来消费数据的,所以如果在提交offset的过程中出问题,就会造成数据的问题,即已经消费了数据,但是offset没提交
大佬博客里已经解释很详细了https://blog.csdn.net/qingqing7/article/details/80054281
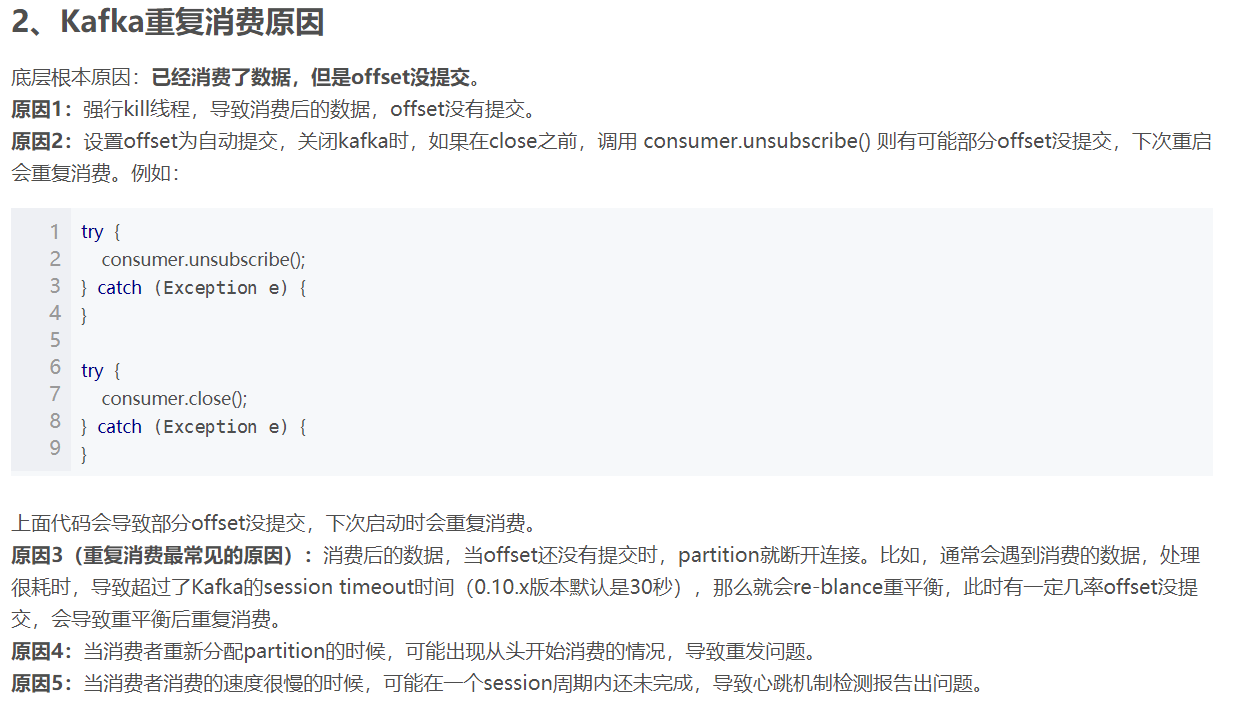
注意:手动提交时,无论是同步提交还是异步提交,都会有数据重复消费的风险
解决方案:
1.手动维护offset
2.加大这个参数kafka.consumer.session.timeout,以避免被错误关闭的情况
3.加大消费能力
4.在下游对数据进行去重