回归评估
-
平均绝对误差(Mean Absolute Error, MAE), 又被称为L1范数损失
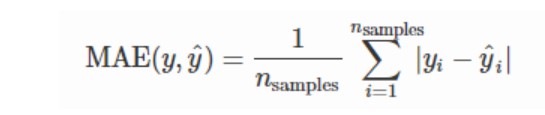
-
平均平方误差(Mean Squared Error, MSE ,又被称为l2范数损失

-
分类平评估指标
二维混淆矩阵
| 预测 | 结果 | |
|---|---|---|
| 真实类别 | 正例 | 反例 |
| 正例 | 真正例(True Positive) TP | 假反例(False Negative) FN |
| 反例 | 假正例(False Positive) FP | 真反例(True Negative)TN |
(1) 准确率 表示正确分类的测试实例的个数占测试实例总数的比例,计算公式为
Accuracy = TP + TN / TP + FP + FN + TN
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联昂广告里面,点击的数量很少,一般只有千分之几,如果用accuracy,即使全部预测成负类(不点击),accuracy也有99%以上,没有意义
(2)召回率 也叫查全率, 表示正确分类的正例个数占实际正例个数的比例
Reccall = TP/(TP + FN)
(3) 精确度 也叫查准率,表示正确分类的正例个数占分类为正例的实例个数的比例,计算公式为
Precision = TP/(TP + FP)
(4) F1-Score 是基于召回率与精确率的调和平均,即将召回率和精确率综合起来评价,计算公式为
F1-Score = 2 Recall*Precision/(Recaall + Prcision)*
ROC AUC

ROC曲线横坐标是FPR,纵坐标是TPR
FPR = FP/(FP + TN)
TPR = TP/(TP + FN)
ROC曲线越接近左上角,该分类器的性能越好
AUC 被定义为ROC曲线下面的面积,显然这个面积的数值不会大于1,AUC的面积越大越好。如果AUC值大,会有更多的正样本被更大概率准确预测,负样本被预测为正样本的概率也会越小。