2.python数据结构的性能分析
一.引言
- 现在大家对 大O 算法和不同函数之间的差异有了了解。本节的目标是告诉你 Python 列表和字典操作的 大O 性能。然后我们将做一些基于时间的实验来说明每个数据结构的花销和使用这些数据结构的好处。重要的是了解这些数据结构的效率,因为它们是本博客实现其他数据结构所用到的基础模块。本节中,我们将不会说明为什么是这个性能。在后面的博文中,你将看到列表和字典一些可能的实现,以及性能是如何取决于实现的。
二.列表:
- python 的设计者在实现列表数据结构的时候有很多选择。每一个这种选择都可能影响列表操作的性能。为了帮助他们做出正确的选择,他们查看了最常使用列表数据结构的方式,并且优化了实现,以便使得最常见的操作非常快。
- 在列表的操作有一个非常常见的编程任务就是是增加一个列表。我们马上想到的有两种方法可以创建更长的列表,可以使用 append 方法或拼接运算符。但是这两种方法那种效率更高呢。这对你来说很重要,因为它可以帮助你通过选择合适的工具来提高你自己的程序的效率。
- 让我们看看四种不同的方式,我们可以生成一个从0开始的n个数字的列表。首先,我们将尝试一个 for 循环并通过创建列表,然后我们将使用 append 而不是拼接。接下来,我们使用列表生成器创建列表,最后,也是最明显的方式,通过调用列表构造函数包装 range 函数。

def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000))
- 下面我们来使用timeit模块来计算上述四种方式的平均运行时长是多少:
- timeit模块:该模块可以用来测试一段python代码的执行速度/时长。
- Timer类:该类是timeit模块中专门用于测量python代码的执行速度/时长的。原型为:class timeit.Timer(stmt='pass',setup='pass')。
- stmt参数:表示即将进行测试的代码块语句。
- setup:运行代码块语句时所需要的设置。
- timeit函数:timeit.Timer.timeit(number=100000),该函数返回代码块语句执行number次的平均耗时。
- 案例:
from timeit import Timer
#被测试的代码块
def func(n):
sum = 0
for i in range(0,100):
sum += i
print(sum)
if __name__ == "__main__":
#参数2:因为参数1必须为字符串且表示的是即将被测试代码块函数的名字,因此参数2必须设置为执行参数1函数所需的设置
t = Timer('func(10)','from __main__ import func')
print(t.timeit(1000))
- 使用timeit模块来计算上述四种方式的平均运行时长是多少:
t1 = Timer("test1()", "from __main__ import test1")
print("concat ",t1.timeit(number=1000), "milliseconds")
t2 = Timer("test2()", "from __main__ import test2")
print("append ",t2.timeit(number=1000), "milliseconds")
t3 = Timer("test3()", "from __main__ import test3")
print("comprehension ",t3.timeit(number=1000), "milliseconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list range ",t4.timeit(number=1000), "milliseconds")
concat 6.54352807999 milliseconds
append 0.306292057037 milliseconds
comprehension 0.147661924362 milliseconds
list range 0.0655000209808 milliseconds
注意:你上面看到的时间都是包括实际调用函数的一些开销,但我们可以假设函数调用开销在四种情况下是相同的,所以我们仍然得到的是有意义的比较。因此,拼接字符串操作需要 6.54 毫秒并不准确,而是拼接字符串这个函数需要 6.54 毫秒。你可以测试调用空函数所需要的时间,并从上面的数字中减去它。剩下的基于列表的其他操作大家也可以使用timeit进行平均耗时的测量计算。
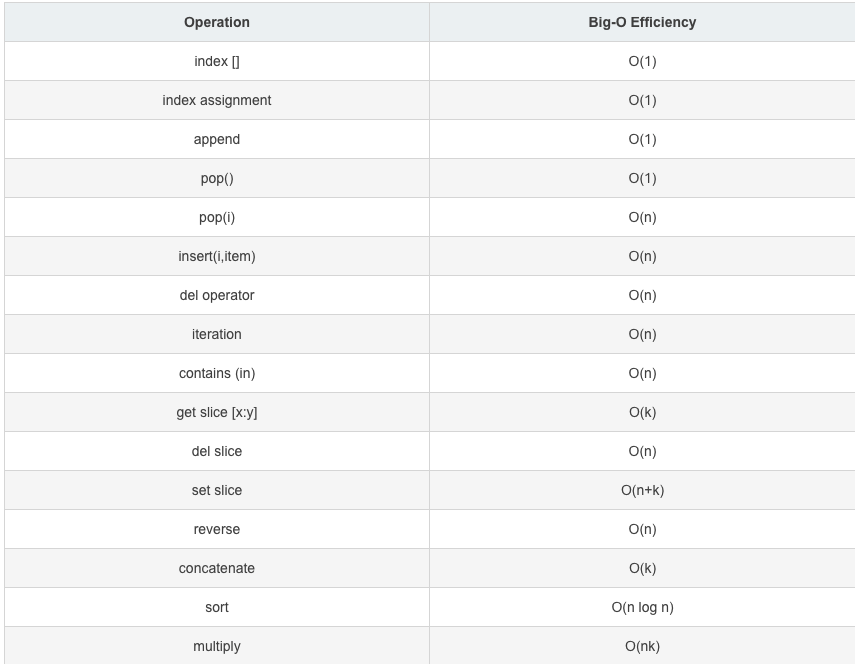
- 列表的相关操作的方法都是被封装好的,我们没有必要对相关操作的底层算法时间进行分析,下面直接给出大家一张基于列表操作的时间复杂度的表,供大家参考:
三.字典
- python 中第二个主要的数据结构是字典。你可能记得,字典和列表不同,你可以通过键而不是位置来访问字典中的项目。
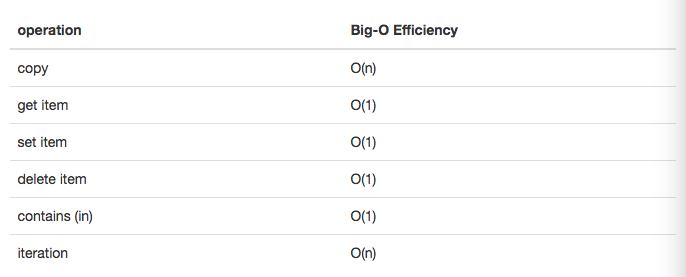
- 字典的时间复杂度: