1、django的orm数据库查询的优化
"""
only的作用:括号内传字段,得到的结果是一个列表套数据对象,该对象内只含有括号内指定的字段属性,对象点字段属性是不会走数据库查询的,但是你一旦点了非括号内的字段,它也能过获取数据,只不过是重新走数据库查询的
defer的作用:括号内传字段,得到的结果是一个列表套数据对象,该对象内没有括号内指定的字段属性,对象点括号内字段属性会重走数据库,但是你一旦点了非括号内的字段属性 是不走数据库的
"""
- select_related与prefetch_related
"""
select_related内部是连表操作,先将关系表全部链接起来拼接成一张大表,之后再一次性查询出来
封装到对象中去,数据对象之后在获取任意表中数据的时候都不需要再走数据库了,select_related括号内只能传外键字段 并且不能是多对多字段 只能是一对多和一对一
prefetch_related内部是子查询(即可能是多次查询),但是给你的感觉就像是连表操作,内部通过子查询将外键关联表中的数据全部封装到对象中,之后对象点当前表或者外键关联表中的字段也都不需要走数据库了
优缺点比较:
select_related连表操作,好处在于只走一次SQL查询,耗时在连表操作
prefetch_related子查询 耗时在查询的次数
"""
2、django的请求生命周期
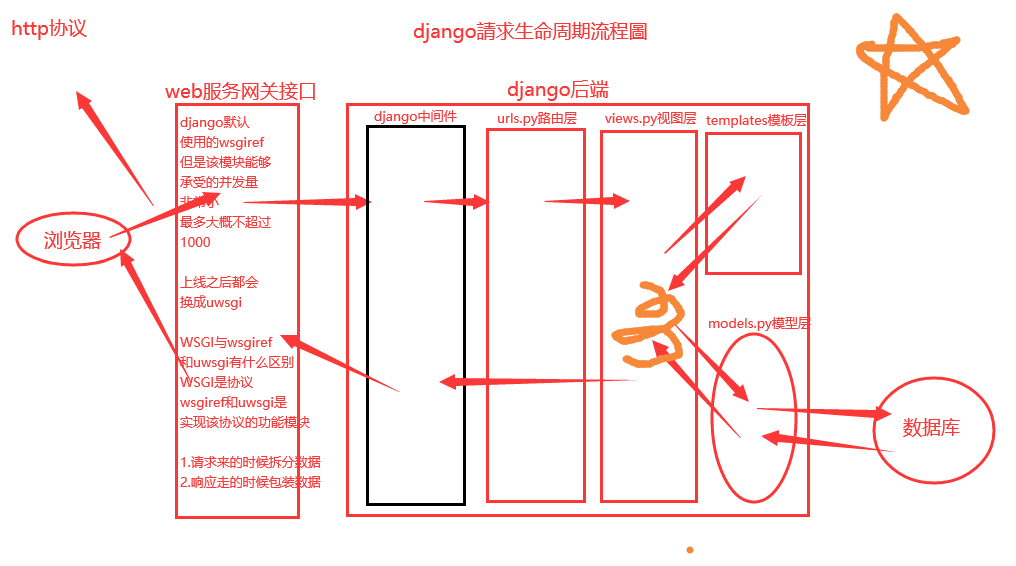
"""
django中间件的流程
当请求到达中间件,先按照中间件的注册顺序执行每个中间件的process_request方法,如果process_request方法返回的是none,就继续执行下面的中间件的process_request方法;如果返回的是HttpResponse对象,那就不再执行后面的process_request方法,而是执行当前中间件对应的process_response方法,将HttpResponse对象返回给浏览器。
当process_request方法都执行完后,路由匹配,找到对应的视图函数,但是这里它先不执行视图函数,而是去执行中间件的process_view方法,process_view方法返回的none,继续按顺序执行,等到所有的process_view方法执行完成之后再执行视图函数,如果process_view方法返回值是一个HttpResponse对象,则下面的process_view方法以及视图函数都不执行,直接从最后一个中间件的process_response方法开始执行
"""
3、django开发中数据库做过什么优化?
"""
1、设计表时,尽量减少使用外键,因为外键约束会影响插入和删除的性能
2、应当使用缓存,减少对数据库的访问
3、在orm框架下设置表时,能用vachar确定字段长度时,就别用text
4、可以给搜索频率高的字段属性,在定义时创建索引
5、如果一个页面需要多次连接数据库,最好一次性取出所有需要的数据,坚守对数据库的查询次数
"""
4、python中三大框架的各自应用场景
"""
- django:大而全,自身就有很多的功能模块,可以用来快速开发
- flask:轻量级,主要是用来写接口的,实现前后端分离,提升开发效率,自身功能比较少,但是第三方模块非常多
- tornado:可支持高并发,一般用于对并发量要求很高的web服务
"""
5、restful规范
"""
1)为什么要指定接口规范
在前后台分离情况下,后台可以采用不同的后台语言,开发出类似的功能,所以前后台请求响应的规则是一致的;如果安装一套标准来编写接口,后台不管是什么语言,前台都可以采用一样的方式进行交互。反过来,后台也不需要管前台到底采用何种方式请求(页面、工具、代码)
2)通用的接口规范:Restful接口规范 - 规定了url如何编写;请求方式的含义;响应的数据规则
i)url编写
https协议 - 保证数据安全性
api字眼 - 标识操作的是数据
v1、v2字眼 - 数据的不同版本共存
资源复数 - 请求的数据称之为资源
拼接条件 - 过滤群查接口数据(https://api.baidu.com/books/?limit=3&ordering=-price)
ii)请求方式
/books/ - get - 群查
/books/(pk)/ - get - 单查
/books/ - post - 单增
/books/(pk)/ - put - 单整体改
/books/(pk)/ - patch - 单局部改
/books/(pk)/ - delete - 单删
iii)响应结果
网络状态码与状态信息:2xx | 3xx | 4xx | 5xx
200:常规请求 201:创建成功
301:永久重定向 302:暂时重定向
403:请求权限不足 404:请求路径不存在 405:请求方法不存在
500:服务器异常
数据状态码:前后台约定规则比如 - 0:成功 1:失败 2:成功无结果
数据状态信息:自定义成功失败的信息解释(英文)
数据本体:json数据
数据子资源:头像、视频等,用资源的url链接
"""
6、celery分布式任务队列
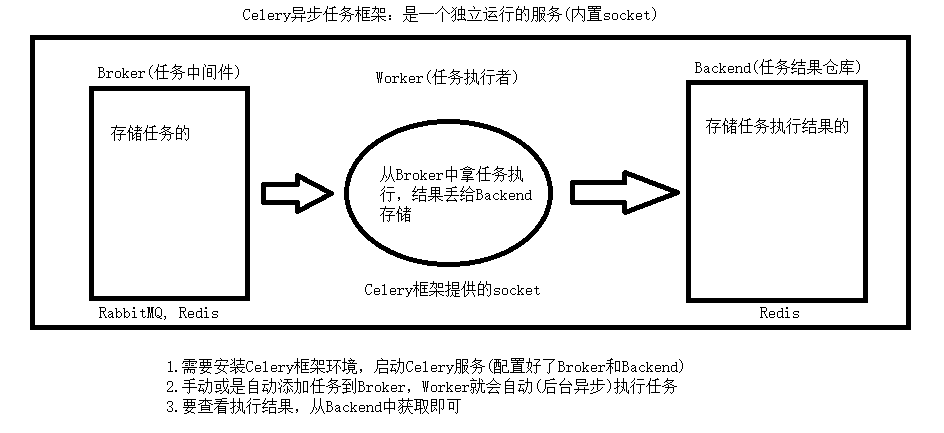
"""
正向代理是对客户端的代理,由客户端设立,客户端了解代理服务器和目标服务器,但是目标服务器不了解真正的客户端是谁;使用正向代理可以达到突破访问限制,提高访问速度,对服务器隐藏客户端ip等目的
反向代理是对服务器的代理,由服务器设立,客户端不了解真正的服务器是谁,使用反向代理可以达到负载均衡,保障服务端安全,对客户端隐藏服务器ip等目的
"""
7、cookie、session、token
"""
session 是存储在服务器上的,cookie是存储在客户端浏览器上的,两者其实是相辅相成的
当用户首次访问服务器的时候会为每一个用户单独创建一个session对象,并且为每一个session分配一个唯一的id(sessionid),sessionid通过cookie保存到客户端,当用户再次访问服务器时,需要将对应的sessionid携带给服务器,服务器通过这个唯一的sessionid就可以找到相对应的session
token:是不存储在服务器上的,所以它低消耗,token的签发校验都是基算法的,安全
"""
8、HTTP与HTTPS
"""
http协议传输的数据是未加密的,也就是明文的,因此使用HTTP协议传输的一些隐私的数据信息是不安全的,为了保证这些隐私的数据能加密传输,于是网景公司设计了ssl协议用来对数据进行加密,从此就诞生了HTTPS。简单来说HTTPS就是由ssl+http协议构建的可对数据进行加密的一种传输协议。
区别:
1、HTTPS协议是需要ca申请证书,需要收取费用
2、HTTP协议是明文,不安全的,HTTPS协议是加密的,安全性高
3、HTTP使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443
4、HTTP的连接很简单,是无状态的,HTTPS协议是加密连接的
"""
9、websocket协议以及原理
"""
网络协议
HTTP 不加密传输
HTTPS 加密传输
上面两个都是短链接/无链接
WebSocket 加密传输
浏览器和服务端创建链接之后默认不断开(联想网络编程TCP recv和send方法)
它的诞生能够真正的实现服务端给客户端推送消息
"""
"""
websocket实现原理可以分为两部分
1.握手环节(handshake):并不是所有的服务端都支持websocket 所以用握手环节来验证服务端是否支持websocket
2.收发数据环节:数据解密
"""
"""
1.握手环节
浏览器访问服务端之后浏览器会立刻生成一个随机字符串
浏览器会将生成好的随机字符串发送给服务端(基于HTTP协议 放在请求头中),并且自己也保留一份
服务端和客户端都会对该随机字符串做以下处理
1.1 先拿随机字符串跟magic string(固定的字符串)做字符串的拼接
1.2 将拼接之后的结果做加密处理(sha1+base64)
服务端将生成好的处理结果发送给浏览器(基于HTTP协议 放在响应头中)
浏览器接受服务端发送过来的随机字符串跟本地处理好的随机字符串做比对,如果一致说明服务端支持websocket,如果不一致说明不支持
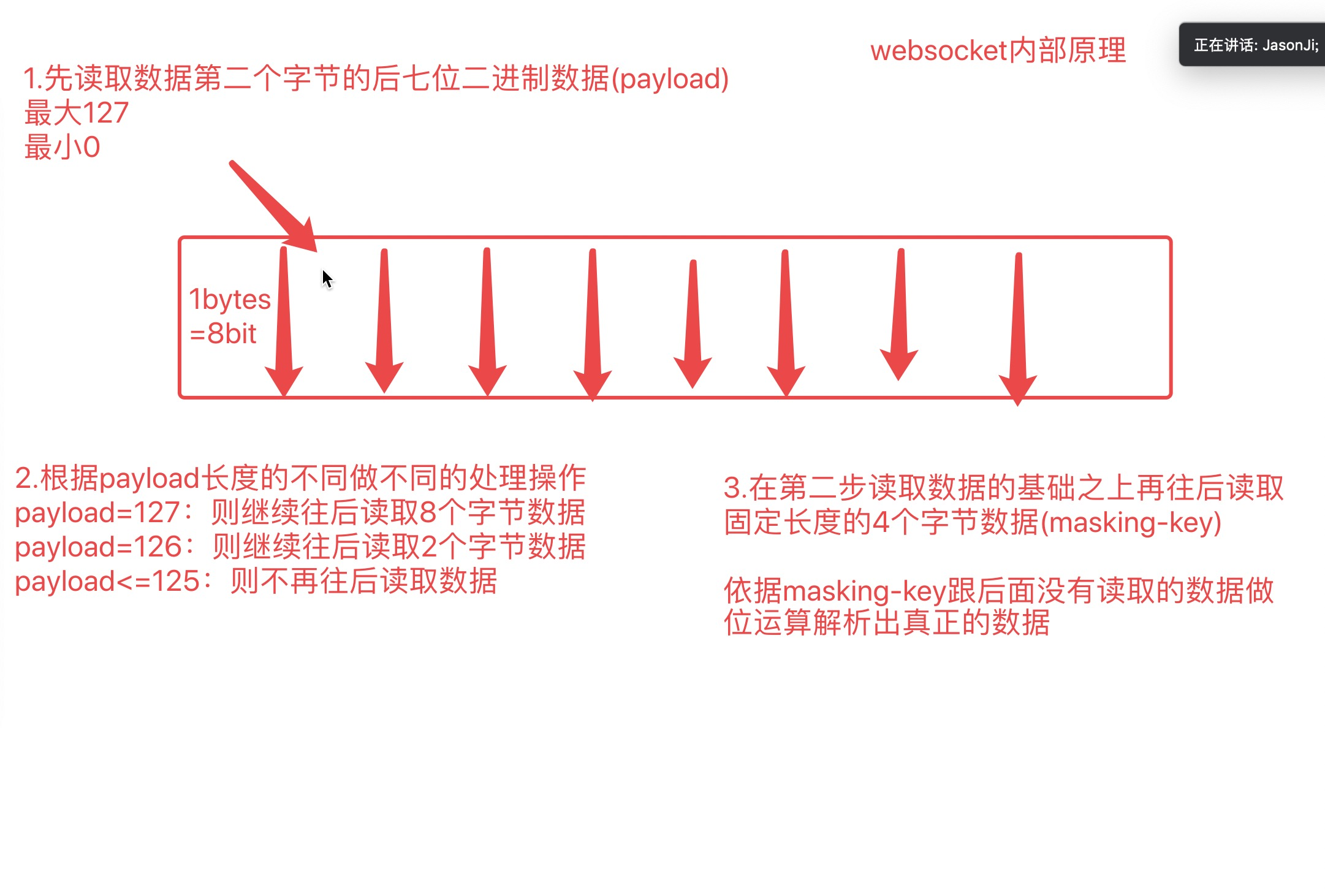
2.收发数据环节
前提知识点:
1.基于网络传输数据都是二进制格式 在python中可以用bytes类型对应
2.进制换算
先读取第二个字节的后七位数据(payload) 根据payload做不同的处理
=127:继续往后读取8个字节数据(数据报10个字节)
=126:继续往后读取2个字节数据(数据报4个字节)
<=125:不再往后读取(数据2个字节)
上述操作完成后,会继续往后读取固定长度4个字节的数据(masking-key)
依据masking-key解析出真实数据
"""
# 关键字:magic string、sha1/base64、payload(127,126,125)、masking-key
10、django的request对象是在什么时候创建的?
"""
`class WSGIHandler(base.BaseHandler):`
`-------request = self.request_class(environ)`
请求走到WSGIHandler类的时候,执行**call**方法,将environ封装成了request
"""