1.Mapreduce的shuffle机制:
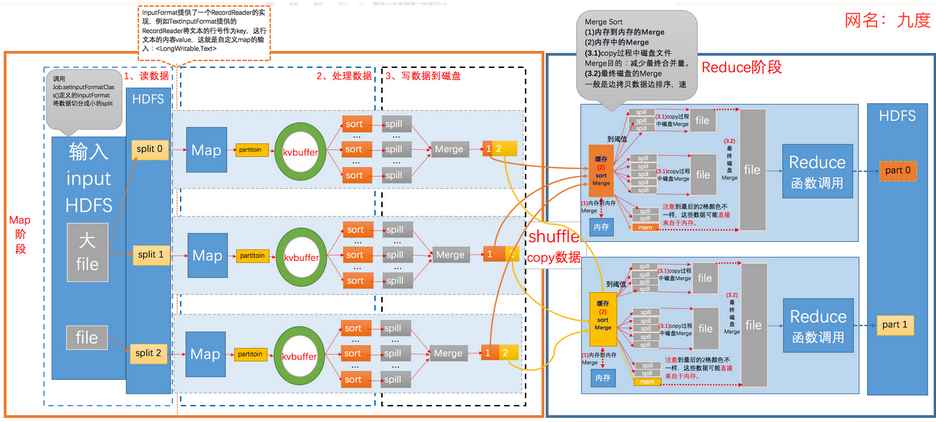
Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle
将maptask处理后的输出结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序
MapReduce程序的执行过程分为两个阶段:Mapper阶段和Reducer阶段。
1.MapReduce的Map阶段:
1.1.从HDFS读取数据:
由FileInputFormat实现类的getSplits()方法将待处理数据执行逻辑切片,默认切片的类为FileInputFormat,通过切片
输入文件将会变成split1、split2、split3……随后对输入切片split按照一定的规则解析成键值对<k1,v1>,在MapTask进行读取
数据时,其中默认处理的类为TextInputFormat,并通过记录读取器RecordReader的read()方法一次读取一行,并返回key和
value,其中k1就是读到的一行文本的起始偏移量,v1就是行文本的内容。
调用自己编写的Map逻辑,Maptask会对每一行<k1,v1>输入数据调用一次我们自定义的map()方法,
Map使用context.write输出键值对<k2,v2>,其输出结果由OutPutCollector将每个Map任务的键值对输出到内存所构造
的一个环形缓冲区中,其数据结构其实就是个字节数组,叫Kvbuffer,Mapper中的Kvbuffer的大小默认100M,spill一般会在
Buffer空间大小的80%开始进行spill溢出到文件,在溢出之前,按照一定的规则对输出的键值对<k2,v2>进行分区:分区的规
则是针对k2进行的,比如说k2如果是省份的话,那么就可以按照不同的省份进行分区,同一个省份的k2划分到一个区,注意:
默认分区的类是HashPartitioner类,这个类默认只分为一个区,因此Reducer任务的数量默认也是1.注意:如reduce要求得
到的是全局的结果,则不适合分区!然后再对每个分区中的键值对进行排序;注意:所谓排序是针对k2进行的,v2是不参与排
序的,如果要让v2也参与排序,需要自定义排序的类,此时得到的溢出文件分区且区内有序;不断溢出,不断形成溢出文件;
在MapTask结束前会对这些spill溢出文件进行归并排序Merge,形成MapTask的最终结果文件
注:Combiner存在的时候,此时会根据Combiner定义的函数对map的结果进行合并
由于job的每一个map都会根据reduce(n)数将数据输出结果分成n个partition,hadoop中是等job的第一个map结束后,
所有的reduce就开始尝试从完成的map中下载该reduce对应的partition部分数据(网络传输)到ReduceTask的本地磁盘工作
目录,当所有map输出都拷贝完毕之后,所有数据被最后合并成一个整体有序的文件,作为reduce任务的输入,Reducetask
真正进入reduce函数的计算阶段
Reduce在这个阶段,框架为已分组的输入数据中的每个 <key, (list of values)>对调用一次 reduce()方法。Reduce
任务的输出通常是通过调用 OutputCollector.collect(WritableComparable,Writable)写入文件系统
注意:Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速
度就越快缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
2.Mapreduce中的Combiner:
(1)combiner是MR程序中Mapper和Reducer之外的一种组件
(2)combiner组件的父类就是Reducer
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果;
(4) combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
具体实现步骤:
1、 自定义一个combiner继承Reducer,重写reduce方法
2、 在job中设置: job.setCombinerClass(CustomCombiner.class)
(5) combiner能够应用的前提是不能影响最终的业务逻辑而且,combiner的输出kv应该跟reducer的输入kv类型要
对应起来
Combiner的使用要非常谨慎因为combiner在mapreduce过程中可能调用也肯能不调用,可能调一次也可能调多次所以:
combiner使用的原则是:有或没有都不能影响业务逻辑
参考文章:https://blog.csdn.net/aijiudu/article/details/72353510