在这部分中,主要是添加一些JQ的方法和属性,如:
JQuery:2.0.3 JQ版本
constructor:JQuery 重新指向JQ构造函数
init(): 初始化和参数管理的方法。
selector:存储选择字符串
length:this对象的长度
toArray():转换数组的方法
get():转原生集合
pushStack():jQuery的入栈
each():遍历集合
ready():dom加载的接口。
slice():集合的截取
first():集合的第一项
last():集合的最后一项
eq():返回集合的某项
map():对集合进行遍历操作
end():查找当前对象在栈中的下一个对象
push:数组的push方法 (内部使用)
sort:数组的sort方法(内部使用)
splice:数组的splice方法(内部使用)
代码解析:
这部分的代码都包含在
jQuery.fn = jQuery.prototype = {
};
首先是对JQ版本的赋值和重指向:
jquery: core_version,
constructor: jQuery,
这里需要注意的是重指向,看如下代码:
function Obj() { } Obj.prototype.age = 10; var o1 = new Obj(); console.log(o1.constructor); //function Obj(){} function ObjNew() { } ObjNew.prototype = { age:10 } var o1New = new ObjNew(); console.log(o1New.constructor); //function Object(){}
运行代码可以看到,第二种通过字面量赋值的方式,对象上的constructor会丢失。因为这种方式是将原型上的对象进行覆盖操作,而不是添加。所以在JQ源码中需要重新指定一下。
INIT方法:
init方法是JQ最先执行的方法,通过这段代码进行调用:
jQuery = function( selector, context ) { // The jQuery object is actually just the init constructor 'enhanced' return new jQuery.fn.init( selector, context, rootjQuery ); },
init方法会接收三个参数,分别是:
selector:$()括号中的第一个参数。如:"#id" ".class" "<li>" document function()等
context:执行的上下文
rootJquery:JQ的根对象。
然后定义变量,并检查selector是否为空也就是对 $(""),$(null),$(undefind),$(false) 进判断。
var match, elem; // HANDLE: $(""), $(null), $(undefined), $(false) if ( !selector ) { return this; }
通过校验之后,接着是判断selector的类型:
if ( typeof selector === "string" ) { //实现代码 } else if ( selector.nodeType ) { //实现代码 } else if ( jQuery.isFunction( selector ) ) { //实现代码 }
依次对字符串、节点、函数进行判断,并分别进行了单独的处理
先对字符串中的代码进行解析:
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) { // Assume that strings that start and end with <> are HTML and skip the regex check match = [ null, selector, null ]; } else { match = rquickExpr.exec( selector ); }
首先对字符串进行判断,如果传入的selector是"<li>"或"<li>1</li><li>2</li>"这种形式想要创建节点的,则 match=[null,"<li>",null]或则 match=[null,"<li>1</li><li>2</li>",null]
否则进行正则匹配,例如:$("#id"),$(".class"),$("div") 这种形式的。
match=null;//$(".class") $("div") $("#div div.class")
match=["#id",null,"id"] //$("#id")
match=["<li>hello","<li>",null] //$("<li>hello")
这里先对JQ的内部执行有一个说明,例如:$("li").css("background","red") 这段代码,对页面上的所有li的背景颜色赋值。那么这句代码的两部分分别做了什么处理呢。
首先 $("li") 其实是选择了页面上所有的li,并返回了一个this对象存放这些li的节点,

然后通过这个对象在对.css方法进行调用,在css方法内部的实现类似于:
for(var i=0;i<this.length;i++){ this[i].style.background="red"; }
了解完这个过程在看下面的代码:
if ( match && (match[1] || !context) ) {
}
这个判断首先判断math不为null,并且match[1]有值,那么这就代表创建标签的语句满足条件,或者context为空,context为空代表是选择id,因为id没有上下文,所以满足这个条件的有:
$("<li>"),$("#id")
接下来在条件里进一步判断:
if ( match && (match[1] || !context) ) { // HANDLE: $(html) -> $(array) if ( match[1] ) { //判断是创建标签还是id } else { //id执行这 }
在这个条件里又将创建标签和查找id区分。
先看创建标签的源码:
context = context instanceof jQuery ? context[0] : context; // scripts is true for back-compat jQuery.merge( this, jQuery.parseHTML( match[1], context && context.nodeType ? context.ownerDocument || context : document, true ) );
这段代码中,先将context赋值,在创建标签时,有是可能需要第二参数,这个第二个参数也就是执行上下文,例如:$("<li>",document) 一般很少这样使用,但是当页面中有iframe时,想在iframe中创建,那么第二参数设置为iframe后,就在iframe中创建了。
context instanceof jQuery ? context[0] : context 这句目的就是将context赋值为原生的节点,当我传递参数时,可能会:
1、$("<li>",document)
2、$("<li>",$(document))
这两种形式,同过这判断是否用第二种形式传入,如果是,则将原生的document对象赋值。
然后用到两个方法:jQuery.merge和jQuery.parseHTML方法。
先说一下jQuery.parseHTML方法,代码如下:
var str = "<li>1</li><li>2</li><li>3</li><li>4</li><li>5</li>"; var arr = jQuery.parseHTML(str, document, true); console.log(arr);
执行结果为,如图:

可以看到这个方法是将字符串转换为数组的形式。需要特别注意的最后一个参数,默认为false,为false代表不可以插入script代码,为true则代表可以。
再看下jQuery.merge方法
这个方法常用的功能就是将两个数组合并,如:
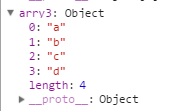
var arry1 = ["a", "b"]; var arry2 = ["c", "d"]; var arry3 = jQuery.merge(arry1, arry2); console.log(arry3); //["a", "b", "c", "d"]
但这里的this对象是个json对象,通过他也可以进行合并。并返回jq想要的json格式。如:
var arry1 = { 0: "a", 1: "b", length:2 }; var arry2 = ["c", "d"]; var arry3 = jQuery.merge(arry1, arry2); console.log(arry3);
结果如下:
接下来处理特殊的形式,也是很少使用的一种创建标签的方式,代码如下:
if ( rsingleTag.test( match[1] ) && jQuery.isPlainObject( context ) ) { for ( match in context ) { // Properties of context are called as methods if possible if ( jQuery.isFunction( this[ match ] ) ) { this[ match ]( context[ match ] ); // ...and otherwise set as attributes } else { this.attr( match, context[ match ] ); } } }
这种匹配的是:$("<li>",{title:"hello",html:"aaaaaaa"}) 后面有个json对象当参数的方式。
如果是这种方式的话,那么会循环这个json对象,先判断json里的属性是否是jq自带的方法,如果是,则直接调用方法,否则,进去else,用jq的attr方法为这个标签加一个属性。
到这里创建标签的方式就介绍完了。下面介绍一下传入id形式的代码。
elem = document.getElementById( match[2] ); // Check parentNode to catch when Blackberry 4.6 returns // nodes that are no longer in the document #6963 if ( elem && elem.parentNode ) { // Inject the element directly into the jQuery object this.length = 1; this[0] = elem; } this.context = document; this.selector = selector; return this;
代码很简单,但需要注意一下判断,这是为了最黑莓浏览器的兼容,因为在黑莓4.6版本的浏览器中,当删除节点之后,还可以用js代码查找到这个节点,
所以需要进行一下父节点的判断,因为任何节点都会有父节点。
接下来也是返回一个JQ需要的特殊json格式。赋值长度为1,第一个对象是当前查找到的对象。然后把上下文赋值document,赋值selector。
到这里已经把创建标签和id查找的源码分析完了,其他复杂查找的代码会进入下面的代码:
} else if ( !context || context.jquery ) { return ( context || rootjQuery ).find( selector ); // HANDLE: $(expr, context) // (which is just equivalent to: $(context).find(expr) } else { return this.constructor( context ).find( selector ); }
这段代码的判断就是要保证$("ul",document).find("li") $("ul",$(document)).find("li") 这两种形式,都会执行:jQuery(document).find();这个方法。
到这就把当参数是字符串传入时,要执行的代码解析完了,下面分析传入节点或者方法时要执行的代码。
selector为节点时,执行的代码:
else if ( selector.nodeType ) { this.context = this[0] = selector; this.length = 1; return this; }
首先先判断传入的是不是节点,如果是节点,肯定就会有nodeType,然后设置上下文、长度并返回一个类似数组的json对象。
当selector为函数时,执行的代码:
else if ( jQuery.isFunction( selector ) ) { return rootjQuery.ready( selector ); }
我们在页面中使用jQuery的时候,一般都会先这样写:
$(function(){ //代码 })
或者
$(documnet).ready(function(){ //代码 })
从源码可以看出,当使用第一种方式写的时候,其实在源码中就是转换为第二种方式,所以这两种方式是等价的。
if ( selector.selector !== undefined ) { this.selector = selector.selector; this.context = selector.context; }
有时在写代码时可能会这么写:$( $("div") ),虽然很少有人这么写,但这里也对这种情况进行了处理,从源码可以看出,这种写法其实最后被转换成:$("div")这种形式。
接下来是init方法的最后一行,进行返回
return jQuery.makeArray( selector, this );
这里用到了一个方法,jQuery.makeArry方法,这个方法是将选择到节点返回一个原生数组,例如:
$(document).ready(function () { var arr = $.makeArray($("div")); console.log(arr); //[div, div, div, div, div] })
但是我们可以看到,在jQuery源码内部还有一个参数this,当传入第二个参数时,会返回一个jQuery需要的json对象。例如:
$(document).ready(function () { var arr = $.makeArray($("div"), {length:5}); console.log(arr); //Object {5: div, 6: div, 7: div, 8: div, 9: div, length: 10} })
在指定第二个对象时,我们需要传入一个length属性,这是jQuery需要的,这样就返回了一个json对象。
到这里,init方法就结束了。
继续往下看,接着开始定义了两个变量
// Start with an empty selector selector: "", // The default length of a jQuery object is 0 length: 0,
在接着声明了一个toArry的实例方法。注意,在这里定义的都是实例方法,在jQuery内部有实例方法还有工具方法,工具方式是最底层的方法,有时实例方法会调用工具方法。
toArray: function() { return core_slice.call( this ); },
代码很简单就一行,这里用到了原生数组的slice方法,这个方法是截取数组的某个一部分,如果不传值,就返回一个副本,所以这个方法就返回了一个原生数组。
在接着声明了get方法。get方法也是返回原生的对象,如果传值则返回某一个,不传的话则返回一个集合。
// Get the Nth element in the matched element set OR // Get the whole matched element set as a clean array get: function( num ) { return num == null ? // Return a 'clean' array this.toArray() : // Return just the object ( num < 0 ? this[ this.length + num ] : this[ num ] ); },
从代码可以看到,如果num为null时,则直接调用toArry方法,返回一个数组集合,当传入num的时候,先判断是否大于0,如果大于0则直接返回集合中对应的对象,如果小于0,则倒序查找,如-1,则返回最后一个。
接着声明了pushStack方法,这个方法是入栈的方法,在外部我们很少使用这个方法,但是在jQuery内部,则经常使用,所以这个方法特别重要。
先说明一下什么是入栈,入栈和队列不一样,队列像买票一样,先进先出,而入栈则是先进后出,要理解他们的区别。
// Take an array of elements and push it onto the stack // (returning the new matched element set) pushStack: function( elems ) { // Build a new jQuery matched element set var ret = jQuery.merge( this.constructor(), elems ); // Add the old object onto the stack (as a reference) ret.prevObject = this; ret.context = this.context; // Return the newly-formed element set return ret; },
先声明一个ret,然后用merge方法,将传入的对象和一个空对象合并,也就是this.constructor(),
然后到了最关键的一步,ret.prevObject赋值为this也就是说通过这个属性进行关联,以后在查找的时候,通过prevObject就可以找到了上一个对象了。
然后赋值上下文并返回。
看下面的代码:
<div>aaaaa</div> <span>vvv</span> <script> $("div").pushStack($("span")).css("background", "red"); </script>
页面中只有span标签的背景颜色变为红色,也就说明了栈的执行顺序,对最后一个进行操作,那么如果想对它的下一层进行操作呢:
$("div").pushStack($("span")).css("background", "red").end().css("background","blue");
通过end方法来找到它的下一层,其实在end方法内部,就是通过ret.prevObject的属性来找到的。
each方法:
// Execute a callback for every element in the matched set. // (You can seed the arguments with an array of args, but this is // only used internally.) each: function( callback, args ) { return jQuery.each( this, callback, args ); },
源码中,each方法是又调用了jQuery的工具方法each进行了第二次调用,等到解析工具方法的时候在来解析。
ready方法:
ready: function( fn ) { // Add the callback jQuery.ready.promise().done( fn ); return this; },
ready方法也一样,先不做讲解。
slice方法:
slice: function() { return this.pushStack( core_slice.apply( this, arguments ) ); },
jQuery的slice方法和数组中的slice方法基本一致,只是这里调用了入栈的方法,如:
<div>aaaaa</div> <div>aaaaa</div> <div>aaaaa</div> <div>aaaaa</div> <div>aaaaa</div> <script> $("div").slice(1, 4).css("background", "red"); </script>
通过代码可以看到这里对选择的第二个到第四个的背景颜色进行了改变,在栈的最底层存放这个五个div,然后在它的上层存放选择的div,并通过prevObject属性链接到最底层的五个div。
eq方法:
first: function() { return this.eq( 0 ); }, last: function() { return this.eq( -1 ); }, eq: function( i ) { var len = this.length, j = +i + ( i < 0 ? len : 0 ); return this.pushStack( j >= 0 && j < len ? [ this[j] ] : [] ); },
这里有三个方法,其实通过源码可以看到我们常用的first方法和last方法其实都是在内部调用了eq方法,所以在这里一起说了。
只看eq方法就可以了,先获取调用对象的length,然后对j进行赋值,其实这里j是真正索引。
j = +i + ( i < 0 ? len : 0 );
这句话是处理当传入的i为负数时,例如-1,则查找最后一个元素。
然后返回要查找的元素。
map方法:
map: function( callback ) { return this.pushStack( jQuery.map(this, function( elem, i ) { return callback.call( elem, i, elem ); })); },
这个方法也等到了解析工具方法时说明,这里顺便说一下如何使用这个map方法:
var arr=[1,2,3]; arr = $.map(arr, function (elem, index) { return elem * index; }) console.log(arr);//[1,2,6]
end方法:
end: function() { return this.prevObject || this.constructor(null); },
从源码可以看出,就是通过prevObject的属性来找到它的下层对象,这里的this.constructor(null)则是为了防止多次调用end,如果已经调用到尽头,则返回一个空对象。
// For internal use only. // Behaves like an Array's method, not like a jQuery method. push: core_push, sort: [].sort, splice: [].splice
这里只是把数组的这些方法挂载到这几个变量上,以供内部使用,另外注释上的意思也说了不建议在外部使用。
到这里第二部分就讲解完了。下一篇对第三部分进行讲解,另外再次推荐去网易云课堂上,标题是"逐行分析jQuery源码的奥秘",这套视频。这里的内容大部分都是这套教程上的。个人感觉非常不错,推荐一下。