之前学过的一个课程,最近又看了一遍,发现要是自己写的话,还是写不出来,所幸就照着视频又操作了一遍。哎,啥时候能学会测试开发呢,有点迷茫,但是又不想放弃,每天坚持一会吧。。每天坚持写点啥,让自己有点进步。
#coding:utf-8
import requests
import re,json,os
from requests.exceptions import RequestException
from multiprocessing import Pool #引入多线程
'''使用requests 与 正则表达式爬取 猫眼电影榜单top100'''
def get_one_page(url):
try:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.152 Safari/537.36'}
html = requests.get(url,headers=header)
#不加编码格式,显示的返回页面会显示乱码
html.encoding='utf-8'
if html.status_code == 200:
return html.text
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-src="(.*?)".*?name">'
'<a.*?title="(.*?)".*?</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>',re.S)
items = re.findall(pattern,html)
# print(items)
for item in items:
yield{
"id" :item[0],
"img":item[1],
"name":item[2],
"actar":item[3].strip()[3:],
"time":item[4].strip()[5:],
"score":item[5]+item[6]
}
def write_to_file(content):
dir = os.getcwd()
dir_to=dir +'\static\'
print(dir_to)
#不加encoding 保存的信息是unicode编码
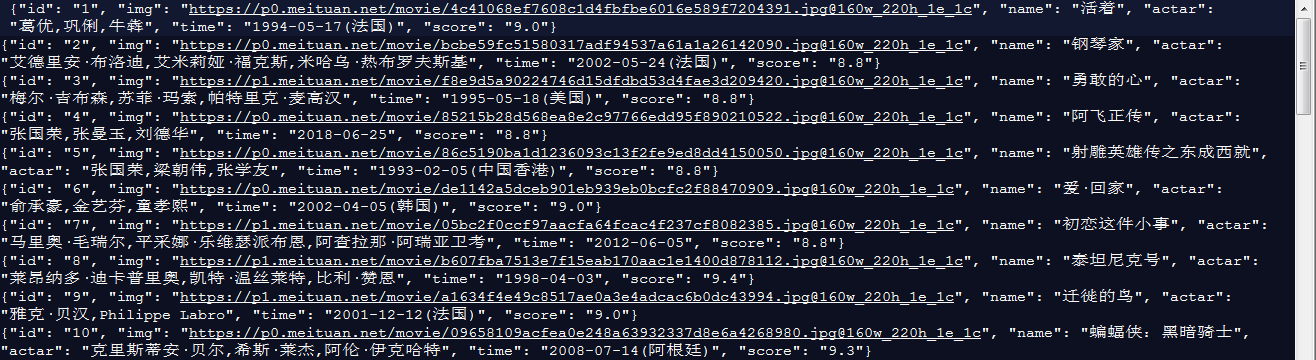
with open(dir_to+'film100.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+' ')
f.close()
def main(offset):
url ='https://maoyan.com/board/4?offset='+ str(offset)
print(url)
html=get_one_page(url)
items=parse_one_page(html)
for item in items :
print(item)
write_to_file(item)
if __name__=='__main__':
'''未使用进程池'''
# for i in range(10):
# #offset翻页传的数据,模拟0-90 的数据,即是前10页的数据
# main(i*10)
'''使用进程池'''
pool=Pool()
pool.map(main,[ i*10 for i in range (10)])