目前所学的复杂数据类型有三种array,map,struct。
复杂数据类型: 如何存 如何取(*****)
1.array(用这种数据类型的特点就是集合里的每一个字段都是一个具体的信息,不会是那种key与values的关系)
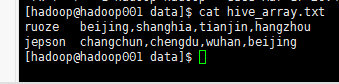
load数据如上所示,一共两个字段,ruoze 和他们工作的城市
也就是字段与字段之间的分割用table array字段之间的分割用“,”。
create table hive_array(
name string,
work_locations array<string>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '--表示字段与字段之间的分割用table
COLLECTION ITEMS TERMINATED BY ',';--表示集合之内的分割用逗号。集合就是代表array这个复杂数据类型里边的数据之间的分割。
load data local inpath '/home/hadoop/data/hive_array.txt'
overwrite into table hive_array;

select * from hive_array where array_contains(work_locations,'tianjin');
array_contains这个函数是array_contains(array字段,‘字段包含的内容’)
比如以上就是array字段包含tianjin的数据。
2.map : key-value
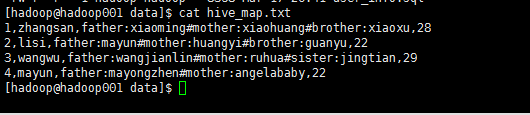
以上数据一共有3个字段,分别为id,name,member。其中member里的内容都是以key:values的形式出现的,若是这种形式一般用map这种复杂数据类型
father:xiaoming#mother:xiaohuang#brother:xiaoxu
create table hive_map(
id int,
name string,
members map<string,string>,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','--字段之间用逗号分隔
COLLECTION ITEMS TERMINATED BY '#'--集合也就是map字段中的数据key:values相互之间用#分割
MAP KEYS TERMINATED BY ':';map中key与values之间用冒号分割
load data local inpath '/home/hadoop/data/hive_map.txt'
overwrite into table hive_map;
3.struct struct('a',1,2,3,4)(这个数据类型的特点就是可以包含各种各样的数据类型。但是struct可以是任意数据类型,在写struct数据类型时,在<>中要写清楚struct字段中的字段名称跟数据类型)
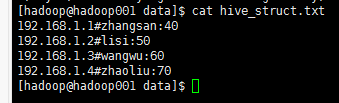
create table hive_struct(
ip string,
userinfo struct<name:string,age:int>--struct这个数据类型中的字段名,字段类型
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '#'--字段之间的分割用#
COLLECTION ITEMS TERMINATED BY ':';--集合之间的分割用冒号
load data local inpath '/home/hadoop/data/hive_struct.txt'
overwrite into table hive_struct;