mysql分库分表
参考:
https://blog.csdn.net/xlgen157387/article/details/53976153
https://blog.csdn.net/clevercode/article/details/50877580
https://www.cnblogs.com/phpper/p/6937896.html
https://www.cnblogs.com/try-better-tomorrow/p/4987620.html
数据库分库分表策略的具体实现方案
相关文章:
1、 使用Spring AOP实现MySQL数据库读写分离案例分析
2、MySQL5.6 数据库主从(Master/Slave)同步安装与配置详解
3、MySQL主从复制的常见拓扑、原理分析以及如何提高主从复制的效率总结
4、使用mysqlreplicate命令快速搭建 Mysql 主从复制
一、MySQL扩展具体的实现方式
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
关于数据库的扩展主要包括:业务拆分、主从复制,数据库分库与分表。这篇文章主要讲述数据库分库与分表
(1)业务拆分
在 大型网站应用之海量数据和高并发解决方案总结一二 一篇文章中也具体讲述了为什么要对业务进行拆分。
业务起步初始,为了加快应用上线和快速迭代,很多应用都采用集中式的架构。随着业务系统的扩大,系统变得越来越复杂,越来越难以维护,开发效率变得越来越低,并且对资源的消耗也变得越来越大,通过硬件提高系统性能的方式带来的成本也越来越高。
因此,在选型初期,一个优良的架构设计是后期系统进行扩展的重要保障。
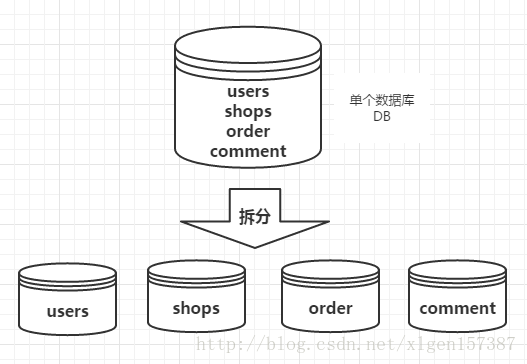
例如:电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。
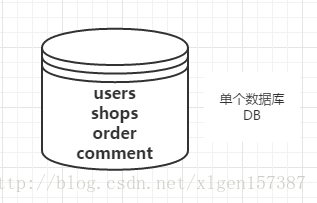
但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
(2)主从复制
1、MySQL5.6 数据库主从(Master/Slave)同步安装与配置详解
2、MySQL主从复制的常见拓扑、原理分析以及如何提高主从复制的效率总结
3、使用mysqlreplicate命令快速搭建 Mysql 主从复制
上述三篇文章中,讲述了如何配置主从数据库,以及如何实现数据库的读写分离,这里不再赘述,有需要的选择性点击查看。
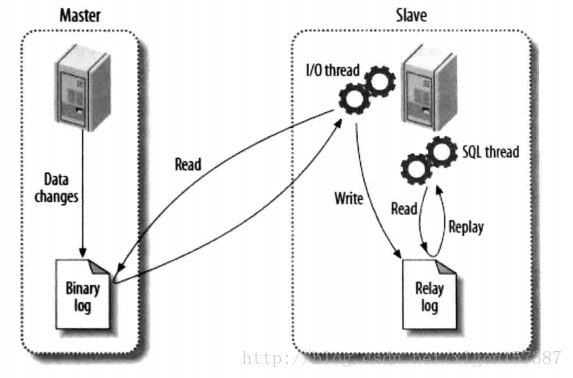
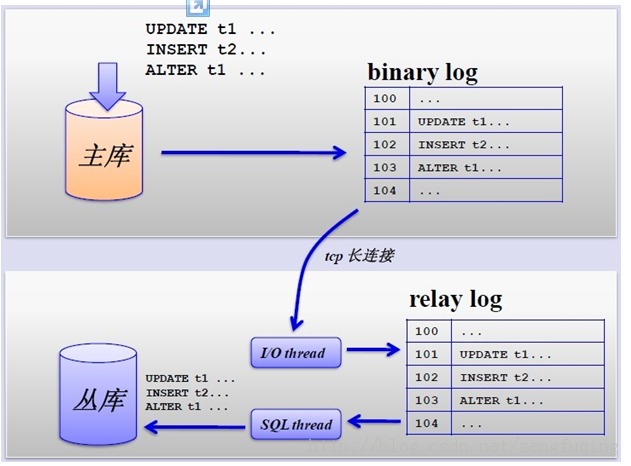
上图是网上的一张关于MySQL的Master和Slave之间数据同步的过程图。
主要讲述了MySQL主从复制的原理:数据复制的实际就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。
(3)数据库分库与分表
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是通过添加更多的机器来共同承担压力。
我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?因此,使用数据库的分库分表,能够立竿见影的提升系统的性能,关于为什么要使用数据库的分库分表的其他原因这里不再赘述,主要讲具体的实现策略。请看下边章节。
二、分表实现策略
关键字:用户ID、表容量
对于大部分数据库的设计和业务的操作基本都与用户的ID相关,因此使用用户ID是最常用的分库的路由策略。用户的ID可以作为贯穿整个系统用的重要字段。因此,使用用户的ID我们不仅可以方便我们的查询,还可以将数据平均的分配到不同的数据库中。(当然,还可以根据类别等进行分表操作,分表的路由策略还有很多方式)
接着上述电商平台假设,订单表order存放用户的订单数据,sql脚本如下(只是为了演示,省略部分细节):
CREATE TABLE `order` (
`order_id` bigint(32) primary key auto_increment,
`user_id` bigint(32),
...
) 当数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量。
这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 user_id%100 获取对应的表进行存储查询操作,示意图如下:
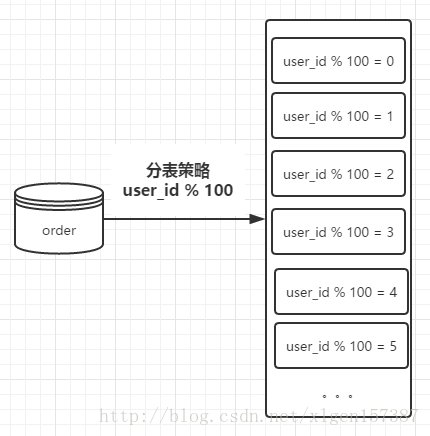
例如,user_id = 101 那么,我们在获取值的时候的操作,可以通过下边的sql语句:
select * from order_1 where user_id= 101其中,order_1是根据 101%100 计算所得,表示分表之后的第一章order表。
注意:
在实际的开发中,如果你使用MyBatis做持久层的话,MyBatis已经提供了很好得支持数据库分表的功能,例如上述sql用MyBatis实现的话应该是:
接口定义:
/**
* 获取用户相关的订单详细信息
* @param tableNum 具体某一个表的编号
* @param userId 用户ID
* @return 订单列表
*/
public List<Order> getOrder(@Param("tableNum") int tableNum,@Param("userId") int userId);xml配置映射文件:
<select id="getOrder" resultMap="BaseResultMap">
select * from order_${tableNum}
where user_id = #{userId}
</select>其中${tableNum} 含义是直接让参数加入到sql中,这是MyBatis支持的特性。
注意:
另外,在实际的开发中,我们的用户ID更多的可能是通过UUID生成的,这样的话,我们可以首先将UUID进行hash获取到整数值,然后在进行取模操作。三、分库实现策略
数据库分表能够解决单表数据量很大的时候数据查询的效率问题,但是无法给数据库的并发操作带来效率上的提高,因为分表的实质还是在一个数据库上进行的操作,很容易受数据库IO性能的限制。
因此,如何将数据库IO性能的问题平均分配出来,很显然将数据进行分库操作可以很好地解决单台数据库的性能问题。
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
还是上例,将用户ID进行取模操作,这样的话获取到具体的某一个数据库,同样关键字有:
用户ID、库容量
路由的示意图如下:
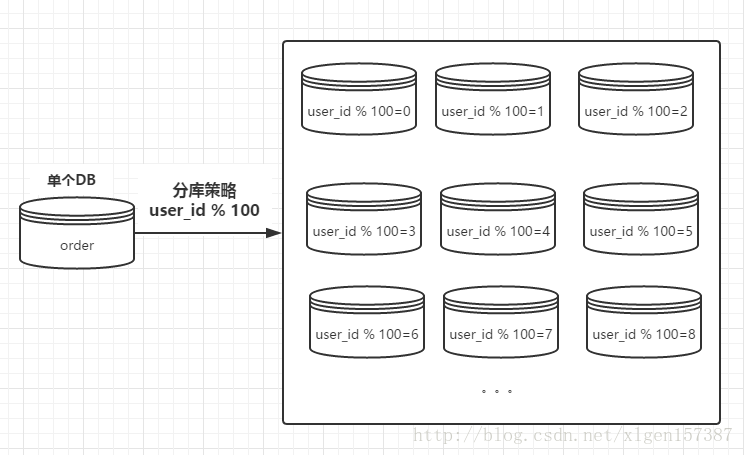
上图中库容量为100。
同样,如果用户ID为UUID请先hash然后在进行取模。
四、分库与分表实现策略
上述的配置中,数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题。
有时候,我们需要同时考虑这两个问题,因此,我们既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
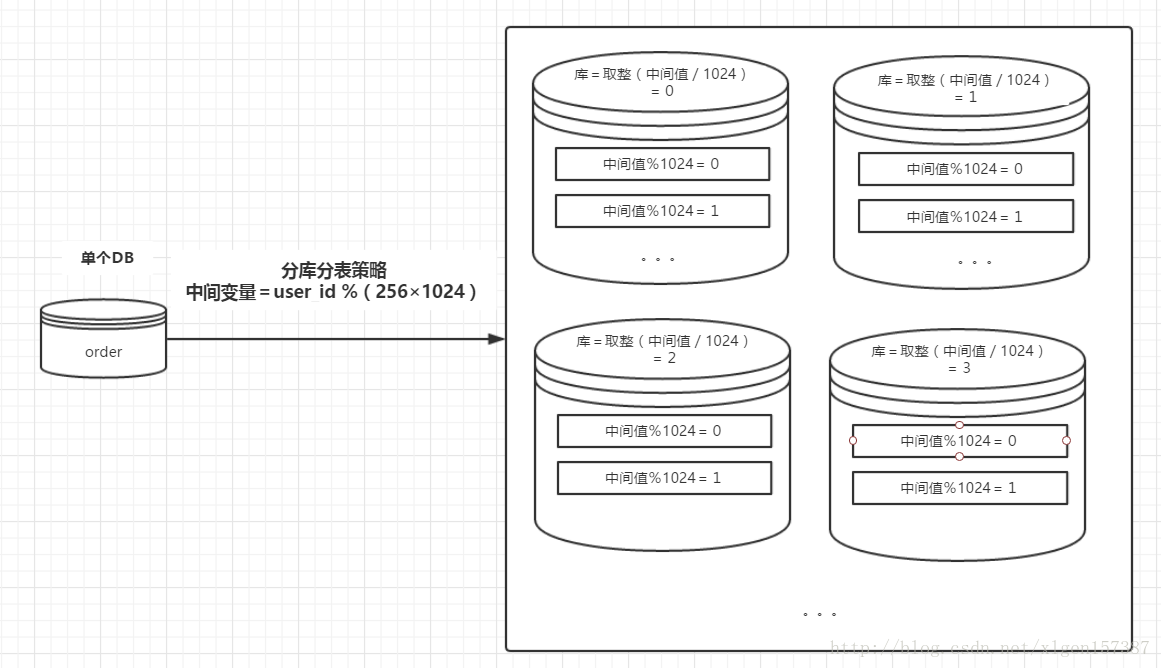
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。
示意图如下:
五、分库分表总结
关于分库分表策略的选择有很多种,上文中根据用户ID应该是比较简单的一种。其他方式比如使用号段进行分区或者直接使用hash进行路由等。有兴趣的可以自行查找学习。
关于上文中提到的,如果用户的ID是通过UUID的方式生成的话,我们需要单独的进行一次hash操作,然后在进行取模操作等,其实hash本身就是一种分库分表的策略,使用hash进行路由策略的时候,我们需要知道的是,也就是hash路由策略的优缺点,优点是:数据分布均匀;缺点是:数据迁移的时候麻烦,不能按照机器性能分摊数据。
上述的分库和分表操作,查询性能和并发能力都得到了提高,但是还有一些需要注意的就是,例如:原本跨表的事物变成了分布式事物;由于记录被切分到不同的数据库和不同的数据表中,难以进行多表关联查询,并且不能不指定路由字段对数据进行查询。分库分表之后,如果我们需要对系统进行进一步的扩阵容(路由策略变更),将变得非常不方便,需要我们重新进行数据迁移。
最后需要指出的是,分库分表目前有很多的中间件可供选择,最常见的是使用淘宝的中间件Cobar。
GitHub地址:https://github.com/alibaba/cobara
文档地址为:https://github.com/alibaba/cobar/wiki
关于淘宝的中间件Cobar本篇内容不具体介绍,会在后边的学习中在做介绍。
另外Spring也可以实现数据库的读写分离操作,后边的文章,会进一步学习。
六、总结
上述中,我们学到了如何进行数据库的读写分离和分库分表,那么,是不是可以实现一个可扩展、高性能、高并发的网站那?很显然还不可以!一个大型的网站使用到的技术远不止这些,可以说,这些都是其中的最基础的一个环节,因为还有很多具体的细节我们没有掌握到,比如:数据库的集群控制,集群的负载均衡,灾难恢复,故障自动切换,事务管理等等技术。因此,还有很多需要去学习去研究的地方。
Mysql数据库常用分库和分表方式
1 分库
1.1 按照功能分库
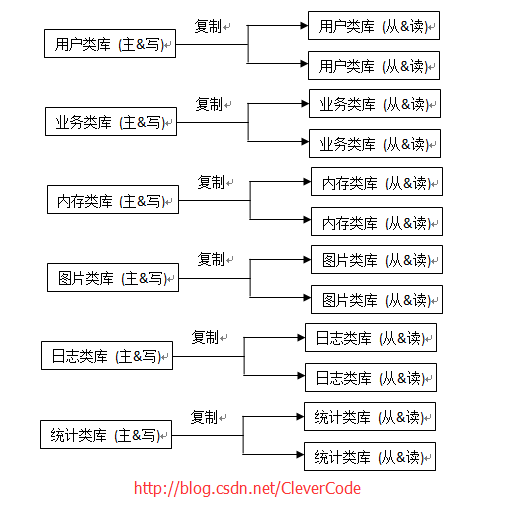
按照功能进行分库。常见的分成6大库:
1 用户类库:用于保存了用户的相关信息。例如:db_user,db_system,db_company等。
2 业务类库:用于保存主要业务的信息。比如主要业务是笑话,用这个库保存笑话业务。例如:db_joke,db_temp_joke等。
3 内存类库:主要用Mysql的内存引擎。前台的数据从内存库中查找,速度快。例如:heap。
4 图片类库:主要保存图片的索引以及关联。例如:db_img_index,db_img_res。
5 日志类库:记录点击,刷新,登录等日志信息。例如:db_log_click,db_log_fresh,db_log_login。
6 统计类库:对业务的统计,比如点击量,刷新量等等。例如db_stat。
1.2 安装城市站分库
如果业务遍布全国,在按照功能分库库,每一个城市复制一份一模一样的库,只是库后缀都是城市名称。比如db_log_click_bj,db_log_click_tj,db_log_click_sh;
2 分表
2.1 水平分割。解决表行数过大问题
对与用户或业务可以按照编号%n,进行分成n表。
例如:笑话表。
tb_joke_01,tb_joke_02,tb_joke_03,tb_joke_04........
2.1.2 按照日期分表
对于日志或统计类等的表。可以按照年,月,日,周分表。
例如 点击量统计。
tb_click_stat_201601,tb_click_stat_201602,tb_click_stat_201603
2.2 垂直分割。解决列过长问题。
1)经常组合查询的列放在一张表中。常用字段的表可以考虑用Memory引擎。
2)把不常用的字段单独放在一张表。
3)把text,blob等大字段拆分出来放在附表中。
3 Mysql数据库常用架构
Mysql分库分表方案
1.为什么要分表:
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。
2. mysql proxy:amoeba
做mysql集群,利用amoeba。
从上层的java程序来讲,不需要知道主服务器和从服务器的来源,即主从数据库服务器对于上层来讲是透明的。可以通过amoeba来配置。
3.大数据量并且访问频繁的表,将其分为若干个表
比如对于某网站平台的数据库表-公司表,数据量很大,这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。
某网站现在的数据量至多是5000万条,可以设计每张表容纳的数据量是500万条,也就是拆分成10张表,
那么如何判断某张表的数据是否容量已满呢?可以在程序段对于要新增数据的表,在插入前先做统计表记录数量的操作,当<500万条数据,就直接插入,当已经到达阀值,可以在程序段新创建数据库表(或者已经事先创建好),再执行插入操作。
4. 利用merge存储引擎来实现分表
如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了。用merge存储引擎来实现分表, 这种方法比较适合.
举例子:
------------------- ----------华丽的分割线--------------------------------------
数据库架构
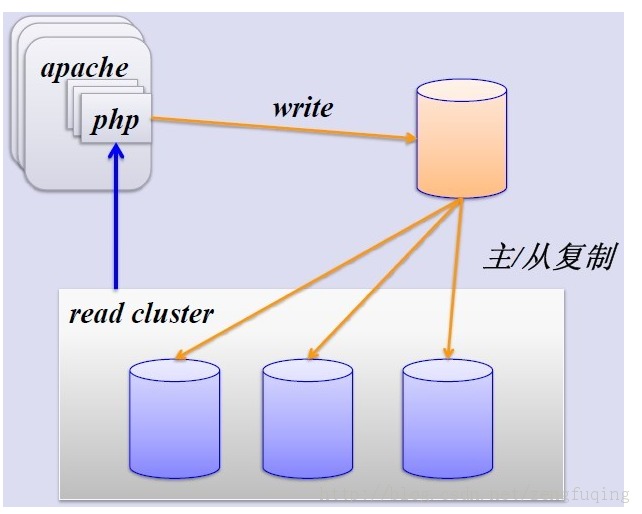
1、简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其图如下:
其主从复制的过程如下图所示:
但是,主从复制也带来其他一系列性能瓶颈问题:
1. 写入无法扩展
2. 写入无法缓存
3. 复制延时
4. 锁表率上升
5. 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
2、MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:
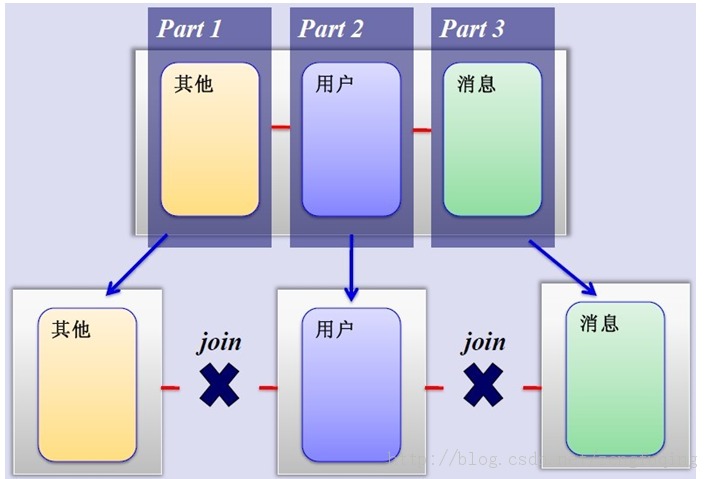
然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平分割呢?
3、MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:
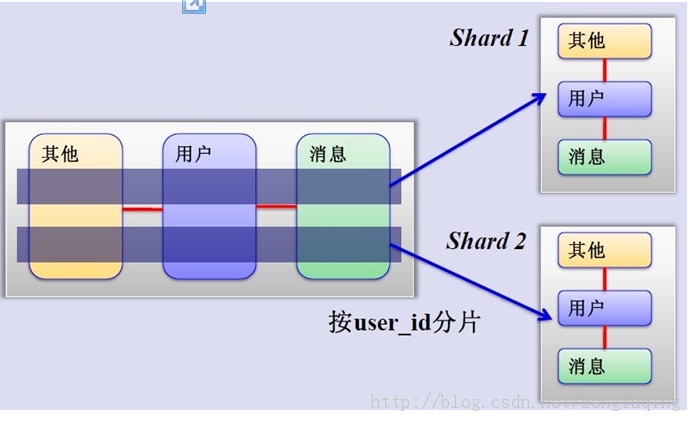
如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:
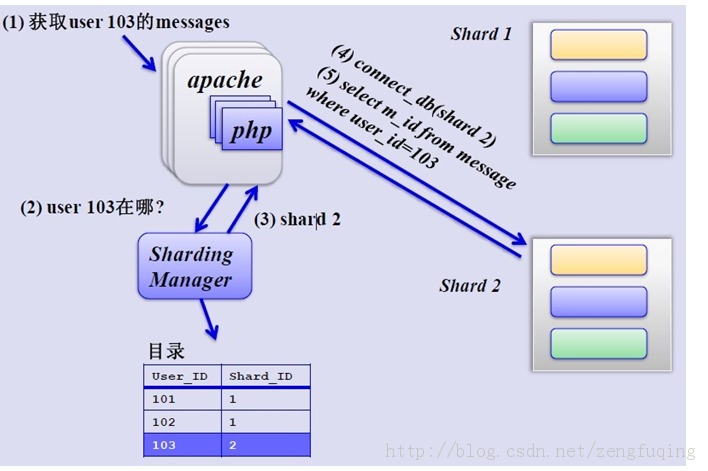
单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库分表规则
设计表的时候需要确定此表按照什么样的规则进行分库分表。例如,当有新用户时,程序得确定将此用户信息添加到哪个表中;同理,当登录的时候我们得通过用户的账号找到数据库中对应的记录,所有的这些都需要按照某一规则进行。
路由
通过分库分表规则查找到对应的表和库的过程。如分库分表的规则是user_id mod 4的方式,当用户新注册了一个账号,账号id的123,我们可以通过id mod 4的方式确定此账号应该保存到User_0003表中。当用户123登录的时候,我们通过123 mod 4后确定记录在User_0003中。
分库分表产生的问题,及注意事项
1. 分库分表维度的问题
假如用户购买了商品,需要将交易记录保存取来,如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的查找到某用户的 购买情况,但是某商品被购买的情况则很有可能分布在多张表中,查找起来比较麻烦。反之,按照商品维度分表,可以很方便的查找到此商品的购买情况,但要查找 到买人的交易记录比较麻烦。
所以常见的解决方式有:
a.通过扫表的方式解决,此方法基本不可能,效率太低了。
b.记录两份数据,一份按照用户纬度分表,一份按照商品维度分表。
c.通过搜索引擎解决,但如果实时性要求很高,又得关系到实时搜索。
2. 联合查询的问题
联合查询基本不可能,因为关联的表有可能不在同一数据库中。
3. 避免跨库事务
避免在一个事务中修改db0中的表的时候同时修改db1中的表,一个是操作起来更复杂,效率也会有一定影响。
4. 尽量把同一组数据放到同一DB服务器上
例如将卖家a的商品和交易信息都放到db0中,当db1挂了的时候,卖家a相关的东西可以正常使用。也就是说避免数据库中的数据依赖另一数据库中的数据。
一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在 Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂 Slave,通过此方式可以有效的提高DB集群的 QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以,1. 当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。 2. 当写压力很大的时候,就必须得进行分库操作。
---------------------------------------------
MySQL使用为什么要分库分表
可以用说用到MySQL的地方,只要数据量一大, 马上就会遇到一个问题,要分库分表.
这里引用一个问题为什么要分库分表呢?MySQL处理不了大的表吗?
其实是可以处理的大表的.我所经历的项目中单表物理上文件大小在80G多,单表记录数在5亿以上,而且这个表
属于一个非常核用的表:朋友关系表.
但这种方式可以说不是一个最佳方式. 因为面临文件系统如Ext3文件系统对大于大文件处理上也有许多问题.
这个层面可以用xfs文件系统进行替换.但MySQL单表太大后有一个问题是不好解决: 表结构调整相关的操作基
本不在可能.所以大项在使用中都会面监着分库分表的应用.
从Innodb本身来讲数据文件的Btree上只有两个锁, 叶子节点锁和子节点锁,可以想而知道,当发生页拆分或是添加
新叶时都会造成表里不能写入数据.
所以分库分表还就是一个比较好的选择了.
那么分库分表多少合适呢?
经测试在单表1000万条记录一下,写入读取性能是比较好的. 这样在留点buffer,那么单表全是数据字型的保持在
800万条记录以下, 有字符型的单表保持在500万以下.
如果按 100库100表来规划,如用户业务:
500万*100*100 = 50000000万 = 5000亿记录.
心里有一个数了,按业务做规划还是比较容易的.
总结下Mysql分表分库的策略及应用
我们知道对于大型的互联网应用,数据库单表的数据量可能达到千万甚至上亿级别,同时面临这高并发的压力。Master-Slave结构只能对数据库的读能力进行扩展,写操作还是集中在Master中,Master并不能无限制的挂接Slave库,如果需要对数据库的吞吐能力进行进一步的扩展,可以考虑采用分库分表的策略。
1.分表
在分表之前,首先要选中合适的分表策略(以哪个字典为分表字段,需要将数据分为多少张表),使数据能够均衡的分布在多张表中,并且不影响正常的查询。在企业级应用中,往往使用org_id(组织主键)做为分表字段,在互联网应用中往往是userid。在确定分表策略后,当数据进行存储及查询时,需要确定到哪张表里去查找数据,
数据存放的数据表 = 分表字段的内容 % 分表数量
2.分库
分表能够解决单表数据量过大带来的查询效率下降的问题,但是不能给数据库的并发访问带来质的提升,面对高并发的写访问,当Master无法承担高并发的写入请求时,不管如何扩展Slave服务器,都没有意义了。我们通过对数据库进行拆分,来提高数据库的写入能力,即所谓的分库。分库采用对关键字取模的方式,对数据库进行路由。
数据存放的数据库=分库字段的内容%数据库的数量
3.即分表又分库
数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题
当数据库同时面临海量数据存储和高并发访问的时候,需要同时采取分表和分库策略。一般分表分库策略如下:
中间变量 = 关键字%(数据库数量*单库数据表数量)
库 = 取整(中间变量/单库数据表数量)
表 = (中间变量%单库数据表数量)
先谈谈分表的几种方式:
1、mysql集群
事实它并不是分表,但起到了和分表相同的作用。集群可分担数据库的操作次数,将任务分担到多台数据库上。集群可以读写分离,减少读写压力。从而提升数据库性能。
2、自定义规则分表
大表可以按照业务的规则来分解为多个子表。通常为以下几种类型,也可自己定义规则。

1 Range(范围)–这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区。 2 Hash(哈希)–这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。 3 Key(键值)-上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。 4 List(预定义列表)–这种模式允许系统通过预定义的列表的值来对数据进行分割。 5 composite(复合模式) –以上模式的组合使用
以聊天信息表为例:
我事先建100个这样的表,message_00,message_01,message_02……….message_98,message_99.然后根据用户的ID来判断这个用户的聊天信息放到哪张表里面,你可以用hash的方式来获得,可以用求余的方式来获得,方法很多,各人想各人的吧。下面用hash的方法来获得表名:
<?php
function get_hash_table($table,$userid) {
$str = crc32($userid);
if($str<0){
$hash = "0".substr(abs($str), 0, 1);
}else{
$hash = substr($str, 0, 2);
}
return $table."_".$hash;
}
echo get_hash_table('message' , 'user18991'); //结果为message_10
echo get_hash_table('message' , 'user34523'); //结果为message_13
?>
说明一下,上面的这个方法,告诉我们user18991这个用户的消息都记录在message_10这张表里,user34523这个用户的消息都记录在message_13这张表里,读取的时候,只要从各自的表中读取就行了。
优点:避免一张表出现几百万条数据,缩短了一条sql的执行时间
缺点:当一种规则确定时,打破这条规则会很麻烦,上面的例子中我用的hash算法是crc32,如果我现在不想用这个算法了,改用md5后,会使同一个用户的消息被存储到不同的表中,这样数据乱套了。扩展性很差。
3,利用merge存储引擎来实现分表
我觉得这种方法比较适合,那些没有事先考虑,而已经出现了得,数据查询慢的情况。这个时候如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了,现在一张表要分成几十张表,甚至上百张表,这样sql语句是不是要重写呢?举个例子,我很喜欢举例子
mysql>show engines;的时候你会发现mrg_myisam其实就是merge。
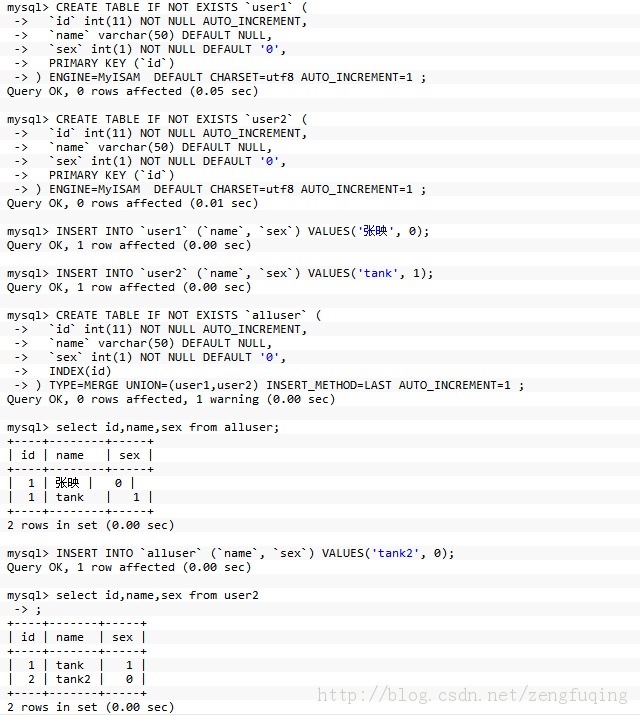
mysql> CREATE TABLE IF NOT EXISTS `user1` (
-> `id` int(11) NOT NULL AUTO_INCREMENT,
-> `name` varchar(50) DEFAULT NULL,
-> `sex` int(1) NOT NULL DEFAULT '0',
-> PRIMARY KEY (`id`)
-> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
Query OK, 0 rows affected (0.05 sec)
mysql> CREATE TABLE IF NOT EXISTS `user2` (
-> `id` int(11) NOT NULL AUTO_INCREMENT,
-> `name` varchar(50) DEFAULT NULL,
-> `sex` int(1) NOT NULL DEFAULT '0',
-> PRIMARY KEY (`id`)
-> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO `user1` (`name`, `sex`) VALUES('张映', 0);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO `user2` (`name`, `sex`) VALUES('tank', 1);
Query OK, 1 row affected (0.00 sec)
mysql> CREATE TABLE IF NOT EXISTS `alluser` (
-> `id` int(11) NOT NULL AUTO_INCREMENT,
-> `name` varchar(50) DEFAULT NULL,
-> `sex` int(1) NOT NULL DEFAULT '0',
-> INDEX(id)
-> ) TYPE=MERGE UNION=(user1,user2) INSERT_METHOD=LAST AUTO_INCREMENT=1 ;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select id,name,sex from alluser;
+----+--------+-----+
| id | name | sex |
+----+--------+-----+
| 1 | 张映 | 0 |
| 1 | tank | 1 |
+----+--------+-----+
2 rows in set (0.00 sec)
mysql> INSERT INTO `alluser` (`name`, `sex`) VALUES('tank2', 0);
Query OK, 1 row affected (0.00 sec)
mysql> select id,name,sex from user2
-> ;
+----+-------+-----+
| id | name | sex |
+----+-------+-----+
| 1 | tank | 1 |
| 2 | tank2 | 0 |
+----+-------+-----+
2 rows in set (0.00 sec)
mysql> CREATE TABLE IF NOT EXISTS `user1` ( -> `id` int(11) NOT NULL AUTO_INCREMENT, -> `name` varchar(50) DEFAULT NULL, -> `sex` int(1) NOT NULL DEFAULT '0', -> PRIMARY KEY (`id`) -> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; Query OK, 0 rows affected (0.05 sec) mysql> CREATE TABLE IF NOT EXISTS `user2` ( -> `id` int(11) NOT NULL AUTO_INCREMENT, -> `name` varchar(50) DEFAULT NULL, -> `sex` int(1) NOT NULL DEFAULT '0', -> PRIMARY KEY (`id`) -> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO `user1` (`name`, `sex`) VALUES('张映', 0); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO `user2` (`name`, `sex`) VALUES('tank', 1); Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE IF NOT EXISTS `alluser` ( -> `id` int(11) NOT NULL AUTO_INCREMENT, -> `name` varchar(50) DEFAULT NULL, -> `sex` int(1) NOT NULL DEFAULT '0', -> INDEX(id) -> ) TYPE=MERGE UNION=(user1,user2) INSERT_METHOD=LAST AUTO_INCREMENT=1 ; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> select id,name,sex from alluser;
+----+--------+-----+
| id | name | sex |
+----+--------+-----+
| 1 | 张映 | 0 |
| 1 | tank | 1 |
+----+--------+-----+
2 rows in set (0.00 sec)
mysql> INSERT INTO `alluser` (`name`, `sex`) VALUES('tank2', 0); Query OK, 1 row affected (0.00 sec) mysql> select id,name,sex from user2 -> ;
+----+-------+-----+
| id | name | sex |
+----+-------+-----+
| 1 | tank | 1 |
| 2 | tank2 | 0 |
+----+-------+-----+
2 rows in set (0.00 sec)
从上面的操作中,我不知道你有没有发现点什么?假如我有一张用户表user,有50W条数据,现在要拆成二张表user1和user2,每张表25W条数据,
INSERT INTO user1(user1.id,user1.name,user1.sex)SELECT (user.id,user.name,user.sex)FROM user where user.id <= 250000 INSERT INTO user2(user2.id,user2.name,user2.sex)SELECT (user.id,user.name,user.sex)FROM user where user.id > 250000
这样我就成功的将一张user表,分成了二个表,这个时候有一个问题,代码中的sql语句怎么办,以前是一张表,现在变成二张表了,代码改动很大,这样给程序员带来了很大的工作量,有没有好的办法解决这一点呢?办法是把以前的user表备份一下,然后删除掉,上面的操作中我建立了一个alluser表,只把这个alluser表的表名改成user就行了。但是,不是所有的mysql操作都能用的
a,如果你使用 alter table 来把 merge 表变为其它表类型,到底层表的映射就被丢失了。取而代之的,来自底层 myisam 表的行被复制到已更换的表中,该表随后被指定新类型。
b,网上看到一些说replace不起作用,我试了一下可以起作用的。晕一个先
mysql> UPDATE alluser SET sex=REPLACE(sex, 0, 1) where id=2; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from alluser; +----+--------+-----+ | id | name | sex | +----+--------+-----+ | 1 | 张映 | 0 | | 1 | tank | 1 | | 2 | tank2 | 1 | +----+--------+-----+ 3 rows in set (0.00 sec) mysql> UPDATE alluser SET sex=REPLACE(sex, 0, 1) where id=2; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from alluser; +----+--------+-----+ | id | name | sex | +----+--------+-----+ | 1 | 张映 | 0 | | 1 | tank | 1 | | 2 | tank2 | 1 | +----+--------+-----+ 3 rows in set (0.00 sec)
c,一个 merge 表不能在整个表上维持 unique 约束。当你执行一个 insert,数据进入第一个或者最后一个 myisam 表(取决于 insert_method 选项的值)。mysql 确保唯一键值在那个 myisam 表里保持唯一,但不是跨集合里所有的表。
d,当你创建一个 merge 表之时,没有检查去确保底层表的存在以及有相同的机构。当 merge 表被使用之时,mysql 检查每个被映射的表的记录长度是否相等,但这并不十分可靠。如果你从不相似的 myisam 表创建一个 merge 表,你非常有可能撞见奇怪的问题。
c和d在网上看到的,没有测试,大家试一下吧。
优点:扩展性好,并且程序代码改动的不是很大
缺点:这种方法的效果比第二种要差一点
三、总结一下
上面提到的三种方法,我实际做过二种,第一种和第二种。第三种没有做过,所以说的细一点。哈哈。做什么事都有一个度,超过个度就过变得很差,不能一味的做数据库服务器集群,硬件是要花钱买的,也不要一味的分表,分出来1000表,mysql的存储归根到底还以文件的形势存在硬盘上面,一张表对应三个文件,1000个分表就是对应3000个文件,这样检索起来也会变的很慢。我的建议是
方法1和方法2结合的方式来进行分表
方法1和方法3结合的方式来进行分表
我的二个建议适合不同的情况,根据个人情况而定,我觉得会有很多人选择方法1和方法3结合的方式