Hadoop学习笔记 - HA
HA概述
为了保证集群的稳定性,保证业务连续性(即集群中某些节点故障时,有对应的策略使得集群继续运行而不崩溃),于是有了HA模式(Highly Available 高可用性)。
HA原理图
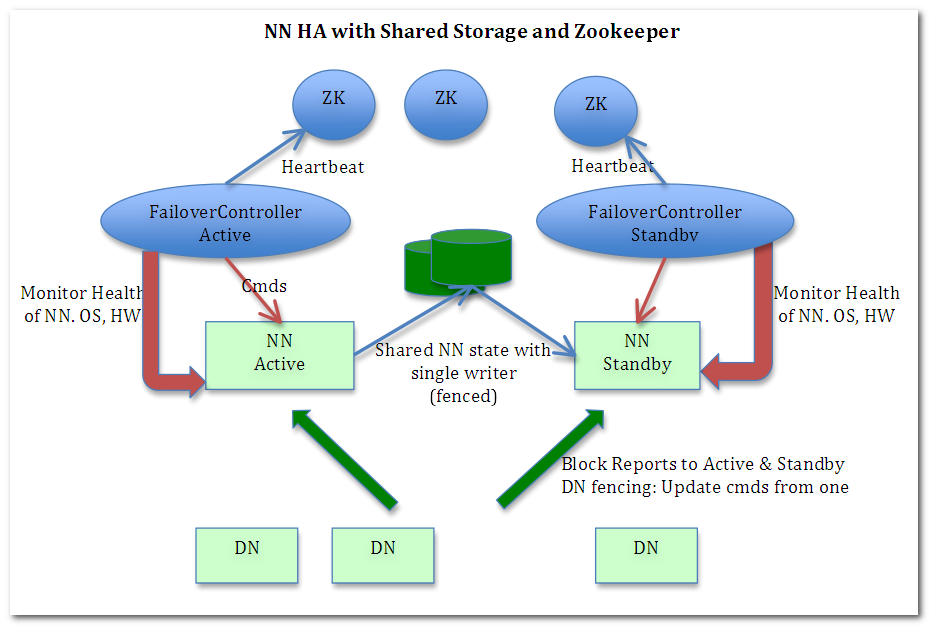
NameNode
- 存储元数据:其中的NN为NameNode,为了避免一个NN的压力过大,在1.x版本中可以设置NameNode和SecondaryNameNode,后面2.x 3.x版本可以支持多个NameNode,将元数据分布式存储。
- 只能有一个NameNode处于Active状态,与Client直接通信,而其他的NameNode处于StandBy状态。
- 为了保证NameNode之间的元数据同步,引入了JN(图中最绿的那两坨,本质也是一个小集群,保证稳定性),即JournalNode,用于同步各个NameNode的信息
JournalNode
ActiveNameNode如何确定数据同步完成呢?
过半原则:JournalNode的数量一般设置为单数,当JournalNode发送的同步数量超过了一半时,默认数据同步完毕
Zookeeper
- 作用:分布式协调,即当集训发生了变化或者故障时,无需手动调整而是自动协调。
- ZKFC:即ZookeeperFailoverController,和NameNode运行在同一台机器上,监视NameNode的状态
HA大致运行过程
- 抢锁:集群启动时,各个NameNode会争相向Zookeeper集训加上自己的锁,但是只有一个集群可以加锁成功,转而成为ActiveNameNode,其他那些NameNode会注册好自己的回调函数,变成StandBy状态
- 故障解锁:当NameNode挂掉时,运行在与之相同一台机器上的ZKFC触发,将其加的那把锁解除
- 回调函数:当原先ActiveNameNode的锁被解除时,触发剩余NameNode的回调函数,剩下的ZKFC会验证原先的ActiveNameNode是否真的宕机,如果是,则将自己设为Active状态