之前的设备掉线问题搞严重了, 陆陆续续搞了一个月,发了太多无效版本,质量部让做出总结。其实都可以说是硬件原因,换硬件!这个肯定不能对他们说,还是老老实实分析自身问题比较靠谱。
一、 异常描述
项目包含客户端、java后台服务、设备端。在同一局域网内,客户端通过java服务对设备端进行控制,设备端也可通过java后台服务主动进行预警信息推送给有权限的客户端。Java服务在此设计中起到通信桥梁作用。
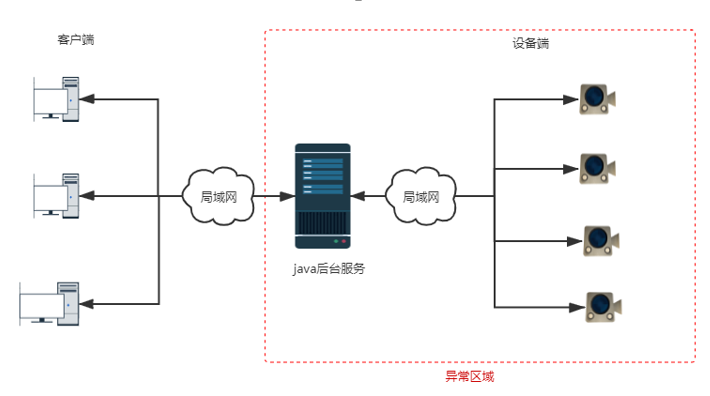
项目阶段性测试结果:一期正常;项目二期,对多台设备进行压测,经过长时间拷机,发现设备端和服务端WS的长连接会概率性的中断(设备掉线)。
中断和消息频率、大小没有明显的相关性;中断都是非正常断开,系统判断为不活跃连接(约定时间内未收到心跳数据)后关闭连接,通信关闭。通信中的中断发生的位置如下图:
二、 技术论证
1. 通信原理
ws协议,ws使用了自定义的二进制分帧格式,把每个应用消息(文本或二进制数据)切分成一或多个帧(二进制编码),发送到目的地解码之后再组装合并起来,完成一次对话。
在客户端和服务器之间的通信协议中,主流的是基于TCP/IP连接的HTTP协议。 在此项目中,使用了websocket(WS)协议进行通信。WS是一个持久化的协议,可以看做HTTP的升级版本,它沿用了HTTP的请求握手进行连接,并对通信中途双方的交互进行了扩展。WS通过一次HTTP握手,建立了一个通道,客户端和服务器都可以随时向对方发送消息,而且可以监听通道当前状态。WS相对HTTP在应用上的优势主要集中在两个方面:
- 双向通信,实现C/S消息主动推送;
- 长连接,可监听设备是否在线。
基于以上两个优点,项目选取了WS协议作为通信协议。
设备端采用多线程配合原生的websocket协议进行消息发送。其技术模型如下:
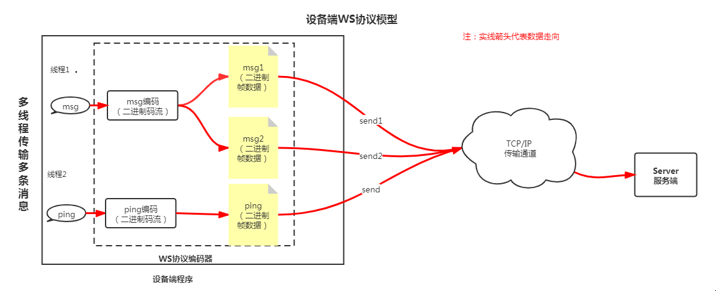
服务端借助netty框架,对WS在框架内部进行处理。每一条帧数据存放在缓存中等待处理,数据模型如下:
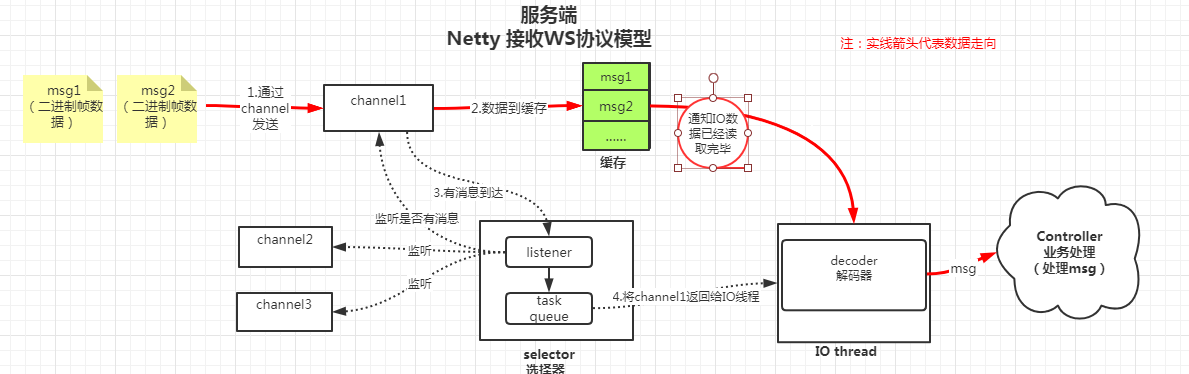
2. 表象描述
掉线集中在服务端和设备端的连接,在查看系统日志后对异常进行总结:
- 设备端在频繁发送几百k预警信息时断开,出现IO异常。
- 服务端消息解码器异常后自动关闭通道,出现解码异常。
- 服务端收到不完整的消息体,不符合接口定义的格式,数据不全。
- 设备、服务器互相无法感知(通道崩溃)。
- 设备端未主动关闭通道,通道崩溃后设备端依然在连续发送数据。
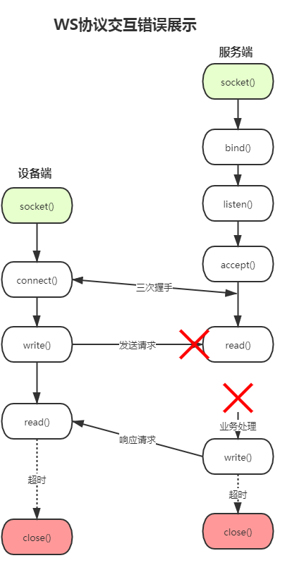
对以上异常表象理解是:服务器接收消息错误(参考上图ws交互错误展示),导致通道数据无法读取和发送,然后服务端在直接关闭通道时,客户端未收到关闭消息,继续处理未处理完成的请求。
3. 原因推测
我们结合上面的表象和ws原理进行推测帧数据异常的环节:
- 数据在TCP/IP传输途中丢失。(TCP是安全的,出错概率忽略)
- 消息编码、解码时发生逻辑错误。(ws成熟的编码模块,出现逻辑错误忽略)
- 消息服务端解码发生系统错误。(如内存溢出,线程中断)
- 程序模块间传递发生错误。(解码和TCP链路之间推送发生错误,丢帧、错序)
以上推测a可忽略;b也是成熟的框架模块,属于协议层面问题,所有程序都是在协议原则上建立的,我们不能推翻协议;c、d错误却让人感觉可能性很大,性能瓶颈是很容易出现程序bug。
经验告诉我们以下情况:网络阻塞、内存溢出、压力测试下的硬件性能瓶颈、多线程……,都会导致一些莫名的bug,尝试着相信是程序间读写ws帧数据犯的错,然后对系统进行优化。
4. 优化措施
根据上述推测,在系统做出以下的调整:
- 优化通信消息中冗余的消息,大数据缓存处理,做到精简通信。
- 心跳数据优化时间间隔,及时清理掉连接后约定时间段无心跳的通道。
- 增加了服务器java运行内存,消息处理完成后手工及时清除消息缓存。
- 建立合理长度的消息队列处理消息,避免多线程抢占资源导致的资源瞬间峰值损耗。
- 服务端解码容错,在缓存中将解码错误的帧数据全部丢弃后清除通道buffer,此消息将作废。
- 服务间断线重连,通道不活跃后自动单开重新连接。
三、 问题分析
在经过了多个阶段的系统优化、容错处理后,有效的避免了设备频繁掉线的问题,顺利的解决了这个问题。也侧面论证了上述推测的准确性。下面具体分析其出现的因果关系
1. 客观原因
由于系统组网只有有限的几十台设备、一个服务端、数个客户端,开发前期凭经验认为交互压力不大,只考虑到了系统业务功能的完善,在功能性测试后就麻痹大意,想当然以为系统已经完善,也太过分相信框架的完善。在遇到问题后也只是想通过表象层容错去进行缓解问题的发生,因为从框架层面去修改一些规则更加耗时耗力。下图将WS传输过程中系统可能出现问题的地方进行标注和说明:
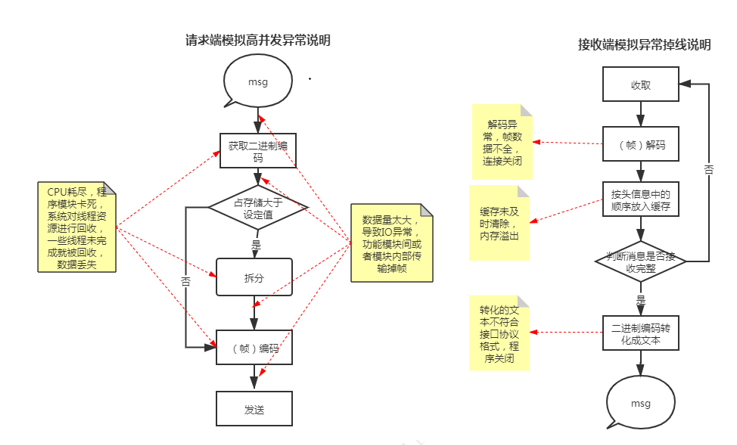
2. 主观原因
在高并发的测试下,系统通信数据传输错误。设备端开启多线程去接收控制指令、处理控制信息、发送预警数据,达到了硬件瓶颈,出现发送过程中拆分、数据编码有错误;服务端对数据帧接收和处理时会出现格式错误、校验错误。如设备端程序发送{“name”:”1234”},服务端会解码异常(缺了一帧),或者会接收到了{“name。错误产生后系统框架无法自我清理,造成的脏数据干扰后续数据读取。
3. 解决方法总结
在压力测试下,设备硬件达到了性能瓶颈,无法解决高并发的大量数据请求。硬件瓶颈在此项目中无法解决,只能通过软件设计来优化。具体优化思路如下图:

设备在作为消息发送者、接收者时,添加消息队列模式,发送者生成一条消息,存放到队列中。队列推送一条消息给接收者,接收成功后返回成功标识给队列。队列收到成功标识后推送下一条消息。这样的处理保证数据的平稳推送,对高并发的请求进行削峰。接收端接收到消息的时候并不立即处理,直接放入队列。队列作为存储缓冲,由时间换取性能。时刻保证硬件设备在瓶颈下运行。保证系统稳定。
服务端做为接收端时,对通信异常也进行了容错处理,对解析异常直接跳过并清除IO缓存池,保证后续的消息能正常接收。(参考netty优化(-))
4. 避免措施
系统设计之初应该考虑在复杂网络环境下的高并发问题,在软件方面将网络请求的削峰、异步、解耦通过相对应的技术进行实现。参考项目硬件以及用户量,对硬件升级。
四、 总结
回首这个问题,我们大多时候是在容错和优化设计。由于ws协议将一个完整的大数据包拆分的成多个数据帧,接收端再重新拼出完整的消息体。本身的复杂性比http协议要高,在实现长连接需求同时,也导致复杂环境下程序的不稳定,增添了优化的难度。反思http也一样,在面对在高并发的情况下如何保持服务稳定也是系统的一个极大考验。所以一个好的系统离不开反复的推敲和优化,打开思维,举一反三。
随着网络环境和用户群体的增长,会遇到高并发的各种问题,在系统开发的过程中应该积极去设计去完善此环境下的问题。目前有很多中间件(如:redis、mq、elasticSearch……)可以帮助我们提高查询、读写效率,在环境允许的情况下,可以使用合适的中间件提升效率。在无法集成这些中间件的情况下,也不能懈怠,学习这些中间件的基本思想,在系统中去使用,努力让系统扩展性更好,兼容性更强。