Wide & Deep算法解决的问题
在推荐系统中LR算法应用的非常广泛,但是LR是一种线性模型,没法学到特征交叉(高阶组合特征),为了解决这个问题,在实际中我们常常需要做特征工程提取高阶特征,一种常用的做法就是求特征的cross-product,如(“gender=female” and “language=en”)。但是在推荐系统中我们一般回对离散特征进行one-hot编码得到高维稀疏特征,也就是说许多特征组合在训练数据中可能从来没有出现过,模型没法学的这部分组合特征的权重。
深度学习+embedding可以不依赖人工特征学到高阶特征,但是容易过度泛化。
本文提出Wide & Deep模型,结合了LR和deep model的优点,旨在使得训练得到的模型能够同时获得记忆(memorization)和泛化(generalization)能力:
记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
在推荐系统中,记忆体现的准确性,而泛化体现的是新颖性。
Wide & Deep模型结构
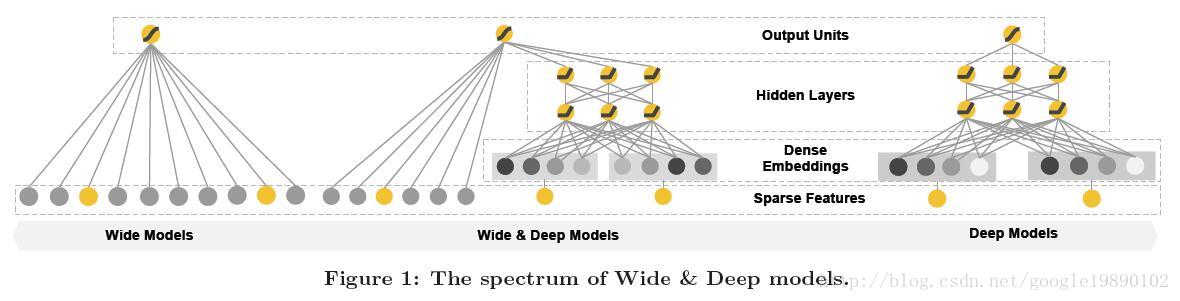

模型表达式:
![]()
wide模型输入:
原始输入特征和交叉特征。
deep模型输入:
原始输入特征