Rabbitmq
网站承受百万级的流量访问设计方案
防止后台服务器直接挂掉,突发大流量很容易把后台打垮,一台垮掉很容易形成连锁式塌陷
相当于增加一层缓冲
一:增加服务器 (可预知,增加成本了) 高峰期需要很多,平时就不需要这么多了
例如:双十一 淘宝
二:增加单台服务器处理性能(不可预知),类比火车站或者游乐园的护栏,(队列)
例如:新浪这种,突发性事件,流量波动巨大的,使用队列(rabbitmq)解决方案
把(点赞,转发,评论)放到众多的队列里然后数据库慢慢消费(生产者-消费者模型)
正常:(点赞,转发,评论)---(redis,mysql)
改进:(点赞,转发,评论)----队列---(redis,mysql)
(exchange:过滤,点赞,转发,品论,走不同的queue)
Rabblitmq和一般queue的区别:多了一个exchange
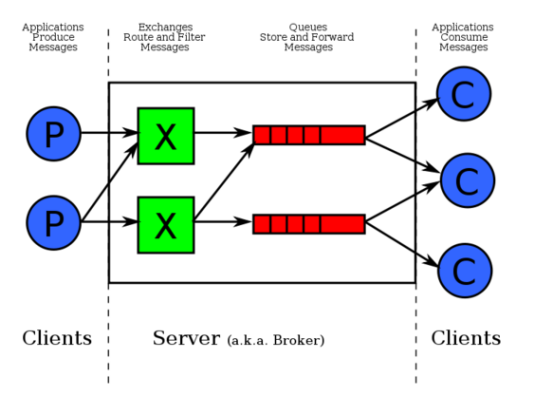
Qbs:单台服务器每秒的请求量,衡量服务器性能的重要指标,越高性能越强
###################################
Linux下安装


1 centos7安装rabbitmq 2 参考文档: 3 https://www.cnblogs.com/web424/p/6761153.html 4 https://blog.csdn.net/qq_22075041/article/details/78855708 5 https://www.rabbitmq.com/ 6 7 1: 8 RabbitMQ依赖Erlang, 所以需要先安装Erlang。 9 yum install epel-release 10 yum install erlang -y 11 12 13 2: 14 安装RabbitMQ 15 wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.6/rabbitmq-server-3.6.6-1.el7.noarch.rpm 16 yum install rabbitmq-server-3.6.6-1.el7.noarch.rpm 17 18 19 3.关于RabbitMQ的一些基本操作 20 完成后启动服务: 21 #service rabbitmq-server start 22 可以查看服务状态: 23 #service rabbitmq-server status 24 #查看服务状态: 25 #service rabbitmq-server status 26 # 添加开机启动RabbitMQ服务 27 chkconfig rabbitmq-server on 28 # 查看当前所有用户 29 $ sudo rabbitmqctl list_users 30 # 查看默认guest用户的权限 31 $ sudo rabbitmqctl list_user_permissions guest 32 # 由于RabbitMQ默认的账号用户名和密码都是guest。为了安全起见, 先删掉默认用户 33 $ sudo rabbitmqctl delete_user guest 34 # 添加新用户 35 $ sudo rabbitmqctl add_user username password 36 # 设置用户tag 37 $ sudo rabbitmqctl set_user_tags username administrator 38 # 赋予用户默认vhost的全部操作权限 39 $ sudo rabbitmqctl set_permissions -p / username ".*" ".*" ".*" 40 # 查看用户的权限 41 $ sudo rabbitmqctl list_user_permissions username 42 # 查看目录的权限用户 43 $sudo rabbitmqctl list_permissions -p /vhost1 44 Listing permissions in vhost "/vhost1" ... 45 46 47 4.RabbitMQ的配置 48 https://www.rabbitmq.com/configure.html#configuration-files 49 https://github.com/rabbitmq/rabbitmq-server/blob/master/docs/rabbitmq.conf.example 50 #cd /etc/rabbitmq/ 51 #vim rabbitmq.config 52 编辑内容如下: 53 [{rabbit, [{loopback_users, []}]}]. 54 这里的意思是开放使用,rabbitmq默认创建的用户guest,密码也是guest,这个用户默认只能是本机访问,localhost或者127.0.0.1,从外部访问需要添加上面的配置。 55 保存配置后重启服务: 56 #service rabbitmq-server stop 57 #service rabbitmq-server start 58 59 60 5.安装插件,开启web管理接口 61 #/sbin/rabbitmq-plugins enable rabbitmq_management 62 重启rabbitmq服务 63 #service rabbitmq-server restart 64 到此,就可以通过http://ip:15672 使用guest,guest 进行登陆web页面了 65 66 67 6.RabbitMQ用户角色及权限控制 68 RabbitMQ用户角色 69 none、management、policymaker、monitoring、administrator 70 RabbitMQ权限控制 71 默认virtual host:"/" 72 默认用户:guest 73 74 75 7.开启用户远程访问 76 默认情况下,RabbitMQ的默认的guest用户只允许本机访问, 如果想让guest用户能够远程访问的话,只需要将配置文件中的loopback_users列表置为空即可,如下: 77 {loopback_users, []} 78 79 另外关于新添加的用户,直接就可以从远程访问的,如果想让新添加的用户只能本地访问,可以将用户名添加到上面的列表, 如只允许admin用户本机访问。 80 {loopback_users, ["admin"]} 81 82 更新配置后,别忘了重启服务哦! 83 sudo /sbin/service rabbitmq-server status # 查看服务状态 84 85 #log文件的位置 86 Logs: /var/log/rabbitmq/rabbit@localhost.log 87 #打开log文件,这里显示的是没有找到配置文件,我们可以自己创建这个文件 88 cd /etc/rabbitmq/ 89 vi rabbitmq.config 90 编辑内容如下: 91 [{rabbit, [{loopback_users, []}]}]. 92 这里的意思是开放使用,rabbitmq默认创建的用户guest,密码也是guest,这个用户默认只能是本机访问,localhost或者127.0.0.1,从外部访问需要添加上面的配置。 93 94 保存配置后重启服务: 95 service rabbitmq-server stop 96 service rabbitmq-server start 97 此时就可以从外部访问了,但此时再看log文件,发现内容还是原来的,还是显示没有找到配置文件,可以手动删除这个文件再重启服务,不过这不影响使用 98 rm rabbit@mythsky.log 99 service rabbitmq-server stop 100 service rabbitmq-server start 101 102 注意:记得要开放5672和15672端口 103 /sbin/iptables -I INPUT -p tcp --dport 5672 -j ACCEPT 104 /sbin/iptables -I INPUT -p tcp --dport 15672 -j ACCEPT
Mac安装
Windows下安装
先安装erlang exe文件 一路安装即可
在安装rabbitmq exe文件 一路安装即可
启动:到响应的目录下面
Rabbitmq-server.bat 点击启动服务
rabbitmq-server -detached 后台启动,释放当前窗口
rabbitmqctl status 查看服务状态 到对应的目录下面
Rabbitmqctl stop 停止服务
Rabbitmqctl list_queues 查看队列里的东西
####################################
使用pika操作rabbitmq
pip3 install pika python操作rabbitmq的工具 对比pymysql
客户端链接rabbitmq server前的准备:
服务端添加用户: 类比mysql的账号密码
Rabbitmqctl add_user xjj 123456
服务端授权:
rabbitmqctl set_permissions -p / xjj ".*" ".*" ".*"
语法:
Rabbitmqctl set_permissions [-p vhost] {user}{conf}{write}{read}
简单的消息发送
Producer.py 生产者没执行一次向队列里,丢一条消息 ()
Consume.py 消费者一直在阻塞状态,队列有消息就处理(后台服务程序:数据库等)
####################################
单条消息丢失
比如:生产者向队列丢了一条消息后,消费者延迟10秒处理此消息,已经取了但是没处理,就造成消息丢失的问题(在回调函数里time.sleep(10)模拟)

处理:
就算消息丢失了,但是一定要告诉一下
生产者端需要加上一个属性:
那怕消费者端死了,一定要告诉一下

消费者端需要加上确认消息代码:
去掉默认就是false,就是要确认的意思,拿没拿到都要确认一下
回调函数里也要确认一下


配置完后,如果队列中有消息消费者挂掉了没来及处理,队列中就一直会存在此消息
####################################
消息队列宕机的情况
假如rabbitmq服务宕机了,队列中有很多消息
模拟:生产者发到队列里3条消息后,rabbitmqctl stop 停止服务,消息在内存中没落地,Rabbitmq-server.bat从新启动 ,rabbitmqctl start_app (在ealang上启动),
rabbitmqctl line-queues 此时查看则消息都没了
解决: 在生产者端加上持久化,刷到磁盘上

####################################
消费者 能者多劳
消费者处理速度的问题处理快的处理更多的消息,最大限度发挥消费者的性能
如果不加上这一条就是轮询模式,一人一条的处理,没法发挥性能优势
消费者端加上:

####################################
Exchange
转发的问题:分门别类的处理,不同的消息放入不同的队列
Direct,fanout,topic,headers headers 性能太差不看了
Direct :组播 分组
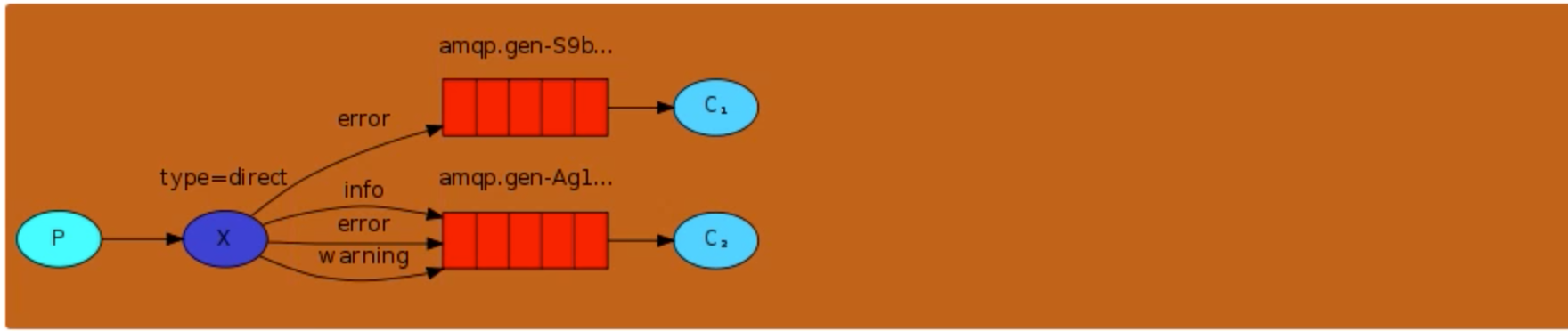
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。路由键与队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。它是完全匹配、单播的模式
启动消费者和生产者
python3 consum-direct.py warning 接收routing key 为warning的队列消息
python3 consum-direct.py info 接收routing key 为info的队列消息
python3 producer-direct.py info 发送routing key 为info的队列消息
python3 producer-direct.py warning 发送routing key 为warning的队列消息
import pika,sys credentials = pika.PlainCredentials('zhangsan','123456') connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", credentials=credentials)) channel = connection.channel() # 开始连接exchange channel.exchange_declare(exchange='mydirect',exchange_type='direct') log_level = sys.argv[1] if len(sys.argv) > 1 else "info" message = ' '.join(sys.argv[1:]) or "info:helloworld!" channel.basic_publish(exchange='mydirect', routing_key=log_level, body=message) print("publish %s to %s" % (message,log_level)) connection.close()
import pika,sys credentials = pika.PlainCredentials('zhangsan','123456') connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='mydirect', exchange_type='direct') #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_obj = channel.queue_declare(exclusive=True) queue_name = queue_obj.method.queue print('queue name',queue_name,queue_obj) log_levels = sys.argv[1:] if not log_levels: sys.stderr.write("Usage: %s [info] [warning] [error] " % sys.argv[0]) sys.exit(1) for level in log_levels: channel.queue_bind(exchange='mydirect',queue=queue_name, routing_key=level) #绑定队列到Exchange print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback,queue=queue_name, no_ack=True) channel.start_consuming()
应用场景:
比如点赞,转发,评论分组
Fanout:广播

每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键,只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的。
注意这种类型的交换器需要:先启动消费者,后启动生产者
如果先启动生产者,没有队列,消息在exchange里没地方发,所以要先启动消费者,有队列接收才可以
启动消费者和生产者
python3 consume-fanout.py
python3 producer-fanout.py hello
import pika,sys credentials = pika.PlainCredentials('xjj', '123456') parameters = pika.ConnectionParameters(host='localhost', credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() # 开始连接exchange 指定发到哪个exchange类型的交换器上 channel.exchange_declare(exchange='myfanout', exchange_type='fanout') message = sys.argv[1] if (len(sys.argv[1]) > 1) else "info" #三元表达式 channel.basic_publish(exchange='myfanout', routing_key='', #没有指定放到哪个队列 body=message) print("publish done %s" % message) connection.close()
import pika # 连接初始化 credentials = pika.PlainCredentials('xjj', '123456') parameters = pika.ConnectionParameters(host='localhost',credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() #1 声明交换器 自定义的交换器的名字 交换器类型 channel.exchange_declare(exchange='myfanout', exchange_type='fanout') #2 声明队列 #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_obj = channel.queue_declare(exclusive=True) queue_name = queue_obj.method.queue print('queue name',queue_name,queue_obj) #3 绑定队列到Exchange channel.queue_bind(exchange='myfanout',queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') #回调函数 def callback(ch, method, properties, body): print(" [x] %r" % body) #指定回调函数,对于指定的队列使用此回调函数 channel.basic_consume(callback,queue=queue_name, no_ack=True) channel.start_consuming() #阻塞状态等着处理队列中的消息
典型应用:
比如微博大V上千万的粉丝,发一个消息的话,不可能所有的粉丝都收到,因为数据量巨大的问题,只有在线的粉丝可以收到,这种时候就是用的fanout广播队列
Topic:规则播
topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。
它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开

启动消费者和生产者
python3 consume-topic.py info.* 接收routing key 以info开头的队列消息
python3 consume-topic.py error.* 接收routing key 以warning开头的队列消息
python3 consume-topic.py # 接收所有的队列消息
python3 producer-topic.py error.mysql xfas 发送routing key 以error开头的队列消息
python3 producer-topic.py info.mysql xfasd 发送routing key 以info开头的队列消息
import pika import sys credentials = pika.PlainCredentials('xjj', '123456') parameters = pika.ConnectionParameters(host='localhost',credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() #队列连接通道 channel.exchange_declare(exchange='mytopic',exchange_type='topic') log_level = sys.argv[1] if len(sys.argv) > 1 else 'all.info' message = ' '.join(sys.argv[1:]) or "all.info: Hello World!" channel.basic_publish(exchange='mytopic', routing_key=log_level, body=message) print(" [x] Sent %r" % message) connection.close()
import pika,sys credentials = pika.PlainCredentials('xjj', '123456') parameters = pika.ConnectionParameters(host='localhost',credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() channel.exchange_declare(exchange='mytopic',exchange_type='topic') queue_obj = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_name = queue_obj.method.queue log_levels = sys.argv[1:] # info warning errr if not log_levels: sys.stderr.write("Usage: %s [info] [warning] [error] " % sys.argv[0]) sys.exit(1) for level in log_levels: channel.queue_bind(exchange='mytopic', queue=queue_name, routing_key=level) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback,queue=queue_name, no_ack=True) channel.start_consuming()
####################################
import pika ## 连接初始化 credentials = pika.PlainCredentials('xjj','123456') #根据用户名密码链接 #链接那台服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() #类似于socket # 声明一个队列test channel.queue_declare('test',durable=True) # durable=True 持久化,如果队列服务宕机,没处理的消息会刷到硬盘上 ## 生产消息到队列 channel.basic_publish(exchange='', #最简单队列,使用默认的,不指定类型,不过滤统一处理 routing_key='test', #放到哪个队列里 body='hello world', #消息 properties=pika.BasicProperties( #消息丢失问题处理,使消息持久 delivery_mode=2, # make message persistent ) ) print('publish done') channel.close() #类比socket 关闭连接
import pika ## 连接初始化 credentials = pika.PlainCredentials('xjj','123456') #根据用户名密码链接 #链接那台服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', credentials=credentials)) channel = connection.channel() #类似于socket # 声明一个队列test channel.queue_declare('test',durable=True) # durable=True 持久化,如果队列服务宕机,没处理的消息会刷到硬盘上 ## 生产消息到队列 channel.basic_publish(exchange='', #最简单队列,使用默认的,不指定类型,不过滤统一处理 routing_key='test', #放到哪个队列里 body='hello world', #消息 properties=pika.BasicProperties( #消息丢失问题处理,使消息持久 delivery_mode=2, # make message persistent ) ) print('publish done') channel.close() #类比socket 关闭连接