应朋友之约,在这里简要谈一下过拟合的问题。
给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比h’小,但在整个实例分布上h’比h的错误率小,那么就说假设h过度拟合训练数据。这是Tom Mitchell在Machine Learning中对过拟合给出的定义。
为啥会出现上面的情况呢?一切都要从哲学说起!
辩证法讲矛盾的对立统一性无处不在,同样,在机器学习中,也存在一对矛盾,这就是模型对已有数据的精度与模型对未知数据的泛化能力。出现过拟合,通常情况是我们对模型的精度要求过于苛刻,导致了模型泛化能力的下降。
具体来讲,如下图
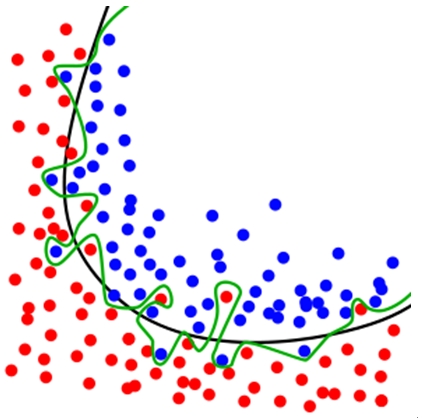
此图来源于维基百科
如果我们要将红色和蓝色的点分开,可以是绿色的那条七拐八拐的曲线,也可以是那条很平滑的黑色的曲线,哪条更好一些呢?
如果单从美感上来讲,我会毫不犹豫地选择那条黑线,那条绿色的线实在是太难看了,以致于我没法立即想到一个函数去拟合出这样一条曲线!
更理性地讲,那条黑色的曲线显然是更加简单的,至少看上去它接近于一个二次函数,更加重要的是,它延续了一个趋势,我们有理由相信这条线能够将未知的大多数点合理地分开。而绿色的曲线需要更高阶的变量,虽然完全分割了所有已知的点,但是我们不敢肯定它对未知数据的分类效果依然很好!
上升一个层次,为何简单的曲线预测效果更好呢?这里涉及到了笔者奉为经典的方法论:奥卡姆剃刀原则——如无必要,勿增实体。或者更朴素地说就是能用简单方法解决的问题,就不要用复杂的方法。因为简单方法的泛化能力更强一些!
笔者一直认为:整个宇宙是统一的,宇宙中万物的运行都能归一为一个规律,不是它不存在,只是我们没有发现。这一点也是受到简单哲学所影响的。