kombu比pika感觉考虑得全面多了,不知道为什么用的人好像少?
生产端是 python-socket.io 的client 接受socketio 消息后, 发到rabbitmq 按时序进行处理.
进行压力测试时, 如果发送到socketio时不加延时, 一次把消息全都发了, 用pika总是报错, channel直接close了.
用kombu一开始也是这样, 使用了producer pool, 好了
https://kombu.readthedocs.io/en/stable/userguide/pools.html#guide-pools
但注意,如果消费者速度有限, 一定要注意加大rabbitmq 的queue的max_length
在生产端声明就行了, 客户端因为是同步单线程, 可以仍然使用pika
conn_kombu = Connection(HOST_RABBITMQ) # heartbeat=0 by default! q_update_sql = Queue('update_sql', routing_key='update_sql', durable=True, exclusive=False, auto_delete=False, max_length = 10000)
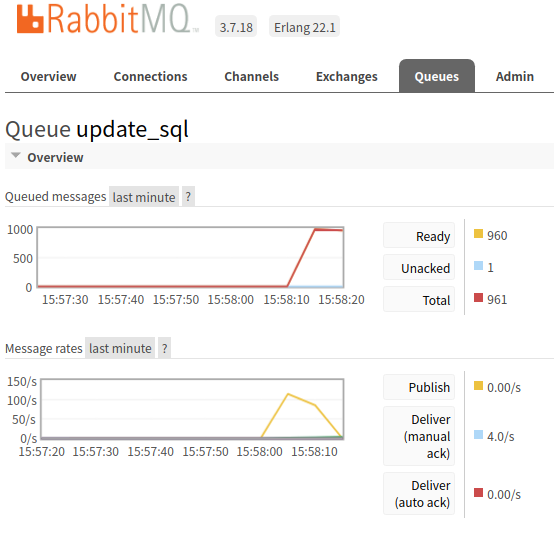
我这个玩具级应用, 发送端猝发1000条消息(实际发送速度大概100条/s, 暂时还不知道怎么提高, ) , 而消费能力只有每秒3-4个消息(目前只有1个worker, 这个倒是不太在意)
速度低因为
1消息要求ack,
2 消息持久化.
3而且严格规定了客户端 每次处理完1个才接下一个, channel.basic_qos(prefetch_count=1)
目前,这3条没什么妥协余地,所以收发速度低,忍了.
注意发送在几秒内就完了(下图message rate里的黄线, publish),
而队列里瞬间积压了1000条消息(上图的queued messages), 正在慢慢处理,下图的蓝线(deliver manual ack 4/s 因为我的消息是手动ack的,每ack一个,说明处理完了1个)
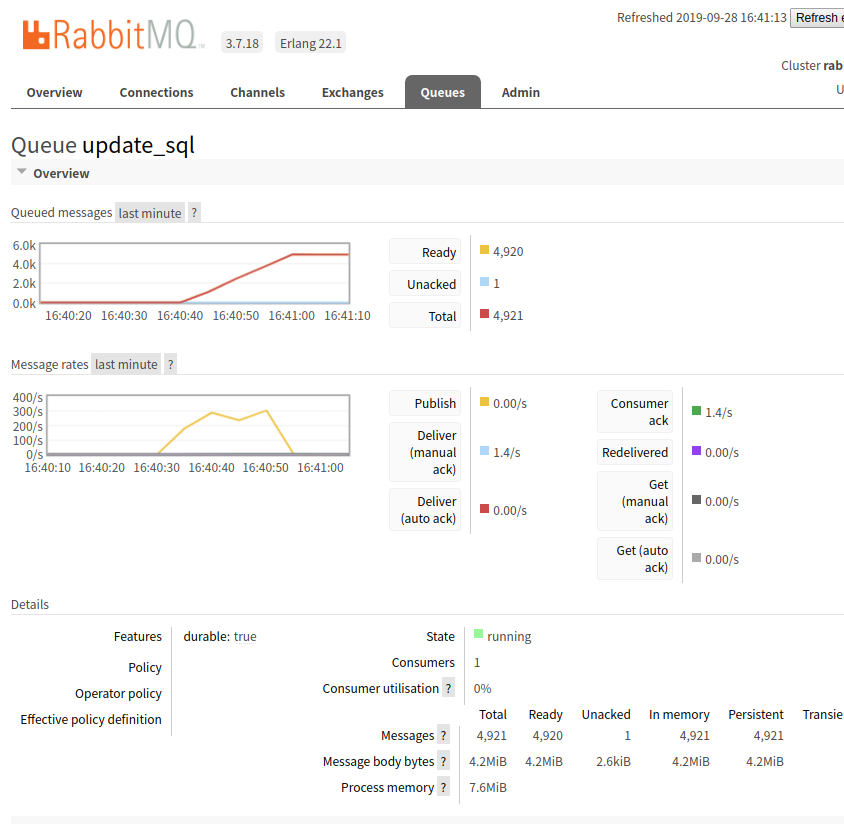
猝发2000条时:
发消息的速度大概能到 200/s 而内存占用几乎忽略不计. rabbitmq 本身运行在docker容器里. 大概内存占用从99M变到110M? 也就这样了. 还是非常放心的

单队列猝发5000条 发送速度能到 300/s 内存 队列里消息占 4M, 处理占7.6M, 几乎忽略不计,很不错了.