1.Policy Evaluation(Prediction)
假如环境模型是完全知道的(就是知道环境的Dynamics),那么就可以将Bellman方程作为更新的原则来求的贝尔曼方程解,进而获得状态值函数vπ的解。其中计算状态值函数vπ就叫做Policy Evaluation。
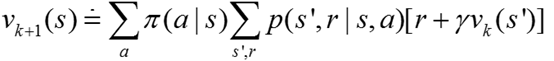
另外,当k趋近于无穷的时候,vk收敛于vπ。这种算法是iterative policy evaluation。在DP中,所有的更新都是expected 更新,因为他们是建立在所有的后继状态上的更新,而不仅仅是一个sample到的后继状态。
2.Policy Improvement
根据原始的policy的value function采用greedy的方法,改进原始policy,这个过程就叫做policy improvement。
3.Policy Iteration

4.Value Iteration
Policy iteration 要先等到vk收敛到vπ后,才能进行policy improvement;而Value iteration是Bellman 最优方程的变形,即讲Bellman最优方程当做更新的规则。Value Iteration和Policy iteration 大体相同,只不过是在Evaluation的时候,采取的action是所有action中最大的。
5.Generalized Policy Iteration
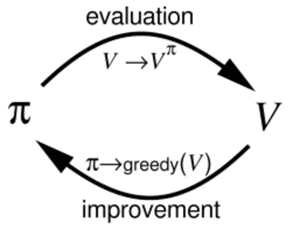
在Policy Iteration中,我们是在Evaluation之后再进行improvement。但是没必要这么做,我们可以在每一次迭代计算Evaluation的时候,就可以进行improvement。所有的强化学习算法都可以表述为GPI,Evaluation和Improvement可以看做是竞争和合作的关系,根据当前的值函数将Policy变得greedy,则会使得当前的值函数不适用于当前的Policy;将Value function当前的Policy保持一致,则有使得Policy不具有greedy性质。但是,长远看来,他们都会走向相同的终点,最优的Value function和最优的Policy。
6.总结
GPI是所有强化学习的核心思想,它包括两个部分。一个部分是进行Policy Evaluation,即给定Policy,不断的去更新Vaule function,使得Value function收敛到真正的Policy Value Function。另外一个部分是Improvement,即给定Value Function,假设它是自己的Value Fucntion的情况下,采用greedy的方法,不断的t提高Policy。
尽管这两个部分会相互改变对方的基础,但是他们最终会找到一个共同的解决方法:最优Policy和最优Value Function。