提到输入输出流,作为CPPer很自然的就会想到std::iostream,对于文本流的处理,iostream可以说足够强大,应付一般复杂度的需求毫无压力。对二进制流处理却只能用“简陋”来形容,悲催的是,作为一个在多媒体软件领域默默耕耘多年的码农日常打交道最多的偏偏就是二进制流。
前些年流行过一本书叫做什么男人来自火星女人来自金星之类的,同样的,如果说文本流来自火星那二进制流就是来自金星。对一个文本流,我们可能期望这样的接口函数:
1 string text = stream.get_line(); // 基础接口 2 string word = stream.get_word(); // 增强接口
而对二进制流,我们期望的接口可能是这个样子的:
1 int read_bytes = stream.read(buffer, size); // 基本接口 2 int value = stream.read_int32(); // 增强接口
做为iostream灵魂的插入/提取运算符("<<"/">>")重载对文本流来说是神一般的存在,但在二进制流中却完全无法使用,因为二进制流需要精确到byte(甚至bit)的控制,所以会有下面这样的接口:
int v1 = stream.read_uint16(); // 读取short int int v2 = stream.read_int16(); // 读取unsigned short int int v3 = stream.read_uint24(); // 读取3字节无符号整型,没错是3字节24位 int v4 = stream.read_int24(); // 想想这个函数有多变态!
基于编译期推导的运算符重载很难满足类似的需求。在我看来,把两类方法合并在同一个类中是得不偿失的,核心需求几乎没什么相似之处,非核心的需求则无关紧要,而且基本上不会有既是文本流又是二进制流的情况出现。iostream偏偏就这么做了,对此,只(wo)能(cuo)呵(le)呵(ma)了。
二进制流按照流的方向可以划分为输入流和输出流(废话);按另外一个纬度上则可以划分为顺序访问流和可随机访问流,两者最主要的区别是是否支持定位操作(seek),前者不支持,后者支持,比如标准输入输出流就是顺序访问流,而文件流一般都是可随机访问流。站在更高的层次上来理解,顺序访问流内置了一个时间箭头,既不能回头也不能跳跃,可随机访问流则是内置的空间轴,没有方向性(或者说方向性很弱),如果你愿意完全可以从一个文件的尾部往头部读。因此带有时间属性的实时流一般是顺序访问流,比如录音、录屏产生的数据流,比如在线直播视频的直播流。
两个纬度各两个分类共四种组合,由此我们就可以设计一个newbility的架构出来了:

哈哈,是不是很强大,是不是……怕了?……怕了就对了,这还只是抽象接口类,如果再把实现类以及各种派生考虑进去,这个系统的复杂度至少还要增加两倍。
……
上面的图是开个玩笑,图中的系统是典型的臆造抽象,连过度设计都算不上,甚至不如没有设计。虽然夸张了些,但现实中也不是没有犯了类似错误的系统,比如DirectShow的base classes内部的实现代码就颇有些神似的地方(说出这样的话,我对DirectShow的怨念得有多深啊……)。
解决任何问题的第一步首先就是简化问题,也就是抓住主要矛盾,忽略次要矛盾。至少在曾经某一段时间,CPPer特别追求精致的设计,而精致的设计往往首先就把简单的问题复杂化了,还记得那个经典的C++版的Hello World吗?精致设计的目的本是为了代码复用,而现实却是:越简单的代码越容易复用,越是精心设计的代码越容易因为复杂而难以复用。回到我们的问题,首先要找到主要矛盾,也就是核心需求:一组能应付大部分日常任务的简单的输入和输出流,注意,这里用的是“输入和输出流”而不是“输入输出流”。事实上,在实际的开发工作中很少会遇到要求一个流即是输入流又是输出流的情况,如果遇到又往往是因为业务需求复杂,此种情况下即使专门写一个应对特殊需求的流也不是不可接受。
所以,“既是输入流又是输出流”这种需求被我们作为次要矛盾砍掉了,尚未考虑清楚的继承关系也暂时砍掉,文件流之类的派生扩展也砍掉,系统的剩余部分就简单的一目了然了:

只有四个孤零零的抽象类。输出流和输入流类似但无关联,所以我们以输入流为例做进一步的考察,也就是两个抽象类:random_istream和sequential_istream。前面说过了,顺序访问流和可随机访问流最主要的区别是顺序访问流不支持支持定位操作(seek)而可随机访问流支持,也就是说,如果sequential_istream设计成下面这样:
1 class sequential_istream 2 { 3 public: 4 virtual void read(void* buffer, int bytes) = 0; 5 };
则random_istream是这样的:
class random_istream { public: virtual void read(void* buffer, int bytes) = 0; virtual void seek(int offset) = 0; };
发现什么没有?random_istream是sequential_istream的超集,这意味着可以让random_istream从sequential_istream继承下来,既不必设计成两个孤零零的类,也不必为了通用强行给两个类提取一个公共基类。从概念上讲也是完美的,一个可随机访问的流当然可以当作顺序流来访问,这是典型的“is-a”的关系。重新调整后的设计如下:
1 class input_stream 2 { 3 public: 4 virtual void read(void* buffer, int bytes) = 0; 5 }; 6 7 class random_istream : public input_stream 8 { 9 public: 10 virtual void seek(int offset) = 0; 11 };
这里去掉顺序流的sequential关键字,让概念的继承逻辑更加顺畅。
事实上,还有另外一种设计方案,可以把input_stream设计成胖接口(fat interface),同时支持顺序流和可随机访问流:
1 class input_stream 2 { 3 public: 4 virtual void read(void* buffer, int bytes) = 0; 5 virtual void seek(int offset) = 0; 6 virtual bool seekable() const = 0; 7 };
注意seekable这个方法,它返回了一个布尔值指示seek方法是否有效,有效表明这是一个可随机访问的流,无效则是顺序流。
我们没有采用这个方案,虽然少了一层继承关系看起来简单了,实际应用却并不比前面的方案简单。seekable在语义上是一种状态属性(有这个说法吗)表示对象的一类状态,一个布尔型可以表示两种状态,每增加一个则应用复杂度就翻一倍,呈指数增长(不要信我,我随口乱说的)。这里虽然只有一个状态属性,但已经足以给我们造成不少的困扰了:
- seekable返回的状态究竟是暂时的还是永久的?是否可能中途改变?至少我们从接口上看不出答案;
- 如果seekable返回false,仍然调用了seek方法会怎样?
- 一个顺序流的派生类根本不需要但还是要实现seekable和seek两个方法,哪怕只是简单的返回false和抛出异常;
- 使用者每次试图调用seek方法前都要先调用seekable判断一下,最后会有一堆的if-else;
上面的问题也是胖接口固有的问题,所以一定要慎重使用胖接口,这次我们选择了抛弃。
把各种派生类和各种辅助类都加上,得到最终的结构图:
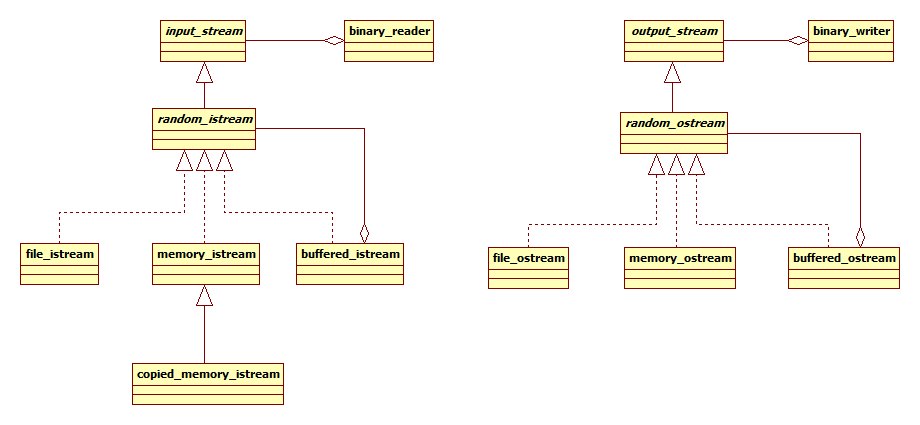
至此,我们的工作已基本完成,剩下的都是无聊的体力活。
input_stream和random_istream接口:
1 class input_stream 2 { 3 public: 4 virtual void read(void* buffer, uint32_t bytes) = 0; 5 virtual void skip(uint32_t bytes) = 0; 6 virtual uint64_t tell() const = 0; 7 }; 8 9 10 class random_istream : public input_stream 11 { 12 public: 13 virtual void seek(int64_t offset, seek_origin origin) = 0; 14 virtual uint64_t size() const = 0; 15 };
注意skip方法,这个方法用于在顺序读入时跳过指定字节数,其功能也可以通过read后丢弃数据的方式实现,在random_istream中则可以直接使用seek方法实现,最终决定加入这个方法主要是为了使用方便,在效率上则与当前流的最优替代方式相当。
output_stream和random_ostream:
1 class output_stream 2 { 3 public: 4 virtual void write(void* buffer, uint32_t bytes) = 0; 5 virtual void flush() = 0; 6 virtual uint64_t tell() const = 0; 7 }; 8 9 class random_ostream : public output_stream 10 { 11 public: 12 virtual void seek(int64_t offset, seek_origin origin) = 0; 13 };
binary_reader和binary_writer两个类是对input_stream和output_stream的扩展,采用外部扩展的方式相对于继承扩展更加灵活。如果用继承扩展的话binary_reader究竟从input_stream还是random_istream继承呢,或者是把binary_reader设计成独立的接口类,实现类比如file_istream同时继承binary_reader和random_istream呢?这些都是让人纠结的问题,并且每一种方案都不完美。外部扩展的方式则堪称完美,实现起来也简单,只要给binary_reader塞一个input_stream的指针就可以了,用起来就像下面这个样子:
1 input_stream* ist = ... 2 3 binary_reader reader(ist); 4 5 int v1 = reader.read_uint8(); 6 7 reader.skip(4); 8 int v2 = reader.read_uint16_be(); 9 ... 10 11 // seek操作也可以支持 12 13 random_istream* ist = ... 14 15 binary_reader reader(ist); 16 17 int v1 = reader.read_uint8(); 18 19 ist->seek(4, see_origin::current); 20 int v2 = reader.read_uint16_be(); 21 ...
binary_reader的完整声明大体如下,binary_writer与之类似:
1 class binary_reader 2 { 3 public: 4 binary_reader(input_stream* stream); 5 6 void read(void* buffer, uint32_t read_bytes); 7 void skip(uint32_t offset); 8 9 uint64_t tell() const; 10 11 uint8_t read_uint8(); 12 13 uint16_t read_uint16_be(); 14 uint32_t read_uint24_be(); 15 uint32_t read_uint32_be(); 16 uint64_t read_uint64_be(); 17 18 uint16_t read_uint16_le(); 19 uint32_t read_uint24_le(); 20 uint32_t read_uint32_le(); 21 uint64_t read_uint64_le(); 22 23 .... 24 25 private: 26 input_stream* _stream; 27 };
……
花了一周的业余时间总算把这一篇写完了,一个简单的设计方案想讲清楚却也不是那么容易。这个方案特别是具体接口函数的设计还很不完善,需要在实际应用的过程中逐渐丰富改进,当然了,在一个简单的方案上做改进想来也不会太麻烦。下一篇,准备写一下这个方案背后的东西——错误处理,具体来讲是基于异常的错误处理方案。