| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 更加熟练去使用github,对json文件进行解析,增强编码能力,学会功能测试 |
| 学号 | 031802329 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| Estimate | 估计这个任务需要多少时间 | 120 | 180 |
| Development | 开发 | 120 | 150 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 420 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 60 | 90 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 30 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 180 | 240 |
| Code Review | 代码复审 | 60 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | 30 | 30 |
| Test Report | 测试报告 | 15 | 20 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1230 | 1680 |
二、解题过程
解题思路:
刚刚看到这个题目的时候我完全是一头雾水,毕竟我从来也没有接触过这种类型的作业,并且自己的编码能力也十分有限。
在查看了题目要求之后,我打开了数据,当时我的第一印象是这个:

这使得我更加懵了,甚至开始连题目需要统计什么都完全不清楚了。于是我开始向大佬求助,终于,在大佬的讲解下,我才弄
懂了题意,并且明白了这个题目就是要求我们解析 json 文件。并从他那里得知用 Python 去写会比较简单,好在之前看过
Python的一些基础语法,便又开始学习 Python 中关于 json 库的使用。对于我来说,解题思路分为以下几点:
- 首先对 json 文件进行解析,弄懂其中每个数据的含义
- 通过观察可得,每一个数据都是字典类型,所以我们可以通过键值对来进行查找和统计
- 在编码中定义三个函数来进行统计,从而达到题目要求
- 将统计好的结果放入创建的 json 文件中,需要的时候直接查询就行
- 对写好的代码进行测试,从结果中发现存在的问题,从而进行改进
- 将代码提交到 Github 进行运行测试
三、流程图

四、代码说明
定义函数求个人4种事件的数量
def personal_action_times(data):
personal_times = {}
for item in data:
if not isinstance(personal_times.get(item["actor"]['id'], None), dict):
personal_times[item["actor"]['id']] = {}
if item['type'] in ['PushEvent', 'IssueCommentEvent', 'IssuesEvent', 'PullRequestEvent']: #判断事件类型是否为所需要统计的事件
personal_times[item["actor"]['id']][item['type']] = personal_times[item["actor"]['id']].get(item['type'], 0) + 1
for key in list(personal_times.keys()):
personal_times[key]['PushEvent'] = personal_times[key].get('PushEvent', 0)
personal_times[key]['IssueCommentEvent'] = personal_times[key].get('IssueCommentEvent', 0)
personal_times[key]['IssuesEvent'] = personal_times[key].get('IssuesEvent', 0)
personal_times[key]['PullRequestEvent'] = personal_times[key].get('PullRequestEvent', 0)
return personal_times
定义函数求每一个项目的 4 种事件的数量
def project_action_times(data): #定义函数求每一个项目的 4 种事件的数量
project_times = {}
for item in data:
if not isinstance(project_times.get(item["repo"]['id'], None), dict):
project_times[item["repo"]['id']] = {}
if item['type'] in ['PushEvent', 'IssueCommentEvent', 'IssuesEvent', 'PullRequestEvent']:
project_times[item["repo"]['id']][item['type']] = project_times[item["repo"]['id']].get(item['type'], 0) + 1
for key in list(project_times.keys()):
project_times[key]['PushEvent'] = project_times[key].get('PushEvent', 0)
project_times[key]['IssueCommentEvent'] = project_times[key].get('IssueCommentEvent', 0)
project_times[key]['IssuesEvent'] = project_times[key].get('IssuesEvent', 0)
project_times[key]['PullRequestEvent'] = project_times[key].get('PullRequestEvent', 0)
return project_times
定义函数求每一个人在每一个项目的 4 种事件的数量
def per_map_to_pro(data): #定义函数求每一个人在每一个项目的 4 种事件的数量。
per_map_pro_times = {}
for item in data:
per_map_pro_times[item['repo']['id']] = {}
for item in data:
per_map_pro_times[item['repo']['id']][item['actor']['id']] = {}
for item in data:
if item['type'] in ['PushEvent', 'IssueCommentEvent', 'IssuesEvent', 'PullRequestEvent']:
per_map_pro_times[item['repo']['id']][item['actor']['id']][item['type']] = per_map_pro_times[item['repo']['id']][item['actor']['id']].get(item['type'], 0) + 1
per_map_pro_times[item['repo']['id']][item['actor']['id']]['PushEvent'] = per_map_pro_times[item['repo']['id']][item['actor']['id']].get("PushEvent", 0)
per_map_pro_times[item['repo']['id']][item['actor']['id']]['IssueCommentEvent'] = per_map_pro_times[item['repo']['id']][item['actor']['id']].get("IssueCommentEvent", 0)
per_map_pro_times[item['repo']['id']][item['actor']['id']]['IssuesEvent'] = per_map_pro_times[item['repo']['id']][item['actor']['id']].get("IssuesEvent", 0)
per_map_pro_times[item['repo']['id']][item['actor']['id']]['PullRequestEvent'] = per_map_pro_times[item['repo']['id']][item['actor']['id']].get("PullRequestEvent", 0)
return per_map_pro_times
解析 json 文件,并将数据存入 data
def load_data():
with open("./data.json", 'r+', encoding='utf-8') as fp:
data = [json.loads(line) for line in fp.readlines()]
return data
将统计出来的结果转成 json 文件
def save_data(data, filename=None):
with open(filename, 'w+', encoding='utf-8') as fp:
json.dump(data, fp, indent=4, ensure_ascii=False)
五、单元测试及覆盖率


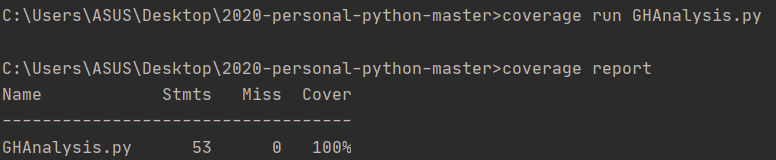
通过使用第三方库 Coverage 测得代码的覆盖率为100%
六、代码规范链接
https://github.com/xiaofei2000/2020-personal-python/blob/master/codestyle.md
七、总结
这次的作业对于我来说是一次非常大的挑战,从刚刚拿到题目开始我就被深深地打击了,对于我来说确实是太难了。
从前我也从来没有接触过这种类型的题目,光就题目条件和要求我就被折磨到了,完全都看不懂。好在有大佬的讲解和分析,
我才理解题目的意思和要求,并且对于这个对我来说工程量比较大的作业,仅仅有大佬还是不够的呀,还是得上网查找资料
啊。虽然说过程是十分艰难和漫长的,但是在解题的过程中我也接触到了不少的新事物,掌握了不少的新知识,对于一些编
程软件的使用和对于Python的使用,我也更加的熟练了。关于 Github 的使用,我也学到了不少。最后,希望以后我能再
接再厉,学到更多的知识吧。